IndicGuard: A Multilingual Safety Guard Model and Dataset for Indic Languages
Pith reviewed 2026-06-26 08:45 UTC · model grok-4.3
The pith
IndicGuard is a safety guard model and dataset built for ten Indic languages to catch regional harms and jailbreaks that English models miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
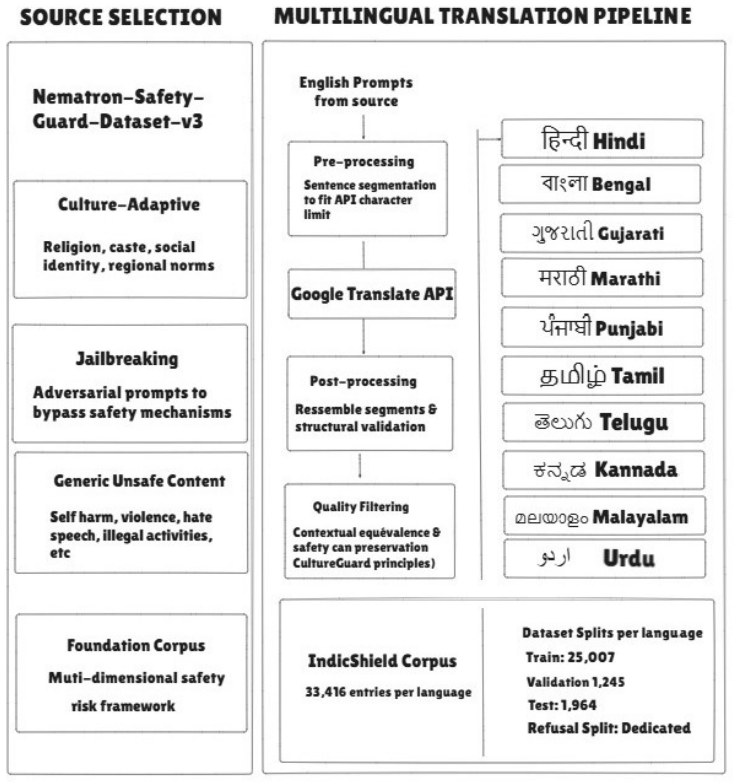
IndicGuard, constructed from a high-volume culturally nuanced safety dataset for ten Indic languages that includes regional harms, sensitive socio-political contexts, and adversarial jailbreaks, yields a fine-tuned 4B model that enhances LLM robustness against localized vulnerabilities, delivers high moderation consistency across turns, outperforms CultureGuard, and generalizes to low-resource Indic languages excluded from training.
What carries the argument
IndicGuard, the 4B-parameter model fine-tuned from Gemma-3-4B-IT on the curated Indic safety dataset, used for real-time content moderation and policy compliance checking.
If this is right
- LLMs equipped with IndicGuard will show higher moderation consistency across multiple conversational turns.
- Safety performance will exceed that of CultureGuard on the evaluated Indic languages.
- The same fine-tuning approach will extend protection to low-resource Indic languages never seen during training.
Where Pith is reading between the lines
- Guard models built the same way could be created for other language families that have distinct cultural harm categories.
- Native-language safety checks could reduce the need to translate Indic content into English before moderation.
- The results point to the value of language-specific datasets when aligning models for regions outside high-resource English data.
Load-bearing premise
The curated dataset systematically and accurately captures regional harms, sensitive socio-political contexts, and adversarial jailbreaks in a way that supports real-world generalization.
What would settle it
Run IndicGuard and CultureGuard on a held-out test set of real Indic-language prompts containing socio-political sensitivities or jailbreaks and measure whether IndicGuard shows no improvement in moderation accuracy or consistency.
Figures



read the original abstract
As Large Language Models (LLMs) achieve widespread integration across diverse linguistic landscapes, ensuring their safety and alignment with regional normative values remains a critical challenge. Current safety mechanisms are predominantly optimized for English-centric frameworks, often failing to capture the unique socio-cultural sensitivities and localized categories of harm inherent to the Indic region. To address this gap, we introduce IndicGuard, a multilingual safety guard model and dataset for Indic languages. We construct a high-volume, culturally nuanced safety dataset encompassing ten major Indic languages, systematically curated to capture regional harms, sensitive socio-political contexts, and adversarial jailbreaks. Leveraging this corpus, we fine-tune a 4B-parameter instruction-tuned model based on Gemma-3-4B-IT to serve as a multilingual safety guardrail for real-time content moderation and policy compliance checking. Our empirical evaluations demonstrate that IndicGuard significantly enhances LLM robustness against localized vulnerabilities, achieving high moderation consistency across different conversational turns. Crucially, IndicGuard consistently outperforms the existing baseline model, CultureGuard, across evaluated languages. Finally, we demonstrate that our model effectively generalizes to low-resource Indic languages excluded from training, substantiating the structural robustness and cross-lingual transfer capabilities of the framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces IndicGuard, a multilingual safety guard model and dataset for Indic languages. It constructs a high-volume, culturally nuanced safety dataset for ten major Indic languages capturing regional harms, sensitive socio-political contexts, and adversarial jailbreaks; fine-tunes a 4B-parameter instruction-tuned model based on Gemma-3-4B-IT; and claims that the resulting guardrail enhances LLM robustness against localized vulnerabilities, achieves high moderation consistency, consistently outperforms the CultureGuard baseline across evaluated languages, and generalizes to low-resource Indic languages excluded from training.
Significance. If the empirical results hold with proper controls, this would address a meaningful gap in non-English LLM safety for Indic languages, which have distinct socio-cultural sensitivities not covered by English-centric frameworks. The cross-lingual generalization claim to unseen low-resource languages, if substantiated, would be a notable strength for extending safety mechanisms beyond high-resource settings.
major comments (2)
- [Abstract and §5] Abstract and §5 (Experiments): the central claims of outperformance over CultureGuard and generalization to excluded languages are asserted without any reported metrics, baselines, data splits, error bars, or evaluation protocol details; this is load-bearing for the empirical contribution and prevents assessment of whether the results support the headline conclusions.
- [§3] §3 (Dataset Construction): the description of how the corpus systematically captures regional harms, socio-political contexts, and adversarial jailbreaks lacks quantitative details on coverage, annotation guidelines, inter-annotator agreement, or validation steps; this directly underpins the weakest assumption regarding real-world generalization and cross-lingual transfer.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., accuracy delta vs. baseline) to ground the claims of outperformance.
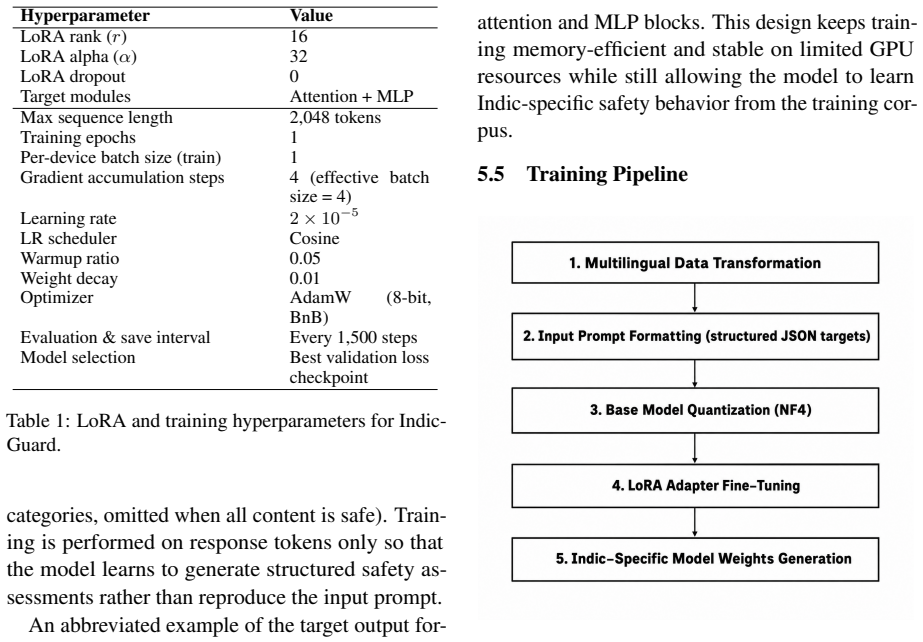
- [§4] Notation for the ten Indic languages and the exact fine-tuning hyperparameters should be listed explicitly in a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comments point by point below and will revise the manuscript to provide the requested details.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experiments): the central claims of outperformance over CultureGuard and generalization to excluded languages are asserted without any reported metrics, baselines, data splits, error bars, or evaluation protocol details; this is load-bearing for the empirical contribution and prevents assessment of whether the results support the headline conclusions.
Authors: We agree that the abstract and §5 currently lack the quantitative details needed to substantiate the claims. In the revised version we will add explicit performance metrics (e.g., F1, accuracy) for IndicGuard versus CultureGuard across all evaluated languages, train/validation/test split sizes, the precise evaluation protocol, and error bars or confidence intervals from multiple runs. These additions will allow readers to assess the strength of the outperformance and generalization results. revision: yes
-
Referee: [§3] §3 (Dataset Construction): the description of how the corpus systematically captures regional harms, socio-political contexts, and adversarial jailbreaks lacks quantitative details on coverage, annotation guidelines, inter-annotator agreement, or validation steps; this directly underpins the weakest assumption regarding real-world generalization and cross-lingual transfer.
Authors: We acknowledge that §3 would be strengthened by quantitative and procedural details. We will expand the section to report dataset coverage statistics (instances per language and harm category), the complete annotation guidelines, inter-annotator agreement scores, and the validation procedures used. This will better document how regional harms and contexts were captured and support claims about generalization. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript describes an empirical pipeline of dataset curation across ten Indic languages followed by fine-tuning of Gemma-3-4B-IT and standard hold-out evaluation; no equations, derivations, or parameter-fitting steps are present that could reduce a claimed prediction to its own inputs by construction. All performance claims rest on external test sets and cross-lingual generalization experiments rather than self-referential definitions or self-citation chains. The work is therefore self-contained as a conventional ML engineering contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The constructed dataset captures regional harms, sensitive socio-political contexts, and adversarial jailbreaks in a culturally accurate and comprehensive way.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Muhammad Farid Adilazuarda, Sagnik Mukherjee, Pradhyumna Lavania, Siddhant Shivdutt Singh, Alham Fikri Aji, Jacki O’Neill, Ashutosh Modi, and Monojit Choudhury. 2024. Towards measuring and modeling “culture” in llms: A survey. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15763--15784
2024
-
[10]
Masoomali Fatehkia, Enes Altinisik, and Husrev Taha Sencar. 2026. Fanarguard: A culturally-aware moderation filter for arabic language models. In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7848--7869
2026
-
[11]
Shaona Ghosh, Prasoon Varshney, Makesh Narsimhan Sreedhar, Aishwarya Padmakumar, Traian Rebedea, Jibin Rajan Varghese, and Christopher Parisien. 2025. Aegis2. 0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational L...
2025
-
[12]
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. 2024. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms. Advances in neural information processing systems, 37:8093--8131
2024
-
[14]
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. 2023. Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36:24678--24704
2023
-
[16]
Raviraj Bhuminand Joshi, Rakesh Paul, Kanishk Singla, Anusha Kamath, Michael Evans, Katherine Luna, Shaona Ghosh, Utkarsh Vaidya, Eileen Margaret Peters Long, Sanjay Singh Chauhan, and 1 others. 2025. Cultureguard: Towards culturally-aware dataset and guard model for multilingual safety applications. In Proceedings of the 14th International Joint Conferen...
2025
-
[17]
Chen Cecilia Liu, Iryna Gurevych, and Anna Korhonen. 2025. Culturally aware and adapted nlp: A taxonomy and a survey of the state of the art. Transactions of the Association for Computational Linguistics, 13:652--689
2025
-
[18]
Todor Markov, Chong Zhang, Sandhini Agarwal, Florentine Eloundou Nekoul, Theodore Lee, Steven Adler, Angela Jiang, and Lilian Weng. 2023. A holistic approach to undesired content detection in the real world. In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 15009--15018
2023
-
[20]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
-
[21]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728--53741
2023
-
[22]
Paul R \"o ttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. 2024. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Lo...
2024
-
[23]
Kush R Varshney. 2024. Decolonial ai alignment: Openness, visesa-dharma, and including excluded knowledges. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 7, pages 1467--1481
2024
-
[26]
0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails , author=
Aegis2. 0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[27]
Cultureguard: Towards culturally-aware dataset and guard model for multilingual safety applications , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[28]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
FanarGuard: A Culturally-Aware Moderation Filter for Arabic Language Models , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[29]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Towards measuring and modeling “culture” in LLMs: A survey , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[30]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[31]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[32]
arXiv preprint arXiv:2212.08073 , year=
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
-
[33]
Advances in neural information processing systems , volume=
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms , author=. Advances in neural information processing systems , volume=
-
[34]
Advances in Neural Information Processing Systems , volume=
Beavertails: Towards improved safety alignment of llm via a human-preference dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
arXiv preprint arXiv:2312.06674 , year=
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
-
[36]
Proceedings of the AAAI conference on artificial intelligence , volume=
A holistic approach to undesired content detection in the real world , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[37]
arXiv preprint arXiv:2402.04249 , year=
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal , author=. arXiv preprint arXiv:2402.04249 , year=
-
[38]
arXiv preprint arXiv:2407.21772 , year=
Shieldgemma: Generative ai content moderation based on gemma , author=. arXiv preprint arXiv:2407.21772 , year=
-
[39]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[40]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[41]
Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations , pages=
Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails , author=. Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations , pages=
2023
-
[42]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
CantTalkAboutThis: Aligning language models to stay on topic in dialogues , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[43]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
Decolonial AI alignment: Openness, visesa-dharma, and including excluded knowledges , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
-
[44]
Transactions of the Association for Computational Linguistics , volume=
Culturally aware and adapted nlp: A taxonomy and a survey of the state of the art , author=. Transactions of the Association for Computational Linguistics , volume=. 2025 , publisher=
2025
-
[45]
arXiv preprint arXiv:2308.16149 , year=
Jais and jais-chat: Arabic-centric foundation and instruction-tuned open generative large language models , author=. arXiv preprint arXiv:2308.16149 , year=
-
[46]
arXiv preprint arXiv:2307.15043 , year=
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[47]
arXiv preprint arXiv:2205.14728 , year=
L3cube-mahanlp: Marathi natural language processing datasets, models, and library , author=. arXiv preprint arXiv:2205.14728 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.