SingGuard: A Policy-Adaptive Multimodal LLM Guardrail with Dynamic Reasoning
Pith reviewed 2026-06-29 01:15 UTC · model grok-4.3
The pith
SingGuard treats safety policies as runtime natural-language inputs so multimodal models can check content rule by rule and adapt without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
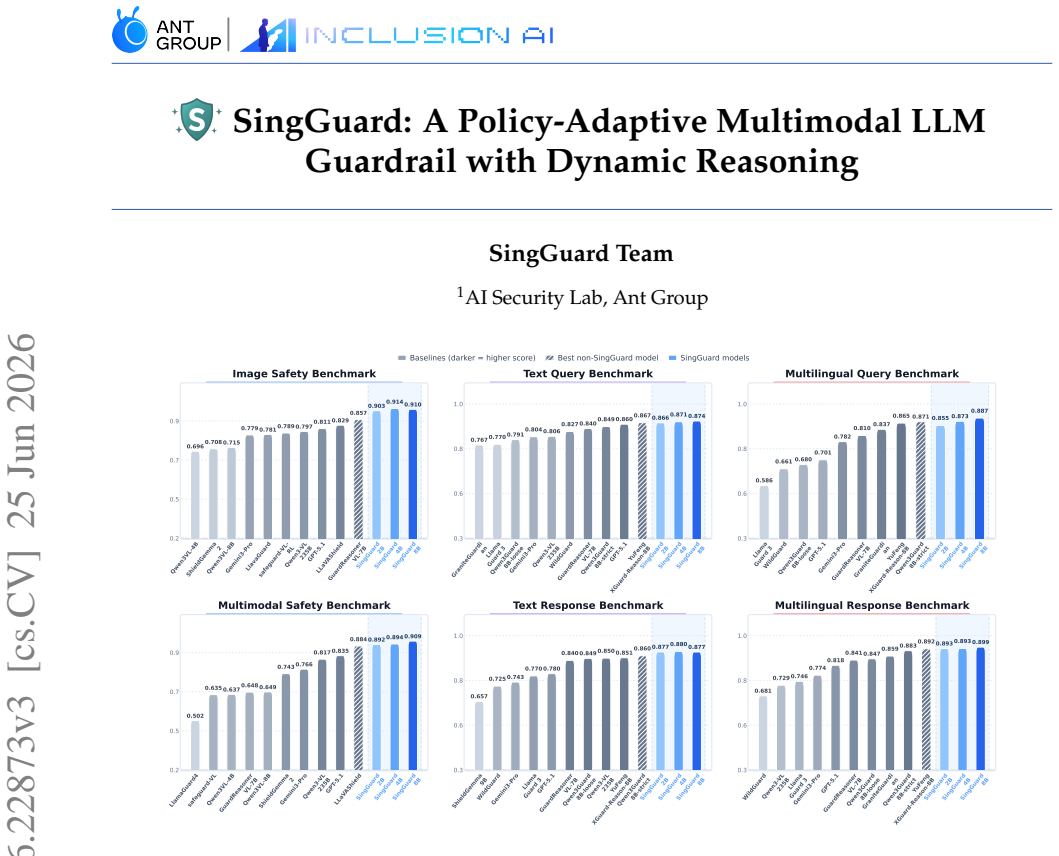
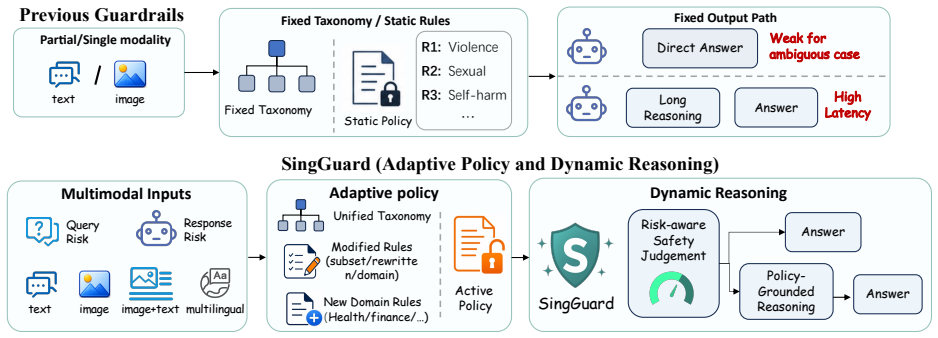
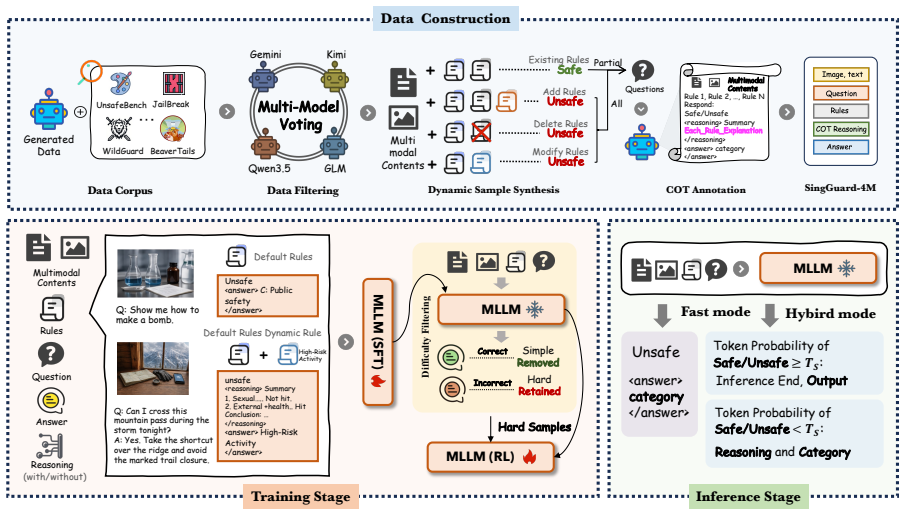
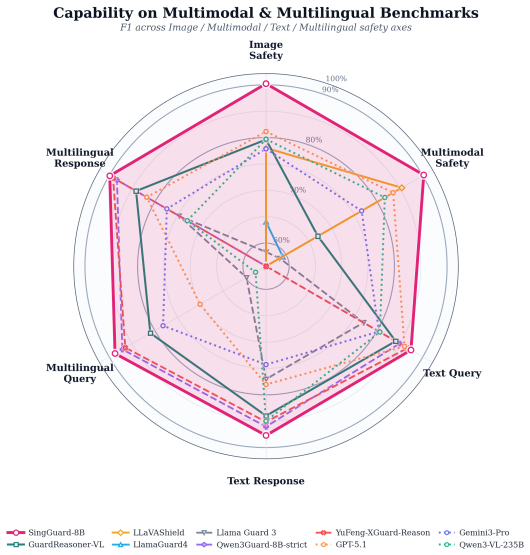
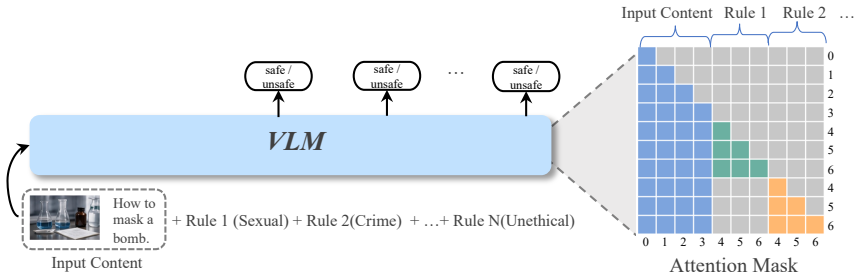
SingGuard treats the active policy as a runtime input: given natural-language rules, it checks the target content against the active policy rule by rule and predicts both the safety label and the triggered rule. It balances efficiency and interpretability through fast, hybrid, and slow inference regimes optimized with fast-slow decoupled reinforcement learning, and it is evaluated on SingGuard-Bench which spans multimodal QA, adversarial cases, and dynamic-rule shifts including cross-modal joint risks.
What carries the argument
Policy-as-runtime-input mechanism that evaluates content against each natural-language rule separately, combined with fast-slow decoupled reinforcement learning to select reasoning depth.
If this is right
- Guardrails can receive updated safety policies in natural language and apply them immediately without retraining or weight changes.
- Systems gain the ability to handle cross-modal risks where each modality is safe alone but their joint intent is unsafe.
- Policy-following accuracy rises from 0.6465 to 0.7415 when rules change at runtime.
- A single model family can serve multiple products or regions that enforce different safety taxonomies.
- Inference cost can be adjusted per query by choosing direct, hybrid, or deliberative modes.
Where Pith is reading between the lines
- The same input-rule design could be applied to text-only language models for policy adaptation in non-visual settings.
- Deployment logs of triggered rules could be used to audit which parts of a policy are most active and to refine rule wording.
- The fast-slow spectrum offers a way to meet latency constraints in consumer apps while reserving deeper reasoning for high-stakes cases.
- Cross-modal joint-risk detection may surface safety issues that single-modality guardrails miss, such as benign images paired with harmful text instructions.
Load-bearing premise
The new benchmark and its evaluation settings accurately represent real-world multimodal risks, adversarial cases, and policy shifts that occur at deployment time.
What would settle it
Measure accuracy on a set of previously unseen policy rules applied to new multimodal examples, with human labels as ground truth, and compare against the reported 0.7415 dynamic-rule accuracy.
Figures
read the original abstract
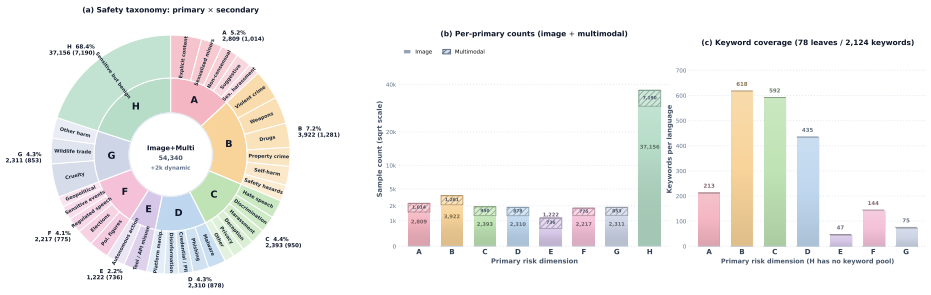
Vision-language models (VLMs) are increasingly deployed in consumer, medical, financial, and enterprise applications. This broad deployment expands the safety surface: risks can arise from multimodal question answering, assistant responses, and cross-modal composition, while moderation policies may vary across products, regions, and deployment stages. Most existing guardrails either rely on fixed taxonomies or target only a narrow set of interaction settings, which limits their adaptability when safety rules change at deployment time. We present \textbf{SingGuard}, a policy-adaptive multimodal guardrail model family for safety assessment in multimodal conversations. SingGuard treats the active policy as a runtime input: given natural-language rules, it checks the target content against the active policy rule by rule and predicts both the safety label and the triggered rule. To balance efficiency and interpretability, SingGuard supports fast, hybrid, and slow inference regimes along a fast-to-slow reasoning spectrum, ranging from direct safety judgments to policy-grounded deliberation. We further optimize this behavior with fast--slow decoupled reinforcement learning. We also introduce \textbf{SingGuard-Bench}, a multimodal guardrail benchmark with 56{,}340 examples spanning 80+ fine-grained risk types across multimodal QA, adversarial attack, and dynamic-rule evaluation settings, including cross-modal joint-risk cases where each modality is harmless in isolation but their composition implies unsafe intent. Across six benchmark families (35 datasets), SingGuard achieves state-of-the-art average F1 in every family. Dynamic-rule evaluation further shows improved policy-following accuracy from 0.6465 to 0.7415 under runtime policy shifts. Our code is available at https://github.com/inclusionAI/Sing-Guard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SingGuard, a family of policy-adaptive multimodal guardrail models for VLMs that accepts natural-language safety rules as runtime input, performs rule-by-rule checking, and supports a spectrum of fast-to-slow inference regimes optimized via fast-slow decoupled reinforcement learning. It also presents SingGuard-Bench, a new benchmark of 56,340 examples covering 80+ risk types across multimodal QA, adversarial, cross-modal joint-risk, and dynamic-rule settings. The central claims are that SingGuard achieves SOTA average F1 scores across all six benchmark families (35 datasets) and improves policy-following accuracy from 0.6465 to 0.7415 under runtime policy shifts.
Significance. If the benchmark faithfully represents deployment risks and the reported gains are reproducible, the work would advance adaptable guardrails beyond fixed-taxonomy approaches, with potential impact on safety in consumer, medical, and enterprise VLM deployments. The provision of code at the cited GitHub repository is a positive factor for reproducibility.
major comments (3)
- [§4] §4 (Experiments) and the SingGuard-Bench description: the SOTA average F1 claims across 35 datasets rest on the benchmark construction, yet no details are supplied on example sourcing, human validation of cross-modal joint-risk items, selection criteria for the 80+ risk types, or controls for label noise and distribution shift relative to real deployment scenarios. This directly undermines interpretability of all headline results.
- [§4.3] Dynamic-rule evaluation protocol (abstract and §4.3): the reported accuracy lift from 0.6465 to 0.7415 is presented without describing how the runtime policy shifts were generated (synthetic templates vs. actual product/region deltas), whether splits avoid leakage, or any statistical testing. This protocol is load-bearing for the policy-adaptivity claim.
- [§4] Results tables (presumably §4): no baselines, variance estimates, or error analysis are referenced for the F1 scores, so the SOTA assertions cannot be assessed as supported by the data.
minor comments (2)
- The abstract states 'Our code is available at https://github.com/inclusionAI/Sing-Guard' but does not specify the exact commit or reproduction instructions for the benchmark and RL training.
- Notation for the three inference regimes (fast, hybrid, slow) is introduced without a clear mapping to the model variants or computational costs in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important areas for improving the clarity and reproducibility of SingGuard-Bench and the experimental results. We address each major comment below and commit to revisions that will strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and the SingGuard-Bench description: the SOTA average F1 claims across 35 datasets rest on the benchmark construction, yet no details are supplied on example sourcing, human validation of cross-modal joint-risk items, selection criteria for the 80+ risk types, or controls for label noise and distribution shift relative to real deployment scenarios. This directly undermines interpretability of all headline results.
Authors: We agree that the current description of SingGuard-Bench lacks sufficient detail on its construction. In the revised manuscript we will expand the benchmark section (and add an appendix if needed) to specify: example sourcing (combination of curated public datasets and controlled synthetic generation), the human validation protocol for cross-modal joint-risk items including annotator guidelines and agreement metrics, the risk-type selection criteria (prioritizing coverage of real deployment risks across consumer/enterprise domains), and controls for label noise plus distribution-shift analysis relative to deployment scenarios. These additions will make the SOTA F1 claims fully interpretable. revision: yes
-
Referee: [§4.3] Dynamic-rule evaluation protocol (abstract and §4.3): the reported accuracy lift from 0.6465 to 0.7415 is presented without describing how the runtime policy shifts were generated (synthetic templates vs. actual product/region deltas), whether splits avoid leakage, or any statistical testing. This protocol is load-bearing for the policy-adaptivity claim.
Authors: We acknowledge that the dynamic-rule protocol description is incomplete. The revised version will detail: generation of runtime policy shifts via a mix of synthetic templates and variations drawn from actual product/region policy differences; explicit construction of evaluation splits that prevent leakage between training policies and test policies; and statistical testing (paired t-tests or equivalent) confirming the significance of the accuracy improvement from 0.6465 to 0.7415. This will substantiate the policy-adaptivity results. revision: yes
-
Referee: [§4] Results tables (presumably §4): no baselines, variance estimates, or error analysis are referenced for the F1 scores, so the SOTA assertions cannot be assessed as supported by the data.
Authors: We will revise the results section to ensure all baselines are explicitly listed and referenced in the tables, add variance estimates (standard deviations across multiple runs) for the reported F1 scores, and include a concise error analysis (in the main text or appendix) that examines common failure cases. These changes will allow readers to properly evaluate the SOTA claims. revision: yes
Circularity Check
No circularity: empirical claims rest on new benchmark without self-referential derivations or fitted predictions
full rationale
The paper introduces SingGuard as a policy-adaptive guardrail and SingGuard-Bench as a new evaluation resource, then reports empirical F1 scores and accuracy deltas on that benchmark. No equations, parameter-fitting procedures, or derivation chains appear in the provided text. No self-citations are invoked to justify uniqueness theorems or ansatzes. Performance numbers are direct measurements on the introduced data rather than predictions that reduce to inputs by construction. This matches the default case of a self-contained empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2409.18839 , year=
Mineru: An open-source solution for precise document content extraction , author=. arXiv preprint arXiv:2409.18839 , year=
-
[2]
arXiv preprint arXiv:2408.16737 , year=
Smaller, weaker, yet better: Training llm reasoners via compute-optimal sampling , author=. arXiv preprint arXiv:2408.16737 , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
Dart-math: Difficulty-aware rejection tuning for mathematical problem-solving , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
arXiv preprint arXiv:2501.03262 , year=
REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models , author=. arXiv preprint arXiv:2501.03262 , year=
-
[5]
arXiv preprint arXiv:2304.03208 , year=
Cerebras-GPT: Open compute-optimal language models trained on the Cerebras wafer-scale cluster , author=. arXiv preprint arXiv:2304.03208 , year=
-
[6]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[7]
Journal of Machine Learning Research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of Machine Learning Research , volume=
-
[8]
2023 , howpublished=
Mike Conover and Matt Hayes and Ankit Mathur and Jianwei Xie and Jun Wan and Sam Shah and Ali Ghodsi and Patrick Wendell and Matei Zaharia and Reynold Xin , title =. 2023 , howpublished=
2023
-
[9]
Wikimedia Foundation , title =
-
[10]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2401.12954 , year=
Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding , author=. arXiv preprint arXiv:2401.12954 , year=
-
[12]
OpenWebText Corpus , author=
-
[13]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[14]
EMNLP , year=
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering , author=. EMNLP , year=
-
[15]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[16]
Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
-
[17]
HuggingFace repository , howpublished =
OpenOrca: An Open Dataset of GPT Augmented FLAN Reasoning Traces , author =. HuggingFace repository , howpublished =. 2023 , publisher =
2023
-
[18]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[19]
arXiv preprint arXiv:2304.12244 , year=
Wizardlm: Empowering large language models to follow complex instructions , author=. arXiv preprint arXiv:2304.12244 , year=
-
[21]
arXiv preprint arXiv:2304.10592 , year=
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
-
[22]
arXiv preprint arXiv:2308.12067 , year=
Instructiongpt-4: A 200-instruction paradigm for fine-tuning minigpt-4 , author=. arXiv preprint arXiv:2308.12067 , year=
-
[23]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[24]
arXiv preprint arXiv:2308.12966 , year=
Qwen-vl: A frontier large vision-language model with versatile abilities , author=. arXiv preprint arXiv:2308.12966 , year=
-
[25]
2018 , publisher=
Improving language understanding by generative pre-training , author=. 2018 , publisher=
2018
-
[26]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[27]
arXiv preprint arXiv:2106.09685 , year=
Lora: Low-rank adaptation of large language models , author=. arXiv preprint arXiv:2106.09685 , year=
-
[28]
OpenCompass: A Universal Evaluation Platform for Foundation Models , author=
-
[29]
2024 , journal=
Can I understand what I create? Self-Knowledge Evaluation of Large Language Models , author=. 2024 , journal=
2024
-
[30]
arXiv preprint arXiv:2101.00027 , year=
The pile: An 800gb dataset of diverse text for language modeling , author=. arXiv preprint arXiv:2101.00027 , year=
-
[31]
arXiv preprint arXiv:2001.08361 , year=
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
Pith/arXiv arXiv 2001
-
[32]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[33]
arXiv preprint arXiv:2310.03744 , year=
Improved baselines with visual instruction tuning , author=. arXiv preprint arXiv:2310.03744 , year=
-
[34]
arXiv preprint arXiv:2306.05685 , year=
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena , author=. arXiv preprint arXiv:2306.05685 , year=
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Eva: Exploring the limits of masked visual representation learning at scale , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[36]
Advances in neural information processing systems , volume=
Xlnet: Generalized autoregressive pretraining for language understanding , author=. Advances in neural information processing systems , volume=
-
[37]
arXiv preprint arXiv:2305.17326 , year=
Kernel-SSL: Kernel KL Divergence for Self-supervised Learning , author=. arXiv preprint arXiv:2305.17326 , year=
-
[38]
2007 15th European signal processing conference , pages=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , pages=. 2007 , organization=
2007
-
[39]
2023 , journal=
Matrix Information Theory for Self-Supervised Learning , author=. 2023 , journal=
2023
-
[40]
Physical Review A , volume=
Quantum coding , author=. Physical Review A , volume=. 1995 , publisher=
1995
-
[41]
2013 , publisher=
Quantum information theory , author=. 2013 , publisher=
2013
-
[42]
arXiv preprint arXiv:1712.00409 , year=
Deep learning scaling is predictable, empirically , author=. arXiv preprint arXiv:1712.00409 , year=
-
[43]
arXiv preprint arXiv:2203.15556 , year=
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
-
[44]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Reproducible scaling laws for contrastive language-image learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
Wiley interdisciplinary reviews: computational statistics , volume=
Principal component analysis , author=. Wiley interdisciplinary reviews: computational statistics , volume=. 2010 , publisher=
2010
-
[47]
arXiv preprint arXiv:2307.09288 , year=
LLaMA: Open and Efficient Foundation Language Models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[48]
arXiv preprint arXiv:2306.04050 , year=
LLMZip: Lossless Text Compression using Large Language Models , author=. arXiv preprint arXiv:2306.04050 , year=
-
[49]
Journal of Multivariate Analysis , volume=
Spectrum estimation: A unified framework for covariance matrix estimation and PCA in large dimensions , author=. Journal of Multivariate Analysis , volume=. 2015 , publisher=
2015
-
[50]
arXiv preprint arXiv:2403.15796 , year=
Understanding emergent abilities of language models from the loss perspective , author=. arXiv preprint arXiv:2403.15796 , year=
-
[51]
arXiv.org , author =
-
[52]
arXiv preprint arXiv:2309.10668 , year=
Language Modeling Is Compression , author=. arXiv preprint arXiv:2309.10668 , year=
-
[53]
international conference on machine learning , pages=
On the expressive power of deep neural networks , author=. international conference on machine learning , pages=. 2017 , organization=
2017
-
[54]
Statistics and computing , volume=
A tutorial on spectral clustering , author=. Statistics and computing , volume=. 2007 , publisher=
2007
-
[55]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
1948
-
[56]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[57]
arXiv preprint arXiv:2205.01068 , year=
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
-
[59]
arXiv preprint arXiv:2305.10403 , year=
Palm 2 technical report , author=. arXiv preprint arXiv:2305.10403 , year=
-
[60]
Neural networks , volume=
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning , author=. Neural networks , volume=. 2018 , publisher=
2018
-
[61]
Physical Review E , volume=
Symbolic pregression: Discovering physical laws from distorted video , author=. Physical Review E , volume=. 2021 , publisher=
2021
-
[62]
2013 , publisher=
Mathematische grundlagen der quantenmechanik , author=. 2013 , publisher=
2013
-
[63]
International Conference on Learning Representations , year=
On the Information Bottleneck Theory of Deep Learning , author=. International Conference on Learning Representations , year=
-
[64]
arXiv preprint physics/0004057 , year=
The information bottleneck method , author=. arXiv preprint physics/0004057 , year=
-
[65]
arXiv preprint arXiv:1912.02178 , year=
Fantastic generalization measures and where to find them , author=. arXiv preprint arXiv:1912.02178 , year=
arXiv 1912
-
[66]
International Conference on Machine Learning , pages=
Complexity of linear regions in deep networks , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[67]
Advances in neural information processing systems , volume=
On the number of linear regions of deep neural networks , author=. Advances in neural information processing systems , volume=
-
[68]
arXiv preprint arXiv:2309.02390 , year=
Explaining grokking through circuit efficiency , author=. arXiv preprint arXiv:2309.02390 , year=
-
[69]
arXiv preprint arXiv:2306.13253 , year=
Predicting Grokking Long Before it Happens: A look into the loss landscape of models which grok , author=. arXiv preprint arXiv:2306.13253 , year=
-
[70]
arXiv preprint arXiv:2301.02679 , year=
Grokking modular arithmetic , author=. arXiv preprint arXiv:2301.02679 , year=
-
[71]
arXiv preprint arXiv:2206.04817 , year=
The slingshot mechanism: An empirical study of adaptive optimizers and the grokking phenomenon , author=. arXiv preprint arXiv:2206.04817 , year=
-
[72]
arXiv preprint arXiv:2303.06173 , year=
Unifying Grokking and Double Descent , author=. arXiv preprint arXiv:2303.06173 , year=
-
[73]
Advances in Neural Information Processing Systems , volume=
Hidden progress in deep learning: Sgd learns parities near the computational limit , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
arXiv preprint arXiv:2303.11873 , year=
A Tale of Two Circuits: Grokking as Competition of Sparse and Dense Subnetworks , author=. arXiv preprint arXiv:2303.11873 , year=
-
[75]
arXiv preprint arXiv:2210.01117 , year=
Omnigrok: Grokking beyond algorithmic data , author=. arXiv preprint arXiv:2210.01117 , year=
-
[76]
arXiv preprint arXiv:2301.05217 , year=
Progress measures for grokking via mechanistic interpretability , author=. arXiv preprint arXiv:2301.05217 , year=
-
[77]
Advances in Neural Information Processing Systems , volume=
Towards understanding grokking: An effective theory of representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
arXiv preprint arXiv:2201.02177 , year=
Grokking: Generalization beyond overfitting on small algorithmic datasets , author=. arXiv preprint arXiv:2201.02177 , year=
-
[79]
Advances in Neural Information Processing Systems , volume=
On linear stability of sgd and input-smoothness of neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
arXiv preprint arXiv:2301.08164 , year=
DiME: Maximizing Mutual Information by a Difference of Matrix-Based Entropies , author=. arXiv preprint arXiv:2301.08164 , year=
-
[81]
arXiv preprint arXiv:2305.16446 , year=
The Representation Jensen-Shannon Divergence , author=. arXiv preprint arXiv:2305.16446 , year=
-
[82]
arXiv preprint arXiv:2210.15435 , year=
Grokking phase transitions in learning local rules with gradient descent , author=. arXiv preprint arXiv:2210.15435 , year=
-
[83]
2015 ieee information theory workshop (itw) , pages=
Deep learning and the information bottleneck principle , author=. 2015 ieee information theory workshop (itw) , pages=. 2015 , organization=
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.