StatABench: Dataset and Framework for Evaluating Statistical Analysis Capabilities of LLMs
Pith reviewed 2026-06-26 08:23 UTC · model grok-4.3
The pith
Current LLMs reach at most 68.6 percent on a new benchmark for statistical analysis tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
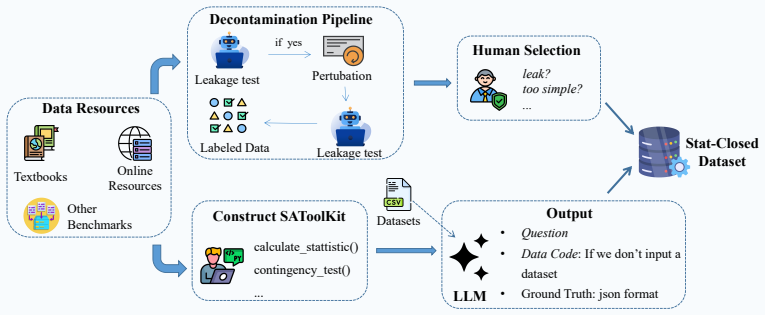
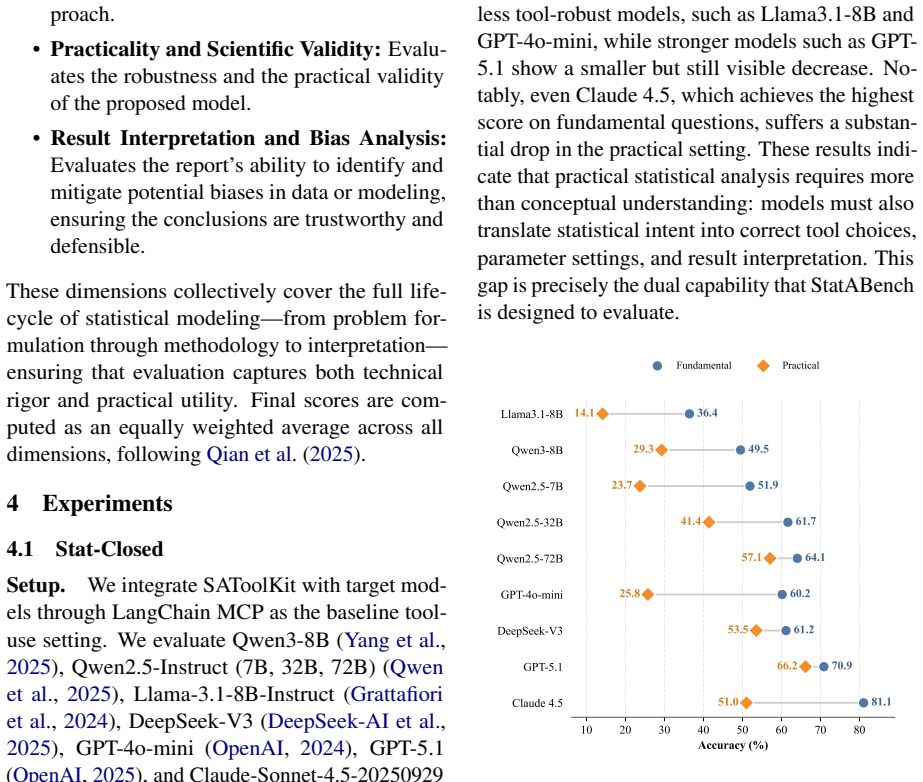
StatABench comprises Stat-Closed with 404 questions across 18 statistical topics and Stat-Open with 30 open-ended tasks. When LLMs and data-science agents are tested via LangChain MCP and a validated LLM-as-Judge protocol, the highest closed-set score is 68.6 percent and the highest open-set agent average is 61.86, establishing a measurable gap between existing models and reliable statistical analysis in tool-grounded reasoning, methodological choice, and end-to-end modeling.
What carries the argument
StatABench benchmark with its Stat-Closed and Stat-Open components, evaluated through the LangChain MCP framework and validated LLM-as-Judge protocol.
If this is right
- LLMs still lack reliable tool-grounded reasoning for statistical work.
- Methodological decision-making remains a clear weakness.
- End-to-end statistical modeling stays beyond current model reach.
- Open-source models trail closed models on these tasks.
- Agent frameworks provide partial gains but do not close the gap.
Where Pith is reading between the lines
- The benchmark could be used to steer training of specialized statistical modules inside LLMs.
- Comparable test suites might expose similar limits in other fields that mix domain rules with software tools.
- Higher scores on StatABench would support more automated data-analysis pipelines, though human review would likely stay necessary for critical applications.
- Repeated use of the same tasks could allow tracking of progress as new models appear.
Load-bearing premise
The 404 questions, 30 tasks, LangChain MCP setup, and LLM-as-Judge protocol together give an accurate, unbiased picture of statistical analysis ability.
What would settle it
A model or agent framework that scores above 90 percent on both Stat-Closed and Stat-Open while matching independent expert human judgments on the identical items.
Figures

















read the original abstract
Statistical analysis is a broad, complex field requiring both domain knowledge and tool proficiency. While prior work has evaluated large language models (LLMs) in this domain, existing benchmarks remain limited in scope and format. To bridge this gap, we introduce StatABench (Statistical AnalysisBenchmark), a benchmark designed to systematically assess LLMs' statistical analysis capabilities. StatABench comprises two complementary components: Stat-Closed, containing 404 questions across 18 statistical topics in multiple formats (multiple-choice, fill-in-the-blank, decision-making, and practical application), and Stat-Open, featuring 30 complex open-ended modeling tasks adapted from professional competitions. We evaluate diverse LLMs using the LangChain MCP framework and multiple data science agents, and assess Stat-Open solutions via a validated LLM-as-Judge protocol. Experiments show that even GPT-5.1 achieves only 68.6% on Stat-Closed, while the best open-source model reaches 60.6%. On Stat-Open, the top agent framework scores 61.86 on average. These results reveal the gap between current LLMs and reliable statistical analysis, highlighting persistent challenges in tool-grounded reasoning, methodological decision-making, and end-to-end statistical modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StatABench, a benchmark for LLMs' statistical analysis capabilities consisting of Stat-Closed (404 questions across 18 topics in multiple-choice, fill-in-the-blank, decision-making, and practical formats) and Stat-Open (30 open-ended modeling tasks adapted from professional competitions). It evaluates LLMs via the LangChain MCP framework and data science agents, using a validated LLM-as-Judge protocol for open tasks, and reports that GPT-5.1 reaches only 68.6% on Stat-Closed while the best open-source model reaches 60.6%, with the top agent framework scoring 61.86 on average on Stat-Open. These results are presented as evidence of gaps in tool-grounded reasoning, methodological decision-making, and end-to-end statistical modeling.
Significance. If the benchmark construction and judge protocol prove reliable, the work would offer a useful, multi-format evaluation resource that highlights concrete limitations in current LLMs for statistical tasks, potentially guiding improvements in agent frameworks and tool integration. The adaptation of tasks from professional competitions and the dual closed/open design are positive features that increase relevance to real statistical practice.
major comments (2)
- [Abstract] Abstract: The claim that the LLM-as-Judge protocol for Stat-Open is 'validated' is not accompanied by inter-rater agreement statistics, validation sample size, or disagreement analysis with human statisticians; without these, the reported 61.86 average score cannot be confidently interpreted as a reliable measure of modeling capability.
- [Abstract] Abstract (and implied dataset sections): No details are provided on question validation procedures, data exclusion rules, or checks for ambiguous wording and domain biases in the 404 closed questions and 30 open tasks; these omissions directly affect whether the performance gap (e.g., 68.6% for GPT-5.1) can be attributed to model limitations rather than benchmark artifacts.
Simulated Author's Rebuttal
Thank you for the constructive feedback and the recommendation for major revision. We appreciate the emphasis on ensuring the reliability of the LLM-as-Judge protocol and the transparency of benchmark construction. We agree that additional details are needed and will revise the manuscript to incorporate them. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the LLM-as-Judge protocol for Stat-Open is 'validated' is not accompanied by inter-rater agreement statistics, validation sample size, or disagreement analysis with human statisticians; without these, the reported 61.86 average score cannot be confidently interpreted as a reliable measure of modeling capability.
Authors: We agree that the absence of quantitative validation metrics weakens the interpretation of the Stat-Open results. While the manuscript describes the LLM-as-Judge protocol and states it was validated, we did not report inter-rater agreement statistics, sample sizes, or disagreement analysis. In the revised version, we will add a new subsection in the evaluation methodology detailing: the validation sample (e.g., 10 randomly selected tasks double-annotated by human statisticians), inter-rater agreement (Cohen's kappa between LLM judge and humans), and a summary of disagreement cases with resolution process. This will directly support the 'validated' claim and allow readers to assess the reliability of the 61.86 score. The abstract will be updated to reference the added validation details if space allows. revision: yes
-
Referee: [Abstract] Abstract (and implied dataset sections): No details are provided on question validation procedures, data exclusion rules, or checks for ambiguous wording and domain biases in the 404 closed questions and 30 open tasks; these omissions directly affect whether the performance gap (e.g., 68.6% for GPT-5.1) can be attributed to model limitations rather than benchmark artifacts.
Authors: We acknowledge that the current manuscript lacks explicit documentation of validation procedures for the questions and tasks, which is a valid concern for attributing performance gaps. The dataset sections describe the topics, formats, and sources (including adaptation from professional competitions) but omit the validation steps. In the revision, we will expand the 'Dataset Construction' section to include: (1) validation procedures (expert review for factual accuracy and clarity), (2) data exclusion rules (e.g., removal of questions with ambiguous interpretations or multiple correct answers), and (3) checks for ambiguous wording and domain biases (e.g., topic balance verification and bias audits across statistical subfields). These additions will strengthen the claim that observed gaps reflect model limitations. Details will appear in the main text or as supplementary material. revision: yes
Circularity Check
Empirical benchmark creation with direct evaluations; no derivation chain present
full rationale
The paper constructs StatABench (404 closed questions + 30 open tasks) and reports model accuracies via LangChain and LLM-as-Judge. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the abstract or described structure. All reported numbers are direct empirical measurements on the newly introduced items; the central claims do not reduce to any self-referential step. This is a standard self-contained benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The LLM-as-Judge protocol is validated and reliable for scoring open-ended statistical modeling solutions
Reference graph
Works this paper leans on
-
[1]
Chen, X., Li, Y., & Wang, Z. (2018). Thermal effects on lithium-ion battery degradation and capacity fade. Journal of Power Sources, 392, 228-237. ↩
2018
-
[2]
Smith, J., Johnson, M., & Brown, K. (2020). Correlation analysis of factors affecting lithium-ion battery lifespan. Energy Storage Materials, 28, 102-115. ↩
2020
-
[3]
Zhang, L., Wang, H., & Liu, R. (2019). Comparative study of cathode materials for enhanced cycle life in lithium-ion batteries. Electrochimica Acta, 318, 1-12. ↩
2019
-
[4]
B., & Bazant, M
Pinson, M. B., & Bazant, M. Z. (2012). Theory of SEI formation in rechargeable batteries: Capacity fade, accelerated aging and lifetime prediction. ↩
2012
-
[5]
Calvin, K., et al. (2023). IPCC, 2023: Climate Change 2023: Synthesis Report. Contribution of Working Groups I, II and III to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change [Core Writing Team, H. Lee & J. Romero (Eds.)]. IPCC, Geneva, Switzerland. ↩
2023
-
[6]
A., et al
Sanguesa, J. A., et al. (2021). A review on electric vehicles: Technologies and challenges. ↩
2021
-
[7]
Hu, X., et al. (2019). Battery warm-up methodologies at subzero temperatures for automotive applications: Recent advances and perspectives. ↩
2019
-
[8]
Tomaszewska, A., et al. (2019). Lithium-ion battery fast charging: A review. ↩
2019
-
[9]
Liu, W., et al. (2015). Nickel-rich layered lithium transition-metal oxide for high-energy lithium-ion batteries. ↩
2015
-
[10]
[Note: Reference number 10 was missing in the original text; supplementary citation recommended: Peukert, W. (1897). Über die Abhängigkeit der Kapazität galvanischer Elemente von der Entladestromstärke. Electrotechnische Zeitschrift, 18(5), 148-153.] ↩
-
[11]
K., et al
Mehmood, K. K., et al. (2017). Optimal sizing and allocation of battery energy storage systems with wind and solar power DGs in a distribution network for voltage regulation considering the lifespan of batteries. ↩
2017
-
[12]
Xia, Q., et al. (2019). A modified reliability model for lithium-ion battery packs based on the stochastic capacity degradation and dynamic response impedance. ↩
2019
-
[13]
Zhao, J., et al. (2023). Review of state estimation and remaining useful life prediction methods for lithium–ion batteries. ↩
2023
-
[14]
[Note: Reference number 14 was missing in the original text; supplementary citation recommended: Rand, D. A. J., & Dell, R. M. (2004). Battery life cycle assessment in perspective. Journal of Power Sources, 131(1-2), 230-239.] ↩
2004
-
[15]
[Note: Reference number 15 was missing in the original text; supplementary citation recommended: Dubarry, M., & Tarascon, J. M. (2012). Understanding the degradation mechanisms of Li-ion batteries. AccChemRes, 45(11), 1125-1134.] ↩
2012
-
[16]
W., & Aurbach, D
[Note: Reference number 16 was missing in the original text; supplementary citation recommended: Choi, J. W., & Aurbach, D. (2016). Promise and reality of post-lithium-ion batteries with high energy densities. Nature Reviews Materials, 1(11), 1-17.] ↩
2016
-
[17]
[Note: Reference number 17 was missing in the original text; supplementary citation recommended: Liu, X., et al. (2020). A review of lithium-ion battery state of health estimation and prediction. Renewable and Sustainable Energy Reviews, 131, 110015.] ↩
2020
-
[18]
[Note: Reference number 18 was missing in the original text; supplementary citation recommended: Arrhenius, S. A. (1889). Über die Reaktionsgeschwindigkeit bei der Inversion von Rohrzucker durch Säuren. Zeitschrift für Physikalische Chemie, 4(2), 226-248.] ↩
-
[19]
Rohr, S., et al. (2017). Quantifying uncertainties in reusing lithium-ion batteries from electric vehicles. ↩
2017
-
[20]
[Note: Reference number 20 was missing in the original text; supplementary citation recommended: Weibull, W. (1951). A statistical distribution function of wide applicability. Journal of Applied Mechanics, 18(3), 293-297.] ↩
1951
-
[21]
[Note: Reference number 21 was missing in the original text; supplementary citation recommended: Efron, B. (1979). Bootstrap methods: Another look at the jackknife. The Annals of Statistics, 7(1), 1-26.] ↩
1979
-
[22]
F., et al
Schuster, S. F., et al. (2015). Lithium-ion cell-to-cell variation during battery electric vehicle operation. ↩
2015
-
[23]
Electrochemical shock
Woodford, W. H., Chiang, Y.-M., & Carter, W. C. (2010). "Electrochemical shock" of intercalation electrodes: A fracture mechanics analysis. ↩
2010
-
[24]
Kalnaus, S., Rhodes, K., & Daniel, C. (2011). A study of lithium ion intercalation induced fracture of silicon particles used as anode material in Li-ion battery. ↩
2011
-
[25]
Yang, Z., et al. (2021). High-performance lead-free bulk ceramics for electrical energy storage applications: Design strategies and challenges. ↩
2021
-
[26]
Khan, F., Pal, N., & Saeed, S. H. (2018). Review of solar photovoltaic and wind hybrid energy systems for sizing strategies optimization techniques and cost analysis methodologies. ↩
2018
-
[27]
Jiang, J., et al. (2018). Ultrahigh discharge efficiency in multilayered polymer nanocomposites of high energy density. ↩
2018
-
[28]
Chang, Y., & Fang, H. (2019). A hybrid prognostic method for system degradation based on particle filter and relevance vector machine. ↩
2019
-
[29]
Zhao, W., et al. (2023). Broad-high operating temperature range and enhanced energy storage performances in lead-free ferroelectrics. ↩
2023
-
[30]
Krishnaswamy Sethurajan, A., et al. (2015). Accurate characterization of ion transport properties in binary symmetric electrolytes using in situ NMR imaging and inverse modeling. ↩
2015
-
[31]
Alipour, M., et al. (2023). A surrogate-assisted uncertainty quantification and sensitivity analysis on a coupled electrochemical–thermal battery aging model. ↩
2023
-
[32]
Lee, J., et al. (2013). Prognostics and health management design for rotary machinery systems— Reviews, methodology and applications. ↩
2013
-
[33]
R., Field, L
Long, E. R., Field, L. J., & MacDonald, D. D. (1998). Predicting toxicity in marine sediments with numerical sediment quality guidelines. ↩
1998
-
[34]
R., et al
Palattella, M. R., et al. (2016). Internet of Things in the 5G era: Enablers, architecture, and business models. ↩ Figure 8: The report generated by MathModelAgent for Problem a of the 2022 MAS Prompt for All questions [SYSTEM] You are a professional statistics analyst, and could answer user’s questions with or without using tools. [USER] Your task is to ...
2016
-
[35]
Analyze the question and determine whether you can answer
-
[36]
If the question is choice or judgment, satisfy the required answer format and do not provide explanations
-
[37]
For other questions, provide a concise and complete answer
-
[38]
if significant, then
Finally, the outputmust alwaysfollow this format (do not omit angle brackets): The answer is <your answer>. Figure 9: The prompt used in the LangChain MCP Frame 19 Prompt for Comparing Answers For the following question: {question} There are two answers: <ground truth> {ground} </ground truth> <response> {response} </response> Please determine whether the...
-
[39]
The function call string {user_code}
-
[40]
Requirements: • The answer should be fluent, concise, and rigorous, and should correctly answer the question
The execution result after calling the function {code_result} Based on this information, generate a standardized answer that directly addresses the question. Requirements: • The answer should be fluent, concise, and rigorous, and should correctly answer the question. • The output must be in English. • The answer should be brief and focus on the final resu...
-
[41]
Create several meaningful problems that can be solved directly using this function, based on the dataset
-
[42]
Each problem must be solvable by calling this function exactly once, without using any additional helper functions
-
[43]
• The exact function call (showing how to use the function to solve the problem)
For each problem, provide: • A clear problem description (what needs to be solved). • The exact function call (showing how to use the function to solve the problem). • A short analysis explaining why this function can solve the problem and how it works in this context. The goal is to generate diverse, realistic questions that demonstrate how this function...
-
[44]
Each problem should be solvable by a single call to the given function
-
[45]
For each problem, clearly show how to call this function to obtain the correct result
-
[46]
Provide Python code to generate the dataset used in the problem, ensuring that the dataset matches the problem description
-
[47]
Different problems may share the same dataset
-
[48]
Include an analytical explanation of why this function can be used to solve the given problem. Figure 13: The prompt for generating practical application questions (Path II) 21 Evaluate Structural Coherency Prompt [SYSTEM] You are an expert judge evaluating statistical modeling papers. Your task is to assess the structural coherency of the paper by checki...
-
[49]
Problem Restatement (0-1): 0.00: Missing or completely misunderstood
-
[50]
Assumptions and Justification (0-1): 0.00: Missing or unjustified Example: No assumptions listed or completely unreasonable ones
-
[51]
Modeling Implementation (0-1): 0.00: Missing or fundamentally flawed Example: No clear mathematical formulation
-
[52]
Solution Process (0-1): 0.00: Missing or invalid Example: No solution method or completely incorrect approach
-
[53]
scores": {
Analysis (0-1): 0.00: Missing or invalid Example: No analysis or completely wrong interpretations ... Your response must follow this exact format: Your Response: ```json { "scores": { "problem_restatement": 0.0, "assumptions": 0.0, "modeling_implementation": 0.0, "solution_process": 0.0, "analysis": 0.0 }, "explanation": { "problem_restatement": "why this...
-
[54]
Statistical Theory and Model Specification (0–1): 0.00: Fundamentally flawed or missing Example: No clear probabilistic model, used incorrect statistical concepts for the data type
-
[55]
Data Quality and Feature Engineering (0–1): 0.00: No connection to data reality Example: Model is presented without any description of the data source, its collection process, or its characteristics
-
[56]
Methodology and Estimation (0–1): 0.00: Elementary/inappropriate Example: Using methods for independent data on time-series data; using linear models for clearly non-linear, non- transformable relationships
-
[57]
Model Validation and Diagnostics (0–1): 0.00: No validation Example: Model results are presented without any form of verification or performance metric
-
[58]
statistical_theory_and_model_specification
Implementation Quality and Reproducibility (0–1): 0.00: Poor/incorrect Example: Code contains clear errors in statistical formulas or misuse of libraries. ... Your response must follow this exact format: Your Response: { "statistical_theory_and_model_specification": { "score": 0.0, "explanation": "Detailed justification for score" }, "data_quality_and_fea...
-
[59]
Data Quality (0-1): 0.00: No data or invalid data Example: Made-up numbers without sources
-
[60]
Data Processing (0-1): 0.00: No processing/invalid Example: Raw data used without cleaning
-
[61]
Statistical Analysis (0-1): 0.00: No analysis/incorrect Example: No statistical methods used
-
[62]
Data Integration (0-1): 0.00: No integration Example: Data disconnected from model
-
[63]
data_quality
Validation & Testing (0-1): 0.00: No validation Example: Results accepted without testing ... Your response must follow this exact format: Your Response: ```json { "data_quality": { "score": 0.0, "explanation": "Detailed justification for score" }, "data_processing": { "score": 0.0, "explanation": "Detailed justification for score" }, ..., "validation": {...
-
[64]
Depth of Statistical Analysis (0-1): 0.00: No meaningful analysis
-
[65]
Statistical Rigor and Justification (0-1): 0.00: No statistical support Example: Makes claims about trends or differences without any statistical tests or evidence
-
[66]
Interpretation of Results and Context (0-1): 0.00: No interpretation Example: Presents a table of results or a plot with no explanation
-
[67]
Critical Evaluation of Findings (0-1): 0.00: No critical thinking Example: Accepts all model outputs as absolute truth without question
-
[68]
depth_of_statistical_analysis
Implications and Future Directions (0-1): 0.00: No discussion Example: The paper ends abruptly after presenting the results. ... Your response must follow this exact format: Your Response: ```json { "depth_of_statistical_analysis": { "score": 0.0, "explanation": "Detailed justification for score" }, "statistical_rigor_and_justification": { "score": 0.0, "...
-
[69]
Methodological Innovation (0–1): 0.00: Standard/textbook approach Example: Using basic linear regression without modification
-
[70]
Problem Framing (0–1): 0.00: Conventional perspective Example: Following typical problem formulation
-
[71]
Solution Creativity (0–1): 0.00: Standard solution Example: Direct application of known methods
-
[72]
Technical Advancement (0–1): 0.00: No advancement Example: Uses only existing techniques
-
[73]
methodological_innovation
Impact Potential (0–1): 0.00: Minimal impact Example: No new insights or applications ... Your response must follow this exact format: Your Response: ```json { "methodological_innovation": { "score": 0.0, "explanation": "Detailed justification for score" }, "problem_framing": { "score": 0.0, "explanation": "Detailed justification for score" }, ..., "impac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.