Distilling Collaborative Dynamics into Latent Space for Implicit Coordination in Decentralized Multi-Agent Manipulation
Pith reviewed 2026-07-03 23:15 UTC · model grok-4.3
The pith
CLS-DP distills multi-agent dynamics into a latent space so each robot can coordinate implicitly from its local camera view and task instruction alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
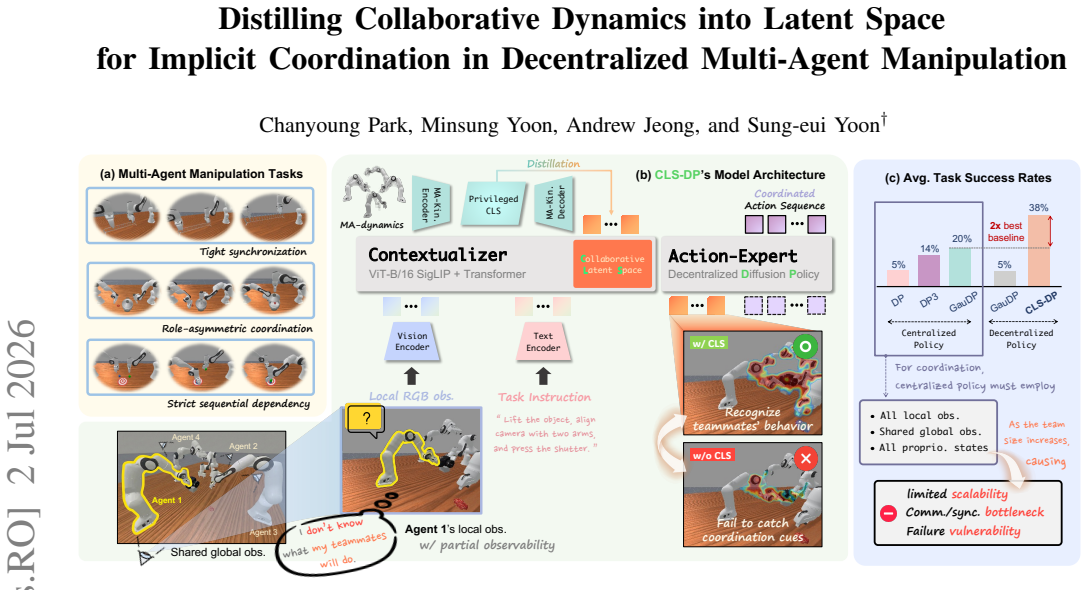
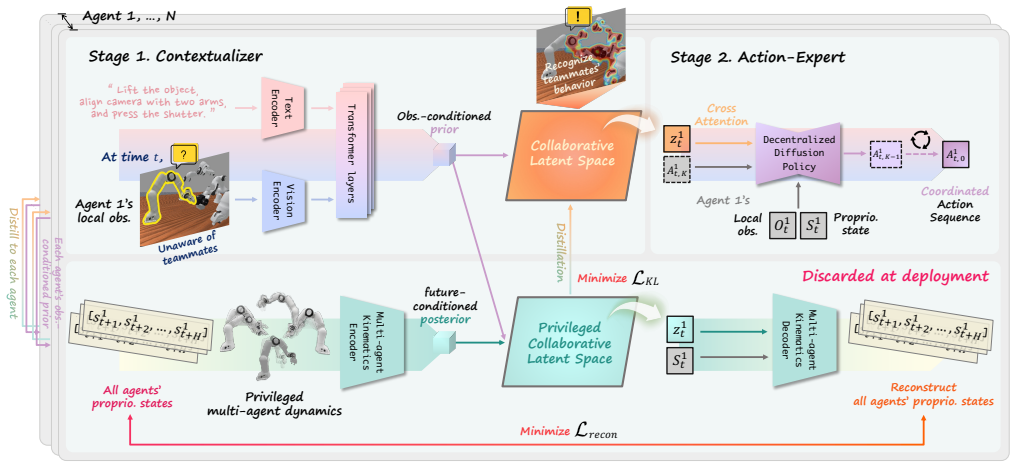
CLS-DP distills privileged multi-agent dynamics into a latent space. At deployment each agent infers a collaborative latent from its local RGB observation and shared task instruction, then conditions the diffusion denoising process on this latent. This produces implicit coordination whose per-agent cost stays independent of team size and yields 38 percent mean success across six RoboFactory tasks, outperforming the best centralized baseline at 20 percent and a decentralized ablation without the latent at 9 percent.
What carries the argument
Collaborative latent inferred by each agent from local RGB observation and task instruction to condition the diffusion policy.
If this is right
- Success rate on multi-agent manipulation tasks rises to 38 percent mean while remaining independent of team size.
- Each agent's computation and memory cost stays constant even as the number of robots increases from two to four.
- Coordination occurs using only local RGB images and a shared task instruction, with no inter-agent messages required.
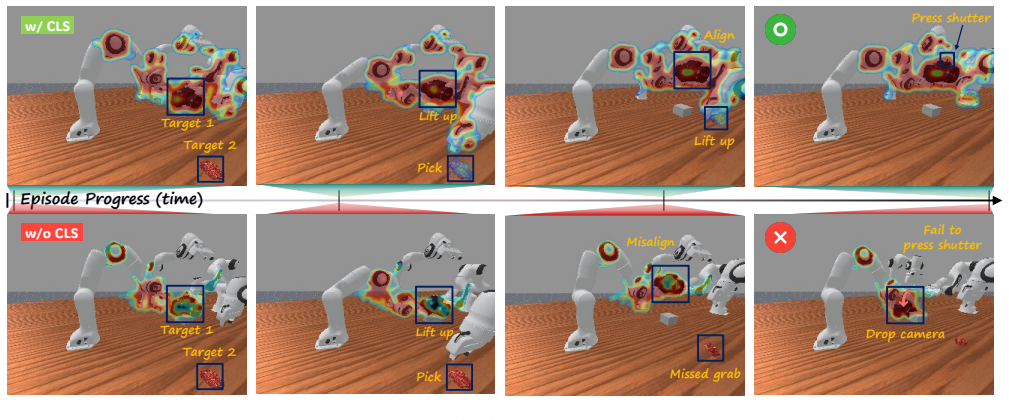
- Attribution maps show the latent encodes joint and gripper information for both the agent itself and its teammates.
Where Pith is reading between the lines
- The same latent-distillation pattern could be tested in other partially observable multi-agent domains such as navigation or object transport.
- Because cost does not grow with team size, the approach may remain practical for teams larger than four agents.
- If the inferred latent reliably captures intended actions, it could reduce reliance on explicit synchronization in other robotic coordination settings.
Load-bearing premise
The latent inferred from one agent's local RGB view and task instruction contains enough information about teammates' states and intended actions to support reliable coordination.
What would settle it
A controlled run in which the collaborative latent is withheld or local observations are masked, causing success to fall to the 9 percent level of the no-latent ablation.
Figures

read the original abstract
Multi-arm manipulation demands precise spatiotemporal coordination, yet many centralized approaches scale poorly as team size increases. To address this, we propose CLS-DP, a decentralized multi-agent framework that enables implicit coordination under partial observability without shared global views, explicit state information, or inter-agent communication. Under the centralized training and decentralized execution (CTDE) paradigm, CLS-DP distills privileged multi-agent dynamics into a latent space. At deployment, each agent infers a collaborative latent from its local RGB observation and a shared task instruction; it then conditions the diffusion denoising process on this latent. This design enables implicit coordination with a per-agent cost independent of team size. Across six RoboFactory benchmark tasks spanning two to four agents, CLS-DP achieves a 38% mean success rate, outperforming the best centralized baseline (20%) and a decentralized ablation without the collaborative latent (9%). It also maintains superior parameter efficiency across all agent configurations. Attribution maps show that an agent conditioned on the collaborative latent places high attribution on the joints and grippers of both itself and its teammates throughout execution. This suggests that the learned latent efficiently encodes collaborative dynamics from local observation, which facilitates implicit coordination in realistic settings characterized by partial observability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CLS-DP, a CTDE decentralized framework for multi-agent manipulation that distills privileged collaborative dynamics into a latent space. At execution, each agent infers a collaborative latent solely from its local RGB observation and shared task instruction, then conditions a diffusion policy's denoising process on this latent to achieve implicit coordination without explicit communication or global state. On six RoboFactory tasks with 2–4 agents, CLS-DP reports a 38% mean success rate, outperforming the best centralized baseline (20%) and a no-latent decentralized ablation (9%), while maintaining parameter efficiency independent of team size; attribution maps are cited as evidence that the latent encodes teammate joints and grippers.
Significance. If the central mechanism is validated, the approach would offer a scalable path for decentralized multi-agent robotics under partial observability, with per-agent compute independent of team size and no inter-agent messaging. The architectural choice of distilling dynamics into a latent that conditions diffusion policies is a concrete contribution that could be adopted in other CTDE settings.
major comments (2)
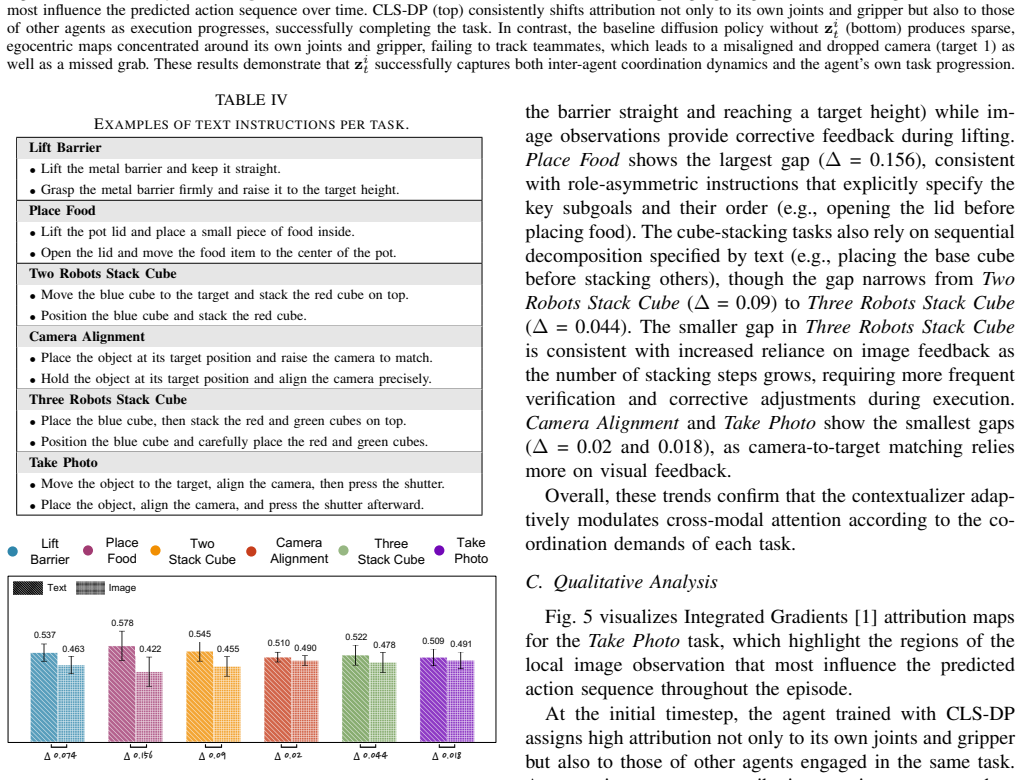
- [Abstract] Abstract and Results: the 29-point success-rate gap versus the no-latent ablation and the attribution maps are presented as support that the inferred collaborative latent contains sufficient information about teammates' states and intended actions. Neither directly quantifies information content (e.g., mutual information between latent and teammate joint positions/actions, or predictive accuracy of teammate actions conditioned on the latent alone); the ablation controls only for module presence, and attribution is post-hoc, so the performance gain could arise from capacity or training effects rather than implicit coordination.
- [Abstract] Abstract: comparative success rates (38%, 20%, 9%) are reported without any description of experimental protocol, number of trials, statistical tests, error bars, random seeds, or how the centralized and ablation baselines were implemented and trained, preventing verification that the numbers support the claim of reliable implicit coordination.
minor comments (1)
- [Abstract] Abstract: the claim of 'superior parameter efficiency across all agent configurations' is stated without the specific metric (parameters, FLOPs, or inference time) or the table/figure that reports the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on evidence for the collaborative latent and experimental transparency. We address each major comment below with proposed revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and Results: the 29-point success-rate gap versus the no-latent ablation and the attribution maps are presented as support that the inferred collaborative latent contains sufficient information about teammates' states and intended actions. Neither directly quantifies information content (e.g., mutual information between latent and teammate joint positions/actions, or predictive accuracy of teammate actions conditioned on the latent alone); the ablation controls only for module presence, and attribution is post-hoc, so the performance gain could arise from capacity or training effects rather than implicit coordination.
Authors: We agree that the performance gap and post-hoc attribution maps provide indirect rather than direct evidence of information content in the latent. The ablation isolates the module's contribution but does not fully exclude capacity or training confounds. We will add new quantitative evaluations in the revised manuscript, including the accuracy of predicting teammate joint positions and actions from the latent alone (and mutual information estimates where feasible), to directly support the claim of implicit coordination. revision: yes
-
Referee: [Abstract] Abstract: comparative success rates (38%, 20%, 9%) are reported without any description of experimental protocol, number of trials, statistical tests, error bars, random seeds, or how the centralized and ablation baselines were implemented and trained, preventing verification that the numbers support the claim of reliable implicit coordination.
Authors: The abstract's length constraints limit full protocol details, but we acknowledge this reduces verifiability. Section 4 and the appendix already contain the evaluation protocol (100 trials per task, 5 random seeds, error bars, statistical tests, and baseline implementations), yet we will revise the main results section to prominently summarize these elements and add a brief reference sentence to the abstract directing readers to the experimental setup. revision: yes
Circularity Check
No circularity: architectural proposal with external empirical validation
full rationale
The paper introduces CLS-DP as a new CTDE framework that distills dynamics into a latent space for decentralized execution. The central claims rest on empirical success rates (38% mean) versus baselines and an ablation (9%), plus attribution maps, none of which are defined in terms of the method itself. No equations, self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The derivation chain is the architectural choice plus training procedure, which remains independent of the reported outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Axiomatic attribution for deep net- works
Mukund Sundararajan et al., “Axiomatic attribution for deep net- works”, inICML. 2017, pp. 3319–3328, PMLR
2017
-
[2]
Christopher M ¨uller,World Robotics 2025: Industrial Robots, VDMA Services GmbH, 2025
2025
-
[3]
AutoMate: Specialist and generalist assembly policies over diverse geometries
Bingjie Tang et al., “AutoMate: Specialist and generalist assembly policies over diverse geometries”, inRSS, 2024, vol. 20
2024
-
[4]
Surgical robot transformer (SRT): Imitation learning for surgical tasks
J. W. Kim et al., “Surgical robot transformer (SRT): Imitation learning for surgical tasks”, inCoRL. 2024, pp. 130–144, PMLR
2024
-
[5]
RoboCasa: Large-scale simulation of household tasks for generalist robots
Soroush Nasiriany et al., “RoboCasa: Large-scale simulation of household tasks for generalist robots”, inRSS, 2024, vol. 20
2024
-
[6]
Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots
Cheng Chi et al., “Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots”, inRSS, 2024, vol. 20
2024
-
[7]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi et al., “Diffusion policy: Visuomotor policy learning via action diffusion”, inRSS, 2023, vol. 19
2023
-
[8]
Generative modeling by estimating gradients of the data distribution
Yang Song et al., “Generative modeling by estimating gradients of the data distribution”, inNeurIPS, 2019, pp. 11895–11907
2019
-
[9]
Diffusion policies as an expressive policy class for offline reinforcement learning
Zhendong Wang et al., “Diffusion policies as an expressive policy class for offline reinforcement learning”, inICLR, 2023
2023
-
[10]
RoboFactory: Exploring embodied agent collabo- ration with compositional constraints
Yiran Qin et al., “RoboFactory: Exploring embodied agent collabo- ration with compositional constraints”, inICCV. 2025, pp. 10075– 10085, IEEE
2025
-
[11]
Imitating task and motion planning with visuomotor transformers
Murtaza Dalal et al., “Imitating task and motion planning with visuomotor transformers”, inCoRL. 2023, pp. 2565–2593, PMLR
2023
-
[12]
Offline imitation learning through graph search and retrieval
Zhao-Heng Yin et al., “Offline imitation learning through graph search and retrieval”, inRSS, 2024, vol. 20
2024
-
[13]
Contrastive imitation learning for language-guided multi-task robotic manipulation
Teli Ma et al., “Contrastive imitation learning for language-guided multi-task robotic manipulation”, inCoRL. 2024, pp. 4651–4669, PMLR
2024
-
[14]
Is behavior cloning all you need? understanding horizon in imitation learning
Dylan J. Foster et al., “Is behavior cloning all you need? understanding horizon in imitation learning”, inNeurIPS, 2024, pp. 120602–120666
2024
-
[15]
Implicit behavioral cloning
Pete Florence et al., “Implicit behavioral cloning”, inCoRL. 2021, pp. 158–168, PMLR
2021
-
[16]
Improved contrastive divergence training of energy- based models
Yilun Du et al., “Improved contrastive divergence training of energy- based models”, inICML. 2021, pp. 2837–2848, PMLR
2021
-
[17]
Conditional energy-based models for implicit policies: The gap between theory and practice
Duy-Nguyen Ta et al., “Conditional energy-based models for implicit policies: The gap between theory and practice”, inIMRSS: Workshop on Implicit Representations for Robotic Manipulation @ RSS, 2022
2022
-
[18]
MIMIC-D: Multi-modal imitation for multi-agent coordination with decentralized diffusion policies
Dayi Dong et al., “MIMIC-D: Multi-modal imitation for multi-agent coordination with decentralized diffusion policies”, inICRA. 2026, IEEE
2026
-
[19]
An initial introduction to cooperative multi-agent reinforcement learning
Christopher Amato, “An initial introduction to cooperative multi-agent reinforcement learning”,arXiv preprint arXiv:2405.06161, 2024
-
[20]
MADiff: Offline multi-agent learning with diffusion models
Zhengbang Zhu et al., “MADiff: Offline multi-agent learning with diffusion models”, inNeurIPS, 2024, pp. 4177–4206
2024
-
[21]
Latent theory of mind: A decentralized diffusion architecture for cooperative manipulation
Chengyang He et al., “Latent theory of mind: A decentralized diffusion architecture for cooperative manipulation”, inCoRL. 2025, PMLR
2025
-
[22]
TD-MPC2: Scalable, robust world models for continuous control
Nicklas Hansen et al., “TD-MPC2: Scalable, robust world models for continuous control”, inICLR, 2024
2024
-
[23]
DINO-WM: World models on pre-trained visual features enable zero-shot planning
Gaoyue Zhou et al., “DINO-WM: World models on pre-trained visual features enable zero-shot planning”, inICML. 2025, pp. 79115–79135, PMLR
2025
-
[24]
DynaMo: In-domain dynamics pretraining for visuo-motor control
Zichen Jeff Cui et al., “DynaMo: In-domain dynamics pretraining for visuo-motor control”, inNeurIPS, 2024, pp. 33933–33961
2024
-
[25]
Hierarchical world models as visual whole- body humanoid controllers
Nicklas Hansen et al., “Hierarchical world models as visual whole- body humanoid controllers”, inICLR, 2025
2025
-
[26]
Denoising diffusion probabilistic models
Jonathan Ho et al., “Denoising diffusion probabilistic models”, in NeurIPS, 2020, pp. 6840–6851
2020
-
[27]
Oliehoek et al.,A Concise Introduction to Decentralized POMDPs, Springer, 2016
Frans A. Oliehoek et al.,A Concise Introduction to Decentralized POMDPs, Springer, 2016
2016
-
[28]
Character controllers using motion V AEs
Hung Yu Ling et al., “Character controllers using motion V AEs”, ACM Trans. Graph., vol. 39, no. 4, pp. 1–12, 2020
2020
-
[29]
Haoru Xue et al., “LeVERB: Humanoid whole-body control with latent vision-language instruction”,arXiv preprint arXiv:2506.13751, 2025
-
[30]
Sigmoid loss for language image pre-training
Xiaohua Zhai et al., “Sigmoid loss for language image pre-training”, inICCV. 2023, pp. 11941–11952, IEEE
2023
-
[31]
Attention is all you need
Ashish Vaswani et al., “Attention is all you need”, inNeurIPS, 2017, pp. 5998–6008
2017
-
[32]
Fixing a broken ELBO
Alexander A. Alemi et al., “Fixing a broken ELBO”, inICML. 2018, pp. 159–168, PMLR
2018
-
[33]
The unsurprising effectiveness of pre-trained vision models for control
Simone Parisi et al., “The unsurprising effectiveness of pre-trained vision models for control”, inICML. 2022, pp. 17359–17371, PMLR
2022
-
[34]
Pre-trained text-to-image diffusion models are versatile representation learners for control
Gunshi Gupta et al., “Pre-trained text-to-image diffusion models are versatile representation learners for control”, inNeurIPS, 2024, pp. 74182–74210
2024
-
[35]
FiLM: Visual reasoning with a general condition- ing layer
Ethan Perez et al., “FiLM: Visual reasoning with a general condition- ing layer”, inAAAI, 2018, vol. 32, pp. 3942–3951
2018
-
[36]
MotionDiffuser: Controllable multi-agent motion prediction using diffusion
Chiyu Jiang et al., “MotionDiffuser: Controllable multi-agent motion prediction using diffusion”, inCVPR. 2023, pp. 9644–9653, IEEE
2023
-
[37]
A diffusion-model of joint interactive navigation
Matthew Niedoba et al., “A diffusion-model of joint interactive navigation”, inNeurIPS, 2023, pp. 55995–56011
2023
-
[38]
GauDP: Reinventing multi-agent collaboration through gaussian-image synergy in diffusion policies
Ziye Wang et al., “GauDP: Reinventing multi-agent collaboration through gaussian-image synergy in diffusion policies”, inNeurIPS, 2025, pp. 5620–5639
2025
-
[39]
Dense policy: Bidirectional autoregressive learning of actions
Yue Su et al., “Dense policy: Bidirectional autoregressive learning of actions”, inICCV. 2025, pp. 14486–14495, IEEE
2025
-
[40]
3D diffusion policy: Generalizable visuomotor policy learning via simple 3D representations
Yanjie Ze et al., “3D diffusion policy: Generalizable visuomotor policy learning via simple 3D representations”, inRSS, 2024, vol. 20
2024
-
[41]
3D gaussian splatting for real-time radiance field rendering
Bernhard Kerbl et al., “3D gaussian splatting for real-time radiance field rendering”,ACM Trans. Graph., vol. 42, no. 4, pp. 1–14, 2023
2023
-
[42]
Tianxing Chen et al., “RoboTwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation”,arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.