Sequential Minimal Optimization Algorithm for One-Class Support Vector Machines With Privileged Information
Pith reviewed 2026-06-26 11:57 UTC · model grok-4.3
The pith
An SMO algorithm for one-class SVM with privileged information converges in finite time and trains faster than interior-point solvers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present an SMO algorithm for the dual of the OC-SVM+ problem that selects and optimizes pairs of Lagrange multipliers at each step while holding the rest fixed. They establish that the procedure terminates at the global optimum after a finite number of iterations. Numerical tests confirm that the resulting models differ from those trained without privileged information, and that training completes more quickly than with non-sequential solvers.
What carries the argument
The SMO decomposition applied to the OC-SVM+ dual quadratic program, which reduces the full optimization to repeated two-variable subproblems that admit closed-form or simple numerical solutions.
If this is right
- The algorithm terminates after a finite number of iterations, removing the need for arbitrary stopping tolerances.
- Training time for OC-SVM+ models is lower than that of interior-point or other non-sequential solvers on the tested data sets.
- The learned decision function in the original feature space changes measurably when privileged information is supplied during training.
- The method scales to problem sizes where general-purpose quadratic solvers become impractical.
Where Pith is reading between the lines
- The same pairwise decomposition could be applied to related one-class formulations such as support vector data description with privileged features.
- Because privileged data is never needed at test time, the approach could improve anomaly detection pipelines that already collect extra sensor or metadata streams only during model fitting.
- Faster, guaranteed-convergent training may make parameter sweeps over the regularization constants more feasible in practice.
Load-bearing premise
The privileged information can be folded into the one-class SVM dual problem using the standard LUPI formulation without creating numerical instabilities or needing extra tuning beyond what SVM+ and OC-SVM already require.
What would settle it
A run of the proposed SMO procedure on one of the paper's benchmark datasets that either fails to reach the same objective value as an interior-point solver or requires more wall-clock time than the non-sequential baseline.
Figures

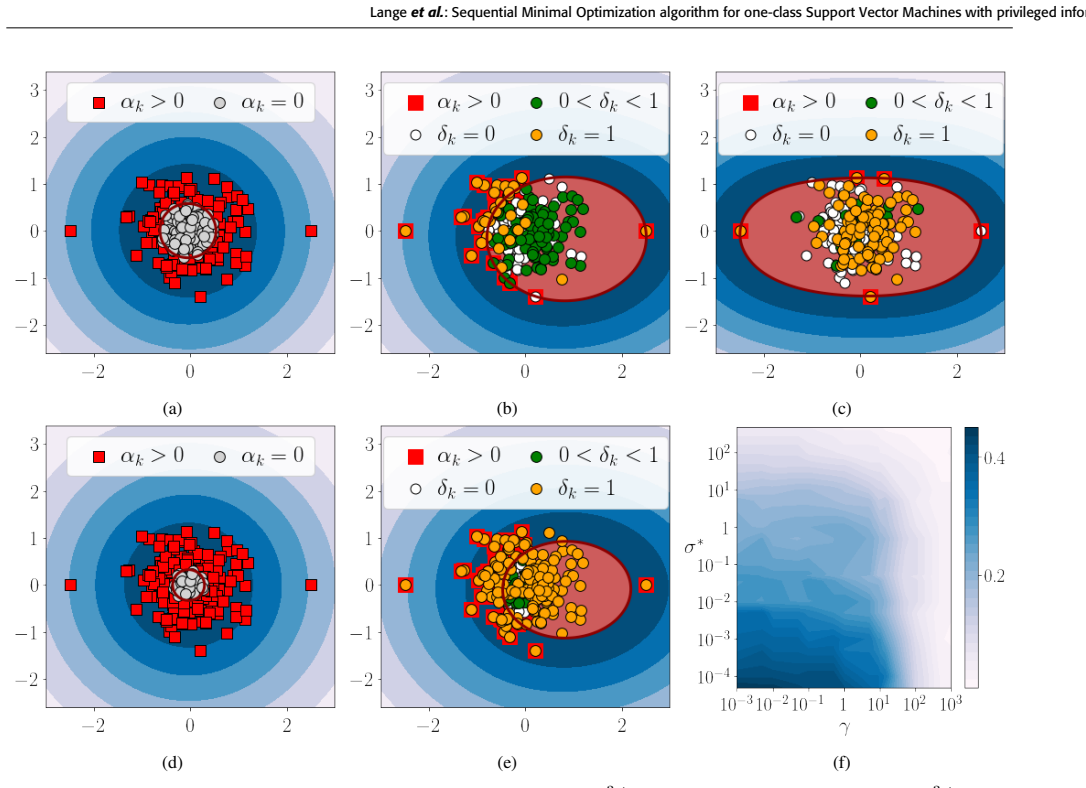
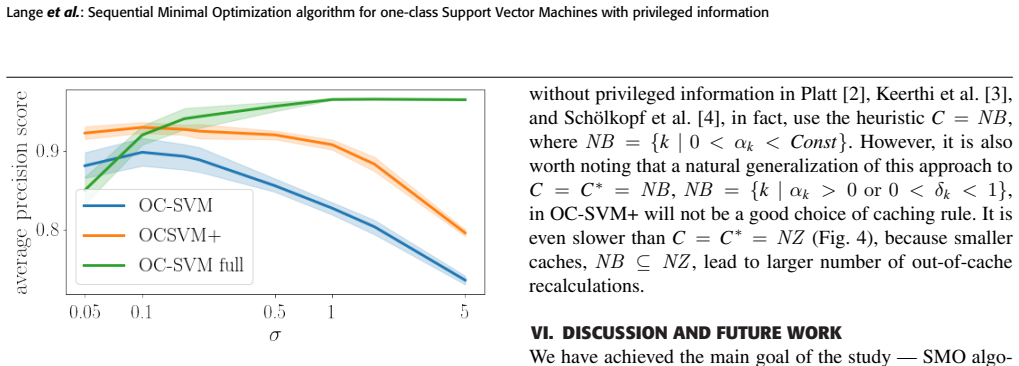
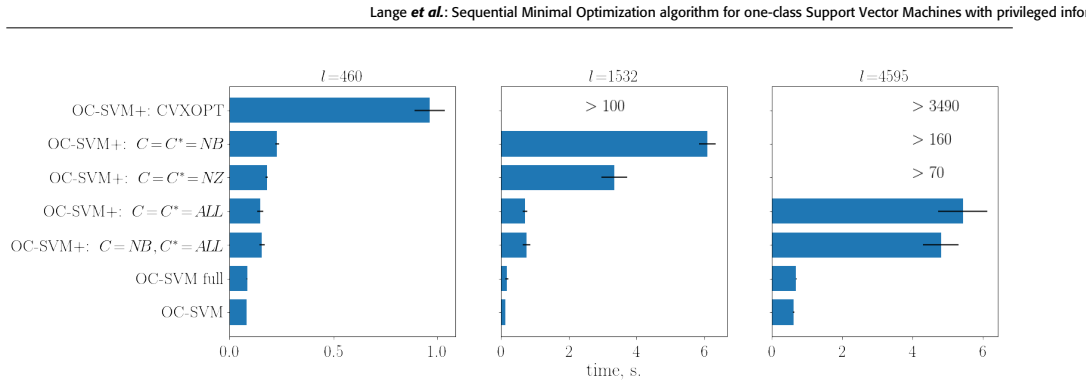
read the original abstract
One of the powerful techniques in data modeling is accounting for features that are available at the training stage, but are not available when the trained model is used to classify or predict test data -- the Learning Using Privileged Information paradigm (LUPI). Sequential Minimal Optimization (SMO) methods have been developed for supervised Support Vector Machines (SVM), unsupervised one-class SVM, and SVM with privileged information (SVM+). The missing brick in this research has long been a one-class SVM with privileged information (OC-SVM+). In this paper, we propose an SMO algorithm for OC-SVM+ that significantly outperforms non-sequential algorithms for training the OC-SVM+ model. Its finite-time convergence is established. The experiments show how privileged information affects a descriptive domain in the space of original features. Comparative benchmark tests demonstrate that our algorithm is superior over interior point algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Sequential Minimal Optimization (SMO) algorithm for One-Class Support Vector Machines with Privileged Information (OC-SVM+). It extends the LUPI paradigm and prior SMO work on SVM, OC-SVM, and SVM+ to this setting, claims to establish finite-time convergence of the proposed algorithm, and reports experiments showing the effect of privileged information on the descriptive domain together with outperformance relative to non-sequential and interior-point solvers.
Significance. If the finite-time convergence result is rigorously established and the empirical superiority holds under standard benchmarks, the work would complete the family of SMO solvers for SVM variants that incorporate privileged information. This could improve training efficiency for one-class models in settings where additional training-only features are available, such as anomaly detection with expert annotations.
minor comments (3)
- [Abstract] Abstract: the claim of finite-time convergence and experimental superiority is stated without derivation steps, precise update rules, error bounds, or any quantitative benchmark numbers, which limits immediate verifiability of the central claims.
- The manuscript would benefit from explicit pseudocode or update-rule equations for the SMO procedure in the OC-SVM+ dual, even if the derivation is standard.
- [Experiments] Experiments section: comparative results against interior-point methods should include the specific datasets, kernel choices, and numerical performance metrics (accuracy, training time, etc.) to support the superiority statement.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on the SMO algorithm for OC-SVM+ and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; derivation is self-contained algorithmic extension
full rationale
The paper proposes an SMO algorithm for the OC-SVM+ dual problem under the standard LUPI formulation, proves finite-time convergence, and reports empirical comparisons. No step reduces a claimed prediction or result to a fitted parameter or self-citation by construction; the convergence claim is a mathematical property of the algorithm, and performance claims are experimental outcomes. The derivation chain relies on established SVM/SMO techniques without self-referential definitions or load-bearing self-citations that collapse the central result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
V apnik and A
V . V apnik and A. V ashist, ‘‘A new learning paradigm: Learning using privileged information,’’Neural networks, vol. 22, no. 5-6, pp. 544–557, 2009
2009
-
[2]
Platt, ‘‘Fast training of support vector machines using sequential minimal optimization,’’ inAdvances in Kernel Methods - Support V ector Learning
J. Platt, ‘‘Fast training of support vector machines using sequential minimal optimization,’’ inAdvances in Kernel Methods - Support V ector Learning. MIT Press, January 1998. [Online]. Available: https://www.microsoft.com/en-us/research/publication/ fast-training-of-support-vector-machines-using-sequential-minimal-optimization/
1998
-
[3]
S. S. Keerthi, S. K. Shevade, C. Bhattacharyya, and K. R. K. Murthy, ‘‘Improvements to Platt’s SMO algorithm for SVM classifier design,’’ Neural computation, vol. 13, no. 3, pp. 637–649, 2001
2001
-
[4]
Schölkopf, J
B. Schölkopf, J. C. Platt, J. Shawe-Taylor, A. J. Smola, and R. C. Williamson, ‘‘Estimating the support of a high-dimensional distribution,’’ Neural computation, vol. 13, no. 7, pp. 1443–1471, 2001
2001
-
[5]
Pechyony and V
D. Pechyony and V . V apnik, ‘‘Fast optimization algorithms for solving SVM+,’’Stat. Learning and Data Science, vol. 1, 2011
2011
-
[6]
V apnik,Estimation of dependencies based on empirical data
V . V apnik,Estimation of dependencies based on empirical data. Springer Science & Business Media, 2006
2006
-
[7]
V apnik, A
V . V apnik, A. V ashist, and N. Pavlovitch, ‘‘Learning using hidden informa- tion: Master-class learning,’’ inNATO workshop on Mining Massive Data sets for security. IOS Press, 2008, pp. 3–14
2008
-
[8]
V apnik and R
V . V apnik and R. Izmailov, ‘‘Knowledge transfer in SVM and neural networks,’’Annals of Mathematics and Artificial Intelligence, vol. 81, no. 1, pp. 3–19, 2017
2017
-
[9]
X. Li, B. Du, C. Xu, Y . Zhang, L. Zhang, and D. Tao, ‘‘Robust learning with imperfect privileged information,’’Artificial Intelligence, vol. 282, pp. 103–246, 2020
2020
-
[10]
V apnik and R
V . V apnik and R. Izmailov, ‘‘Learning with intelligent teacher: Similarity control and knowledge transfer,’’ inInternational Symposium on Statistical Learning and Data Sciences. Springer, 2015, pp. 3–32
2015
-
[11]
B. E. Boser, I. M. Guyon, and V . N. V apnik, ‘‘A training algorithm for optimal margin classifiers,’’ inProceedings of the fifth annual workshop on Computational learning theory, 1992, pp. 144–152
1992
-
[12]
Cortes and V
C. Cortes and V . V apnik, ‘‘Support-vector networks,’’Machine learning, vol. 20, no. 3, pp. 273–297, 1995
1995
-
[13]
Serra-Toro, V
C. Serra-Toro, V . J. Traver, and F. Pla, ‘‘Exploring some practical issues of SVM+: Is really privileged information that helps?’’Pattern Recognition Letters, vol. 42, pp. 40–46, 2014
2014
-
[14]
Lapin, M
M. Lapin, M. Hein, and B. Schiele, ‘‘Learning using privileged informa- tion: SVM+ and weighted SVM,’’Neural Networks, vol. 53, pp. 95–108, 2014
2014
-
[15]
Lodhi, C
H. Lodhi, C. Saunders, J. Shawe-Taylor, N. Cristianini, and C. Watkins, ‘‘Text classification using string kernels,’’Journal of machine learning research, vol. 2, no. Feb, pp. 419–444, 2002
2002
-
[16]
R. I. Kondor and J. Lafferty, ‘‘Diffusion kernels on graphs and other discrete structures,’’ inProceedings of the 19th international conference on machine learning, vol. 2002, 2002, pp. 315–322
2002
-
[17]
Couto, ‘‘Kernel k-means for categorical data,’’ inInternational Sympo- sium on Intelligent Data Analysis
J. Couto, ‘‘Kernel k-means for categorical data,’’ inInternational Sympo- sium on Intelligent Data Analysis. Springer, 2005, pp. 46–56
2005
-
[18]
Potdar, T
K. Potdar, T. S. Pardawala, and C. D. Pai, ‘‘A comparative study of categorical variable encoding techniques for neural network classifiers,’’ International journal of computer applications, vol. 175, no. 4, pp. 7–9, 2017
2017
-
[19]
Rodríguez, M
P . Rodríguez, M. A. Bautista, J. Gonzalez, and S. Escalera, ‘‘Beyond one- hot encoding: Lower dimensional target embedding,’’Image and Vision Computing, vol. 75, pp. 21–31, 2018
2018
-
[20]
Burnaev and D
E. Burnaev and D. Smolyakov, ‘‘One-class SVM with privileged infor- mation and its application to malware detection,’’ in2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW). IEEE, 2016, pp. 273–280
2016
-
[21]
J. Chen, X. Liu, and S. Lyu, ‘‘Boosting with side information,’’ inAsian Conference on Computer Vision. Springer, 2012, pp. 563–577
2012
-
[22]
B. Liu, L. Liu, Y . Xiao, C. Liu, X. Chen, and W. Li, ‘‘AdaBoost-based transfer learning with privileged information,’’Information Sciences, vol. 593, pp. 216–232, 2022
2022
-
[23]
Ribeiro, C
B. Ribeiro, C. Silva, A. Vieira, A. Gaspar-Cunha, and J. C. das Neves, ‘‘Fi- nancial distress model prediction using svm+,’’ inThe 2010 International Joint Conference on Neural Networks (IJCNN). IEEE, 2010, pp. 1–7
2010
-
[24]
Ribeiro, C
B. Ribeiro, C. Silva, N. Chen, A. Vieira, and J. C. das Neves, ‘‘Enhanced de- fault risk models with SVM+,’’Expert Systems with Applications, vol. 39, no. 11, pp. 10 140–10 152, 2012. 17 Langeet al.: Sequential Minimal Optimization algorithm for one-class Support Vector Machines with privileged information
2012
-
[25]
Liang and V
L. Liang and V . Cherkassky, ‘‘Learning using structured data: Application to fMRI data analysis,’’ in2007 International Joint Conference on Neural Networks. IEEE, 2007, pp. 495–499
2007
-
[26]
IEEE, 2008, pp
——, ‘‘Connection between SVM+ and multi-task learning,’’ in2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence). IEEE, 2008, pp. 2048–2054
2008
-
[27]
Liang, F
L. Liang, F. Cai, and V . Cherkassky, ‘‘Predictive learning with structured (grouped) data,’’Neural Networks, vol. 22, no. 5-6, pp. 766–773, 2009
2009
-
[28]
Cai and V
F. Cai and V . Cherkassky, ‘‘SVM+ regression and multi-task learning,’’ in 2009 International Joint Conference on Neural Networks, 2009, pp. 418– 424
2009
-
[29]
F. Tang, C. Xiao, F. Wang, J. Zhou, and L.-W. H. Lehman, ‘‘Retaining privileged information for multi-task learning,’’ inProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019, pp. 1369–1377
2019
-
[30]
Y ang and I
H. Y ang and I. Patras, ‘‘Privileged information-based conditional regres- sion forest for facial feature detection,’’ in2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG). IEEE, 2013, pp. 1–6
2013
-
[31]
Sharmanska, N
V . Sharmanska, N. Quadrianto, and C. H. Lampert, ‘‘Learning to rank using privileged information,’’ inProceedings of the IEEE international conference on computer vision, 2013, pp. 825–832
2013
-
[32]
——, ‘‘Learning to transfer privileged information,’’arXiv preprint arXiv:1410.0389, 2014
Pith/arXiv arXiv 2014
-
[33]
W. Li, L. Niu, and D. Xu, ‘‘Exploiting privileged information from web data for image categorization,’’ inComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Pro- ceedings, Part V 13. Springer, 2014, pp. 437–452
2014
-
[34]
Wang and Q
Z. Wang and Q. Ji, ‘‘Classifier learning with hidden information,’’ in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 4969–4977
2015
-
[35]
Y . Y an, F. Nie, W. Li, C. Gao, Y . Y ang, and D. Xu, ‘‘Image classification by cross-media active learning with privileged information,’’IEEE Trans- actions on Multimedia, vol. 18, no. 12, pp. 2494–2502, 2016
2016
-
[36]
A. C. Rodríguez, S. D’Aronco, K. Schindler, and J. D. Wegner, ‘‘Fine- grained species recognition with privileged pooling: Better sample effi- ciency through supervised attention,’’IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 2023
2023
-
[37]
Feyereisl, S
J. Feyereisl, S. Kwak, J. Son, and B. Han, ‘‘Object localization based on structural SVM using privileged information,’’Advances in Neural Information Processing Systems, vol. 27, 2014
2014
-
[38]
D. Lopez-Paz, L. Bottou, B. Schölkopf, and V . V apnik, ‘‘Unifying distilla- tion and privileged information,’’arXiv preprint arXiv:1511.03643, 2015
Pith/arXiv arXiv 2015
-
[39]
L. Niu, W. Li, and D. Xu, ‘‘Exploiting privileged information from web data for action and event recognition,’’International Journal of Computer Vision, vol. 118, no. 2, pp. 130–150, 2016
2016
-
[40]
Hoffman, S
J. Hoffman, S. Gupta, and T. Darrell, ‘‘Learning with side information through modality hallucination,’’ inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 826–834
2016
-
[41]
Sarafianos, M
N. Sarafianos, M. Vrigkas, and I. A. Kakadiaris, ‘‘Adaptive SVM+: Learn- ing with privileged information for domain adaptation,’’ inProceedings of the IEEE International Conference on Computer Vision Workshops, 2017, pp. 2637–2644
2017
-
[42]
J. Tang, Y . Tian, P . Zhang, and X. Liu, ‘‘Multiview Privileged Support V ector Machines,’’IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 8, pp. 3463–3477, 2018
2018
-
[43]
Lambert, O
J. Lambert, O. Sener, and S. Savarese, ‘‘Deep learning under privileged information using heteroscedastic dropout,’’ inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8886– 8895
2018
-
[44]
Zhang, S
C. Zhang, S. Sun, Y . Tian, and Z. Wang, ‘‘Structured output prediction using privileged information,’’IEEE Access, vol. 7, pp. 106 065–106 074, 2019
2019
-
[45]
W. Zhu, X. Jia, and W. Li, ‘‘Privileged label enhancement with multi-label learning.’’ inIJCAI, 2020, pp. 2376–2382
2020
-
[46]
Y . Li, F. Meng, J. Shi, and A. D. N. Initiative, ‘‘Learning using privileged information improves neuroimaging-based CAD of Alzheimer’s disease: a comparative study,’’Medical & biological engineering & computing, vol. 57, pp. 1605–1616, 2019
2019
-
[47]
Ganaie and M
M. Ganaie and M. Tanveer, ‘‘Ensemble deep random vector functional link network using privileged information for Alzheimer’s disease diagnosis,’’ IEEE/ACM Transactions on Computational Biology and Bioinformatics, 2022
2022
-
[48]
T. A. Shaikh, R. Ali, and M. S. Beg, ‘‘Transfer learning privileged in- formation fuels CAD diagnosis of breast cancer,’’Machine Vision and Applications, vol. 31, pp. 1–23, 2020
2020
-
[49]
Zhang, L
H. Zhang, L. Guo, J. Wang, S. Ying, and J. Shi, ‘‘Multi-View Feature Transformation Based SVM+ for Computer-Aided Diagnosis of Liver Can- cers With Ultrasound Images,’’IEEE Journal of Biomedical and Health Informatics, vol. 27, no. 3, pp. 1512–1523, 2023
2023
-
[50]
W. Lee, J. Lee, D. Kim, and B. Ham, ‘‘Learning with Privileged Informa- tion for Efficient Image Super-Resolution,’’ inComputer Vision – ECCV 2020, A. V edaldi, H. Bischof, T. Brox, and J.-M. Frahm, Eds. Cham: Springer International Publishing, 2020, pp. 465–482
2020
-
[51]
Z. Wu, X. Xia, R. Wang, J. Li, J. Y u, Y . Mao, and T. Liu, ‘‘LR-SVM+: Learning using privileged information with noisy labels,’’IEEE Transac- tions on Multimedia, vol. 24, pp. 1080–1092, 2021
2021
-
[52]
Z. Che, B. Liu, Y . Xiao, and H. Cai, ‘‘Twin support vector machines with privileged information,’’Information Sciences, vol. 573, pp. 141–153,
-
[53]
Available: https://www.sciencedirect.com/science/article/ pii/S0020025521005478
[Online]. Available: https://www.sciencedirect.com/science/article/ pii/S0020025521005478
-
[54]
Y . Li, H. Sun, W. Y an, and Q. Cui, ‘‘R-CTSVM+: Robust capped L1-norm twin support vector machine with privileged information,’’Information Sciences, vol. 574, pp. 12–32, 2021
2021
-
[55]
Y . Shu, Q. Li, C. Xu, S. Liu, and G. Xu, ‘‘V -SVR+: support vector regression with variational privileged information,’’IEEE Transactions on Multimedia, vol. 24, pp. 876–889, 2021
2021
-
[56]
Jung and F
B. Jung and F. D. Johansson, ‘‘Efficient learning of nonlinear prediction models with time-series privileged information,’’Advances in Neural In- formation Processing Systems, vol. 35, pp. 19 048–19 060, 2022
2022
-
[57]
Feyereisl and U
J. Feyereisl and U. Aickelin, ‘‘Privileged information for data clustering,’’ Information Sciences, vol. 194, pp. 4–23, 2012
2012
-
[58]
Zhu and P
W. Zhu and P . Zhong, ‘‘A new one-class SVM based on hidden information,’’Knowledge-Based Systems, vol. 60, pp. 35–43, 2014. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0950705114000136
2014
-
[59]
Fouad, P
S. Fouad, P . Tino, S. Raychaudhury, and P . Schneider, ‘‘Incorporating privileged information through metric learning,’’IEEE transactions on neural networks and learning systems, vol. 24, no. 7, pp. 1086–1098, 2013
2013
-
[60]
R. M. Marcacini, M. A. Domingues, E. R. Hruschka, and S. O. Rezende, ‘‘Privileged information for hierarchical document clustering: a metric learning approach,’’ in2014 22nd International Conference on Pattern Recognition. IEEE, 2014, pp. 3636–3641
2014
-
[61]
Y ang, M
X. Y ang, M. Wang, and D. Tao, ‘‘Person re-identification with metric learning using privileged information,’’IEEE Transactions on Image Pro- cessing, vol. 27, no. 2, pp. 791–805, 2017
2017
-
[62]
Shekhar and L
S. Shekhar and L. Akoglu, ‘‘Incorporating privileged information to unsu- pervised anomaly detection,’’ inJoint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2018, pp. 87–104
2018
-
[63]
Smolyakov, N
D. Smolyakov, N. Sviridenko, E. Burikov, and E. Burnaev, ‘‘Anomaly pattern recognition with privileged information for sensor fault detection,’’ inIAPR Workshop on Artificial Neural Networks in Pattern Recognition. Springer, 2018, pp. 320–332
2018
-
[64]
T.-H. Vu, H. Jain, M. Bucher, M. Cord, and P . Pérez, ‘‘Dada: Depth- aware domain adaptation in semantic segmentation,’’ inProceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 7364– 7373
2019
-
[65]
H. Tang, Y . Wang, and K. Jia, ‘‘Unsupervised domain adaptation via dis- tilled discriminative clustering,’’Pattern Recognition, vol. 127, Jul. 2022, art. no. 108638
2022
-
[66]
C. Gautam, A. Tiwari, and M. Tanveer, ‘‘OCKELM+: kernel extreme learning machine based one-class classification using privileged informa- tion (or KOC+: Kernel ridge regression or least square SVM with zero bias based one-class classification using privileged information),’’arXiv preprint arXiv:1904.08338, 2019
Pith/arXiv arXiv 1904
-
[67]
Osuna, R
E. Osuna, R. Freund, and F. Girosi, ‘‘An improved training algorithm for support vector machines,’’ inNeural networks for signal processing VII. Proceedings of the 1997 IEEE signal processing society workshop. IEEE, 1997, pp. 276–285
1997
-
[68]
Joachims, ‘‘Making large-scale SVM learning practical,’’ Technical report, Tech
T. Joachims, ‘‘Making large-scale SVM learning practical,’’ Technical report, Tech. Rep., 1998
1998
-
[69]
Platt,Sequential minimal optimization: A fast algorithm for training support vector machines
J. Platt,Sequential minimal optimization: A fast algorithm for training support vector machines. Advances in Kernel Methods. Support V ector Learning. MIT Press, Boston, 1998. 18 Langeet al.: Sequential Minimal Optimization algorithm for one-class Support Vector Machines with privileged information
1998
-
[70]
Bordes, S
A. Bordes, S. Ertekin, J. Weston, L. Bottou, and N. Cristianini, ‘‘Fast kernel classifiers with online and active learning.’’Journal of Machine Learning Research, vol. 6, no. 9, 2005
2005
-
[71]
Fan, P .-H
R.-E. Fan, P .-H. Chen, C.-J. Lin, and T. Joachims, ‘‘Working set selection using second order information for training support vector machines.’’ Journal of machine learning research, vol. 6, no. 12, 2005
2005
-
[72]
Palagi and M
L. Palagi and M. Sciandrone, ‘‘On the convergence of a modified version of SVMlight algorithm,’’Optimization Methods and Software, vol. 20, no. 2-3, pp. 317–334, 2005. [Online]. Available: https://doi.org/10.1080/ 10556780512331318209
2005
-
[73]
Glasmachers, C
T. Glasmachers, C. Igel, K. P . Bennett, and E. Parrado-Hernández, ‘‘Maximum-gain working set selection for SVMs.’’Journal of Machine Learning Research, vol. 7, no. 7, 2006
2006
-
[74]
C.-C. Chang and C.-J. Lin, ‘‘LIBSVM: A library for support vector machines,’’ACM Trans. Intell. Syst. Technol., vol. 2, no. 3, May 2011. [Online]. Available: https://doi.org/10.1145/1961189.1961199
-
[75]
D. M. Tax and R. P . Duin, ‘‘Support vector domain description,’’Pattern recognition letters, vol. 20, no. 11-13, pp. 1191–1199, 1999
1999
-
[76]
——, ‘‘Data domain description using support vectors.’’ inESANN, vol. 99. Citeseer, 1999, pp. 251–256
1999
-
[77]
Chang, C.-P
W.-C. Chang, C.-P . Lee, and C.-J. Lin, ‘‘A revisit to support vector data description,’’Dept. Comput. Sci., Nat. Taiwan Univ., Taipei, Taiwan, Tech. Rep, 2013
2013
-
[78]
Schölkopf, R
B. Schölkopf, R. C. Williamson, A. J. Smola, J. Shawe-Taylor, J. C. Platt et al., ‘‘Support vector method for novelty detection.’’ inNIPS, vol. 12. Citeseer, 1999, pp. 582–588
1999
-
[79]
S. S. Khan and M. G. Madden, ‘‘One-class classification: taxonomy of study and review of techniques,’’The Knowledge Engineering Review, vol. 29, no. 3, pp. 345–374, 2014
2014
-
[80]
C. C. Aggarwal,An introduction to outlier analysis. Springer, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.