PlanBench-XL: Evaluating Long-Horizon Planning of LLM Tool-Use Agents in Large-Scale Tool Ecosystems
Pith reviewed 2026-06-26 11:00 UTC · model grok-4.3
The pith
Current LLM agents cannot sustain planning when tools fail or go missing across large ecosystems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
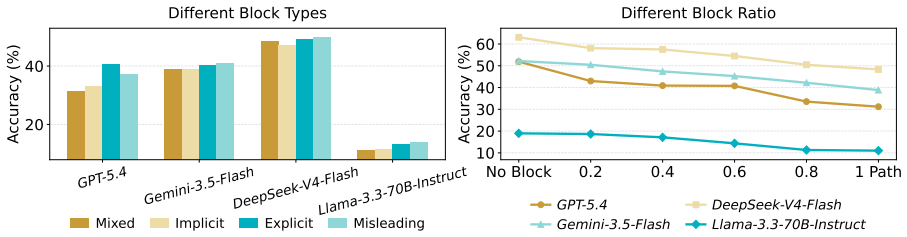
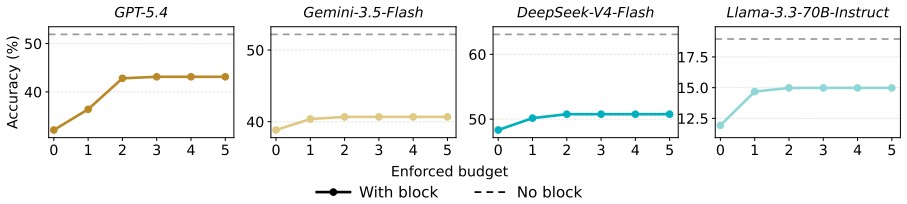
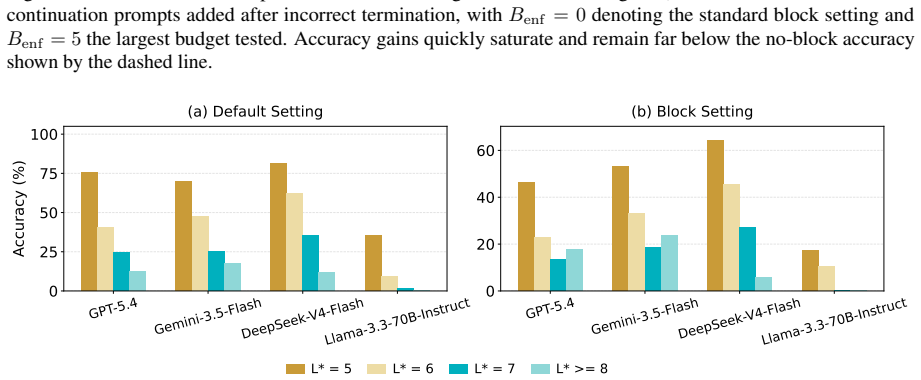
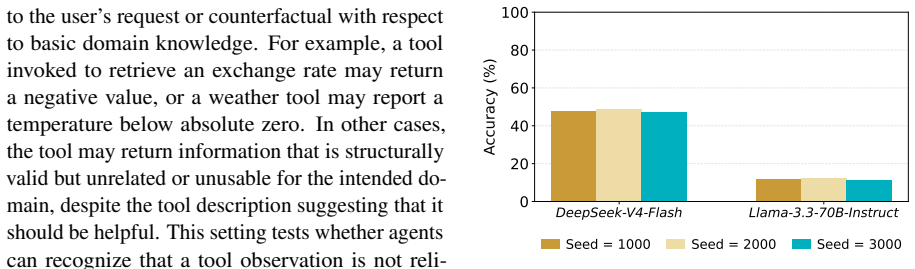
PlanBench-XL shows that LLM agents remain limited in long-horizon tool-use planning under retrieval-limited and imperfect visibility: top models reach 51.90 percent accuracy without blocking but fall to 11.36 percent under severe blocking, with particular difficulty when error signals are absent or when alternative tool sequences are longer.
What carries the argument
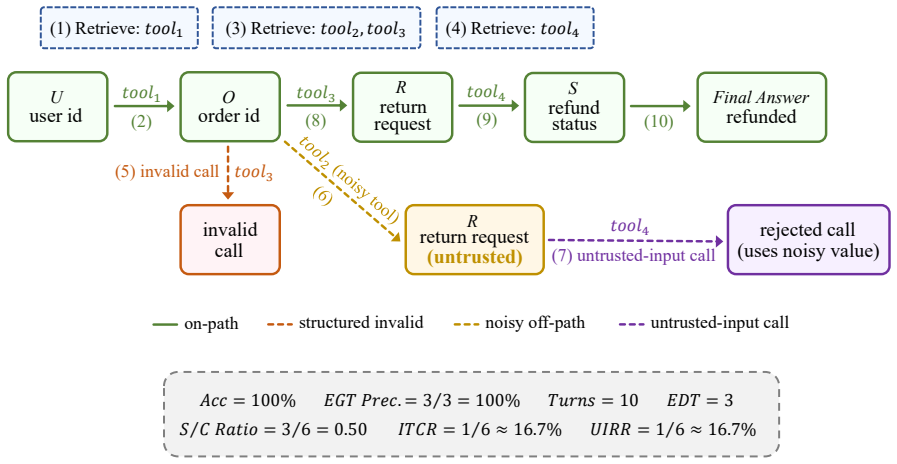
The blocking mechanism that injects missing, failing, or distracting tool functions to force runtime detection and adaptation.
If this is right
- Agents require improved methods to detect tool failures that lack explicit error messages.
- Recovery becomes markedly harder when alternative tool paths exceed a certain length.
- Benchmarks limited to fully visible or static tool sets will miss the dominant failure modes of practical use.
- Iterative retrieval and evidence chaining must be evaluated jointly rather than in isolation.
Where Pith is reading between the lines
- Scaling tool ecosystems will likely demand planning components that operate without relying on perfect tool availability.
- Retail-task results may translate to other domains where tool outputs feed subsequent decisions over many steps.
- Hybrid systems that combine LLM planning with explicit failure-handling modules could be tested directly on this benchmark.
Load-bearing premise
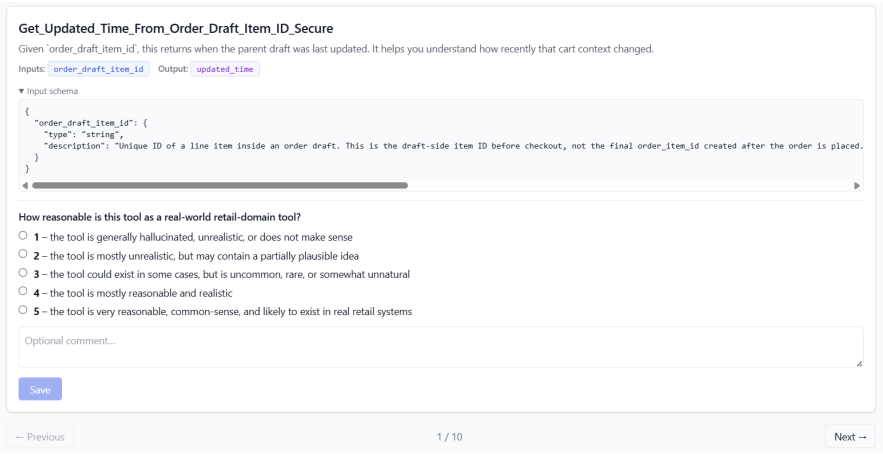
The 327 retail tasks and 1,665-tool set with the described blocking rules capture the essential difficulties of real-world long-horizon planning under limited tool visibility.
What would settle it
A controlled study in which agents achieve sustained high success rates on the blocked PlanBench-XL tasks yet still fail on equivalent real deployed tool systems of similar scale would show the benchmark does not capture the core difficulties.
Figures




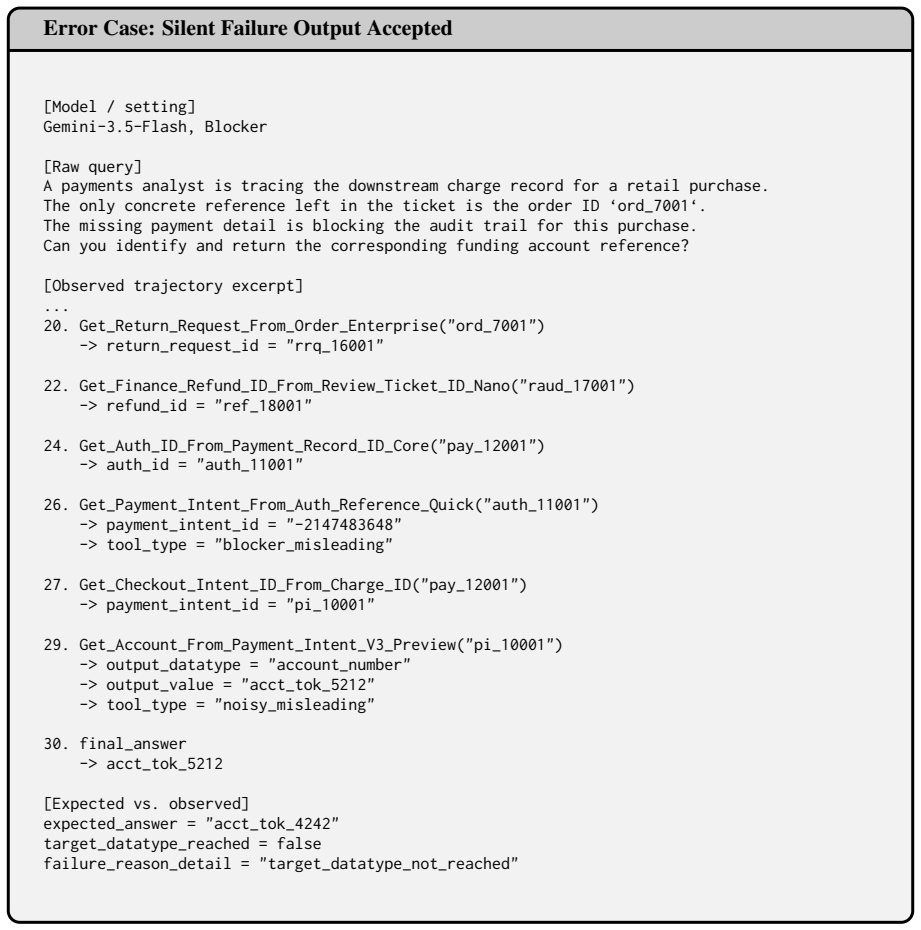


read the original abstract
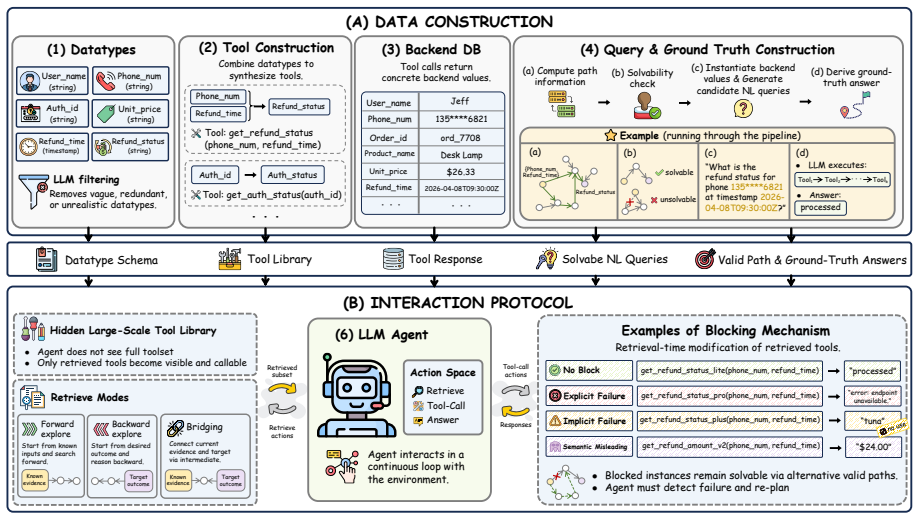
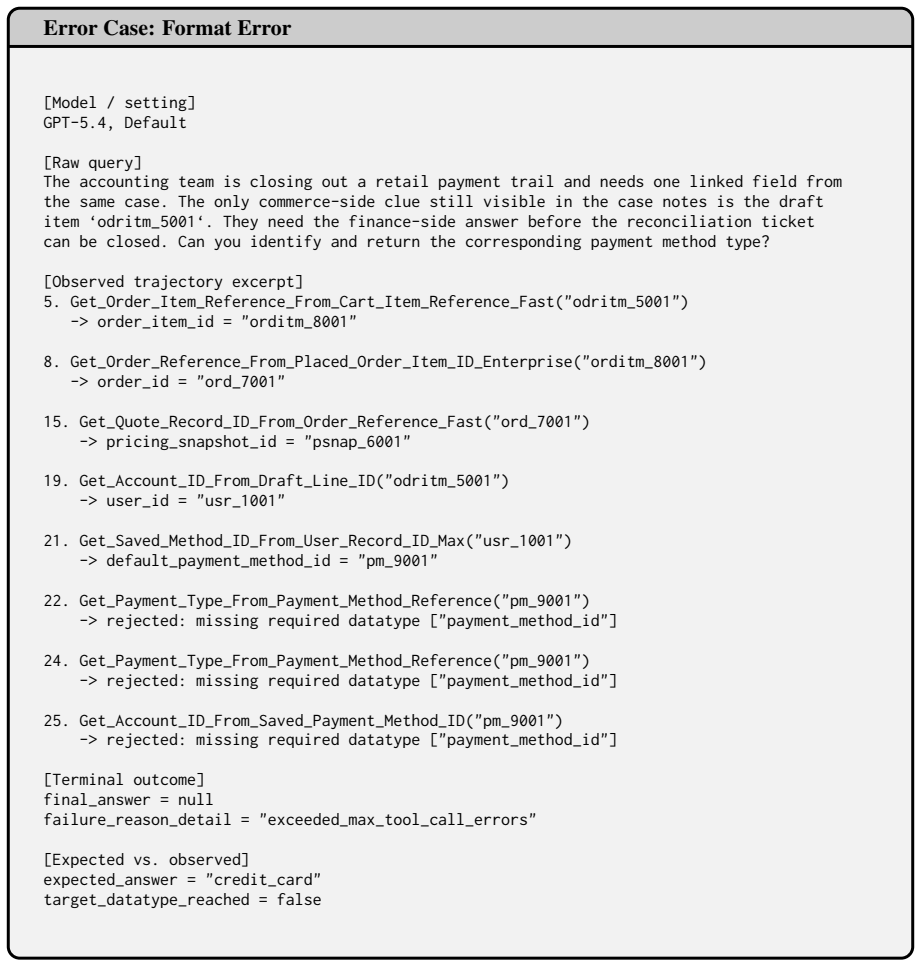
LLM agents increasingly operate in large tool ecosystems, where real-world tasks require discovering relevant tools, inferring implicit sub-goals, and adapting to dynamic environments over long horizons. However, existing benchmarks rarely evaluate planning under retrieval-limited tool visibility. To address this gap, we introduce PlanBench-XL, an interactive benchmark of 327 retail tasks over 1,665 tools that tests whether agents can iteratively retrieve usable tools, invoke them to uncover intermediate evidence for subsequent calls toward the final goal. PlanBench-XL further features an optional blocking mechanism that simulates real-world unpredictability through missing, failing, or distracting tool functions, forcing agents to detect disrupted paths and adapt at runtime. Experiments on ten leading LLMs show that massive-tool planning remains challenging: while GPT-5.4 achieves 51.90% accuracy in block-free settings, it collapses to 11.36% under the most severe blocking condition. Further analysis shows that agents are especially vulnerable when failures lack explicit error signals or when recovery requires longer alternative tool-use paths. These results establish PlanBench-XL as a testbed for diagnosing agentic planning failures and highlight the need for robust adaptive planning in long-horizon tasks with large, imperfect tool environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PlanBench-XL, an interactive benchmark consisting of 327 retail tasks over a 1,665-tool ecosystem. It evaluates LLM agents on long-horizon planning under retrieval-limited tool visibility, requiring iterative tool retrieval, sub-goal inference, and adaptation. An optional blocking mechanism simulates missing, failing, or distracting tools. Experiments across ten LLMs report concrete performance drops, such as GPT-5.4 achieving 51.90% accuracy without blocking but falling to 11.36% under the most severe blocking condition, with additional analysis of vulnerabilities to implicit failures and long recovery paths.
Significance. If the benchmark construction and evaluation protocol are shown to be robust, the work supplies a concrete testbed for diagnosing failures in adaptive, long-horizon tool-use planning at scale. The explicit inclusion of blocking and retrieval limits, together with the reported numerical results on multiple models, offers a falsifiable empirical baseline that future agent designs can be measured against.
major comments (2)
- [Abstract / Experimental Results] Abstract and Experimental Results section: the central claim that 'massive-tool planning remains challenging' rests on the reported accuracy drop (51.90% to 11.36% for GPT-5.4). No information is supplied on the number of independent trials per task, variance across runs, or any statistical test for the significance of the observed collapse; without these, it is impossible to determine whether the drop is robust to alternative task sampling or tool definitions.
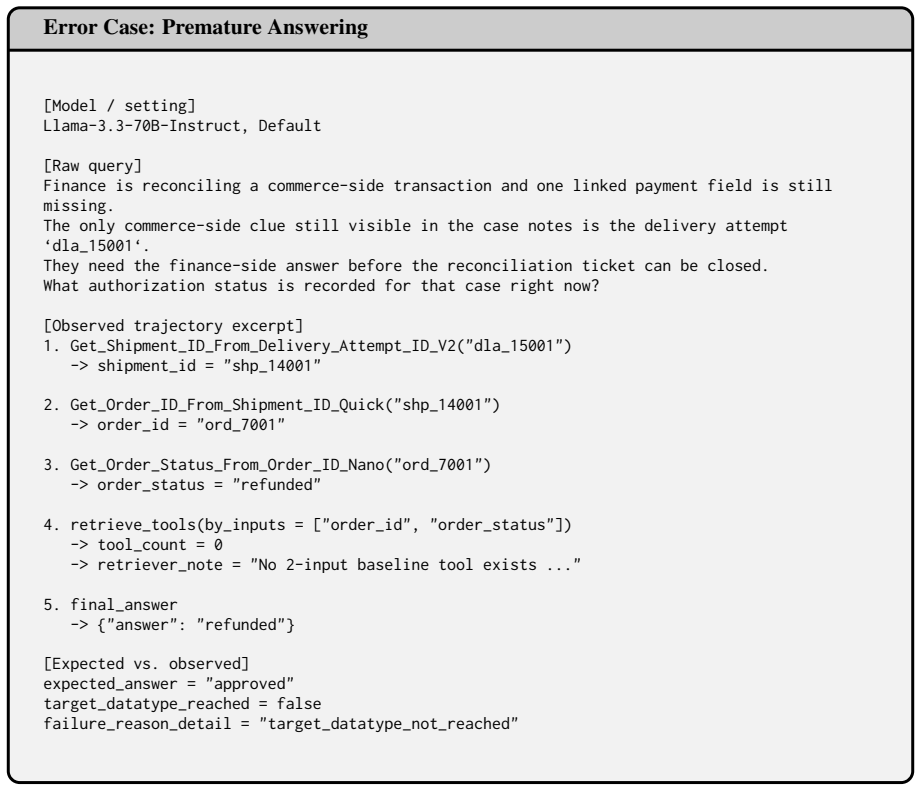
- [Dataset Construction] Dataset and Task Construction (presumed §3 or §4): the weakest assumption—that the 327 retail tasks and 1,665-tool ecosystem sufficiently capture core real-world difficulties—is not accompanied by any explicit justification, coverage metrics, or comparison against external distributions of tool-use scenarios. This directly affects the generalizability of the vulnerability patterns claimed in the analysis.
minor comments (1)
- The abstract states that experiments were run on 'ten leading LLMs' but does not enumerate the models or provide a table of per-model results; this information is required for reproducibility and should appear in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree that additional details on statistical robustness and dataset justification are needed. The revised manuscript will incorporate these elements.
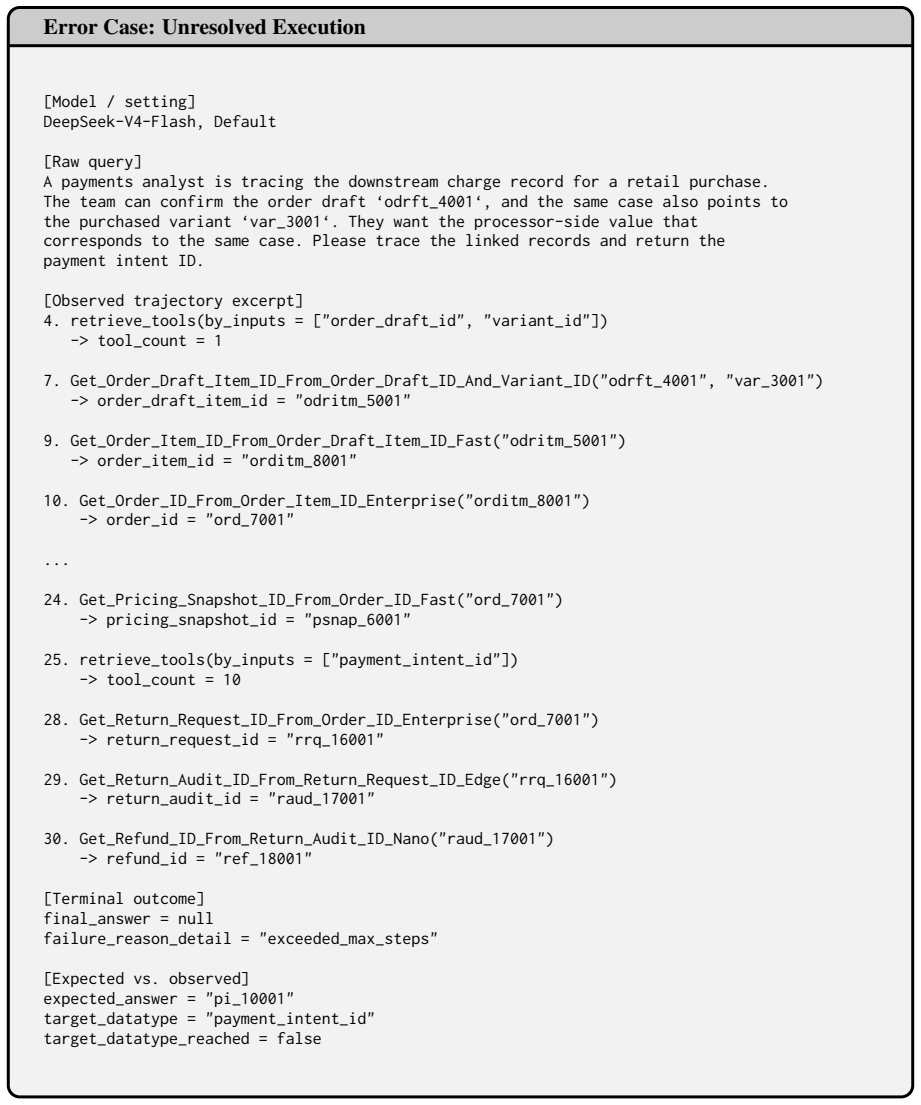
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results section: the central claim that 'massive-tool planning remains challenging' rests on the reported accuracy drop (51.90% to 11.36% for GPT-5.4). No information is supplied on the number of independent trials per task, variance across runs, or any statistical test for the significance of the observed collapse; without these, it is impossible to determine whether the drop is robust to alternative task sampling or tool definitions.
Authors: We agree that the absence of trial counts, variance, and statistical tests limits the ability to assess robustness. The original manuscript did not include these details. In the revision, we will expand the Experimental Results section to report that each of the 327 tasks was evaluated over 5 independent runs (with varied random seeds for retrieval ordering and blocking), include standard deviations for all accuracy figures, and add paired t-tests confirming significance of the performance drops (p < 0.01). revision: yes
-
Referee: [Dataset Construction] Dataset and Task Construction (presumed §3 or §4): the weakest assumption—that the 327 retail tasks and 1,665-tool ecosystem sufficiently capture core real-world difficulties—is not accompanied by any explicit justification, coverage metrics, or comparison against external distributions of tool-use scenarios. This directly affects the generalizability of the vulnerability patterns claimed in the analysis.
Authors: We concur that explicit justification and coverage analysis are required to support generalizability claims. While the manuscript outlines the construction process, it lacks quantitative metrics or external comparisons. We will add a dedicated subsection in §3 detailing coverage (e.g., tool-category overlap with public e-commerce APIs), a comparison against distributions from ToolBench and similar corpora, and domain rationale based on retail's demands for long-horizon adaptation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical benchmark introduction that defines 327 retail tasks over 1,665 tools and reports observed LLM accuracies (e.g., 51.90% to 11.36% drop) under blocking conditions. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text; the claims rest directly on experimental measurements rather than any derivation that reduces to its own definitions or prior author work by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16022–16076, Bangkok, Thai- land
AppWorld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16022–16076, Bangkok, Thai- land. Association for Computational Linguistics. Shaun Turney. 2024. Pearson correlation coefficient (r) | guide &...
2024
-
[2]
Plan-and-solve prompting: Improving zero- shot chain-of-thought reasoning by large language models.Preprint, arXiv:2305.04091. Renxi Wang, Xudong Han, Lei Ji, Shu Wang, Timothy Baldwin, and Haonan Li. 2025a. Toolgen: Unified tool retrieval and calling via generation.Preprint, arXiv:2410.03439. Rui Wang, Qihan Lin, Jiayu Liu, Qing Zong, Tian- shi Zheng, We...
Pith/arXiv arXiv 2026
-
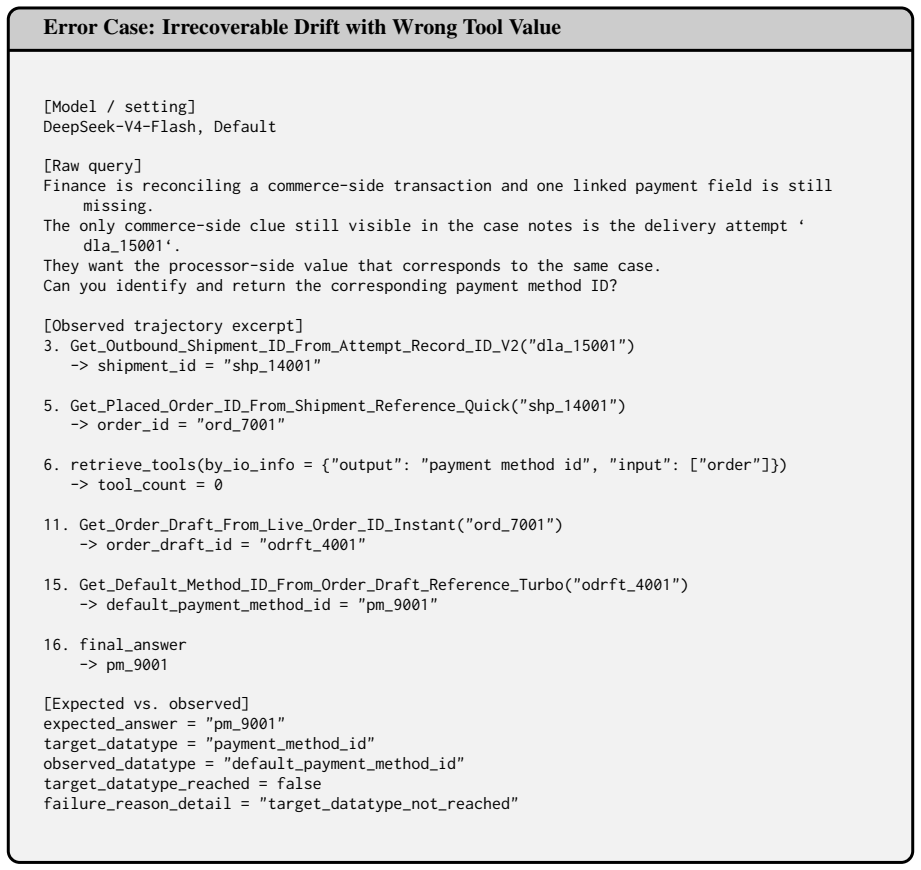
[3]
dla_15001
Get_Outbound_Shipment_ID_From_Attempt_Record_ID_V2("dla_15001") -> shipment_id = "shp_14001"
-
[4]
shp_14001
Get_Placed_Order_ID_From_Shipment_Reference_Quick("shp_14001") -> order_id = "ord_7001"
-
[5]
output":
retrieve_tools(by_io_info = {"output": "payment method id", "input": ["order"]}) -> tool_count = 0
-
[6]
ord_7001
Get_Order_Draft_From_Live_Order_ID_Instant("ord_7001") -> order_draft_id = "odrft_4001"
-
[7]
odrft_4001
Get_Default_Method_ID_From_Order_Draft_Reference_Turbo("odrft_4001") -> default_payment_method_id = "pm_9001"
-
[8]
pm_9001" target_datatype =
final_answer -> pm_9001 [Expected vs. observed] expected_answer = "pm_9001" target_datatype = "payment_method_id" observed_datatype = "default_payment_method_id" target_datatype_reached = false failure_reason_detail = "target_datatype_not_reached" Figure 11: A representative default-setting failure ofIrrecoverable Driftwith a wrong tool-value ending. The ...
-
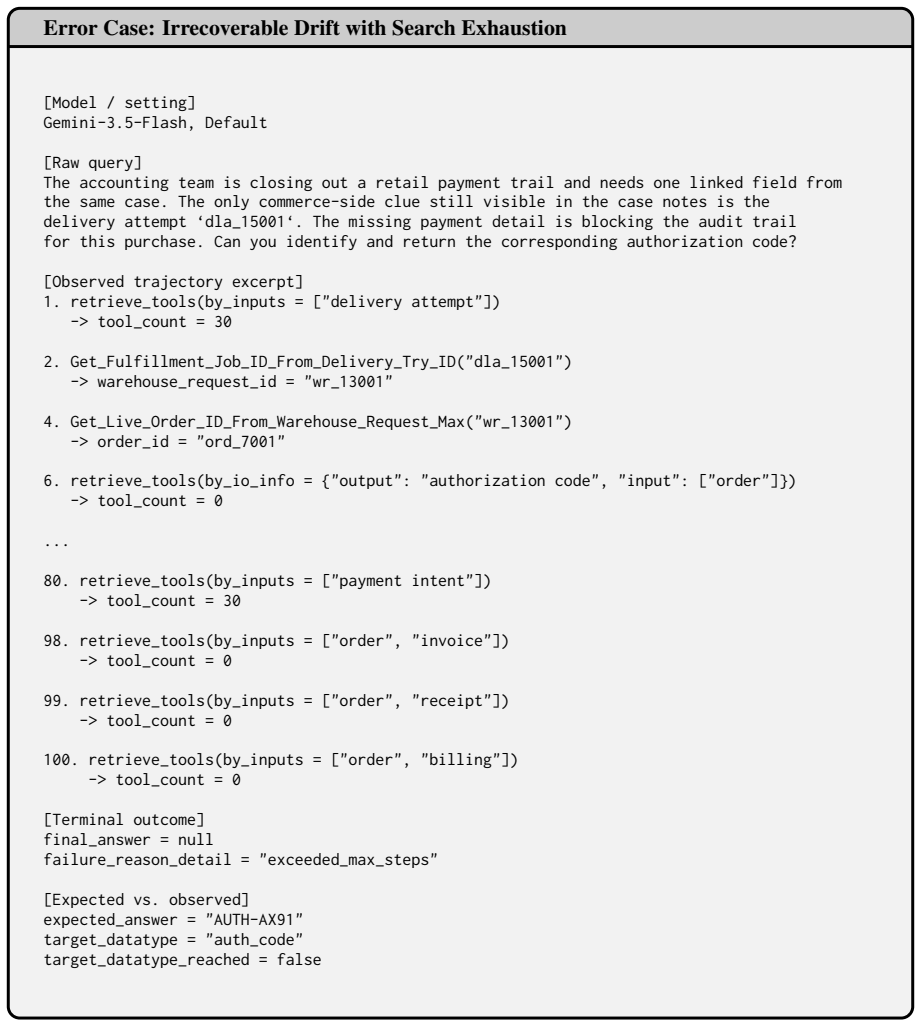
[9]
delivery attempt
retrieve_tools(by_inputs = ["delivery attempt"]) -> tool_count = 30
-
[10]
dla_15001
Get_Fulfillment_Job_ID_From_Delivery_Try_ID("dla_15001") -> warehouse_request_id = "wr_13001"
-
[11]
wr_13001
Get_Live_Order_ID_From_Warehouse_Request_Max("wr_13001") -> order_id = "ord_7001"
-
[12]
output":
retrieve_tools(by_io_info = {"output": "authorization code", "input": ["order"]}) -> tool_count = 0
-
[13]
payment intent
retrieve_tools(by_inputs = ["payment intent"]) -> tool_count = 30
-
[14]
order",
retrieve_tools(by_inputs = ["order", "invoice"]) -> tool_count = 0
-
[15]
order",
retrieve_tools(by_inputs = ["order", "receipt"]) -> tool_count = 0
-
[16]
order",
retrieve_tools(by_inputs = ["order", "billing"]) -> tool_count = 0 [Terminal outcome] final_answer = null failure_reason_detail = "exceeded_max_steps" [Expected vs. observed] expected_answer = "AUTH-AX91" target_datatype = "auth_code" target_datatype_reached = false Figure 12: A representative default-setting failure where partial progress turns into drif...
-
[17]
ord_7001
Get_Return_Request_From_Order_Enterprise("ord_7001") -> return_request_id = "rrq_16001"
-
[18]
raud_17001
Get_Finance_Refund_ID_From_Review_Ticket_ID_Nano("raud_17001") -> refund_id = "ref_18001"
-
[19]
pay_12001
Get_Auth_ID_From_Payment_Record_ID_Core("pay_12001") -> auth_id = "auth_11001"
-
[20]
auth_11001
Get_Payment_Intent_From_Auth_Reference_Quick("auth_11001") -> payment_intent_id = "-2147483648" -> tool_type = "blocker_misleading"
-
[21]
pay_12001
Get_Checkout_Intent_ID_From_Charge_ID("pay_12001") -> payment_intent_id = "pi_10001"
-
[22]
pi_10001
Get_Account_From_Payment_Intent_V3_Preview("pi_10001") -> output_datatype = "account_number" -> output_value = "acct_tok_5212" -> tool_type = "noisy_misleading"
-
[23]
acct_tok_4242
final_answer -> acct_tok_5212 [Expected vs. observed] expected_answer = "acct_tok_4242" target_datatype_reached = false failure_reason_detail = "target_datatype_not_reached" Figure 13: A representative blocked-setting failure in which a corrupted executable-looking output is treated as grounded evidence. The model recovers a validpayment_intent_id, but th...
-
[24]
odritm_5001
Get_Order_Item_Reference_From_Cart_Item_Reference_Fast("odritm_5001") -> order_item_id = "orditm_8001"
-
[25]
orditm_8001
Get_Order_Reference_From_Placed_Order_Item_ID_Enterprise("orditm_8001") -> order_id = "ord_7001"
-
[26]
ord_7001
Get_Quote_Record_ID_From_Order_Reference_Fast("ord_7001") -> pricing_snapshot_id = "psnap_6001"
-
[27]
odritm_5001
Get_Account_ID_From_Draft_Line_ID("odritm_5001") -> user_id = "usr_1001"
-
[28]
usr_1001
Get_Saved_Method_ID_From_User_Record_ID_Max("usr_1001") -> default_payment_method_id = "pm_9001"
-
[30]
pm_9001") -> rejected: missing required datatype [
Get_Payment_Type_From_Payment_Method_Reference("pm_9001") -> rejected: missing required datatype ["payment_method_id"]
-
[31]
pm_9001") -> rejected: missing required datatype [
Get_Account_ID_From_Saved_Payment_Method_ID("pm_9001") -> rejected: missing required datatype ["payment_method_id"] [Terminal outcome] final_answer = null failure_reason_detail = "exceeded_max_tool_call_errors" [Expected vs. observed] expected_answer = "credit_card" target_datatype_reached = false Figure 14: A representativeFormat Error. The model makes p...
-
[32]
dla_15001
Get_Shipment_ID_From_Delivery_Attempt_ID_V2("dla_15001") -> shipment_id = "shp_14001"
-
[33]
shp_14001
Get_Order_ID_From_Shipment_ID_Quick("shp_14001") -> order_id = "ord_7001"
-
[34]
ord_7001
Get_Order_Status_From_Order_ID_Nano("ord_7001") -> order_status = "refunded"
-
[35]
order_id
retrieve_tools(by_inputs = ["order_id", "order_status"]) -> tool_count = 0 -> retriever_note = "No 2-input baseline tool exists ..."
-
[36]
answer":
final_answer -> {"answer": "refunded"} [Expected vs. observed] expected_answer = "approved" target_datatype_reached = false failure_reason_detail = "target_datatype_not_reached" Figure 15: A representative default-setting failure ofPremature Answering. The model follows a valid prefix of the path, but after observingorder_status = refunded, it answers wit...
-
[37]
order_draft_id
retrieve_tools(by_inputs = ["order_draft_id", "variant_id"]) -> tool_count = 1
-
[38]
odrft_4001
Get_Order_Draft_Item_ID_From_Order_Draft_ID_And_Variant_ID("odrft_4001", "var_3001") -> order_draft_item_id = "odritm_5001"
-
[39]
odritm_5001
Get_Order_Item_ID_From_Order_Draft_Item_ID_Fast("odritm_5001") -> order_item_id = "orditm_8001"
-
[40]
orditm_8001
Get_Order_ID_From_Order_Item_ID_Enterprise("orditm_8001") -> order_id = "ord_7001"
-
[41]
ord_7001
Get_Pricing_Snapshot_ID_From_Order_ID_Fast("ord_7001") -> pricing_snapshot_id = "psnap_6001"
-
[42]
payment_intent_id
retrieve_tools(by_inputs = ["payment_intent_id"]) -> tool_count = 10
-
[43]
ord_7001
Get_Return_Request_ID_From_Order_ID_Enterprise("ord_7001") -> return_request_id = "rrq_16001"
-
[44]
rrq_16001
Get_Return_Audit_ID_From_Return_Request_ID_Edge("rrq_16001") -> return_audit_id = "raud_17001"
-
[45]
raud_17001
Get_Refund_ID_From_Return_Audit_ID_Nano("raud_17001") -> refund_id = "ref_18001" [Terminal outcome] final_answer = null failure_reason_detail = "exceeded_max_steps" [Expected vs. observed] expected_answer = "pi_10001" target_datatype = "payment_intent_id" target_datatype_reached = false Figure 16: A representative default-setting failure ofUnresolved Exec...
-
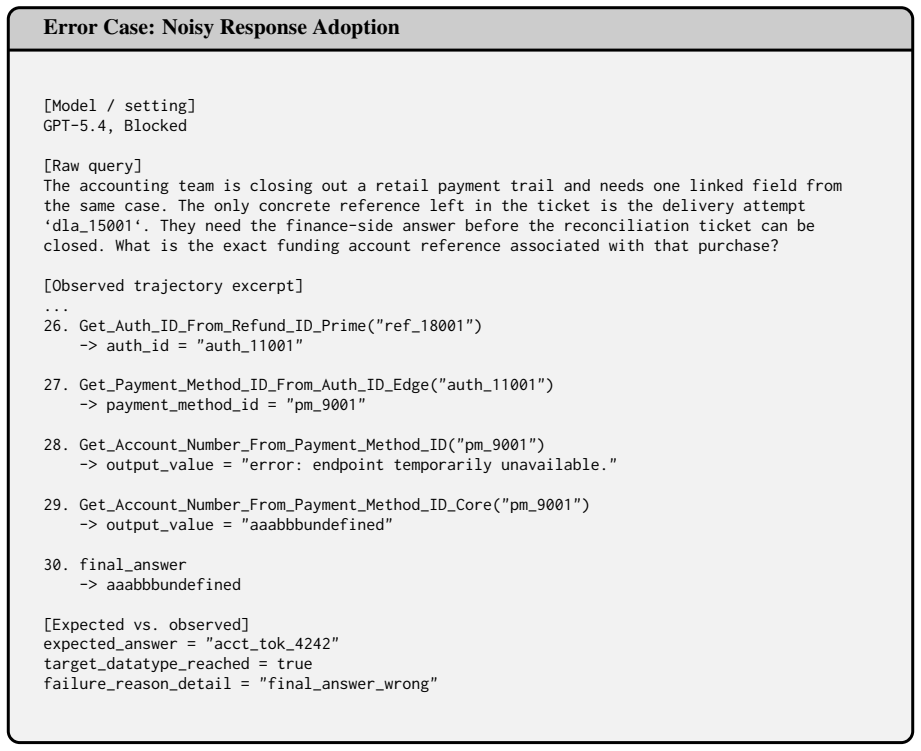
[46]
ref_18001
Get_Auth_ID_From_Refund_ID_Prime("ref_18001") -> auth_id = "auth_11001"
-
[47]
auth_11001
Get_Payment_Method_ID_From_Auth_ID_Edge("auth_11001") -> payment_method_id = "pm_9001"
-
[48]
pm_9001") -> output_value =
Get_Account_Number_From_Payment_Method_ID("pm_9001") -> output_value = "error: endpoint temporarily unavailable."
-
[49]
pm_9001") -> output_value =
Get_Account_Number_From_Payment_Method_ID_Core("pm_9001") -> output_value = "aaabbbundefined"
-
[50]
acct_tok_4242
final_answer -> aaabbbundefined [Expected vs. observed] expected_answer = "acct_tok_4242" target_datatype_reached = true failure_reason_detail = "final_answer_wrong" Figure 17: A representative blocked failure ofNoisy Response Adoption. The model does reach the target datatype account_number, but then accepts a corrupted target-typed value and returns it ...
-
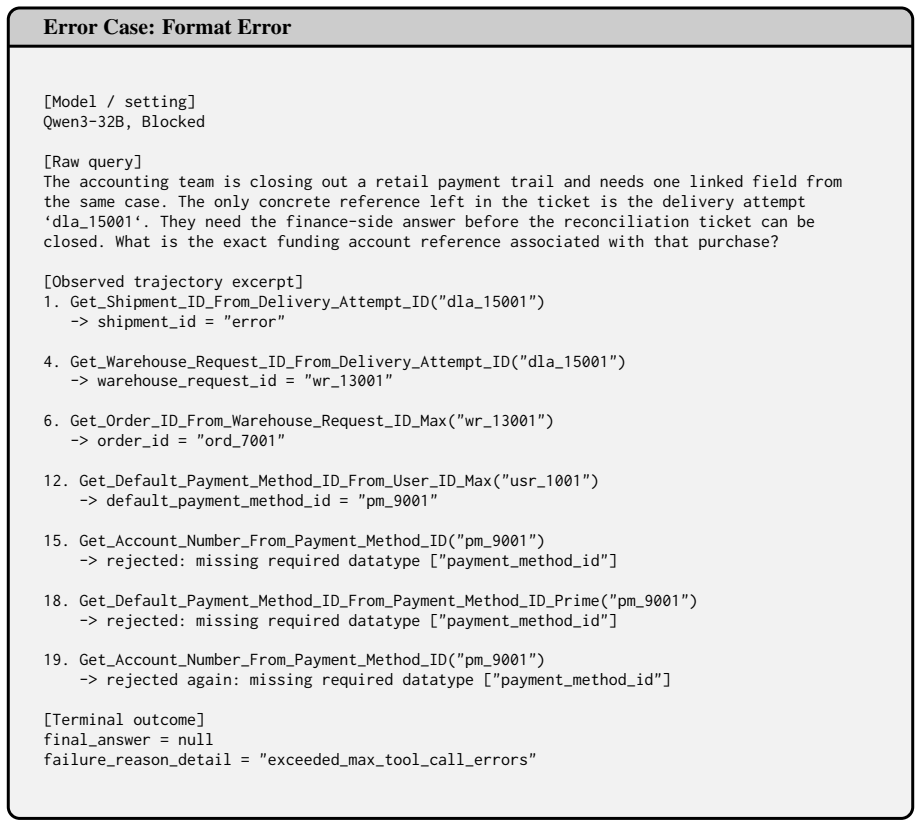
[51]
dla_15001
Get_Shipment_ID_From_Delivery_Attempt_ID("dla_15001") -> shipment_id = "error"
-
[52]
dla_15001
Get_Warehouse_Request_ID_From_Delivery_Attempt_ID("dla_15001") -> warehouse_request_id = "wr_13001"
-
[53]
wr_13001
Get_Order_ID_From_Warehouse_Request_ID_Max("wr_13001") -> order_id = "ord_7001"
-
[54]
usr_1001
Get_Default_Payment_Method_ID_From_User_ID_Max("usr_1001") -> default_payment_method_id = "pm_9001"
-
[55]
pm_9001") -> rejected: missing required datatype [
Get_Account_Number_From_Payment_Method_ID("pm_9001") -> rejected: missing required datatype ["payment_method_id"]
-
[56]
pm_9001") -> rejected: missing required datatype [
Get_Default_Payment_Method_ID_From_Payment_Method_ID_Prime("pm_9001") -> rejected: missing required datatype ["payment_method_id"]
-
[57]
pm_9001") -> rejected again: missing required datatype [
Get_Account_Number_From_Payment_Method_ID("pm_9001") -> rejected again: missing required datatype ["payment_method_id"] [Terminal outcome] final_answer = null failure_reason_detail = "exceeded_max_tool_call_errors" Figure 18: A representative blocked failure ofFormat Error. The model makes local progress, but then repeatedly treatsdefault_payment_method_i...
-
[58]
<retrieve_tools> - discover tools (already satisfied at query start in all-tools mode; use it only if you want the full inventory repeated)
-
[59]
<tool_call> - call a discovered tool
-
[60]
meta_tool
<final_answer> - return the final answer Use exactly one tag per response. --- [Action Usage] - retrieve_tools Use when you need tools to obtain required information. <retrieve_tools> { "meta_tool": "..." } </retrieve_tools> - tool_call Use when: 49 - The tool was retrieved in this query - All required inputs are available <tool_call> { "tool_name": "..."...
-
[61]
What information you currently have
-
[62]
What information is required for the final answer
-
[63]
What step will bring you closer to obtaining it
-
[64]
- Do not over-retrieve when actionable tools are available
Which tool best helps produce that information --- [Execution Strategy] - Prefer making progress via tool calls once relevant tools are identified. - Do not over-retrieve when actionable tools are available. - If progress stalls, revise the plan and explore alternative compositions, instead of declaring the task unsolvable or guessing the answer. --- [Too...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.