Lexical Consensus: Grounded Word Learning and Shared Meaning in Artificial Agents
Pith reviewed 2026-06-26 11:37 UTC · model grok-4.3
The pith
Artificial agents acquire grounded word meanings according to a perceptual-coherence gradient set by visual embedding geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
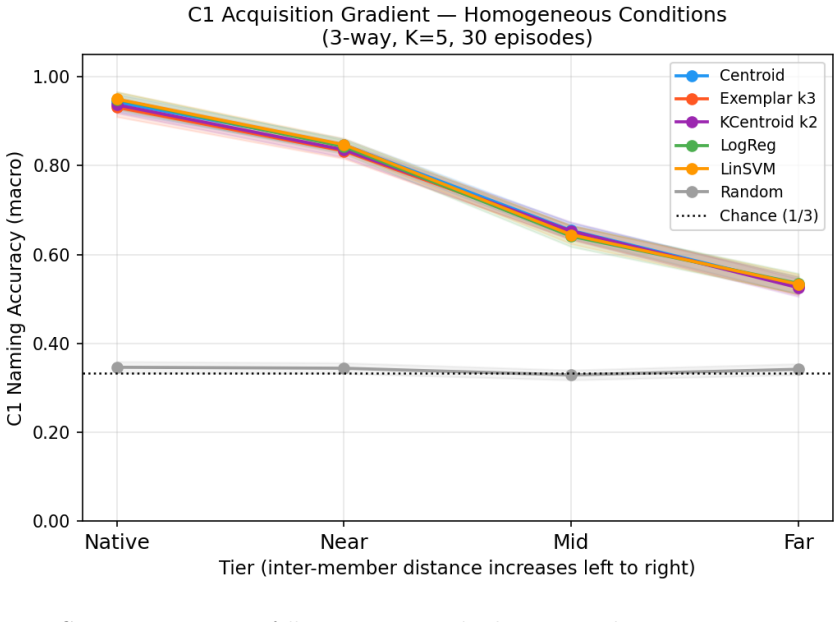
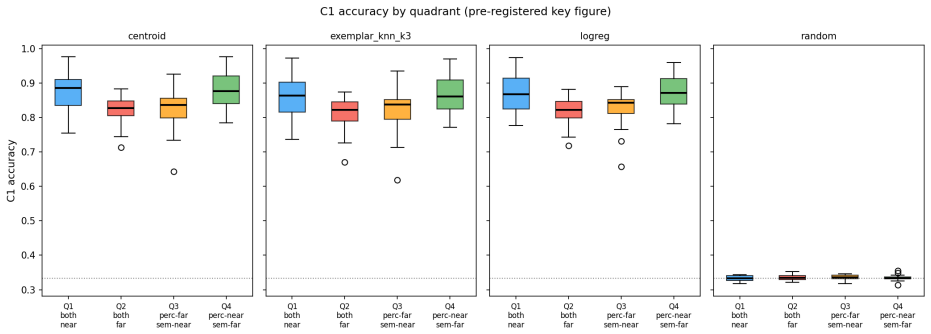
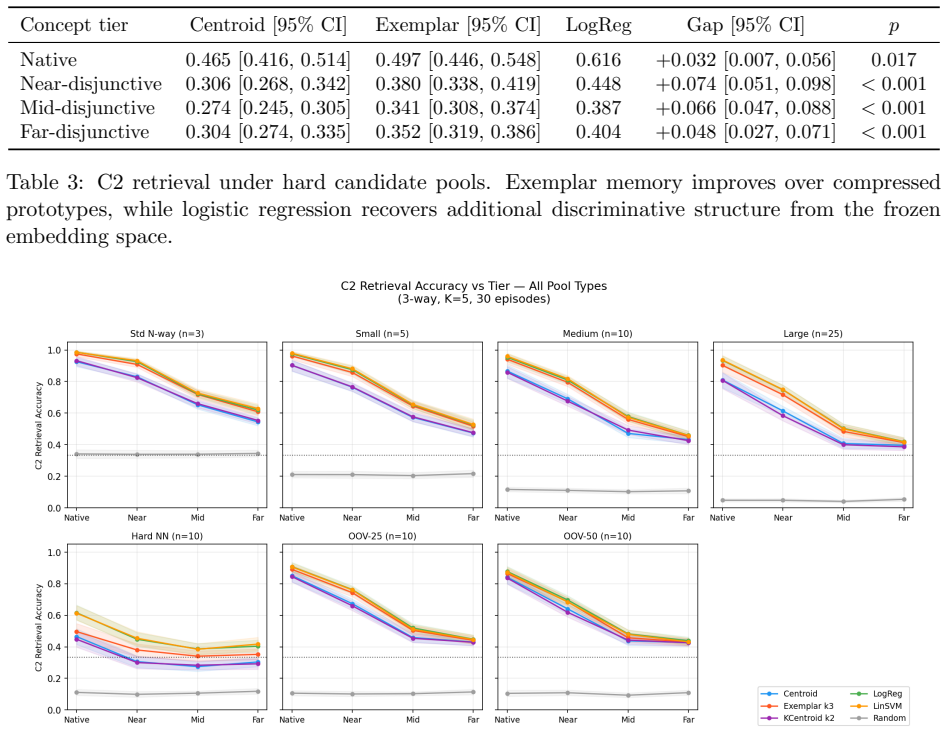
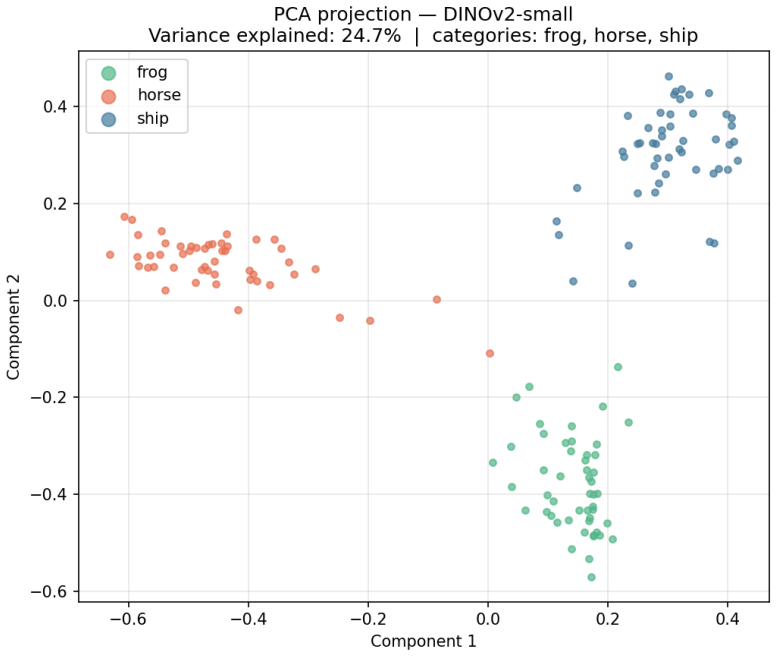
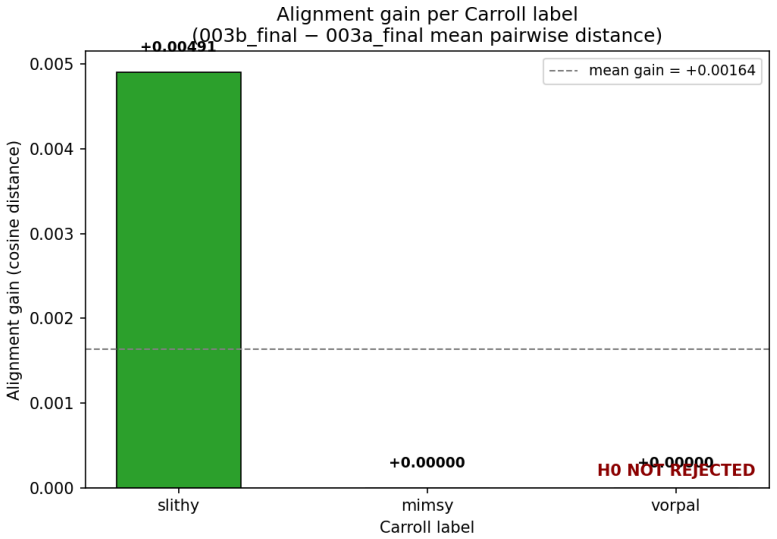
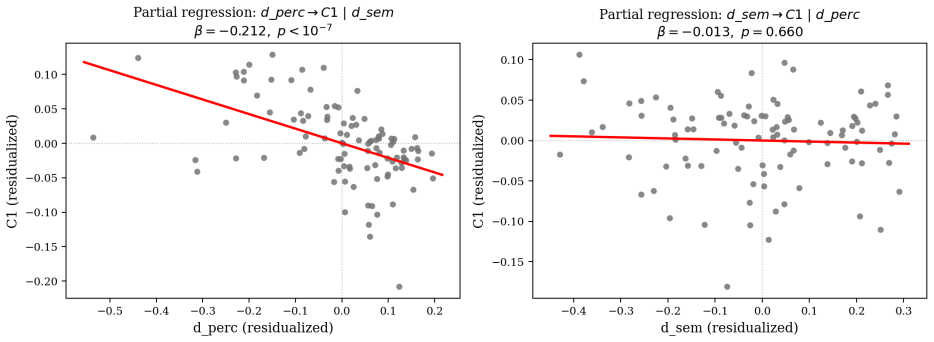
Agents learn artificial visual labels along a perceptual-coherence gradient in which native categories are acquired most readily, coherent overextensions remain learnable, mid-range disjunctives degrade, and far-disjunctive concepts approach chance performance; this gradient is driven by perceptual distance in the embedding space rather than semantic relatedness, as confirmed by partial R-squared values of 0.245 versus 0.002 in the CIFAR-100 dissociation test.
What carries the argument
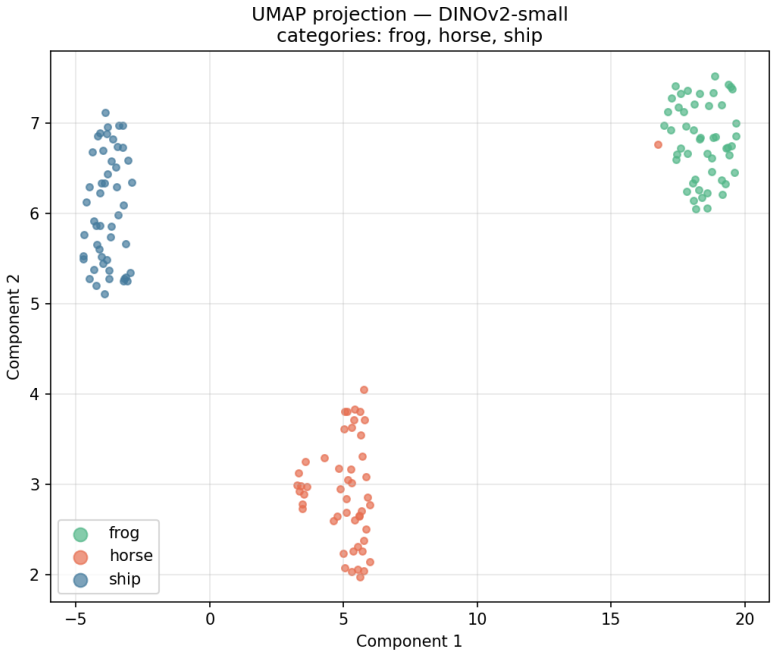
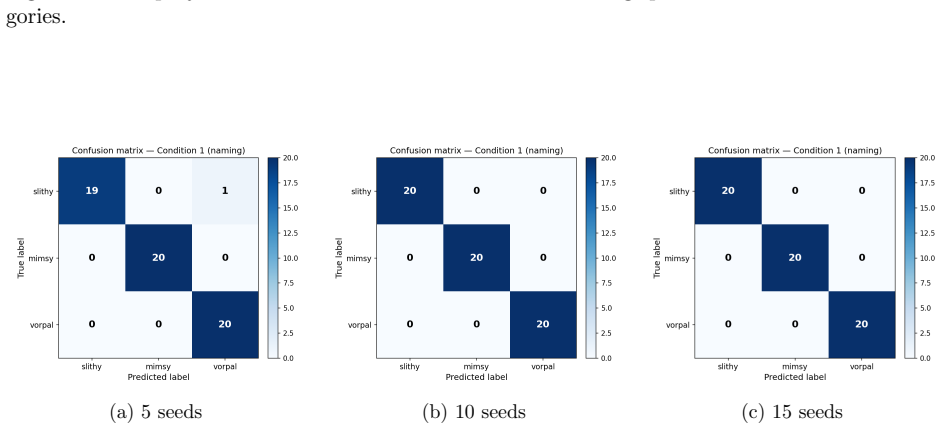
Lexical Consensus framework, which uses frozen DINOv2 visual embeddings as the perceptual substrate, Carroll-style nonce words as labels, and bidirectional naming/retrieval tasks with linear and exemplar-based learners to isolate grounded lexical acquisition.
If this is right
- Native and perceptually coherent categories reach high acquisition accuracy while far-disjunctive ones remain near chance.
- Perceptual distance accounts for 24.5 percent of variance in learning outcomes after controlling for other factors.
- Semantic distance contributes no detectable additional explanatory power once perceptual distance is included.
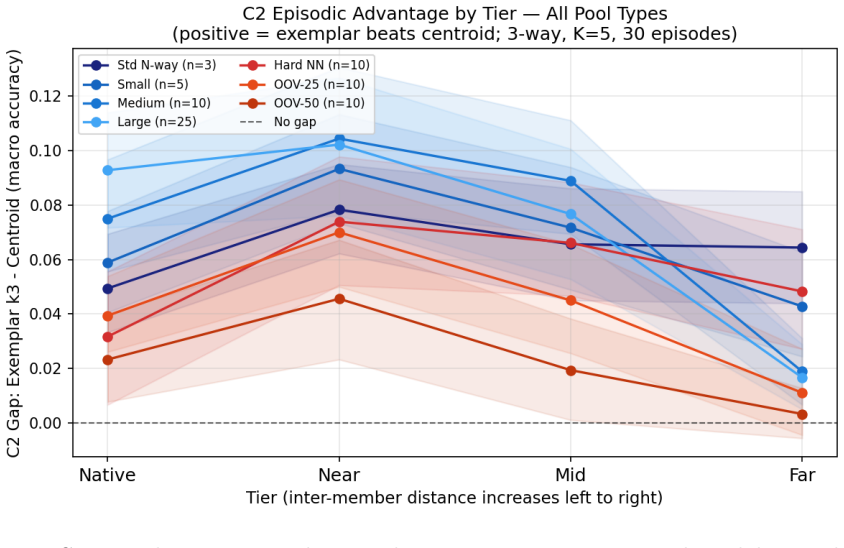
- Exemplar-based mechanisms outperform centroid prototypes specifically in label-to-image retrieval.
- Frozen perceptual geometry enables initial grounding but prevents acquisition of concepts outside its natural clusters without adaptation.
Where Pith is reading between the lines
- Multi-agent systems would need aligned perceptual geometries to reach stable shared lexicons on the same visual inputs.
- The framework could be used to test whether fine-tuning the embedding layer allows agents to learn previously unlearnable disjunctive concepts.
- Current large vision-language models may inherit similar limits on which novel word meanings they can ground without updating their visual representations.
Load-bearing premise
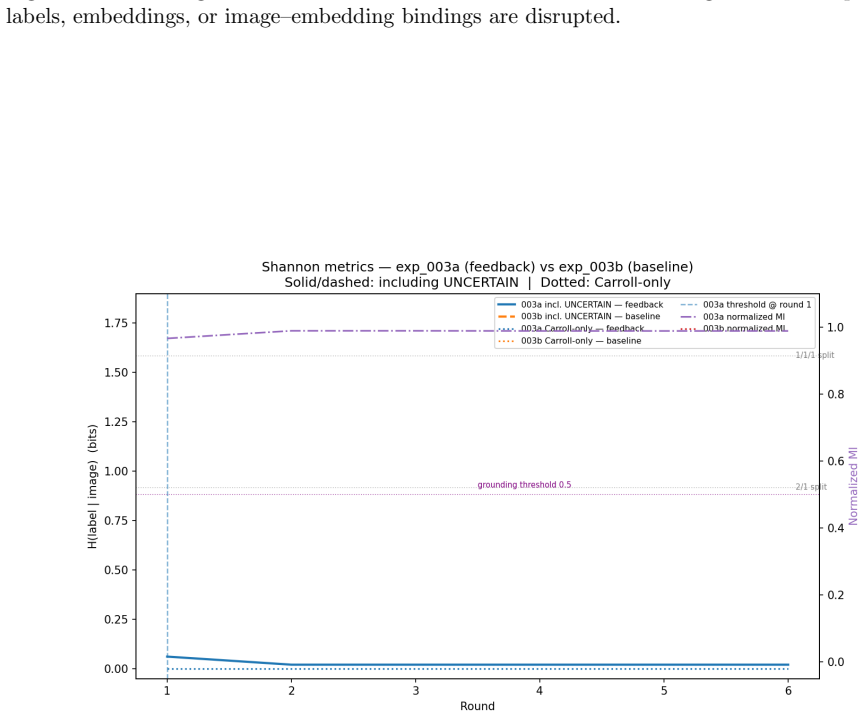
Frozen DINOv2 embeddings supply a fixed, representative geometry for the tested visual concepts so that observed learning differences reflect properties of that geometry rather than model-specific artifacts.
What would settle it
Re-running the dissociation experiment with a different visual embedding model on the same CIFAR-100 concepts and finding that semantic distance then predicts accuracy better than perceptual distance would falsify the claim that the gradient is governed by perceptual geometry.
Figures

read the original abstract
Artificial intelligence systems are commonly evaluated through task performance and behavioral imitation, but such evaluations leave open whether an artificial agent can acquire, stabilize, and use new lexical meanings from grounded experience. This paper introduces Lexical Consensus, an experimental framework for studying grounded word learning over a structured perceptual substrate. Using frozen DINOv2 visual embeddings, Carroll-style nonce words, and interpretable lexical learners plus linear baselines, we test whether agents can acquire artificial labels for visual concepts, generalize them bidirectionally, and stabilize them across controlled settings. The main result is a robust perceptual-coherence gradient: native categories are easiest to learn, coherent overextensions remain learnable, mid-range disjunctive concepts degrade, and far-disjunctive concepts approach chance. A pre-registered CIFAR-100 dissociation experiment confirms that this gradient is governed by perceptual distance rather than semantic relatedness: perceptual distance predicts acquisition accuracy (partial R^2 = 0.245, p < 1e-7), while semantic distance adds no significant explanatory power (partial R^2 = 0.002, p = 0.660). Bidirectional evaluation shows that naming and retrieval are distinct: exemplar-based mechanisms outperform centroid prototypes in label-to-image retrieval, exposing a memory-fidelity dimension separate from naming accuracy. Falsification controls, homogeneous candidate-pool evaluations, and null results on representational restructuring indicate that frozen perceptual geometry both enables lexical grounding and limits what can be acquired without representational adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Lexical Consensus framework for studying grounded word learning in artificial agents. Using frozen DINOv2 visual embeddings, nonce words, and lexical learners, it reports a perceptual-coherence gradient (native categories easiest, far-disjunctive near chance) and a pre-registered CIFAR-100 dissociation experiment in which perceptual distance predicts acquisition accuracy (partial R² = 0.245, p < 1e-7) while semantic distance adds none (partial R² = 0.002, p = 0.660). The work concludes that frozen perceptual geometry both enables and limits lexical grounding without representational adaptation, supported by bidirectional naming/retrieval tests and falsification controls.
Significance. If the results hold, the pre-registered dissociation experiment with partial R-squared values and p-values, together with falsification controls and null results on restructuring, supplies direct statistical evidence that perceptual structure governs lexical acquisition independently of semantic relatedness. This strengthens empirical grounding for claims about the enabling and limiting role of frozen perceptual geometries in artificial lexical learning.
major comments (1)
- [CIFAR-100 dissociation experiment] The dissociation result and the claim that frozen DINOv2 geometry governs the gradient (abstract and dissociation experiment section) rest on the assumption that DINOv2 distances provide an unconfounded perceptual measure. Because DINOv2 is pre-trained on large-scale image data that may correlate with CIFAR-100 super-categories, the partial-R² contrast could arise from how the two distance matrices are constructed rather than from genuine perceptual vs semantic separation; an explicit orthogonality test or replication with alternative embeddings is required to secure this load-bearing step.
minor comments (2)
- [Abstract] The abstract supplies only high-level method descriptions without full protocols, data splits, or error-bar details, which limits immediate reproducibility assessment.
- [Methods] Clarify the exact operationalization of perceptual and semantic distance matrices and the regression model specification used for the partial R² calculations.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the dissociation experiment. The concern about potential confounds in the DINOv2 distance measure is substantive and directly relevant to the load-bearing claim. We address it point-by-point below and commit to revisions that strengthen the result without altering the core findings.
read point-by-point responses
-
Referee: [CIFAR-100 dissociation experiment] The dissociation result and the claim that frozen DINOv2 geometry governs the gradient (abstract and dissociation experiment section) rest on the assumption that DINOv2 distances provide an unconfounded perceptual measure. Because DINOv2 is pre-trained on large-scale image data that may correlate with CIFAR-100 super-categories, the partial-R² contrast could arise from how the two distance matrices are constructed rather than from genuine perceptual vs semantic separation; an explicit orthogonality test or replication with alternative embeddings is required to secure this load-bearing step.
Authors: We agree that an explicit check on the independence of the two distance matrices is necessary to rule out construction artifacts. DINOv2 is trained self-supervised on unlabeled images, so its geometry reflects visual feature similarity rather than category labels; the semantic distance matrix is derived separately from WordNet super-category structure. Nevertheless, to directly test whether the partial-R² dissociation could be an artifact of matrix construction, we will add an orthogonality analysis in the revised manuscript: we will report the Pearson correlation between the DINOv2 perceptual distance matrix and the semantic distance matrix across the CIFAR-100 stimuli. A low correlation would confirm that the two predictors are not redundant and that the unique variance captured by perceptual distance is genuine. Should the correlation prove substantial, we will discuss the implication and, if needed, replicate the dissociation using an alternative visual embedding (e.g., a ResNet trained on a disjoint dataset). This addition will be placed in the dissociation experiment section and referenced in the abstract. revision: yes
Circularity Check
No circularity; central claims are direct empirical measurements from pre-registered tests
full rationale
The paper reports experimental results on lexical acquisition using frozen DINOv2 embeddings, nonce labels, and statistical dissociation (partial R^2 values and p-values) between perceptual and semantic distances on CIFAR-100. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing steps; the perceptual-coherence gradient and bidirectional naming/retrieval findings are measured outcomes rather than quantities defined in terms of themselves or prior author work. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions for partial R-squared calculations and p-value interpretation in multiple regression hold for the dissociation analysis.
Reference graph
Works this paper leans on
-
[1]
2023 , eprint =
Rethinking the Evaluating Framework for Natural Language Understanding in AI Systems: Language Acquisition as a Core for Future Metrics , author =. 2023 , eprint =
2023
-
[2]
1871 , publisher =
Through the Looking-Glass, and What Alice Found There , author =. 1871 , publisher =
-
[3]
2023 , eprint =
Oquab, Maxime and Darcet, Timoth. 2023 , eprint =
2023
-
[4]
Mind , volume =
Computing Machinery and Intelligence , author =. Mind , volume =. 1950 , doi =
1950
-
[5]
Artificial Intelligence Review , volume =
Evaluation in Artificial Intelligence: From Task-Oriented to Ability-Oriented Measurement , author =. Artificial Intelligence Review , volume =. 2017 , doi =
2017
-
[6]
arXiv preprint arXiv:1911.01547 , year =
On the Measure of Intelligence , author =. arXiv preprint arXiv:1911.01547 , year =. 1911.01547 , archivePrefix =
Pith/arXiv arXiv 1911
-
[7]
Physica D: Nonlinear Phenomena , volume =
The Symbol Grounding Problem , author =. Physica D: Nonlinear Phenomena , volume =. 1990 , doi =
1990
-
[8]
Bender, Emily M. and Koller, Alexander , booktitle =. Climbing towards. 2020 , publisher =. doi:10.18653/v1/2020.acl-main.463 , url =
-
[9]
Experience Grounds Language , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2020 , publisher =. doi:10.18653/v1/2020.emnlp-main.703 , url =
-
[10]
1969 , publisher =
Convention: A Philosophical Study , author =. 1969 , publisher =
1969
-
[11]
Artificial Life , volume =
A Self-Organizing Spatial Vocabulary , author =. Artificial Life , volume =. 1995 , doi =
1995
-
[12]
The Talking Heads Experiment: Origins of Words and Meanings , author =. 2015 , publisher =. doi:10.17169/FUDOCS_document_000000022455 , url =
-
[13]
Journal of Statistical Mechanics: Theory and Experiment , volume =
Sharp Transition towards Shared Vocabularies in Multi-Agent Systems , author =. Journal of Statistical Mechanics: Theory and Experiment , volume =. 2006 , doi =
2006
-
[14]
2016 , eprint =
Multi-Agent Cooperation and the Emergence of (Natural) Language , author =. 2016 , eprint =
2016
-
[15]
International Conference on Learning Representations , year =
Emergence of Linguistic Communication from Referential Games with Symbolic and Pixel Input , author =. International Conference on Learning Representations , year =. 1804.03984 , archivePrefix =
-
[16]
Advances in Neural Information Processing Systems , volume =
Emergence of Language with Multi-Agent Games: Learning to Communicate with Sequences of Symbols , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
2017
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Emergence of Grounded Compositional Language in Multi-Agent Populations , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2018 , doi =
2018
-
[18]
Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages =
Natural Language Does Not Emerge `Naturally' in Multi-Agent Dialog , author =. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages =. 2017 , publisher =. doi:10.18653/v1/D17-1321 , url =
-
[19]
Proceedings of the 36th International Conference on Machine Learning , pages =
Similarity of Neural Network Representations Revisited , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , volume =
2019
-
[20]
arXiv preprint arXiv:1808.10696 , year =
How Agents See Things: On Visual Representations in an Emergent Language Game , author =. arXiv preprint arXiv:1808.10696 , year =. 1808.10696 , archivePrefix =
-
[21]
Advances in Neural Information Processing Systems , volume =
Matching Networks for One Shot Learning , author =. Advances in Neural Information Processing Systems , volume =. 2016 , url =
2016
-
[22]
Advances in Neural Information Processing Systems , volume =
Prototypical Networks for Few-shot Learning , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
2017
-
[23]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , volume =
2021
-
[24]
2009 , institution=
Learning multiple layers of features from tiny images , author=. 2009 , institution=
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.