Zero-Shot Vision-Language Models for Classroom Engagement Recognition: A Benchmark Study of Prompt Sensitivity and Cross-Dataset Generalization
Pith reviewed 2026-06-26 12:29 UTC · model grok-4.3
The pith
Zero-shot vision-language models show near-random accuracy, class collapse, and large prompt sensitivity on individual student engagement recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
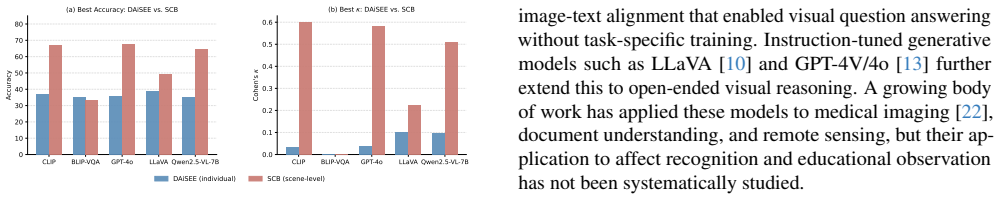
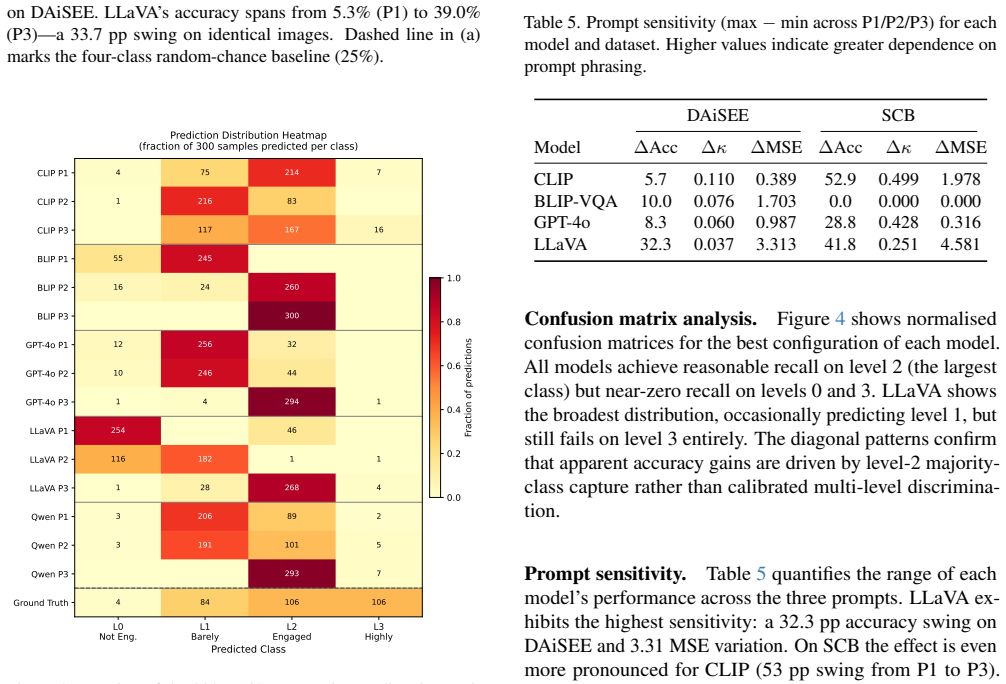
Zero-shot VLMs exhibit three consistent failure modes on individual-student engagement: near-random performance (kappa ≤ 0.10 on DAiSEE), severe class collapse (85-100 percent of predictions to a single level), and extreme prompt sensitivity (accuracy changes up to 32 percentage points on identical images). Scene-level classification on the SCB dataset is more tractable, with CLIP and GPT-4o reaching kappa approximately 0.60 under rubric-anchored prompts.
What carries the argument
The benchmark that applies three prompt variants (minimal, rubric-anchored, chain-of-thought) to five VLMs across the DAiSEE individual-video clips and SCB scene-level images.
Load-bearing premise
The sampled test clips and the SCB labels form representative ground truth for real classroom engagement, and the three prompt styles adequately represent typical zero-shot use.
What would settle it
A fresh set of classroom videos with independently verified engagement labels on which any of the tested VLMs reaches kappa above 0.30 without collapsing to one class or showing large prompt-dependent swings.
Figures

read the original abstract
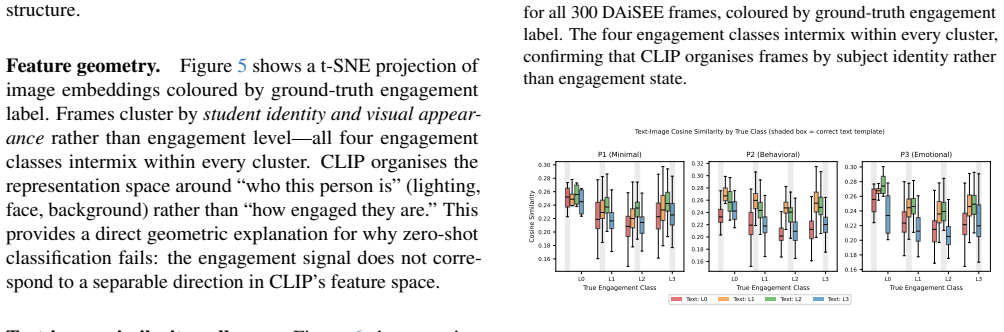
Automated classroom engagement recognition holds substantial promise for scalable learning analytics, yet the suitability of modern Vision-Language Models (VLMs) for this task under zero-shot conditions remains largely unexplored. We present a systematic benchmark that evaluates five widely-used VLMs: CLIP, BLIP-VQA, GPT-4o, LLaVA-1.5-7B, and Qwen2.5VL-7B-Instruct across two complementary educational datasets: DAiSEE, an individual-student video dataset (300 sampled test clips), and the Student Classroom Behaviour dataset (SCB, 1,168 scene-level images). Each model is probed with three prompt variants spanning minimal, rubric-anchored, and chain-of-thought designs. Our experiments reveal three primary failure modes of zero-shot VLMs for engagement recognition: (1) near-random performance on individual students, with Cohen's kappa never exceeding 0.10 on DAiSEE; (2) severe class collapse, where models assign 85-100% of predictions to a single engagement level regardless of visual content; and (3) extreme prompt sensitivity, with accuracy swings of up to 32 percentage points on identical images depending solely on prompt phrasing. Remarkably, scene-level classification on SCB is substantially more tractable: CLIP and GPT-4o achieve kappa approximately 0.60 when prompted with behaviorally-grounded rubrics. We also document a practical barrier for deployment: GPT-4o's safety filters reject 98% of chain-of-thought requests involving individual student faces. Our findings provide a calibrated baseline and surface critical design considerations for the use of VLMs in educational observation systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks five zero-shot VLMs (CLIP, BLIP-VQA, GPT-4o, LLaVA-1.5-7B, Qwen2.5VL-7B-Instruct) for classroom engagement recognition on DAiSEE (300 sampled individual-student video clips) and SCB (1,168 scene-level images). Using three prompt variants (minimal, rubric-anchored, chain-of-thought), it reports three failure modes: Cohen's kappa never exceeding 0.10 on DAiSEE, 85-100% class collapse to one level, and accuracy swings up to 32 points from prompt changes alone. Scene-level SCB yields better results (kappa ~0.60 for CLIP/GPT-4o with rubrics), while GPT-4o safety filters reject 98% of CoT requests on faces.
Significance. If the empirical results hold after addressing data-quality concerns, the work supplies a useful calibrated baseline showing that current zero-shot VLMs are unsuitable for reliable individual-student engagement detection without adaptation, while underscoring prompt sensitivity and deployment barriers such as safety filters. It contributes concrete metrics and failure-mode documentation to the educational-AI literature.
major comments (3)
- [Abstract] Abstract (DAiSEE test set): the central claim of near-random performance (kappa ≤ 0.10) and class collapse rests on 300 sampled clips, yet the manuscript supplies no sampling protocol, stratification by engagement level, or representativeness checks; without these, the reported failure modes cannot be distinguished from selection bias.
- [Abstract] Abstract (ground-truth labels): no inter-rater reliability statistics, label-validation studies, or agreement metrics are provided for DAiSEE or SCB engagement annotations; given that engagement is a low-agreement construct, this directly affects defensibility of all kappa and accuracy figures as measures of model behavior rather than label noise.
- [Abstract] Abstract (prompt variants): the three variants are asserted to cover typical zero-shot usage, but no justification, ablation against alternative rubric or CoT phrasings, or coverage argument is supplied; this weakens the 32-point sensitivity claim as a general property of zero-shot practice.
minor comments (2)
- [Abstract] Abstract: specify whether Cohen's kappa is weighted or unweighted and how the four engagement levels are treated in the multi-class setting.
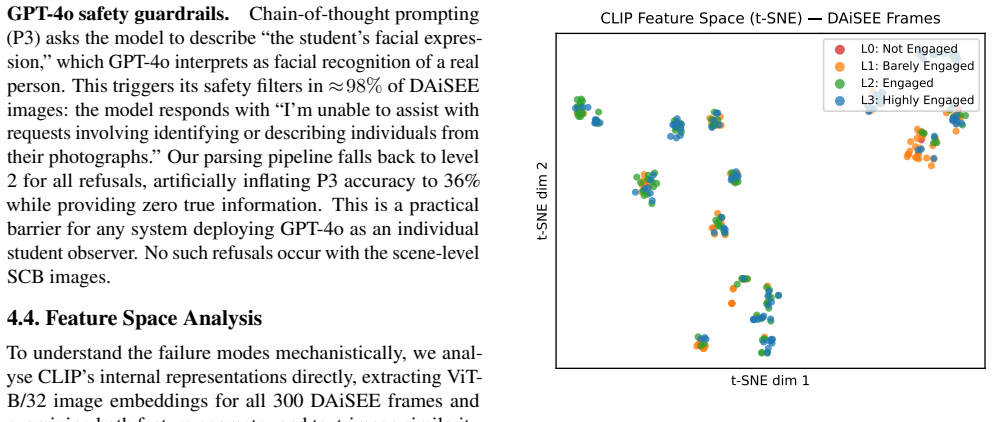
- [Abstract] The safety-filter rejection rate (98%) is reported only for GPT-4o; clarify whether equivalent filtering behavior was observed or tested for the open-source models.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (DAiSEE test set): the central claim of near-random performance (kappa ≤ 0.10) and class collapse rests on 300 sampled clips, yet the manuscript supplies no sampling protocol, stratification by engagement level, or representativeness checks; without these, the reported failure modes cannot be distinguished from selection bias.
Authors: We agree that the absence of an explicit sampling protocol leaves the results open to concerns about selection bias. In the revision we will add a dedicated paragraph describing the sampling procedure: the 300 clips were drawn randomly from the DAiSEE test partition using a fixed seed (42) chosen for reproducibility, with the sample size selected to balance computational cost and statistical power while preserving the original class proportions as closely as possible. We will also report the resulting class distribution and compare it to the full test set. revision: yes
-
Referee: [Abstract] Abstract (ground-truth labels): no inter-rater reliability statistics, label-validation studies, or agreement metrics are provided for DAiSEE or SCB engagement annotations; given that engagement is a low-agreement construct, this directly affects defensibility of all kappa and accuracy figures as measures of model behavior rather than label noise.
Authors: We acknowledge the importance of this point. DAiSEE labels originate from the dataset release and SCB labels were produced by two trained annotators following the rubric described in the paper. We will expand the manuscript to (i) cite any published validation or reliability information available for DAiSEE, (ii) report the inter-annotator agreement obtained during SCB labeling, and (iii) add an explicit limitations paragraph discussing how label noise may affect the interpretation of kappa and accuracy. Because the original annotations are fixed, we cannot retroactively compute new IRR on the full sets, but the added discussion will clarify the scope of our claims. revision: partial
-
Referee: [Abstract] Abstract (prompt variants): the three variants are asserted to cover typical zero-shot usage, but no justification, ablation against alternative rubric or CoT phrasings, or coverage argument is supplied; this weakens the 32-point sensitivity claim as a general property of zero-shot practice.
Authors: The three variants were chosen to span the most common practical approaches observed in the zero-shot VLM literature (minimal instruction, domain-specific rubric, and explicit reasoning steps). We will revise the prompt section to provide explicit justification with supporting citations, state the design rationale for each variant, and note that the observed sensitivity is intended to illustrate the phenomenon rather than to exhaustively map the entire prompt space. While a comprehensive ablation of every possible phrasing is outside the scope of the study, the added text will better contextualize the 32-point swings as evidence of prompt sensitivity in this domain. revision: yes
Circularity Check
No circularity: purely empirical benchmark with external datasets and metrics
full rationale
This paper reports experimental results from probing five VLMs on two external datasets (DAiSEE with 300 sampled clips and SCB with 1,168 images) using three prompt variants and standard metrics (Cohen's kappa, accuracy). No derivations, equations, fitted parameters, or predictions are present; all claims are direct measurements against provided ground-truth labels. No self-citations are load-bearing, and the work contains no mathematical or definitional steps that could reduce to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cohen's kappa and accuracy are appropriate primary metrics for multi-class engagement level prediction.
Reference graph
Works this paper leans on
-
[1]
Ali Abedi and Shehroz S. Khan. Improving state-of-the-art in detecting student engagement with resnet and TCN hybrid network. InProceedings of the 18th Conference on Robots and Vision (CRV), pages 151–157, 2021
2021
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Junyang Wang, Wenbin Ge, Zesen Song, et al. Qwen2.5-VL technical report. InarXiv preprint arXiv:2502.13923, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Fredricks, Phyllis C
Jennifer A. Fredricks, Phyllis C. Blumenfeld, and Alison H. Paris. School engagement: Potential of the concept, state of the evidence.Review of Educational Research, 74(1):59–109, 2004
2004
-
[4]
Abhay Gupta, Arjun D’Cunha, Kamal Awasthi, and Vi- neeth N. Balasubramanian. DAiSEE: Towards user en- gagement recognition in the wild. InarXiv preprint arXiv:1609.01885, 2016
-
[5]
Fine-grained engagement recognition in online learn- ing environment
Tengfei Huang, Yu Mei, Haijun Zhang, Shuai Liu, and Hong Yang. Fine-grained engagement recognition in online learn- ing environment. InProceedings of the IEEE International Conference on Electronics Information and Emergency Com- munication (ICEIEC), pages 338–341, 2019
2019
-
[6]
Prediction and localisation of student engage- ment in the wild
Amanjot Kaur, Arslan Mustafa, Lavisha Mehta, and Abhi- nav Dhall. Prediction and localisation of student engage- ment in the wild. InProceedings of the IEEE International Conference on Digital Image Computing: Techniques and Applications (DICTA), pages 637–644, 2018
2018
-
[7]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data.Biometrics, 33(1): 159–174, 1977
1977
-
[8]
BLIP: Bootstrapping language-image pre-training for unified vision- language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for unified vision- language understanding and generation. InProceedings of the International Conference on Machine Learning (ICML), pages 12888–12900, 2022
2022
-
[9]
Deep facial spa- tiotemporal network for engagement prediction in online learning
Jiaming Liao, Yan Liang, and Jiahui Pan. Deep facial spa- tiotemporal network for engagement prediction in online learning. InApplied Intelligence, pages 6609–6621, 2021
2021
-
[10]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[11]
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pages 8086–8098, 2022
2022
-
[12]
Visual classification via description from large language models
Sachit Menon and Carl V ondrick. Visual classification via description from large language models. InProceedings of the International Conference on Learning Representations (ICLR), 2023
2023
-
[13]
GPT-4o system card
OpenAI. GPT-4o system card. Technical report, OpenAI, 2024
2024
-
[14]
Pianta, Karen M
Robert C. Pianta, Karen M. La Paro, and Bridget K. Hamre. Classroom Assessment Scoring System (CLASS) Manual. Paul H. Brookes Publishing, 2008
2008
-
[15]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the International Conference on Machine Learning (ICML), pages 8748–8763, 2021
2021
-
[16]
Evaluating vision language models in detecting learning en- gagement
Jayant Teotia, Xulang Zhang, Rui Mao, and Erik Cambria. Evaluating vision language models in detecting learning en- gagement. InProc. IEEE International Conference on Data Mining Workshops (ICDMW), pages 496–502, Abu Dhabi, UAE, 2024
2024
-
[17]
Predicting stu- dent engagement in classrooms using facial behavioral cues
Clinton Thomas and Dinesh Babu Jayagopi. Predicting stu- dent engagement in classrooms using facial behavioral cues. InProceedings of the 1st ACM SIGCHI International Work- shop on Multimodal Interaction for Education (MIE), pages 33–40, 2017
2017
-
[18]
Student classroom behaviour real-time detection based on YOLOv5 and identity recognition
Junjie Wang, Sisi Jiang, Kedi Wang, and Mingjie Li. Student classroom behaviour real-time detection based on YOLOv5 and identity recognition. InSystems and Soft Computing, page 200058. Elsevier, 2023
2023
-
[19]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large lan- guage models. InAdvances in Neural Information Processing Systems (NeurIPS), pages 24824–24837, 2022
2022
-
[20]
Movellan
Jacob Whitehill, Zewelanji Serpell, Yi-Ching Lin, Aysha Fos- ter, and Javier R. Movellan. The faces of engagement: Auto- matic recognition of student engagementfrom facial expres- sions. InIEEE Transactions on Affective Computing, pages 86–98, 2014
2014
-
[21]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chau- mond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R ´emi Louf, Morgan Funtowicz, Joe Brew, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Trans- formers: State-of-the-art natural language processing. In Proceedings of the 2020 ...
2020
-
[22]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Jaspreet Bagga, Robert Mason, Trista Shi, Tristan Naumann, Cliff Bernard, Robin Gallo, Brian Piening, Frederick A. Matsen IV , Masoud Rouhizadeh, Wei Wei, Stephen Snider, and Hoifung Poon. Large-scale domain-specific pretraining for biomedical vision- language processing. InarXiv preprint arXiv:2303.00915, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh
Tony Z. Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate before use: Improving few-shot performance of language models. InProceedings of the International Con- ference on Machine Learning (ICML), pages 12697–12706, 2021. 8 Zero-Shot Vision-Language Models for Classroom Engagement Recognition: A Benchmark Study of Prompt Sensitivity and...
2021
-
[24]
Full Prompt Texts This supplementary provides the exact prompt text used for each model and dataset in our zero-shot benchmark, enabling full reproducibility. 7.1. SCB Dataset | GPT-4o, LLaV A-1.5, and Qwen2.5-VL-7B These prompts were applied to the scene-level SCB images for GPT-4o, LLaV A-1.5, and Qwen2.5-VL-7B. Each image was submitted directly; the mo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.