BLUEX v2: Benchmarking LLMs on Open-Ended Questions from Brazilian University Entrance Exams
Pith reviewed 2026-07-01 07:01 UTC · model grok-4.3
The pith
BLUEX v2 evaluates 21 LLMs on open-ended Brazilian university exams and finds a 4.92-point performance spread with math and image tasks as the hardest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
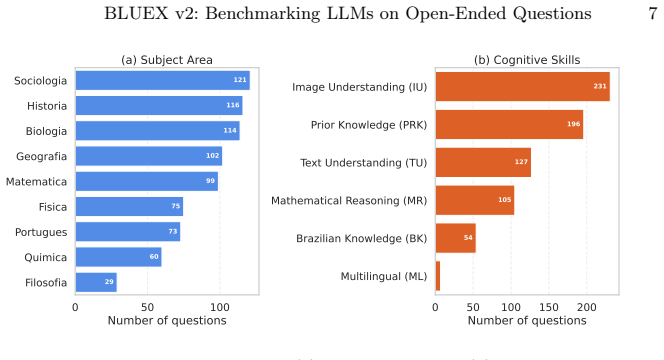
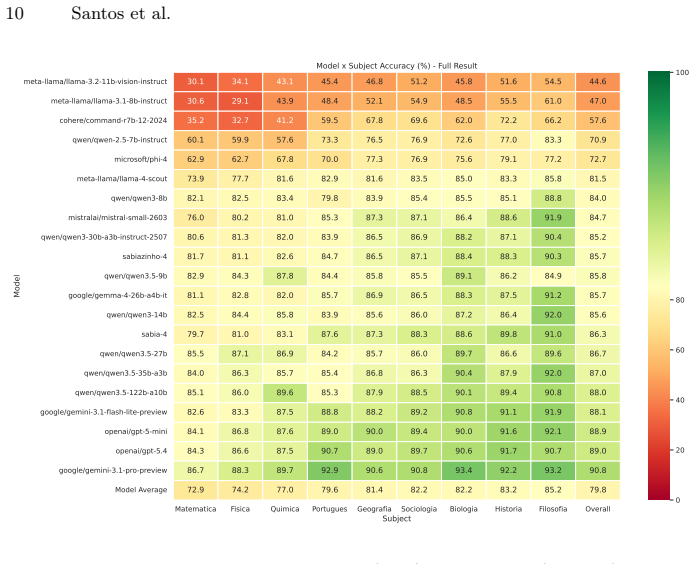
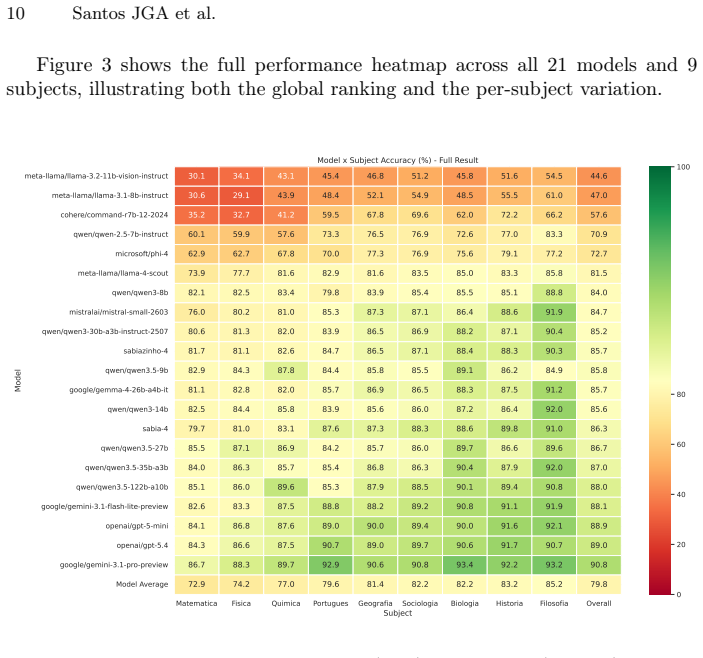
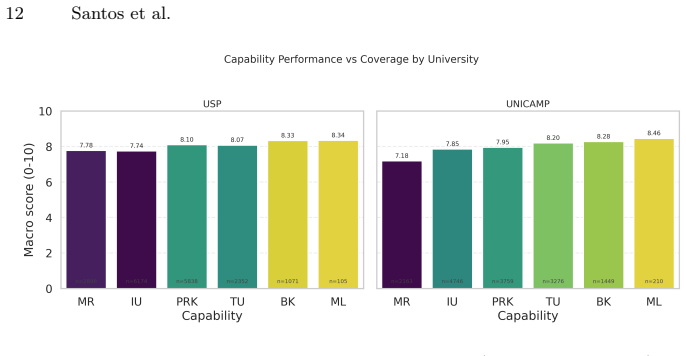
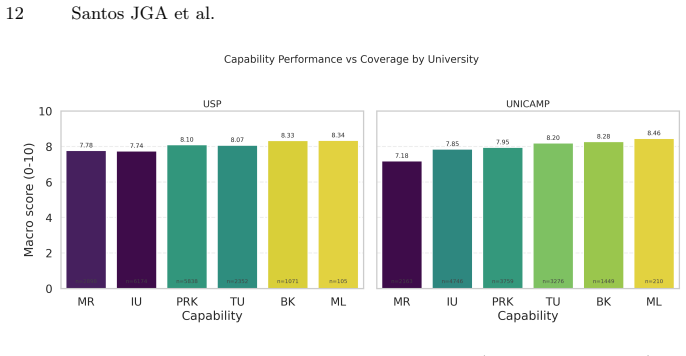
BLUEX v2 supplies a dataset of 395 exam questions that unfold into 919 subquestions drawn from recent UNICAMP and USP second-phase tests. Each item carries subject labels, reference answers, rubric criteria, and six cognitive tags. When 21 state-of-the-art LLMs are scored by an LLM judge, total scores range from 4.18 to 9.10, a spread of 4.92 points, and the lowest scores appear on mathematical reasoning and image understanding.
What carries the argument
The LLM-as-a-judge protocol that assigns 0-10 scores to model answers by comparing them against official rubrics and reference solutions.
If this is right
- Mathematical reasoning remains the weakest dimension across all tested models.
- Image understanding stays difficult even when images are supplied as captions.
- Text-only models and vision-capable models can be compared directly on the same items.
- The dataset supports repeated evaluation as new models appear.
- Capability tags allow fine-grained diagnosis of where each model succeeds or fails.
Where Pith is reading between the lines
- The benchmark could be reused yearly to track whether newer models close the observed gaps.
- Results on Portuguese discursive tasks may generalize to other languages that lack similar open-ended test sets.
- Developers might prioritize training data that pairs images with complex reasoning problems to address the two hardest dimensions.
- The public release of model outputs lets independent groups test alternative judges or rubrics.
Load-bearing premise
An LLM can grade free-form student-style answers with the same consistency and standards that human examiners apply.
What would settle it
A side-by-side human grading of the same 21 model outputs on a representative sample of questions that produces average scores differing by more than one point from the LLM judge.
Figures
read the original abstract
Although Large Language Models (LLMs) excel in many tasks, their assessment in Portuguese has received less attention, particularly for open-ended, discursive tasks that demand deeper reasoning and generation capabilities. While the original BLUEX benchmark addressed the scarcity of Portuguese evaluation datasets through multiple-choice questions from Brazilian university entrance exams, it did not cover the more challenging second-phase examinations, which require free-form written responses. In this work, we introduce BLUEX v2, a benchmark derived from the second-phase entrance exams of Brazil's two leading universities: UNICAMP (Comvest) and USP (Fuvest), spanning exam years 2022--2025. Our dataset comprises 395 questions unfolding into 919 graded subquestions, with 55.7% of questions containing associated images (represented as context-aware captions during inference to enable evaluation across both vision-capable and text-only models). Each question is annotated with subject area, official reference answers, LLM-generated rubric criteria, and six cognitive capability tags. We evaluate 21 state-of-the-art LLMs using an LLM-as-a-judge protocol. Results reveal a 4.92-point performance spread across models (4.18-9.10 on a 0-10 scale), with Mathematical Reasoning and Image Understanding emerging as the hardest capability dimensions. The evaluation code, model outputs, and dataset are publicly available at https://github.com/TropicAI-Research/BLUEXv2 and on Hugging Face at https://huggingface.co/datasets/Tropic-AI/BLUEX-v2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BLUEX v2, a dataset of 395 questions (919 subquestions) drawn from the second-phase open-ended exams of UNICAMP and USP (2022–2025). Questions are annotated with subjects, official answers, LLM-generated rubrics, and six cognitive tags; 55.7% include images rendered as captions. Twenty-one LLMs are evaluated via an LLM-as-a-judge protocol, yielding scores on a 0–10 scale with a 4.92-point spread (4.18–9.10) and identifying Mathematical Reasoning and Image Understanding as the hardest dimensions. Dataset, model outputs, and evaluation code are released publicly.
Significance. If the judge protocol proves reliable, the work supplies a much-needed public benchmark for Portuguese discursive reasoning, extending beyond multiple-choice formats and covering both text-only and vision models. The public release of data, rubrics, and code is a clear strength for reproducibility.
major comments (1)
- [Evaluation] Abstract and Evaluation section: All headline results—the 4.92-point spread, per-model rankings, and identification of Mathematical Reasoning and Image Understanding as hardest—are derived exclusively from LLM-as-a-judge scores on 919 subquestions. No human validation, correlation coefficient, Cohen’s kappa, or even spot-check agreement with human graders on the Portuguese open-ended answers is reported. Without this anchor, differences cannot be distinguished from judge artifacts.
Simulated Author's Rebuttal
We thank the referee for the positive summary of the work's contributions and for highlighting the importance of validating the LLM-as-a-judge protocol. We address the single major comment below.
read point-by-point responses
-
Referee: [Evaluation] Abstract and Evaluation section: All headline results—the 4.92-point spread, per-model rankings, and identification of Mathematical Reasoning and Image Understanding as hardest—are derived exclusively from LLM-as-a-judge scores on 919 subquestions. No human validation, correlation coefficient, Cohen’s kappa, or even spot-check agreement with human graders on the Portuguese open-ended answers is reported. Without this anchor, differences cannot be distinguished from judge artifacts.
Authors: We agree that the absence of human validation metrics is a limitation of the current manuscript. The LLM-as-a-judge approach was selected for its scalability across 919 subquestions and to enable consistent, rubric-based scoring of open-ended Portuguese responses at reasonable cost. However, we recognize that this leaves open the possibility of judge-specific artifacts. In the revised version we will add a human validation subsection: we will recruit Portuguese-speaking graders to score a stratified random sample of at least 100 subquestions (covering all subjects and image/text conditions) and report Pearson/Spearman correlations, Cohen’s kappa, and mean absolute difference between human and LLM-judge scores. This will provide the requested empirical anchor while preserving the full public release of data and code. revision: yes
Circularity Check
No circularity: direct empirical benchmarking on external exam data
full rationale
The paper performs straightforward empirical evaluation: it collects 395 questions/919 subquestions from public Brazilian university entrance exams (2022-2025), annotates them with subjects, reference answers, and capability tags, then applies an LLM-as-a-judge protocol to score 21 models. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps are present in the abstract or described methodology. The central results (performance spread and hardest dimensions) are computed outputs from the stated protocol applied to new data, not reductions to the inputs by construction. This matches the default case of a self-contained empirical benchmark with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Intelligent Systems (BRACIS 2023)
Almeida, T.S., Laitz, T., Bonás, G.K., Nogueira, R.: BLUEX: A Benchmark Based on Brazilian Leading Universities Entrance Exams. In: Intelligent Systems (BRACIS 2023). Lecture Notes in Computer Science, vol. 14195, pp. 337–347. Springer (2023).https://doi.org/10.1007/978-3-031-45368-7_22
-
[2]
Educational and Psy- chological Measurement20, 37 – 46 (1960)
Cohen, J.: A Coefficient of Agreement for Nominal Scales. Educational and Psy- chological Measurement20, 37 – 46 (1960)
1960
-
[3]
ao Guilherme Alves Santos, J., Bonás, G.K., Laitz, T., Almeida, T.S., Pedrini, H.: BLUEX-v2: Benchmarking LLMs on open-ended questions from Brazilian univer- sity entrance exams.https://huggingface.co/datasets/Tropic-AI/BLUEX-v2 (2026)
2026
-
[4]
In: International Con- ference on Learning Representations (ICLR) (2021)
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring Massive Multitask Language Understanding. In: International Con- ference on Learning Representations (ICLR) (2021)
2021
- [5]
-
[6]
arXiv preprint arXiv:2603.10213 (2026)
Laitz, T., Almeida, T.S., Abonizio, H., Junior, R.M., Bonás, G.K., Piau, M., Larcher, C., Pires, R., Nogueira, R.: Sabiá-4 technical report. arXiv preprint arXiv:2603.10213 (2026)
-
[7]
Biometrics pp
Landis, J.R., Koch, G.G.: An Application of Hierarchical kappa-type Statistics in the Assessment of Majority Agreement among Multiple Observers. Biometrics pp. 363–374 (1977)
1977
-
[8]
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., Zhu, C.: G-Eval: NLG Evaluation us- ing GPT-4 with Better Human Alignment (2023),https://arxiv.org/abs/2303. 16634
2023
-
[9]
arXiv preprint arXiv:2303.17003 (2023)
Nunes, D., Primi, R., Pires, R., Lotufo, R., Nogueira, R.: Evaluating GPT-3.5 and GPT-4 Models on Brazilian University Admission Exams. arXiv preprint arXiv:2303.17003 (2023)
-
[10]
arXiv preprint arXiv:2504.21202 (2025)
Pires, R., Junior, R.M., Nogueira, R.: Automatic Legal Writing Evaluation of LLMs. arXiv preprint arXiv:2504.21202 (2025)
-
[11]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Rein, D., Hou, B.L., Stickland, A.C., Petty, J., Pang, R.Y., Dirani, J., Michael, J., Bowman, S.R.: GPQA: A Graduate-Level Google-Proof Q&A Benchmark. arXiv preprint arXiv:2311.12022 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
In: Proceedings of ENIAC (2025)
Santos, J.G.A., Bonás, G.K., Almeida, T.S.: BLUEX Revisited: Enhancing Bench- mark Coverage with Automatic Captioning. In: Proceedings of ENIAC (2025)
2025
-
[13]
In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E.P., Zhang, H., Gonzalez, J.E., Stoica, I.: Judging LLM-as-a- Judge with MT-Bench and Chatbot Arena. In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
2023
-
[14]
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models
Zhong, W., Cui, R., Guo, Y., Liang, Y., Lu, S., Wang, Y., Saied, A., Chen, W., Duan,N.:AGIEval:AHuman-CentricBenchmarkforEvaluatingFoundationMod- els. arXiv preprint arXiv:2304.06364 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.