Holmes: Multimodal Agentic Diagnosis for Mixed-Language Mobile Crashes at Industrial Scale
Pith reviewed 2026-06-26 11:58 UTC · model grok-4.3
The pith
Holmes uses a hierarchical multi-agent system to localize faults in mobile crashes at 87.6% accuracy by synthesizing multimodal runtime signals without reproduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
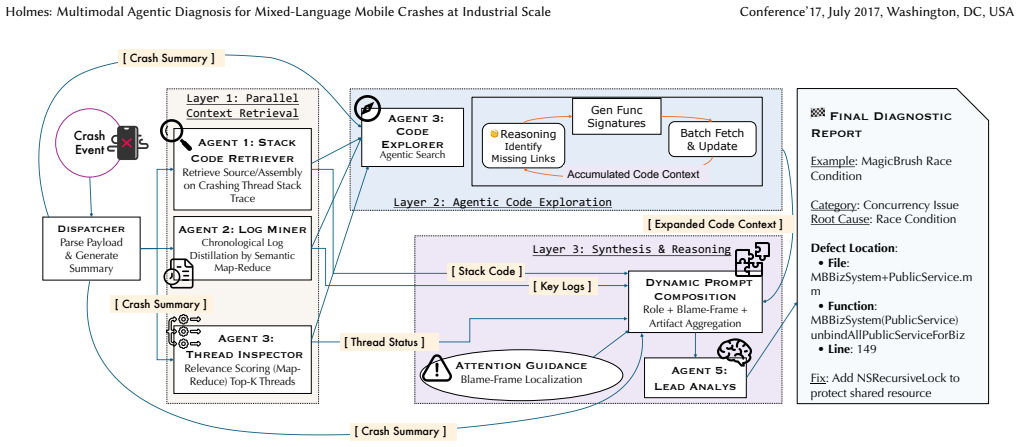
Holmes is a multi-agent system that automates root cause analysis for mobile crashes by reconstructing failure contexts from multimodal runtime signals without reproduction. Its hierarchical Retrieve-Explore-Reason architecture leverages low-level artifacts to bridge the semantic gap between open-source business logic and closed-source system frameworks, dynamically compressing the search space to navigate 70-million-line mixed-language codebases and identify non-local defects.
What carries the argument
The hierarchical Retrieve-Explore-Reason architecture that uses runtime clues and low-level artifacts to bridge semantic gaps and compress the search space.
If this is right
- Diagnosis becomes possible in post-mortem scenarios where reproduction is unavailable.
- Non-local defects become identifiable in mixed-language codebases that exceed traditional static analysis limits.
- Investigation time drops from hours to roughly 77 seconds on average.
- Debugging shifts from labor-intensive search to verification of agent outputs.
Where Pith is reading between the lines
- Similar agent architectures could apply to post-mortem analysis in other large-scale systems where partial code access is the norm.
- Low-level hardware signals may prove useful for resolving mismatches in other layered software stacks beyond mobile.
- Teams could reallocate effort from trace inspection to hypothesis checking if the accuracy holds across more crash types.
Load-bearing premise
The Retrieve-Explore-Reason architecture can reliably map low-level artifacts to the correct business logic across open-source and closed-source code without reproduction.
What would settle it
A set of real crashes where the system returns an incorrect function-level location while human experts using the same multimodal signals reach a different conclusion.
Figures
read the original abstract
Diagnosing mobile crashes in ultra-large-scale industrial applications is a formidable challenge due to the sheer volume of code, the complexity of mixed-language environments, and the inability to reproduce failures locally. Traditional static analysis struggles with scalability, while existing LLM-based agents often rely on reproducible environments unavailable in post-mortem scenarios. We present Holmes, a multi-agent system that automates root cause analysis by synthesizing multimodal runtime signals--stack traces, logs, and thread states--to reconstruct failure contexts without reproduction. Holmes introduces a hierarchical Retrieve-Explore-Reason architecture that leverages low-level artifacts (e.g., registers, assembly) to bridge the semantic gap between open-source business logic and closed-source system frameworks. By dynamically compressing the search space using runtime clues, Holmes precisely navigates 70-million-line codebases to identify non-local defects. Evaluated on real-world crashes from WeChat, Holmes achieves 87.6% accuracy in function-level fault localization and reduces average investigation time by over 98% (to ~77 seconds), demonstrating its effectiveness in transforming labor-intensive debugging into an efficient verification workflow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Holmes, a multi-agent system for post-mortem root-cause analysis of mobile crashes in ultra-large mixed-language codebases (e.g., 70 MLOC WeChat). It introduces a hierarchical Retrieve-Explore-Reason architecture that synthesizes multimodal runtime signals (stack traces, logs, thread states, registers, assembly) to localize non-local defects without reproduction, claiming 87.6% function-level fault-localization accuracy and >98% reduction in average investigation time (to ~77 s) on real WeChat crashes.
Significance. If the empirical claims are substantiated with transparent methodology, the work would be significant for industrial-scale debugging: it addresses a genuine pain point (non-reproducible crashes in closed-source frameworks) at a scale and with a time reduction that could materially change practice. The explicit use of low-level artifacts to bridge open/closed-source gaps is a concrete technical contribution worth evaluating.
major comments (2)
- [Evaluation] Evaluation section: the central claims of 87.6% function-level accuracy and 98% time reduction are presented without any description of dataset size, crash selection criteria, ground-truth labeling process, inter-annotator agreement, baselines, statistical tests, or error bars. These omissions make the quantitative results unverifiable and directly load-bearing for the paper's contribution.
- [§3] Architecture / §3 (Retrieve-Explore-Reason): the claim that low-level artifacts (registers, assembly) successfully bridge open-source business logic to closed-source system frameworks is central, yet no ablation isolates their contribution, no breakdown of closed-source vs. open-source root causes is given, and no failure cases (e.g., missing symbols, defects several frames removed) are quantified. Without these, the 87.6% figure cannot be assessed.
minor comments (2)
- The manuscript should state the total number of crashes processed and the fraction that are closed-source to allow readers to judge the scope of the bridging claim.
- Figure and table captions should explicitly define all metrics (e.g., what constitutes a "function-level" localization success) rather than assuming domain familiarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify areas where additional methodological transparency is needed to substantiate the central claims. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central claims of 87.6% function-level accuracy and 98% time reduction are presented without any description of dataset size, crash selection criteria, ground-truth labeling process, inter-annotator agreement, baselines, statistical tests, or error bars. These omissions make the quantitative results unverifiable and directly load-bearing for the paper's contribution.
Authors: We agree that the current manuscript does not provide sufficient detail on the evaluation methodology, which limits verifiability of the reported figures. In the revised version we will add a dedicated subsection in the Evaluation section that specifies the dataset size and selection criteria for the WeChat crashes, the ground-truth labeling process, inter-annotator agreement, the baselines employed, the statistical tests performed, and error bars. This will be done while respecting the proprietary constraints that prevent public release of the raw data. revision: yes
-
Referee: [§3] Architecture / §3 (Retrieve-Explore-Reason): the claim that low-level artifacts (registers, assembly) successfully bridge open-source business logic to closed-source system frameworks is central, yet no ablation isolates their contribution, no breakdown of closed-source vs. open-source root causes is given, and no failure cases (e.g., missing symbols, defects several frames removed) are quantified. Without these, the 87.6% figure cannot be assessed.
Authors: We concur that the manuscript would be strengthened by explicit ablations and breakdowns supporting the role of low-level artifacts. In the revision we will add an ablation study isolating the contribution of registers and assembly, a quantitative breakdown of root causes in open-source versus closed-source components, and a quantified analysis of failure cases including missing symbols and defects several frames removed. These additions will be placed in §3 and the Evaluation section. revision: yes
Circularity Check
No circularity; system and evaluation are independent of fitted inputs or self-referential definitions.
full rationale
The paper introduces Holmes as a new multi-agent architecture evaluated empirically on external real-world WeChat crash data, reporting accuracy and time metrics without any equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central claims to prior author work by construction. The Retrieve-Explore-Reason hierarchy is presented as a novel contribution rather than derived from or equivalent to its own inputs. No patterns matching self-definitional, fitted-input, or ansatz-smuggling criteria appear in the abstract or described claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
van Gemund
Rui Abreu, Peter Zoeteweij, and Arjan J.C. van Gemund. 2007. On the Accuracy of Spectrum-based Fault Localization. InTesting: Academic and Industrial Conference Practice and Research Techniques - MUTATION (TAICPART-MUTATION 2007). 89–
2007
-
[2]
doi:10.1109/TAIC.PART.2007.13
-
[3]
C, Arun Iyer, Suresh Parthasarathy, Sriram Rajamani, B
Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Vageesh D. C, Arun Iyer, Suresh Parthasarathy, Sriram Rajamani, B. Ashok, and Shashank Shet. 2023. CodePlan: Repository-level Coding Using LLMs and Planning.arXiv preprint arXiv:2309.12499(2023). https://arxiv.org/abs/2309.12499
arXiv 2023
-
[4]
Cristiano Calcagno, Dino Distefano, Jeremy Dubreil, Dominik Gabi, Pieter Hooimeijer, Martino Luca, Peter O’Hearn, Irene Papakonstantinou, Jim Pur- brick, and Dulma Rodriguez. 2015. Moving Fast with Software Verification. In NASA Formal Methods. Springer International Publishing, Cham, 3–11
2015
-
[5]
Zhaoling Chen, Robert Tang, Gangda Deng, Fang Wu, Jialong Wu, Zhiwei Jiang, Viktor Prasanna, Arman Cohan, and Xingyao Wang. 2025. LocAgent: Graph- Guided LLM Agents for Code Localization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Aus...
2025
-
[6]
Yingnong Dang, Rongxin Wu, Hongyu Zhang, Dongmei Zhang, and Peter Nobel
-
[7]
In2012 34th International Conference on Software Engineering (ICSE)
ReBucket: A method for clustering duplicate crash reports based on call stack similarity. In2012 34th International Conference on Software Engineering (ICSE). 1084–1093. doi:10.1109/ICSE.2012.6227111
-
[8]
S. M. Farah Al Fahim, Md Nakhla Rafi, Zeyang Ma, Dong Jae Kim, Tse-Hsun, and Chen. 2025. Crash Report Enhancement with Large Language Models: An Empirical Study.arXiv preprint arXiv:2509.13535(2025). https://arxiv.org/abs/ 2509.13535
arXiv 2025
-
[9]
Wei Guan, Jian Cao, Shiyou Qian, Jianqi Gao, and Chun Ouyang. 2025. LogLLM: Log-based Anomaly Detection Using Large Language Models.arXiv preprint arXiv:2411.08561(2025). https://arxiv.org/abs/2411.08561
arXiv 2025
-
[10]
Haoyu Han, Yu Wang, Harry Shomer, Kai Guo, Jiayuan Ding, Yongjia Lei, Ma- hantesh Halappanavar, Ryan A. Rossi, Subhabrata Mukherjee, Xianfeng Tang, Qi He, Zhigang Hua, Bo Long, Tong Zhao, Neil Shah, Amin Javari, Yinglong Xia, and Jiliang Tang. 2025. Retrieval-Augmented Generation with Graphs (GraphRAG). arXiv preprint arXiv:2501.00309(2025). https://arxiv...
Pith/arXiv arXiv 2025
-
[11]
Minghua He, Tong Jia, Chiming Duan, Pei Xiao, Lingzhe Zhang, Kangjin Wang, Yifan Wu, Ying Li, and Gang Huang. 2025. Walk the Talk: Is Your Log- based Software Reliability Maintenance System Really Reliable?arXiv preprint arXiv:2509.24352(2025). https://arxiv.org/abs/2509.24352
arXiv 2025
-
[12]
Empirical evaluation of the Tarantula automatic fault-localization technique,
James A. Jones and Mary Jean Harrold. 2005. Empirical evaluation of the tarantula automatic fault-localization technique. InProceedings of the 20th IEEE/ACM Inter- national Conference on Automated Software Engineering (ASE ’05). Association for Computing Machinery, 273–282. doi:10.1145/1101908.1101949
-
[13]
Van-Hoang Le and Hongyu Zhang. 2023. Log Parsing with Prompt-based Few- shot Learning. In2023 IEEE/ACM 45th International Conference on Software Engi- neering (ICSE). 2438–2449. doi:10.1109/ICSE48619.2023.00204
-
[14]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th International Conference on Neural Information Processing Systems (NI...
2020
-
[15]
Weibin Meng, Ying Liu, Yichen Zhu, Shenglin Zhang, Dan Pei, Yuqing Liu, Yihao Chen, Ruizhi Zhang, Shimin Tao, Pei Sun, and Rong Zhou. 2019. Loganomaly: unsupervised detection of sequential and quantitative anomalies in unstruc- tured logs. InProceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI’19). AAAI Press, 4739–4745
2019
-
[16]
Siru Ouyang, Wenhao Yu, Kaixin Ma, Zilin Xiao, Zhihan Zhang, Mengzhao Jia, Jiawei Han, Hongming Zhang, and Dong Yu. 2025. RepoGraph: Enhancing AI Software Engineering with Repository-level Code Graph.arXiv preprint arXiv:2410.14684(2025). https://arxiv.org/abs/2410.14684
arXiv 2025
-
[17]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for A...
Pith/arXiv arXiv 2025
-
[18]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agent- less: Demystifying LLM-based Software Engineering Agents.arXiv preprint arXiv:2407.01489(2024). https://arxiv.org/abs/2407.01489
Pith/arXiv arXiv 2024
-
[19]
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-computer In- terfaces Enable Automated Software Engineering. InAdvances in Neural In- formation Processing Systems, Vol. 37. Curran Associates, Inc., 50528–50652. doi:10.52202/079017-1601
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.