SpotAttention: Plug-In Block-Sparse Routing for Pretrained Long-Context Transformers
Pith reviewed 2026-06-26 08:57 UTC · model grok-4.3
The pith
SpotAttention attaches a lightweight selector to frozen transformers so they can attend sparsely to only the relevant past tokens while matching full-attention accuracy at 128K context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
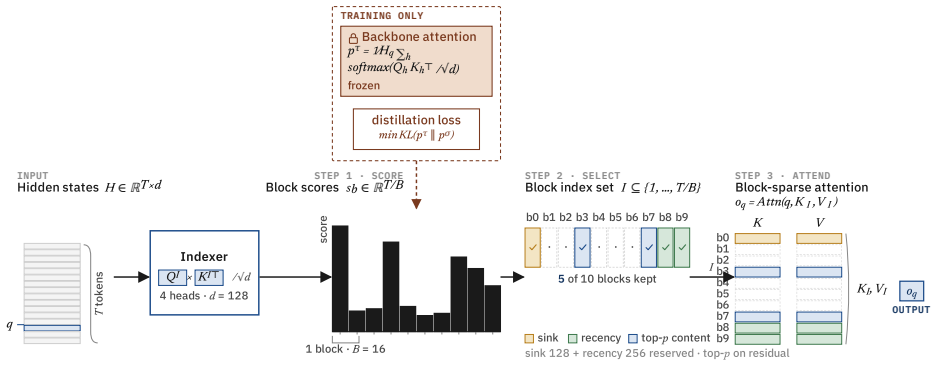
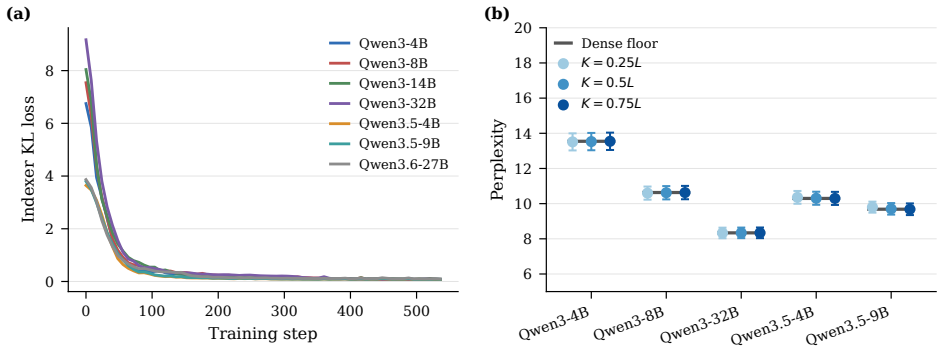
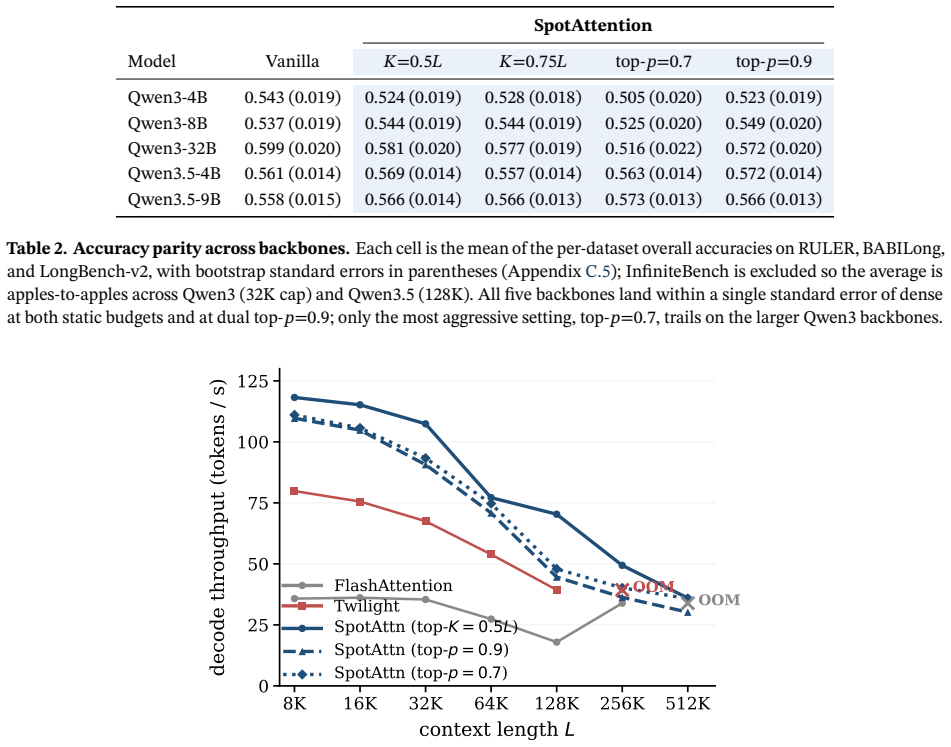
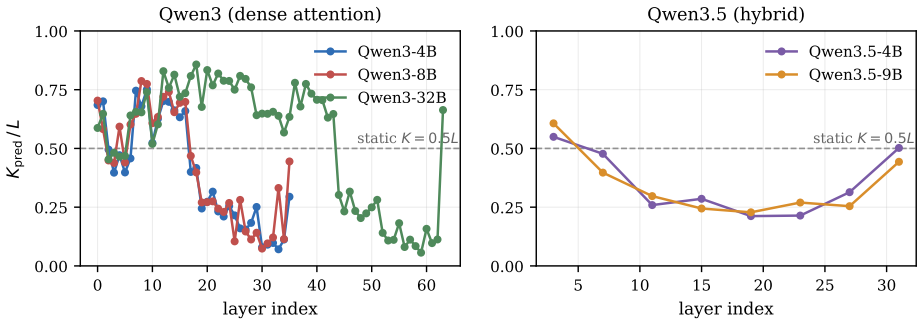
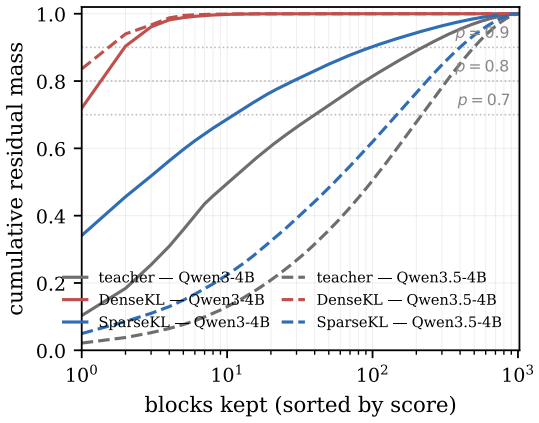
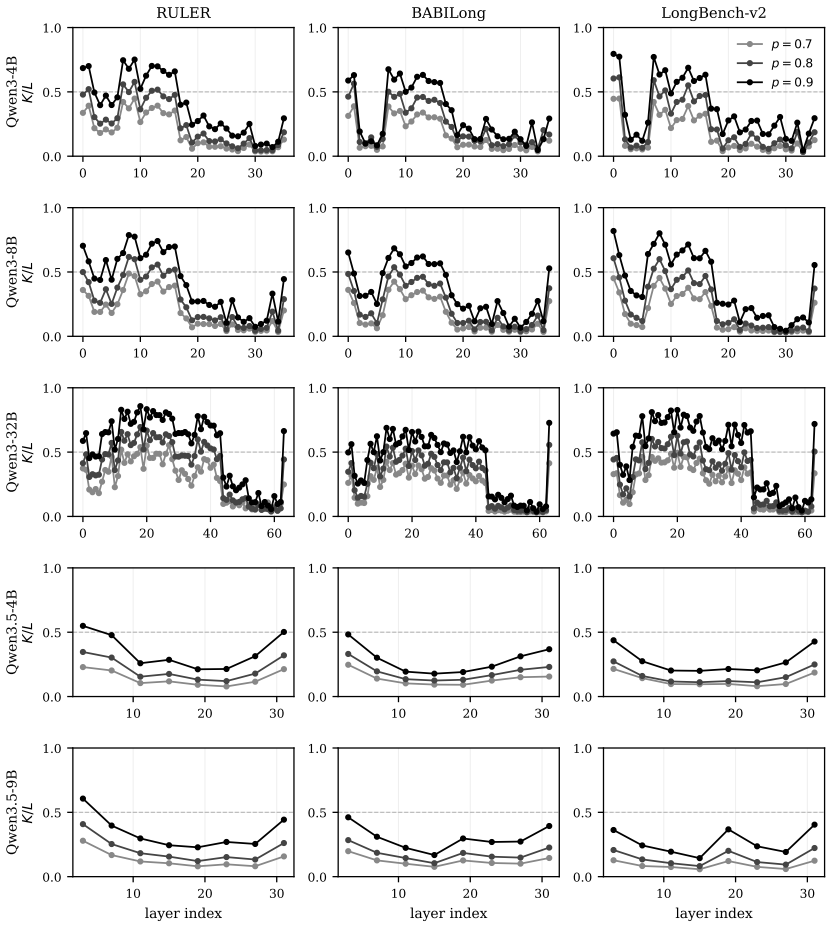
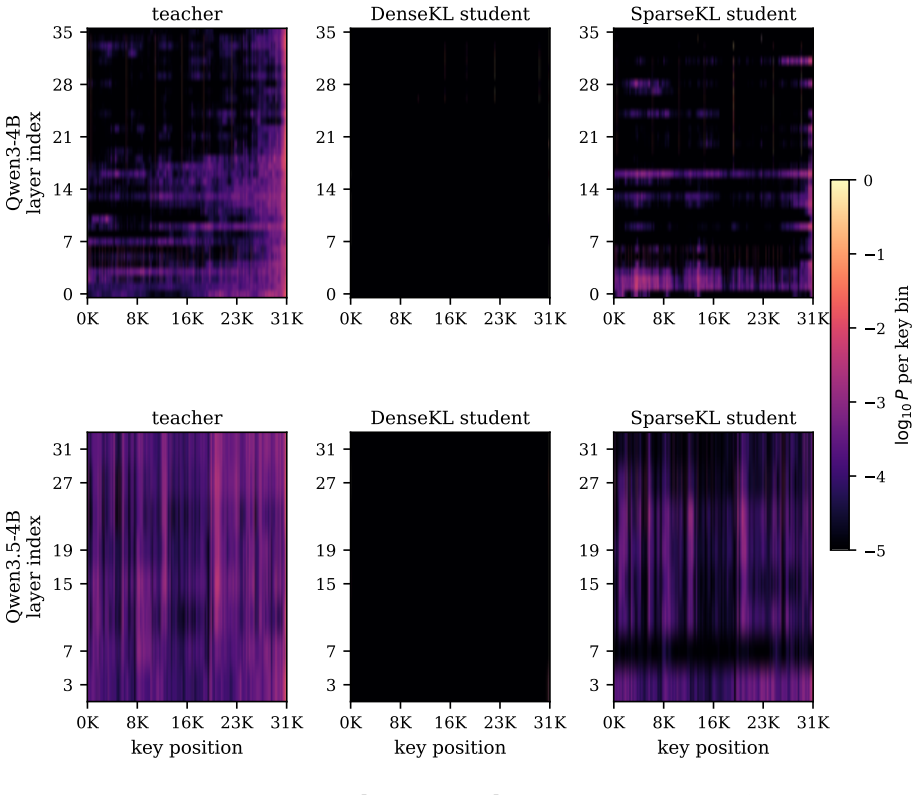
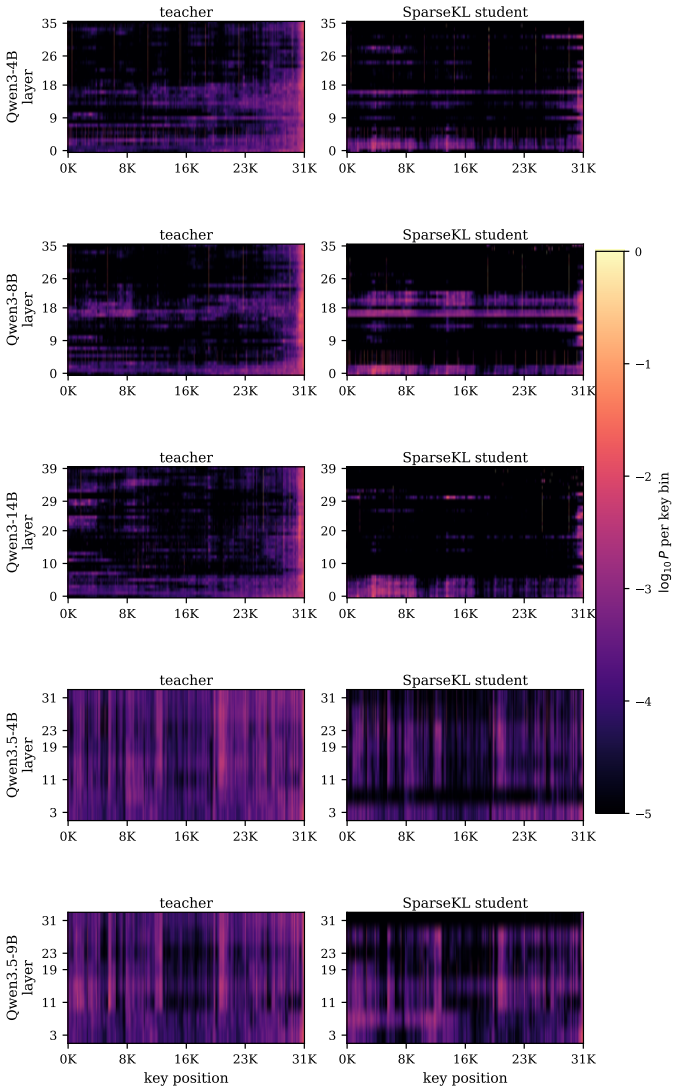
SpotAttention is a lightweight selector that attaches to any frozen pretrained transformer and is trained by KL distillation to reproduce the model's attention distribution; once trained, it selects the top-K keys for each query and uses a dual top-p rule to set the per-query budget directly from its own output distribution, enabling block-sparse attention that matches dense accuracy up to 128K tokens on both dense and hybrid Qwen models.
What carries the argument
The KL-distilled lightweight selector that estimates per-query attention distributions to choose top-K keys and set budgets via a dual top-p rule.
If this is right
- The same selector works across dense 4B-32B Qwen3 models and hybrid 4B-9B Qwen3.5 models without retraining the base model.
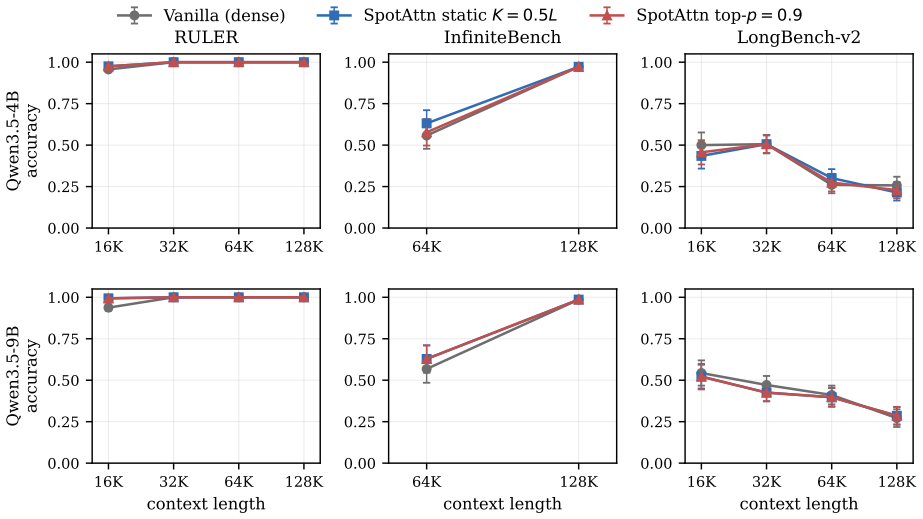
- Decode throughput at 128K context improves 3.9 times over FlashAttention and 1.8 times over the strongest training-free sparse baseline.
- Quantizing the selector's key cache to INT4 or FP4 reduces its memory footprint 3.5 times with no accuracy penalty.
- The approach extends the usable context length to at least eight times the length seen during the base model's original training.
Where Pith is reading between the lines
- The distillation method could be applied to other attention mechanisms, such as those in vision transformers, without changing the base model.
- If the selector generalizes across model families, it might allow mixing of different pretrained checkpoints at inference time by sharing one selector.
- The per-query budget reading might reduce the need for manual sparse-attention hyperparameter search on new tasks.
Load-bearing premise
The selector's distilled estimate of attention is accurate enough that routing each query to only its top keys leaves downstream task performance unchanged.
What would settle it
Running the same long-context benchmark suite on a Qwen model with and without the selector and finding that accuracy drops on any task when the selector is used.
Figures

read the original abstract
Long contexts have become standard in pretrained LLMs, yet they remain expensive to run: prefill compute grows quadratically with sequence length, and every decode step re-reads a key-value cache that grows linearly with it. Sparse attention cuts these costs by attending only to a relevant subset of past tokens, but selecting that subset is itself expensive. We present SpotAttention, a lightweight selector that attaches to a frozen pretrained transformer and learns by KL distillation to estimate its attention distribution. The selector picks the top-K keys each query attends to, and because its estimate is a calibrated distribution, a dual top-p rule reads the per-query, per-layer budget directly from it. Across Qwen3 (dense, 4B-32B) and Qwen3.5 (hybrid linear/full attention, 4B-9B), SpotAttention matches dense accuracy at contexts up to 128K tokens, eight times the training length. Decode at L=128K runs 3.9x faster than FlashAttention and 1.8x faster than Twilight, the strongest training-free baseline. Quantizing the selector's K-cache to INT4 or FP4 microscale shrinks it 3.5x at no accuracy cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpotAttention, a lightweight plug-in selector for block-sparse attention in frozen pretrained transformers (Qwen3 dense and Qwen3.5 hybrid). The selector is trained via KL distillation to approximate the base model's per-layer attention distributions, then applies top-K selection with a dual top-p budget rule derived from the estimated distribution. It reports matching dense-model accuracy on long-context tasks at up to 128K tokens (8× training length) together with 3.9× decode speedup versus FlashAttention and 1.8× versus Twilight, plus INT4/FP4 quantization of the selector cache with no accuracy loss.
Significance. If the empirical claims hold, the work supplies a practical, training-free (for the base model) route to sparse long-context inference that preserves accuracy while delivering concrete speed and memory gains. The distillation-based selector avoids direct parameter fitting to the target task and the quantization result is a clear practical contribution.
major comments (3)
- [Experiments] Experiments section (and abstract): end-to-end accuracy parity at 128K is reported, yet no direct top-K recall, precision, or ranking-error metrics are provided for the selector versus the frozen teacher at lengths beyond the training context. Because KL divergence tolerates tail-ranking errors when mass is diffuse, this measurement is load-bearing for the claim that the selector recovers the same keys the dense attention would have used.
- [Methods] Methods / training details: the soundness assessment notes missing information on exact training procedure, baseline implementations, statistical variance across runs, and data-exclusion rules. These omissions make it impossible to assess whether the reported accuracy matching is robust or sensitive to implementation choices.
- [§3] §3 (selector architecture): the dual top-p rule is presented as reading the per-query budget directly from the calibrated distribution, but no ablation quantifies how often the rule selects a different effective K than a fixed top-K would, nor how this interacts with accuracy at 8× context extension.
minor comments (2)
- [Figures/Tables] Figure captions and tables should explicitly state the number of evaluation runs and whether error bars reflect standard deviation or standard error.
- [Abstract] The abstract states 'matches dense accuracy' without specifying the exact tasks or the tolerance used to declare a match; this should be clarified in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive assessment of the work's significance. We respond point-by-point to the major comments below, proposing revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): end-to-end accuracy parity at 128K is reported, yet no direct top-K recall, precision, or ranking-error metrics are provided for the selector versus the frozen teacher at lengths beyond the training context. Because KL divergence tolerates tail-ranking errors when mass is diffuse, this measurement is load-bearing for the claim that the selector recovers the same keys the dense attention would have used.
Authors: We agree that direct selector-quality metrics at extended contexts would provide stronger evidence. In the revised manuscript we will add top-K recall, precision, and ranking-error metrics computed against the teacher's attention at lengths up to 128K. While end-to-end task accuracy remains the primary claim, these metrics will directly address concerns about tail-ranking fidelity under KL training. revision: yes
-
Referee: [Methods] Methods / training details: the soundness assessment notes missing information on exact training procedure, baseline implementations, statistical variance across runs, and data-exclusion rules. These omissions make it impossible to assess whether the reported accuracy matching is robust or sensitive to implementation choices.
Authors: We will expand the Methods section to include the full training procedure (hyperparameters, optimizer settings, distillation dataset size and composition), baseline implementation details, statistical variance (means and standard deviations over three random seeds), and explicit data-exclusion rules confirming no overlap between distillation data and evaluation sets. revision: yes
-
Referee: [§3] §3 (selector architecture): the dual top-p rule is presented as reading the per-query budget directly from the calibrated distribution, but no ablation quantifies how often the rule selects a different effective K than a fixed top-K would, nor how this interacts with accuracy at 8× context extension.
Authors: We will add an ablation study (new subsection or appendix) that compares the dual top-p rule against fixed top-K selection. The ablation will report the distribution of per-query K values chosen by the adaptive rule and the resulting accuracy difference at 8× context extension, quantifying the benefit of reading the budget from the calibrated distribution. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via independent distillation.
full rationale
The central mechanism trains a selector by KL divergence to the frozen model's per-layer attention outputs, providing external supervision rather than defining the target by the method itself. Reported accuracy parity at 8× context and speedups are empirical claims, not reductions of predictions to fitted inputs or self-citation chains. No equations, uniqueness theorems, or ansatzes are shown to collapse by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Ermon, Stefano and Rudra, Atri and R
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[2]
Deja Vu: Contextual Sparsity for Efficient
Liu, Zichang and Wang, Jue and Dao, Tri and Zhou, Tianyi and Yuan, Binhang and Song, Zhao and Shrivastava, Anshumali and Zhang, Ce and Tian, Yuandong and R. Deja Vu: Contextual Sparsity for Efficient. Proceedings of the 40th International Conference on Machine Learning (ICML) , year =
-
[3]
International Conference on Learning Representations (ICLR) , year =
Efficient Streaming Language Models with Attention Sinks , author =. International Conference on Learning Representations (ICLR) , year =
-
[4]
Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context , author =. arXiv:2403.05530 , year =
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[6]
Quest: Query-Aware Sparsity for Efficient Long-Context
Tang, Jiaming and Zhao, Yilong and Zhu, Kan and Xiao, Guangxuan and Kasikci, Baris and Han, Song , booktitle =. Quest: Query-Aware Sparsity for Efficient Long-Context. 2024 , url =
2024
-
[7]
2024 , url =
Li, Yuhong and Huang, Yingbing and Yang, Bowen and Venkitesh, Bharat and Locatelli, Acyr and Ye, Hanchen and Cai, Tianle and Lewis, Patrick and Chen, Deming , booktitle =. 2024 , url =
2024
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Twilight: Adaptive Attention Sparsity with Hierarchical Top- p Pruning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[9]
Qwen3 Technical Report , author =. arXiv:2505.09388 , year =
-
[10]
International Conference on Learning Representations (ICLR) , year =
The Curious Case of Neural Text Degeneration , author =. International Conference on Learning Representations (ICLR) , year =
-
[11]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[12]
arXiv:2512.02556 , year =
-
[13]
International Conference on Learning Representations (ICLR) , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR) , year =
-
[14]
2024 , url =
Hsieh, Cheng-Ping and Sun, Simeng and Kriman, Samuel and Acharya, Shantanu and Rekesh, Dima and Jia, Fei and Zhang, Yang and Ginsburg, Boris , booktitle =. 2024 , url =
2024
-
[15]
2024 , url =
Kuratov, Yuri and Bulatov, Aydar and Anokhin, Petr and Rodkin, Ivan and Sorokin, Dmitry and Sorokin, Artyom and Burtsev, Mikhail , booktitle =. 2024 , url =
2024
-
[16]
2024 , pages =
Zhang, Xinrong and Chen, Yingfa and Hu, Shengding and Xu, Zihang and Chen, Junhao and Hao, Moo Khai and Han, Xu and Thai, Zhen Leng and Wang, Shuo and Liu, Zhiyuan and Sun, Maosong , booktitle =. 2024 , pages =
2024
-
[17]
2025 , pages =
Bai, Yushi and Tu, Shangqing and Zhang, Jiajie and Peng, Hao and Wang, Xiaozhi and Lv, Xin and Cao, Shulin and Xu, Jiazheng and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , booktitle =. 2025 , pages =
2025
-
[18]
, journal =
Nawrot, Piotr and Li, Robert and Huang, Renjie and Ruder, Sebastian and Marchisio, Kelly and Ponti, Edoardo M. , journal =. The Sparse Frontier: Sparse Attention Trade-offs in Transformer. 2025 , url =
2025
-
[19]
Penedo, Guilherme and Kydl. The. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =
-
[20]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[21]
2025 , url =
Lu, Enzhe and Jiang, Zhejun and Liu, Jingyuan and Du, Yulun and Jiang, Tao and Hong, Chao and Liu, Shaowei and He, Weiran and Yuan, Enming and Wang, Yuzhi and Huang, Zhiqi and Yuan, Huan and Xu, Suting and Xu, Xinran and Lai, Guokun and Chen, Yanru and Zheng, Huabin and Yan, Junjie and Su, Jianlin and Wu, Yuxin and Zhang, Yutao and Yang, Zhilin and Zhou, ...
2025
-
[22]
Longformer: The Long-Document Transformer , author =. arXiv:2004.05150 , year =
Pith/arXiv arXiv 2004
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Big Bird: Transformers for Longer Sequences , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[24]
2024 , url =
Xiao, Chaojun and Zhang, Pengle and Han, Xu and Xiao, Guangxuan and Lin, Yankai and Zhang, Zhengyan and Liu, Zhiyuan and Sun, Maosong , booktitle =. 2024 , url =
2024
-
[25]
Kevin , booktitle =
Feng, Yuan and Lv, Junlin and Cao, Yukun and Xie, Xike and Zhou, S. Kevin , booktitle =. 2025 , url =
2025
-
[26]
2025 , url =
Lai, Xunhao and Lu, Jianqiao and Luo, Yao and Ma, Yiyuan and Zhou, Xun , booktitle =. 2025 , url =
2025
-
[27]
and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , booktitle =
Jiang, Huiqiang and Li, Yucheng and Zhang, Chengruidong and Wu, Qianhui and Luo, Xufang and Ahn, Surin and Han, Zhenhua and Abdi, Amir H. and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , booktitle =. 2024 , url =
2024
-
[28]
Tactic: Adaptive Sparse Attention with Clustering and Distribution Fitting for Long-Context
Zhu, Kan and Tang, Tian and Xu, Qinyu and Gu, Yile and Zeng, Zhichen and Kadekodi, Rohan and Zhao, Liangyu and Li, Ang and Krishnamurthy, Arvind and Kasikci, Baris , booktitle =. Tactic: Adaptive Sparse Attention with Clustering and Distribution Fitting for Long-Context. 2026 , url =
2026
-
[29]
2025 , url =
Zhang, Jintao and Xiang, Chendong and Huang, Haofeng and Wei, Jia and Xi, Haocheng and Zhu, Jun and Chen, Jianfei , booktitle =. 2025 , url =
2025
-
[30]
Less Is More: Fast and Accurate Reasoning with Cross-Head Unified Sparse Attention , author =. arXiv:2508.07101 , year =
-
[31]
2025 , url =
Xiao, Guangxuan and Tang, Jiaming and Zuo, Jingwei and Guo, Junxian and Yang, Shang and Tang, Haotian and Fu, Yao and Han, Song , booktitle =. 2025 , url =
2025
-
[32]
2025 , url =
Chen, Zhuoming and Sadhukhan, Ranajoy and Ye, Zihao and Zhou, Yang and Zhang, Jianyu and Nolte, Niklas and Tian, Yuandong and Douze, Matthijs and Bottou, Leon and Jia, Zhihao and Chen, Beidi , booktitle =. 2025 , url =
2025
-
[33]
Liu, Minghui and Rabbani, Tahseen and O'Halloran, Tony and Sankaralingam, Ananth and Hartley, Mary-Anne and Huang, Furong and Ferm. arXiv:2412.16187 , year =
-
[34]
2026 , url =
Zhou, Ruijie and Meng, Fanxu and Xu, Yufei and Liu, Tongxuan and Lu, Guangming and Zhang, Muhan and Pei, Wenjie , journal =. 2026 , url =
2026
-
[35]
2024 , url =
Gao, Yizhao and Zeng, Zhichen and Du, Dayou and Cao, Shijie and Zhou, Peiyuan and Qi, Jiaxing and Lai, Junjie and So, Hayden Kwok-Hay and Cao, Ting and Yang, Fan and Yang, Mao , journal =. 2024 , url =
2024
-
[36]
2024 , pages =
Ribar, Luka and Chelombiev, Ivan and Hudlass-Galley, Luke and Blake, Charlie and Luschi, Carlo and Orr, Douglas , booktitle =. 2024 , pages =
2024
-
[37]
2025 , url =
Cai, Zefan and Zhang, Yichi and Gao, Bofei and Liu, Yuliang and Li, Yucheng and Liu, Tianyu and Lu, Keming and Xiong, Wayne and Dong, Yue and Hu, Junjie and Xiao, Wen , booktitle =. 2025 , url =
2025
-
[38]
International Conference on Learning Representations (ICLR) , year =
Long-Context Generalization with Sparse Attention , author =. International Conference on Learning Representations (ICLR) , year =
-
[39]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year =
Adaptive Attention Span in Transformers , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year =
-
[40]
Proceedings of the 33rd International Conference on Machine Learning (ICML) , year =
From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification , author =. Proceedings of the 33rd International Conference on Machine Learning (ICML) , year =
-
[41]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , url =
2023
-
[42]
and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir , booktitle =
Hooper, Coleman and Kim, Sehoon and Mohammadzadeh, Hiva and Mahoney, Michael W. and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir , booktitle =. 2024 , url =
2024
-
[43]
2024 , url =
Liu, Zirui and Yuan, Jiayi and Jin, Hongye and Zhong, Shaochen and Xu, Zhaozhuo and Braverman, Vladimir and Chen, Beidi and Hu, Xia , booktitle =. 2024 , url =
2024
-
[44]
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models , author =. arXiv:2601.07372 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.