Generating Public Health Responses using Survey-Augmented Large Language Models
Pith reviewed 2026-06-26 11:22 UTC · model grok-4.3
The pith
Large language models generate synthetic survey data that matches real marginal distributions of demographics and health attitudes but not their joint variation within individuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
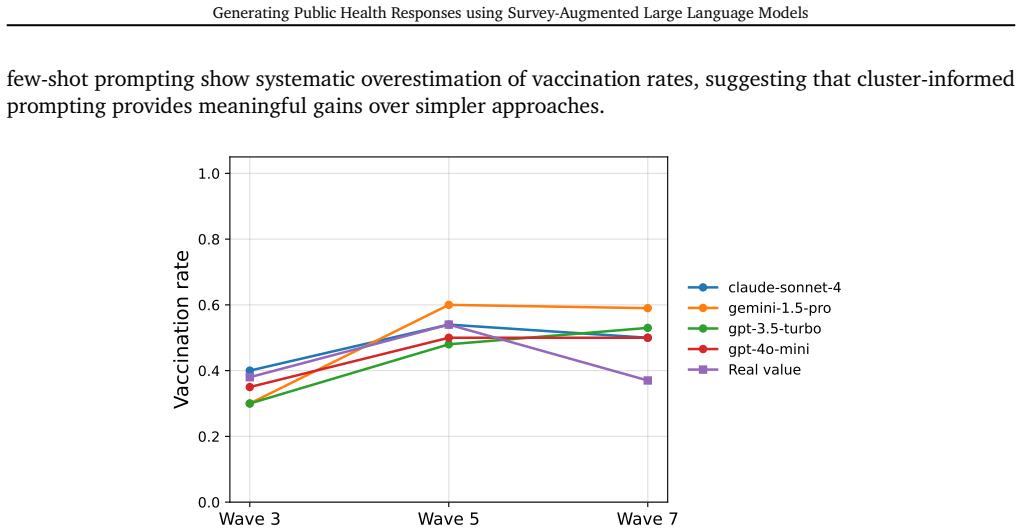
Using a cluster-informed prompting approach derived from longitudinal FluPaths survey data, LLMs produce synthetic responses whose marginal distributions of demographic characteristics, vaccination-related beliefs, risk perceptions, and health behaviors align with observed survey data, with varying reliability across models and waves in reproducing group-level vaccination trends, although a trained classifier can still identify the records as synthetic.
What carries the argument
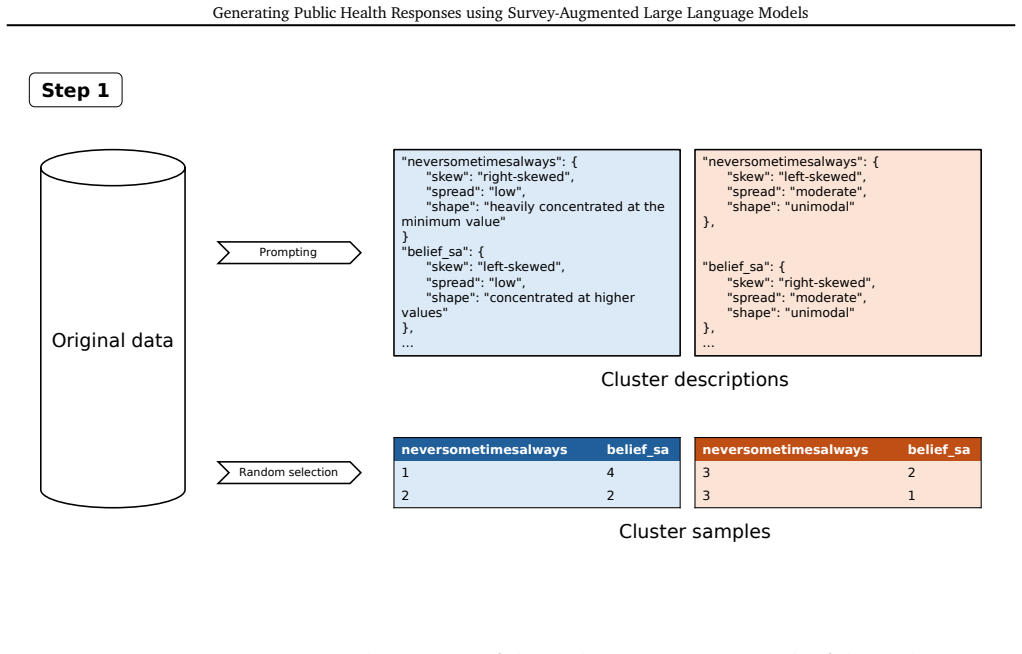
Cluster-informed prompting strategy that identifies groups with positive or negative vaccination attitudes from real survey data and incorporates those groupings into LLM prompts to generate new responses.
If this is right
- The synthetic data can serve as a tool for exploratory data augmentation in agent-based epidemic modeling.
- Performance in matching group-level vaccination trends varies by model and across different epidemic waves.
- Generated responses should not replace human survey data without further methodological improvements and validation.
- Some LLMs reproduce the observed group-level trends more reliably than others.
Where Pith is reading between the lines
- Improving capture of within-respondent correlations could allow synthetic data to support more detailed simulations of individual health decisions during outbreaks.
- The same prompting approach might be tested on surveys about other behaviors, such as economic choices or social attitudes.
- Periodic comparison against newly collected real surveys would be required to check whether the method remains useful as population patterns shift.
Load-bearing premise
That prompting LLMs with groupings taken from real survey clusters will make the generated responses statistically close enough to unobserved population patterns to be useful for exploratory epidemic modeling.
What would settle it
A fresh, independent survey under comparable conditions whose joint distributions or within-respondent correlations differ markedly from those in the synthetic data, or where a real-versus-synthetic classifier reaches near-perfect accuracy on new records.
Figures
read the original abstract
Epidemiological models often rely on survey data to represent how individuals make health-related decisions, such as whether to vaccinate or adopt protective behaviors. However, repeated large-scale surveys are costly, time-consuming, and limited in the range of scenarios they can capture. In this work, we investigate whether large language models (LLMs) can generate synthetic survey responses that reproduce patterns observed in real populations. Using longitudinal data from the FluPaths surveys, we first identify groups associated with broadly positive or negative attitudes toward vaccination through clustering analysis. We then evaluate several LLMs using a cluster-informed prompting approach to generate synthetic survey responses across multiple epidemic waves. Across models, the synthetic data generally reproduce the distributions of demographic characteristics, vaccination-related beliefs, risk perceptions, and health behaviors observed in the survey data. However, they are less successful at capturing how these factors vary together within respondents. Some models reproduce group-level vaccination trends more reliably than others, although performance varies across waves. We also trained a classifier to distinguish real from synthetic records and found that the generated responses remained identifiable as synthetic. Overall, our findings suggest that LLM-generated survey data may provide a useful tool for exploratory data augmentation and we hope that it could support agent-based epidemic modeling approaches. However, the generated data should not be treated as a substitute for human survey data without further methodological improvements and validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates whether LLMs can generate synthetic survey responses that reproduce patterns from the FluPaths longitudinal surveys on vaccination attitudes and health behaviors. Using clustering to identify groups with positive or negative vaccination attitudes, the authors apply cluster-informed prompting to several LLMs to produce synthetic records across epidemic waves. They report that the synthetic data generally match the marginal distributions of demographics, vaccination beliefs, risk perceptions, and behaviors, but are less successful at reproducing within-respondent covariation; classifiers can still distinguish real from synthetic records; and some models better capture group-level trends. The conclusion is that such data may support exploratory augmentation for epidemic modeling but should not substitute for real survey data without further validation.
Significance. If the empirical results hold, the work supplies a transparent, balanced assessment of LLM performance on synthetic public-health survey generation, documenting both marginal-distribution successes and joint-distribution failures. This is directly relevant to researchers exploring data augmentation for agent-based models, as it quantifies the gap between marginal calibration and the individual-level attribute bundles required by such models. The use of real survey clusters for prompting, multi-wave evaluation, and explicit classifier tests are strengths that make the negative findings on joints particularly informative.
major comments (1)
- [Abstract] Abstract: The suggestion that the generated data 'could support agent-based epidemic modeling approaches' sits in tension with the explicit finding that the synthetic records are 'less successful at capturing how these factors vary together within respondents.' Agent-based models require consistent per-respondent attribute bundles (e.g., correlated beliefs and behaviors), not merely marginal or group-level agreement; the manuscript should either supply evidence that marginal matching is sufficient for the intended exploratory uses or qualify the modeling claim more narrowly.
minor comments (1)
- [Methods] The description of how the identified clusters are translated into prompt text could be expanded with an example prompt template to improve reproducibility of the cluster-informed strategy.
Simulated Author's Rebuttal
We thank the referee for this constructive observation on the abstract. The comment correctly identifies a tension between our empirical findings on joint distributions and the phrasing of potential applications. We will revise the abstract to qualify the modeling claim more narrowly, consistent with the manuscript body.
read point-by-point responses
-
Referee: [Abstract] The suggestion that the generated data 'could support agent-based epidemic modeling approaches' sits in tension with the explicit finding that the synthetic records are 'less successful at capturing how these factors vary together within respondents.' Agent-based models require consistent per-respondent attribute bundles (e.g., correlated beliefs and behaviors), not merely marginal or group-level agreement; the manuscript should either supply evidence that marginal matching is sufficient for the intended exploratory uses or qualify the modeling claim more narrowly.
Authors: We agree that the abstract phrasing risks overstating applicability. Our results explicitly document weaker performance on within-respondent covariation, which is a substantive limitation for ABMs that depend on realistic individual-level bundles. No additional evidence is provided that marginal matching alone suffices for such models. We will revise the abstract to state that the synthetic data may aid exploratory augmentation but should not be assumed sufficient for ABMs without further validation of joint distributions, aligning the claim with the paper's conclusions and the referee's point. revision: yes
Circularity Check
No circularity: empirical comparisons to external survey data
full rationale
The paper performs clustering on real FluPaths survey data, uses the resulting groups to construct prompts for LLMs, generates synthetic records, and evaluates them via direct statistical comparison of marginal distributions and a trained classifier against the held-out real survey responses. No derivation, equation, or prediction reduces to a fitted parameter or self-defined quantity by construction; no load-bearing self-citation chain or imported uniqueness theorem appears; all performance claims rest on external empirical benchmarks rather than internal re-labeling of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs prompted with cluster-derived information can produce outputs whose marginal statistics align with real population patterns in health decision-making
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.1110. URLhttps: //github.com/JosephJeesungSuh/subpop. O. Toubia, G. Z. Gui, T. Peng, D. J. Merlau, A. Li, and H. Chen. Database report: Twin-2K-500: A data set for building digital twins of over 2,000 people based on their answers to over 500 questions.Marketing Science, 44(6):144...
-
[2]
The dataset description, in one sentence
-
[3]
If no target exists, choose one from the column as target for the dataset to classify
The target of the dataset. If no target exists, choose one from the column as target for the dataset to classify
-
[4]
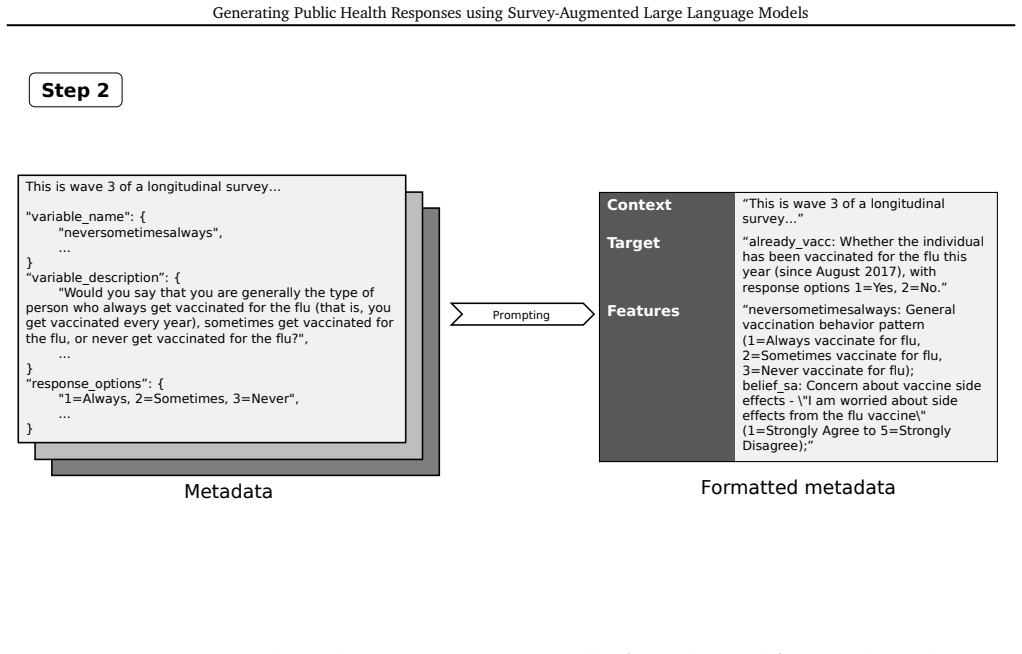
context":
The features and their explanations. Below is a sample output produced by a large language model. { "context": "This is wave 3 of a longitudinal survey studying behavioral and beliefs aspects related to influenza vaccination, conducted in Fall 2017 following a previous wave in Fall 2016.", "target": "already_vacc: Whether the individual has been vaccinate...
2017
-
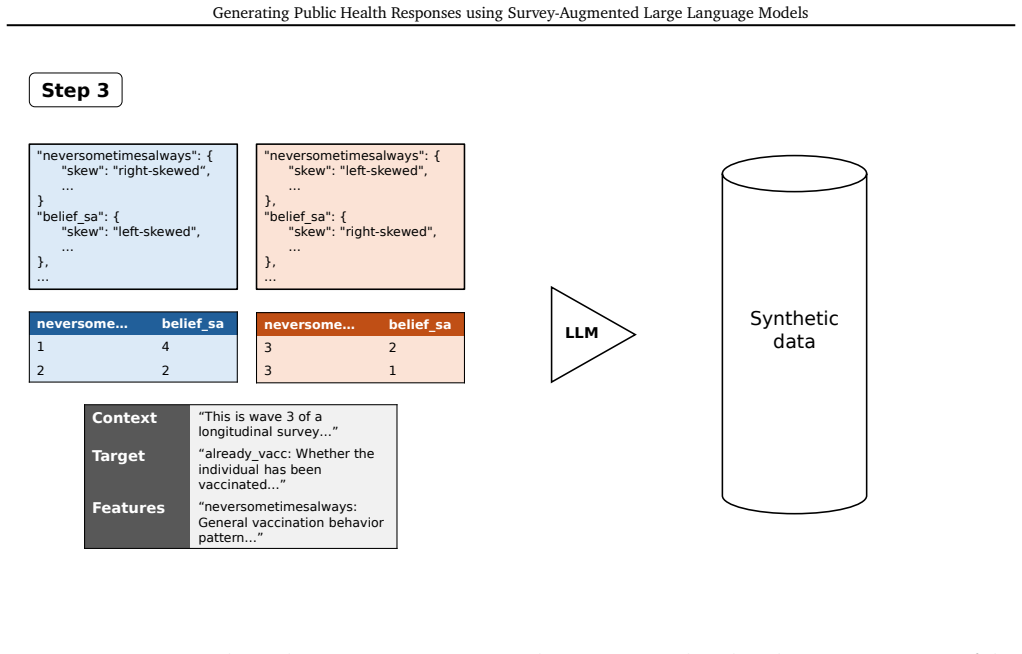
[5]
Generate data for exactly {n_outputs} individuals conforming to the given metadata and examples
-
[6]
Use the provided examples and cluster descriptions to recreate those patterns to the best of your ability
-
[7]
Below we include the first five rows of output of Step 3 for Wave 3
Consider real-world factors, including, but not limited to: vaccine hesitancy, changing attitudes, seasonal patterns, demographics, and health status. Below we include the first five rows of output of Step 3 for Wave 3. calcage gender neversometimesalways belief_xn belief_sa already_vacc cluster prev_cluster 45 2 1 5 4 1 1 1 67 1 1 4 5 1 1 1 29 2 2 3 4 2 ...
2016
-
[8]
A brief demographic/health profile explaining their vaccination tendencies
-
[9]
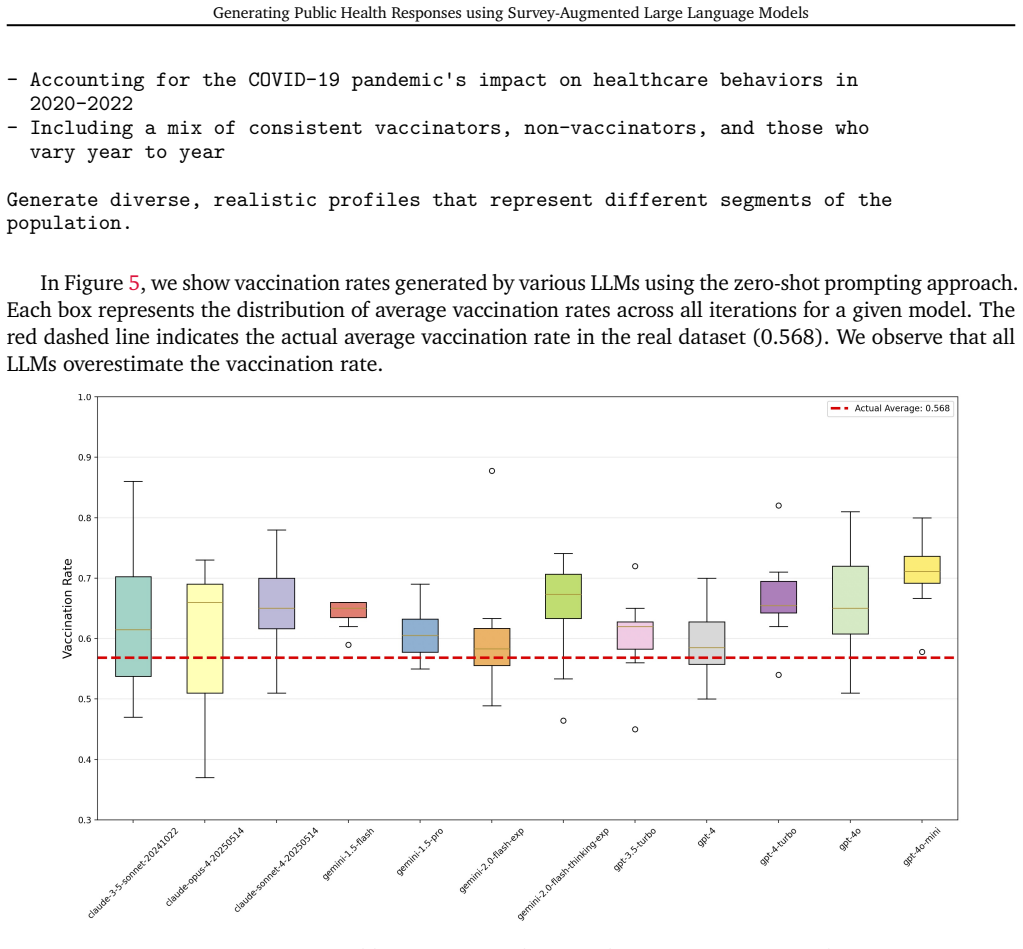
In Figure5, weshowvaccination ratesgenerated by various LLMsusing the zero-shotprompting approach
Vaccination decision for each season (1 = vaccinated, 0 = not vaccinated) Structure your response as follows: Person 1: Profile: [Brief explanation of demographics, health status, and general vaccination tendency - 1-2 sentences] Decisions: 2016-2017: [0 or 1], 2017-2018: [0 or 1], 2018-2019: [0 or 1], 2019-2020: [0 or 1], 2020-2021: [0 or 1], 2021-2022: ...
2016
-
[10]
PARTICIPANT PROFILE: Brief demographic/health profile explaining their vaccination tendencies (1-2 sentences)
-
[11]
VACCINATION DECISIONS: Decision for each season (1 = vaccinated, 0 = not vaccinated) Format: 2016-2017: [0 or 1], 2017-2018: [0 or 1], ..., 2023-2024: [0 or 1]
2016
-
[12]
OVERALL REASONING: Your overall reasoning and justification for the patterns you created
-
[13]
FEW-SHOT INSIGHTS: How the few-shot examples helped you understand vaccination behavior patterns
-
[14]
DECISION INFLUENCE: How the real examples influenced your synthetic data generation decisions
-
[15]
ADDITIONAL DATA NEEDS: What other data you would want in few-shot examples to generate more accurate responses 22 Generating Public Health Responses using Survey-Augmented Large Language Models
-
[16]
Do not simply replicate what you see
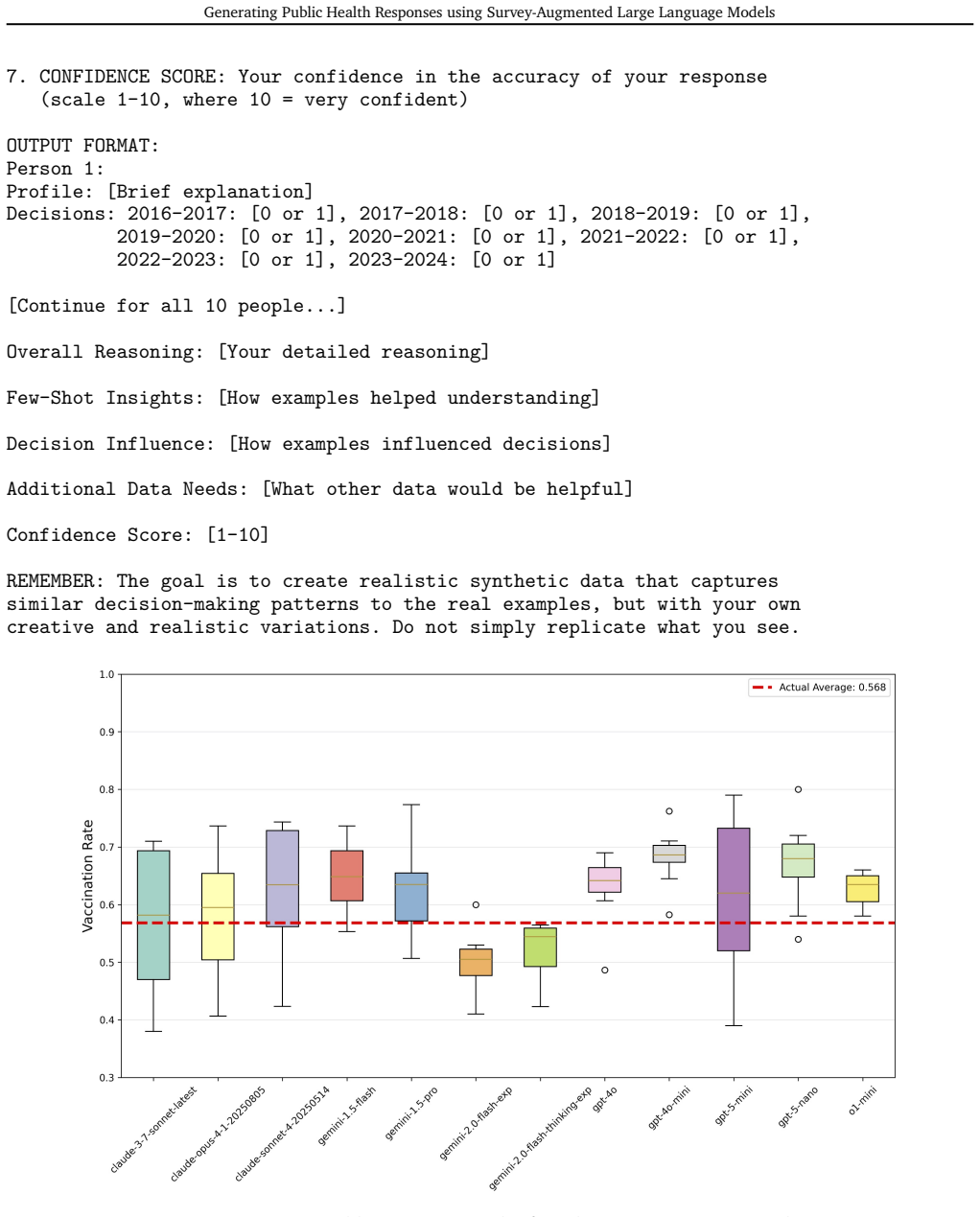
CONFIDENCE SCORE: Your confidence in the accuracy of your response (scale 1-10, where 10 = very confident) OUTPUT FORMAT: Person 1: Profile: [Brief explanation] Decisions: 2016-2017: [0 or 1], 2017-2018: [0 or 1], 2018-2019: [0 or 1], 2019-2020: [0 or 1], 2020-2021: [0 or 1], 2021-2022: [0 or 1], 2022-2023: [0 or 1], 2023-2024: [0 or 1] [Continue for all ...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.