An interpretable closed form for entanglement entropy from bitstrings, guided by a graph neural network
Pith reviewed 2026-06-26 09:52 UTC · model grok-4.3
The pith
A six-term linear formula built from boundary correlators approximates bipartite entanglement entropy to within 0.024 nats.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
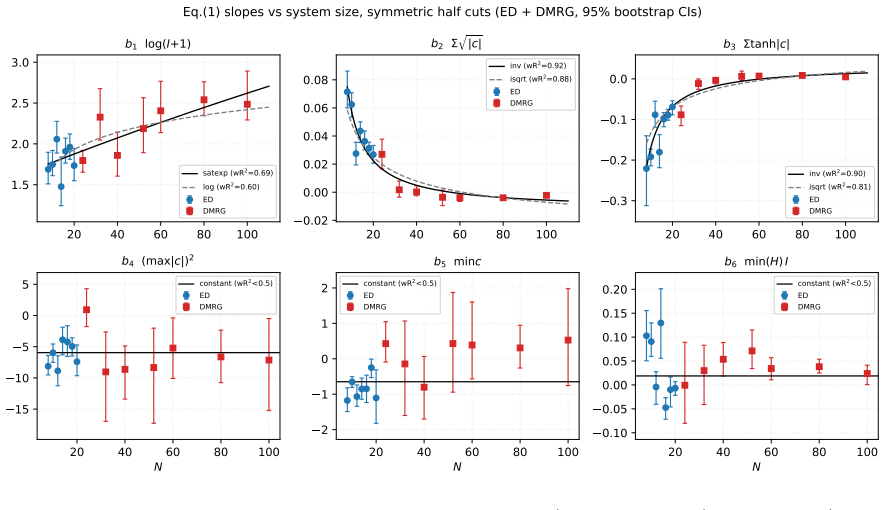
The bipartite von Neumann entropy constrained by bitstring distributions admits a six-term linear closed form in bitstring-derivable scalars. The form is localized by a graph neural network to the two-point correlators on the bipartition boundary and reaches 0.024 nats mean absolute error. When refit per system size the expression remains accurate to 25-50 mnat up to 100 atoms, with two slopes obeying inverse-size laws that allow label-free use at 40-80 mnat error.
What carries the argument
Six-term linear closed form in boundary two-point correlators, selected via graph neural network localization followed by exhaustive search.
Load-bearing premise
Entanglement entropy is accurately captured by a linear combination of only the two-point correlators on the bipartition boundary, with coefficients that remain stable enough to refit per system size.
What would settle it
A direct comparison on DMRG or exact data for system sizes around 100 atoms showing that refitted coefficients yield mean absolute error above 50 mnat on held-out bitstrings would disprove the scaling claim.
Figures
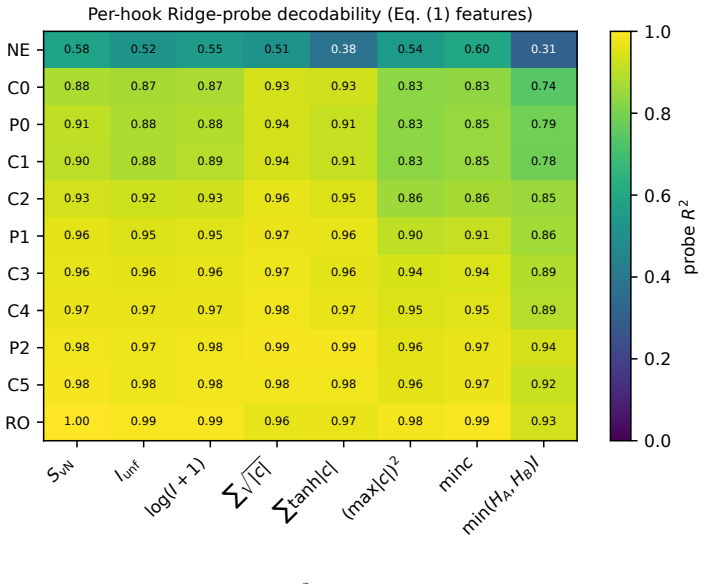
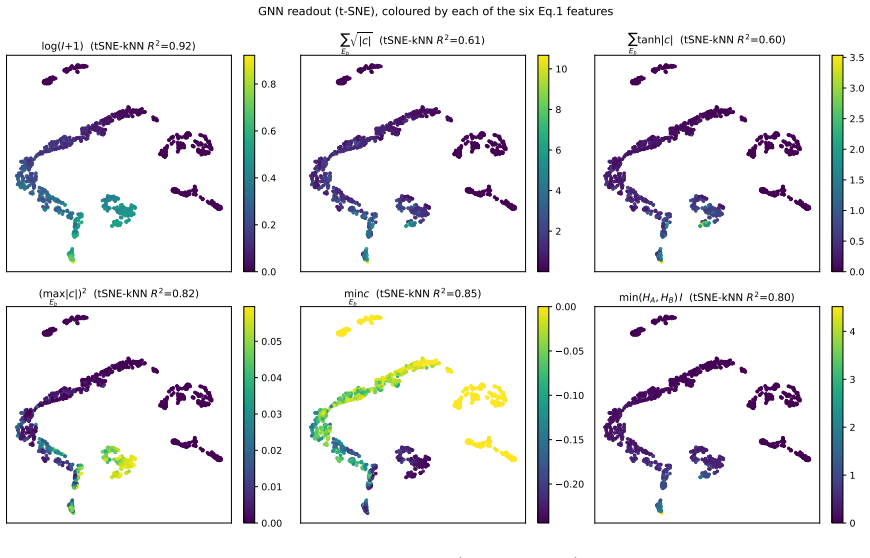
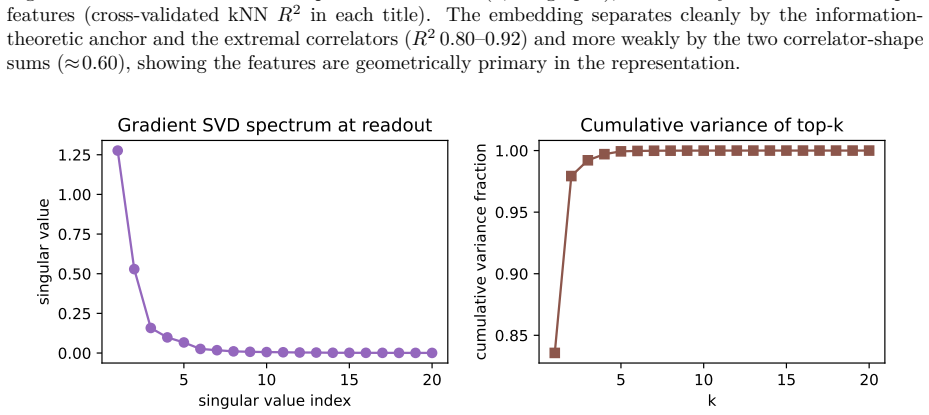
read the original abstract
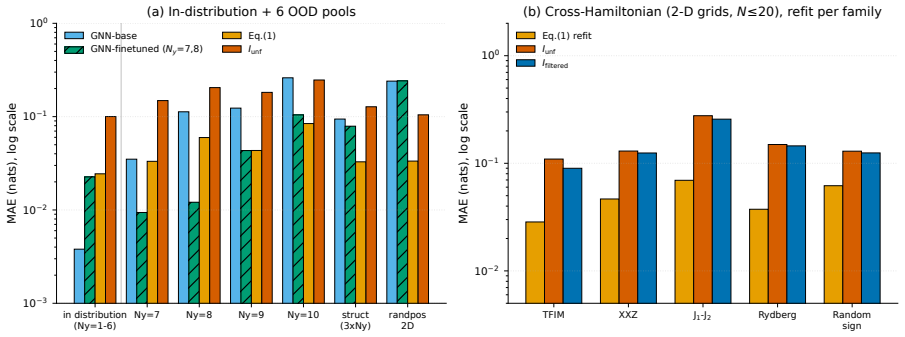
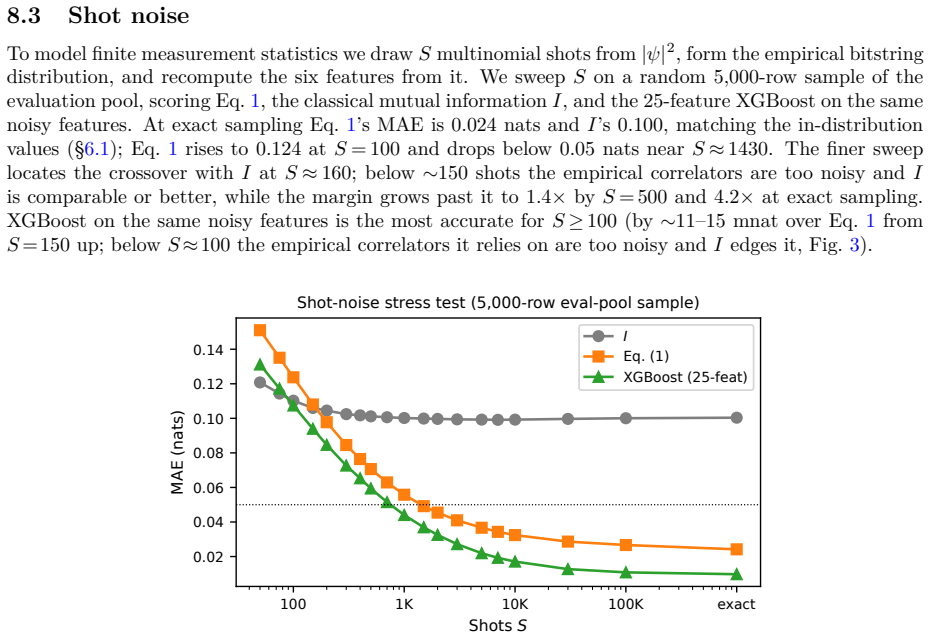
The empirical bitstring distribution is the most accessible observable on Rydberg-atom arrays, but the bipartite von~Neumann entropy it constrains is far costlier to obtain. We present a six-term linear closed form for the entropy, built on bitstring-derivable physics scalars, and characterize its accuracy, portability, scaling behaviour, and calibration cost. The feature set is selected with guidance from a trained graph neural network: probing the network localizes its entropy prediction to the two-point correlators on the bipartition boundary, and an exhaustive ground-truth search restricted to those boundary correlators isolates the form. It reaches $0.024$~nats mean absolute error in distribution: $6.4$ times the network's error, but in a form a human can read and apply without retraining. Fit once and applied unchanged, it has lower error than the base network on five of six out-of-distribution pools and ties the sixth. An independent density-matrix renormalization-group study to one hundred atoms -- five times the reach of exact diagonalization -- settles the size-extrapolation question: coefficients frozen at small size fail at scale, but the failure is structured. Refit per size the form holds to $25$--$50$~mnat (cross-validated); two of its six slopes follow clean inverse-size laws, one a downward curving growth, and the others are trendless; the fitted laws deploy the form label-free at roughly $40$--$80$~mnat. The result fixes a label-budget rule: at large sizes, a few dozen labels recalibrate the closed form to match a fine-tuned in-distribution ensemble on the same features, while nonlinear ML models pull ahead only given large labelled datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a graph neural network trained on bitstring data from Rydberg arrays localizes its entanglement-entropy predictions to two-point correlators on the bipartition boundary; an exhaustive search over those features then isolates a six-term linear closed form whose coefficients, when refit per system size, achieve 0.024 nats in-distribution MAE and 25–50 mnat error up to 100 atoms (five times the exact-diagonalization limit) according to DMRG validation, while remaining portable across out-of-distribution pools when the functional form is held fixed.
Significance. If the empirical result holds, the work supplies a compact, human-readable formula that converts readily measured bitstrings into entropy estimates without retraining a network, together with explicit scaling laws for two of the six coefficients. The GNN-guided feature discovery and the DMRG size-extrapolation protocol constitute reproducible, falsifiable contributions that could be adopted by experimental groups working with Rydberg arrays.
major comments (2)
- [§3] §3 (feature-selection protocol): the exhaustive search is restricted a priori to the boundary two-point correlators highlighted by the GNN; the manuscript does not report the performance of an unrestricted search over all bitstring-derived scalars, leaving open whether the six-term form is the globally simplest or merely the simplest within the GNN-localized subset.
- [§5.2] §5.2 (DMRG extrapolation): the claim that the form 'holds' at large size rests on per-size refitting of the six coefficients; the paper shows that frozen coefficients produce structured growth in error, but does not quantify how many additional labels are required to keep the refitted error below the in-distribution network baseline as N→∞.
minor comments (3)
- [Table 1] Table 1: the reported MAE values for the closed form versus the GNN should include the number of independent training runs or cross-validation folds used to obtain the quoted uncertainties.
- [Eq. (3)] Eq. (3): the six-term expression is written with numerical coefficients; the manuscript should also display the symbolic form with the six physics scalars named explicitly before numerical fitting.
- [Figure 4] Figure 4: axis labels on the coefficient-versus-size plots are too small for print; the inverse-size and curving-growth trends would be clearer with larger fonts and an inset showing the functional fits.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recommendation for minor revision. We address the two major comments below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (feature-selection protocol): the exhaustive search is restricted a priori to the boundary two-point correlators highlighted by the GNN; the manuscript does not report the performance of an unrestricted search over all bitstring-derived scalars, leaving open whether the six-term form is the globally simplest or merely the simplest within the GNN-localized subset.
Authors: The restriction of the exhaustive search to the GNN-localized boundary correlators is intentional and central to the method: the GNN serves to identify physically relevant features before the search, yielding an interpretable form with clear physical motivation. An unrestricted search over the full space of bitstring-derived scalars was not performed, as the combinatorial number of candidate features renders it computationally prohibitive and would defeat the purpose of GNN-guided discovery. We will revise §3 to explicitly state this rationale, note the limitation that the six-term form is the simplest within the GNN-highlighted subset, and add a brief discussion of why boundary two-point correlators are expected to dominate on physical grounds. revision: yes
-
Referee: [§5.2] §5.2 (DMRG extrapolation): the claim that the form 'holds' at large size rests on per-size refitting of the six coefficients; the paper shows that frozen coefficients produce structured growth in error, but does not quantify how many additional labels are required to keep the refitted error below the in-distribution network baseline as N→∞.
Authors: The manuscript already reports that a few dozen labels suffice for recalibration up to N=100 to reach errors comparable to the in-distribution network baseline. We agree, however, that an explicit functional dependence of the required label count on N as N→∞ is not provided. We will revise §5.2 to restate the observed label budget more clearly in comparison to the network baseline and to note that determining the asymptotic scaling would require additional DMRG data at still larger sizes, which lies outside the present scope. revision: partial
Circularity Check
No significant circularity
full rationale
The paper's derivation is an explicit empirical procedure: GNN localization followed by exhaustive search over boundary two-point correlators, then linear regression to obtain a six-term form. This is presented as a fitted, interpretable approximation rather than a first-principles derivation. The manuscript directly validates portability via OOD tests (fixed coefficients outperform or tie the network on five of six pools) and size extrapolation via independent DMRG up to 100 atoms, distinguishing frozen vs. refit coefficients and reporting structured scaling. No load-bearing step reduces by construction to its inputs, no self-citation chain is invoked for uniqueness, and no ansatz is smuggled; the result is self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- six linear coefficients
axioms (2)
- domain assumption Entanglement entropy is linearly related to the selected boundary two-point correlators
- domain assumption GNN attention localizes the relevant physics to the bipartition boundary
Reference graph
Works this paper leans on
-
[1]
A. L. Shaw et al. Benchmarking highly entangled states on a 60-atom analogue quantum simulator. Nature, 628:71, 2024
2024
-
[2]
Bernien et al
H. Bernien et al. Probing many-body dynamics on a 51-atom quantum simulator.Nature, 551:579, 2017
2017
-
[3]
Ebadi et al
S. Ebadi et al. Quantum phases of matter on a 256-atom programmable quantum simulator.Nature, 595:227, 2021
2021
-
[4]
Scholl et al
P. Scholl et al. Quantum simulation of 2D antiferromagnets with hundreds of Rydberg atoms.Nature, 595:233, 2021
2021
-
[5]
A. Saleh. Predicting the von Neumann entanglement entropy using a graph neural network.Mach. Learn.: Sci. Technol., 6:035034, 2025
2025
-
[6]
A. Saleh. Predicting the von Neumann entanglement entropy using a graph neural network. Master’s thesis, University of Iowa, 2025. DOI:10.25820/etd.008062. Extended version of [5]; additionally trains and evaluates the GNN on transverse-field Ising configurations
-
[7]
Kaufman et al
A. Kaufman et al. Improved entanglement entropy estimates from filtered bitstring probabilities. Phys. Rev. A, 112:032430, 2025
2025
-
[8]
Islam et al
R. Islam et al. Measuring entanglement entropy in a quantum many-body system.Nature, 528:77, 2015
2015
-
[9]
Brydges et al
T. Brydges et al. Probing Rényi entanglement entropy via randomized measurements.Science, 364:260, 2019. 21
2019
-
[10]
Huang, R
H.-Y. Huang, R. Kueng, and J. Preskill. Predicting many properties of a quantum system from very few measurements.Nat. Phys., 16:1050, 2020
2020
-
[11]
A. S. Holevo. Bounds for the quantity of information transmitted by a quantum communication channel.Probl. Inf. Transm., 9:177, 1973
1973
-
[12]
M. M. Wilde.Quantum Information Theory. Cambridge University Press, 2nd edition, 2017
2017
-
[13]
M. M. Wolf, F. Verstraete, M. B. Hastings, and J. I. Cirac. Area laws in quantum systems: mutual information and correlations.Phys. Rev. Lett., 100:070502, 2008
2008
-
[14]
Carleo and M
G. Carleo and M. Troyer. Solving the quantum many-body problem with artificial neural networks. Science, 355:602, 2017
2017
-
[15]
Carrasquilla and R
J. Carrasquilla and R. G. Melko. Machine learning phases of matter.Nat. Phys., 13:431, 2017
2017
-
[16]
Carleo et al
G. Carleo et al. Machine learning and the physical sciences.Rev. Mod. Phys., 91:045002, 2019
2019
-
[17]
Udrescu and M
S.-M. Udrescu and M. Tegmark. AI Feynman: a physics-inspired method for symbolic regression. Sci. Adv., 6:eaay2631, 2020
2020
-
[18]
Cranmer et al
M. Cranmer et al. Discovering symbolic models from deep learning with inductive biases. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[19]
Geiger, H
A. Geiger, H. Lu, T. Icard, and C. Potts. Causal abstractions of neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[20]
Jain and B
S. Jain and B. C. Wallace. Attention is not explanation. InProceedings of NAACL-HLT, 2019
2019
-
[21]
Wiegreffe and Y
S. Wiegreffe and Y. Pinter. Attention is not not explanation. InProceedings of EMNLP-IJCNLP, 2019
2019
-
[22]
M. Cranmer. Interpretable machine learning for science with PySR and SymbolicRegression.jl.arXiv preprint arXiv:2305.01582, 2023
Pith/arXiv arXiv 2023
-
[23]
Hauschild and F
J. Hauschild and F. Pollmann. Efficient numerical simulations with tensor networks: Tensor Network Python (TeNPy).SciPost Phys. Lect. Notes, page 5, 2018. 22
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.