MotionHalluc: Diagnosing Kinematic Hallucinations in Fine-Grained Motion Reasoning
Pith reviewed 2026-06-26 08:57 UTC · model grok-4.3
The pith
Injecting explicit kinematic measurements into multimodal models reduces motion hallucinations by 10.6 percent on average in cross-video tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
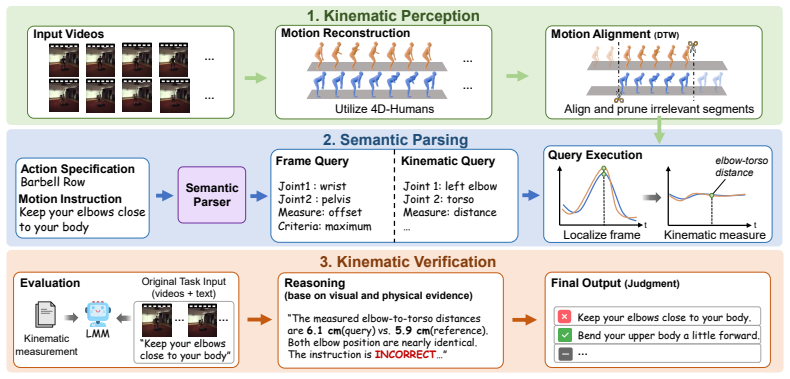
MotionHalluc evaluates fine-grained motion instruction generation across paired videos using 1540 questions on 553 pairs along directional, attributional, and temporal hallucination axes. Large multimodal models exhibit high hallucination rates on these tasks. The Perceive-Parse-Verify baseline extracts kinematic measurements from the videos, converts instructions into executable queries, and supplies the measurements at inference without training, delivering an average 10.6 percent performance improvement across tested models and indicating that explicit quantitative measurements form a key factor in lowering hallucinations during cross-video motion comparison.
What carries the argument
The Perceive-Parse-Verify (PPV) baseline, which converts generated instructions into measurement queries and injects kinematic measurements from the video pair at inference time to verify and correct outputs.
If this is right
- Motion reasoning improves when models receive explicit numerical measurements rather than relying only on learned visual patterns.
- The three hallucination dimensions provide a structured way to diagnose failures in paired-video comparison tasks.
- Training-free measurement injection offers a practical way to raise accuracy across existing multimodal models without retraining.
- Kinematic differences in direction, attribution, and timing can be directly quantified to ground corrective instructions.
Where Pith is reading between the lines
- The same measurement-injection step could be tested on single-video motion description tasks where quantitative errors also occur.
- Extending the benchmark to longer action sequences or multi-person interactions would reveal whether the gain scales with task complexity.
- Models that already output structured data might integrate the measurements more efficiently than those producing free-form text.
- The approach suggests a general pattern: supplying verifiable scalars can reduce hallucination in any multimodal setting that involves measurable physical change.
Load-bearing premise
The 1540 questions and three hallucination dimensions capture real kinematic differences without labeling bias or post-hoc selection, and the PPV baseline can run at inference without unstated limits on video quality or output format.
What would settle it
Running the PPV method on a fresh collection of video pairs outside the 553 used in the benchmark and checking whether the 10.6 percent average gain still appears would test the central claim.
Figures







read the original abstract
Motion instruction generation in cross-video comparison aims to produce corrective feedback that describes the differences between a query and a reference motion. However, existing models often generate instructions that exhibit motion hallucinations, failing to reflect actual kinematic differences between paired videos. To systematically investigate these hallucinations, we introduce MotionHalluc, a dedicated benchmark for evaluating motion hallucinations in paired-video comparison. MotionHalluc comprises 1540 fine-grained questions over 553 video pairs, evaluating hallucinations along three core dimensions: (1)directional hallucination, (2)attributional hallucination, and (3)temporal hallucination. Extensive evaluations of state-of-the-art large multimodal models demonstrate high susceptibility to these hallucinations. Furthermore, we provide Perceive-Parse-Verify (PPV) as a training-free measurements extraction and verification baseline that converts candidate instructions into executable measurement queries and supplies kinematic measurements at inference time. Our results show that this simple measurements injection yields an average 10.6% performance gain across models, suggesting that motion reasoning with explicit quantitative measurements is a key factor in reducing hallucinations in cross-video comparison. Our code and dataset will be made publicly available upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MotionHalluc benchmark comprising 1540 fine-grained questions over 553 video pairs to diagnose kinematic hallucinations in cross-video motion comparison along three dimensions (directional, attributional, temporal). It evaluates state-of-the-art large multimodal models, reports high hallucination susceptibility, and proposes a training-free Perceive-Parse-Verify (PPV) baseline that extracts and injects explicit kinematic measurements, yielding an average 10.6% performance gain.
Significance. If the benchmark is shown to be free of selection and labeling artifacts and the PPV gains are robustly measured, the work would supply a useful diagnostic resource for motion reasoning failures and evidence that explicit quantitative cues can mitigate hallucinations in video comparison tasks. Public release of the dataset and code would strengthen its utility for the multimodal and video understanding communities.
major comments (3)
- [Benchmark construction] Benchmark construction section: the manuscript supplies no protocol for sourcing the 553 video pairs, authoring or filtering the 1540 questions, ground-truth kinematic labeling process, or inter-annotator agreement statistics. These omissions are load-bearing because the headline 10.6% PPV gain and all hallucination-rate claims rest on the assumption that the questions faithfully and unbiasedly measure real kinematic differences.
- [Evaluation and results] Evaluation and results section: the reported average 10.6% performance gain across models is presented without statistical significance tests, confidence intervals, per-dimension breakdowns, or controls for video quality and output format assumptions. This prevents assessment of whether the PPV improvement is reliable or confounded.
- [PPV baseline] PPV baseline section: the description of converting instructions into executable measurement queries and performing verification lacks concrete details on query templates, the kinematic measurement functions used, and any assumptions about video resolution or model output parsing. These specifics are required to evaluate reproducibility and hidden dependencies.
minor comments (2)
- [Abstract] Abstract: the three hallucination dimensions are named but not briefly exemplified, making the scope of the benchmark harder to grasp on first reading.
- [Throughout] Terminology: ensure consistent use of 'motion instruction generation' versus 'corrective feedback' throughout the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key areas where additional detail will strengthen the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the manuscript supplies no protocol for sourcing the 553 video pairs, authoring or filtering the 1540 questions, ground-truth kinematic labeling process, or inter-annotator agreement statistics. These omissions are load-bearing because the headline 10.6% PPV gain and all hallucination-rate claims rest on the assumption that the questions faithfully and unbiasedly measure real kinematic differences.
Authors: We agree that the current manuscript lacks sufficient detail on benchmark construction. In the revised version we will expand the relevant section to describe: the sourcing protocol and selection criteria for the 553 video pairs; the question authoring, filtering, and validation process with examples; the ground-truth kinematic labeling procedure; and inter-annotator agreement statistics. These additions will allow readers to evaluate potential selection or labeling artifacts. revision: yes
-
Referee: [Evaluation and results] Evaluation and results section: the reported average 10.6% performance gain across models is presented without statistical significance tests, confidence intervals, per-dimension breakdowns, or controls for video quality and output format assumptions. This prevents assessment of whether the PPV improvement is reliable or confounded.
Authors: We acknowledge the value of more rigorous statistical reporting. The revision will add paired statistical significance tests, confidence intervals for the performance metrics, per-dimension result breakdowns, and explicit discussion of controls or assumptions regarding video quality and output formats. These changes will clarify the reliability of the reported gains. revision: yes
-
Referee: [PPV baseline] PPV baseline section: the description of converting instructions into executable measurement queries and performing verification lacks concrete details on query templates, the kinematic measurement functions used, and any assumptions about video resolution or model output parsing. These specifics are required to evaluate reproducibility and hidden dependencies.
Authors: We agree that greater specificity is needed for reproducibility. The revised manuscript will include concrete query templates, the exact kinematic measurement functions (with definitions for directional, attributional, and temporal aspects), and the assumptions made about video resolution and output parsing. Pseudocode and illustrative examples will also be added. revision: yes
Circularity Check
No circularity: purely empirical benchmark and baseline evaluation.
full rationale
The paper introduces MotionHalluc benchmark (1540 questions over 553 pairs) and PPV baseline without any equations, fitted parameters, derivations, or self-citations that reduce claims to inputs by construction. Evaluations and the reported 10.6% gain are direct empirical measurements on the introduced dataset; no self-definitional, fitted-prediction, or uniqueness-imported steps exist. Potential selection bias in question authoring is a validity concern, not circularity per the defined patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Motion hallucinations in cross-video comparison fall into directional, attributional, and temporal categories.
Reference graph
Works this paper leans on
-
[1]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[2]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661, 2025
Pith/arXiv arXiv 2025
-
[3]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
Pith/arXiv arXiv 2025
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[6]
Cigtime: Corrective instruc- tion generation through inverse motion editing.Advances in Neural Information Processing Systems, 37:102011–102035, 2024
Qihang Fang, Chengcheng Tang, Bugra Tekin, and Yanchao Yang. Cigtime: Corrective instruc- tion generation through inverse motion editing.Advances in Neural Information Processing Systems, 37:102011–102035, 2024
2024
-
[7]
Coachme: Decoding sport elements with a reference-based coaching instruction generation model
Wei-Hsin Yeh, Yu-An Su, Chih-Ning Chen, Yi-Hsueh Lin, Calvin Ku, Wenhsin Chiu, Min-Chun Hu, and Lun-Wei Ku. Coachme: Decoding sport elements with a reference-based coaching instruction generation model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29126–29151, 2025
2025
-
[8]
Unipose: A unified multimodal framework for human pose comprehension, generation and editing
Yiheng Li, Ruibing Hou, Hong Chang, Shiguang Shan, and Xilin Chen. Unipose: A unified multimodal framework for human pose comprehension, generation and editing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27805–27815, 2025
2025
-
[9]
Pose- fix: Correcting 3d human poses with natural language
Ginger Delmas, Philippe Weinzaepfel, Francesc Moreno-Noguer, and Grégory Rogez. Pose- fix: Correcting 3d human poses with natural language. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15018–15028, 2023
2023
-
[10]
Yipeng Du, Tiehan Fan, Kepan Nan, Rui Xie, Penghao Zhou, Xiang Li, Jian Yang, Zhenheng Yang, and Ying Tai. Motionsight: Boosting fine-grained motion understanding in multimodal llms.arXiv preprint arXiv:2506.01674, 2025
arXiv 2025
-
[11]
Domain knowledge-informed self-supervised representations for workout form assessment
Paritosh Parmar, Amol Gharat, and Helge Rhodin. Domain knowledge-informed self-supervised representations for workout form assessment. InEuropean conference on computer vision, pages 105–123. Springer, 2022
2022
-
[12]
Yoga pose estimation and feedback generation using deep learning.Computational Intelligence and Neuroscience, 2022(1):4311350, 2022
Vivek Anand Thoutam, Anugrah Srivastava, Tapas Badal, Vipul Kumar Mishra, GR Sinha, Aditi Sakalle, Harshit Bhardwaj, and Manish Raj. Yoga pose estimation and feedback generation using deep learning.Computational Intelligence and Neuroscience, 2022(1):4311350, 2022
2022
-
[13]
Yoga-82: a new dataset for fine-grained classification of human poses
Manisha Verma, Sudhakar Kumawat, Yuta Nakashima, and Shanmuganathan Raman. Yoga-82: a new dataset for fine-grained classification of human poses. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 1038–1039, 2020
2020
-
[14]
Integrating multimodal ai technologies for sports injury prediction and rehabilitation: Systematic review.Journal of Human Sport and Exercise, 21(1):22–37, 2026
Pengbo Wang, Aodi Wang, and Saidi Wang. Integrating multimodal ai technologies for sports injury prediction and rehabilitation: Systematic review.Journal of Human Sport and Exercise, 21(1):22–37, 2026. 10
2026
-
[15]
Mash-vlm: Mitigating action-scene hallucination in video-llms through disentangled spatial- temporal representations
Kyungho Bae, Jinhyung Kim, Sihaeng Lee, Soonyoung Lee, Gunhee Lee, and Jinwoo Choi. Mash-vlm: Mitigating action-scene hallucination in video-llms through disentangled spatial- temporal representations. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13744–13753, 2025
2025
-
[16]
Mm-spubench: Towards better understanding of spurious biases in multimodal llms
Wenqian Ye, Bohan Liu, Guangtao Zheng, Di Wang, Xu Cao, Yunsheng Ma, Bolin Lai, James M Rehg, and Aidong Zhang. Mm-spubench: Towards better understanding of spurious biases in multimodal llms. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 2854–2865, 2026
2026
-
[17]
The instinctive bias: Spurious images lead to illusion in mllms
Tianyang Han, Qing Lian, Rui Pan, Renjie Pi, Jipeng Zhang, Shizhe Diao, Yong Lin, and Tong Zhang. The instinctive bias: Spurious images lead to illusion in mllms. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16163–16177, 2024
2024
-
[18]
Mhbench: Demystifying motion hallucination in videollms
Ming Kong, Xianzhou Zeng, Luyuan Chen, Yadong Li, Bo Yan, and Qiang Zhu. Mhbench: Demystifying motion hallucination in videollms. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 4401–4409, 2025
2025
-
[19]
Slowfocus: Enhancing fine-grained temporal understanding in video llm.Advances in Neural Information Processing Systems, 37:81808–81835, 2024
Ming Nie, Dan Ding, Chunwei Wang, Yuanfan Guo, Jianhua Han, Hang Xu, and Li Zhang. Slowfocus: Enhancing fine-grained temporal understanding in video llm.Advances in Neural Information Processing Systems, 37:81808–81835, 2024
2024
-
[20]
Vidhalluc: Evaluating temporal hallucinations in multimodal large language models for video understanding
Chaoyu Li, Eun Woo Im, and Pooyan Fazli. Vidhalluc: Evaluating temporal hallucinations in multimodal large language models for video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13723–13733, 2025
2025
-
[21]
Zongxia Li, Xiyang Wu, Guangyao Shi, Yubin Qin, Hongyang Du, Fuxiao Liu, Tianyi Zhou, Dinesh Manocha, and Jordan Lee Boyd-Graber. Videohallu: Evaluating and mitigating multi- modal hallucinations on synthetic video understanding.arXiv preprint arXiv:2505.01481, 2025
arXiv 2025
-
[22]
What and how well you performed? a multitask learning approach to action quality assessment
Paritosh Parmar and Brendan Tran Morris. What and how well you performed? a multitask learning approach to action quality assessment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 304–313, 2019
2019
-
[23]
Assessing the quality of actions
Hamed Pirsiavash, Carl V ondrick, and Antonio Torralba. Assessing the quality of actions. In European conference on computer vision, pages 556–571. Springer, 2014
2014
-
[24]
Interpretable long-term action quality assessment.arXiv preprint arXiv:2408.11687, 2024
Xu Dong, Xinran Liu, Wanqing Li, Anthony Adeyemi-Ejeye, and Andrew Gilbert. Interpretable long-term action quality assessment.arXiv preprint arXiv:2408.11687, 2024
arXiv 2024
-
[25]
Rui Henriques, Ricardo Rei, Pedro Henrique Martins, et al. Can vision language models judge action quality? an empirical evaluation.arXiv preprint arXiv:2604.08294, 2026
Pith/arXiv arXiv 2026
-
[26]
Attention-driven multimodal alignment for long-term action quality assessment.Applied Soft Computing, page 113649, 2025
Xin Wang, Peng-Jie Li, and Yuan-Yuan Shen. Attention-driven multimodal alignment for long-term action quality assessment.Applied Soft Computing, page 113649, 2025
2025
-
[27]
A computer vision-based yoga pose grading approach using contrastive skeleton feature representations
Yubin Wu, Qianqian Lin, Mingrun Yang, Jing Liu, Jing Tian, Dev Kapil, and Laura Vanderbloe- men. A computer vision-based yoga pose grading approach using contrastive skeleton feature representations. InHealthcare, volume 10, page 36. MDPI, 2021
2021
-
[28]
3d-yoga: a 3d yoga dataset for visual- based hierarchical sports action analysis
Jianwei Li, Haiqing Hu, Jinyang Li, and Xiaomei Zhao. 3d-yoga: a 3d yoga dataset for visual- based hierarchical sports action analysis. InProceedings of the Asian Conference on Computer Vision, pages 434–450, 2022
2022
-
[29]
Deep learning-based human body pose estimation in providing feedback for physical movement: A review.Heliyon, 10(17), 2024
Atima Tharatipyakul, Thanawat Srikaewsiew, and Suporn Pongnumkul. Deep learning-based human body pose estimation in providing feedback for physical movement: A review.Heliyon, 10(17), 2024
2024
-
[30]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023. 11
2023
-
[31]
Meng Luo, Shengqiong Wu, Liqiang Jing, Tianjie Ju, Li Zheng, Jinxiang Lai, Tianlong Wu, Xinya Du, Jian Li, Siyuan Yan, et al. Dr. v: A hierarchical perception-temporal-cognition framework to diagnose video hallucination by fine-grained spatial-temporal grounding.arXiv preprint arXiv:2509.11866, 2025
arXiv 2025
-
[32]
Xiyang Wu, Zongxia Li, Jihui Jin, Guangyao Shi, Gouthaman KV , Vishnu Raj, Nilotpal Sinha, Jingxi Chen, Fan Du, and Dinesh Manocha. Mass: Motion-aware spatial-temporal grounding for physics reasoning and comprehension in vision-language models.arXiv preprint arXiv:2511.18373, 2025
Pith/arXiv arXiv 2025
-
[33]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
2002
-
[34]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004
2004
-
[35]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment, 2023.arXiv preprint arXiv:2303.16634, 12:1, 2023
Pith/arXiv arXiv 2023
-
[36]
Hongcheng Gao, Jiashu Qu, Jingyi Tang, Baolong Bi, Yue Liu, Hongyu Chen, Li Liang, Li Su, and Qingming Huang. Exploring hallucination of large multimodal models in video understanding: Benchmark, analysis and mitigation.arXiv preprint arXiv:2503.19622, 2025
arXiv 2025
-
[37]
Video action differencing.arXiv preprint arXiv:2503.07860, 2025
James Burgess, Xiaohan Wang, Yuhui Zhang, Anita Rau, Alejandro Lozano, Lisa Dunlap, Trevor Darrell, and Serena Yeung-Levy. Video action differencing.arXiv preprint arXiv:2503.07860, 2025
arXiv 2025
-
[38]
Benedetta Liberatori, Alessandro Conti, Lorenzo Vaquero, Yiming Wang, Elisa Ricci, and Paolo Rota. Convis-bench: Estimating video similarity through semantic concepts.arXiv preprint arXiv:2509.19245, 2025
arXiv 2025
-
[39]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: a skinned multi-person linear model.ACM Trans. Graph., 34(6):248:1–248:16, 2015. doi: 10.1145/2816795.2818013. URLhttps://doi.org/10.1145/2816795.2818013
-
[40]
Skeleton-based action recognition with non- linear dependency modeling and hilbert-schmidt independence criterion
Haipeng Chen, Yuheng Yang, and Yingda Lyu. Skeleton-based action recognition with non- linear dependency modeling and hilbert-schmidt independence criterion. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 2043–2051, 2025
2043
-
[41]
End- to-end temporal action detection with transformer.IEEE Transactions on Image Processing, 31: 5427–5441, 2022
Xiaolong Liu, Qimeng Wang, Yao Hu, Xu Tang, Shiwei Zhang, Song Bai, and Xiang Bai. End- to-end temporal action detection with transformer.IEEE Transactions on Image Processing, 31: 5427–5441, 2022
2022
-
[42]
Humans in 4d: Reconstructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Reconstructing and tracking humans with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14783–14794, 2023
2023
-
[43]
Wham: Reconstructing world- grounded humans with accurate 3d motion
Soyong Shin, Juyong Kim, Eni Halilaj, and Michael J Black. Wham: Reconstructing world- grounded humans with accurate 3d motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2070–2080, 2024
2070
-
[44]
Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36:20067–20079, 2023
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36:20067–20079, 2023
2023
-
[45]
Motionllm: Understanding human behaviors from human motions and videos.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Ling-Hao Chen, Shunlin Lu, Ailing Zeng, Hao Zhang, Benyou Wang, Ruimao Zhang, and Lei Zhang. Motionllm: Understanding human behaviors from human motions and videos.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[46]
Motiongpt: Finetuned llms are general-purpose motion generators
Yaqi Zhang, Di Huang, Bin Liu, Shixiang Tang, Yan Lu, Lu Chen, Lei Bai, Qi Chu, Nenghai Yu, and Wanli Ouyang. Motiongpt: Finetuned llms are general-purpose motion generators. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7368–7376, 2024. 12
2024
-
[47]
Motiongpt3: Human motion as a second modality.URL https://arxiv
Bingfan Zhu, Biao Jiang, Sunyi Wang, Shixiang Tang, Tao Chen, Linjie Luo, Youyi Zheng, and Xin Chen. Motiongpt3: Human motion as a second modality.URL https://arxiv. org/abs/2506.24086, 2025
arXiv 2025
-
[48]
Hmvlm: Human motion-vision-lanuage model via moe lora.arXiv preprint arXiv:2511.01463, 2025
Lei Hu, Yongjing Ye, and Shihong Xia. Hmvlm: Human motion-vision-lanuage model via moe lora.arXiv preprint arXiv:2511.01463, 2025
arXiv 2025
-
[49]
Qi Wu, Yubo Zhao, Yifan Wang, Xinhang Liu, Yu-Wing Tai, and Chi-Keung Tang. Motion- agent: A conversational framework for human motion generation with llms.arXiv preprint arXiv:2405.17013, 2024
arXiv 2024
-
[50]
Aifit: Automatic 3d human-interpretable feedback models for fitness training
Mihai Fieraru, Mihai Zanfir, Silviu Cristian Pirlea, Vlad Olaru, and Cristian Sminchisescu. Aifit: Automatic 3d human-interpretable feedback models for fitness training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9919–9928, 2021
2021
-
[51]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019
2019
-
[52]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5152–5161, June 2022
2022
-
[53]
Dynamic programming algorithm optimization for spoken word recognition.IEEE transactions on acoustics, speech, and signal processing, 26(1):43–49, 1978
Hiroaki Sakoe and Seibi Chiba. Dynamic programming algorithm optimization for spoken word recognition.IEEE transactions on acoustics, speech, and signal processing, 26(1):43–49, 1978
1978
-
[54]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[55]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[56]
Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[57]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments.IEEE transactions on pattern analysis and machine intelligence, 36(7):1325–1339, 2013. 13 A Benchmark Download Instruction The MotionHalluc benchmark and code will be made publicly avai...
2013
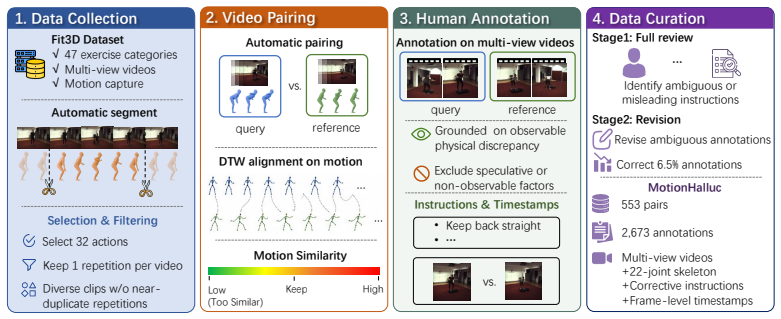
-
[58]
Human Annotation Fit3D Dataset Automatic segment √ 47 exercise categories √ Multi-view videos √ Motion capture Select 32 actions Selection & Filtering Keep 1 repetition per video Diverse clips w/o near- duplicate repetitions Low (Too Similar) Keep High Motion Similarity DTW alignment on motion Automatic pairing vs. query reference Annotation on multi-view...
-
[59]
When the dumbbells reach the highest point,
Data Curation Stage1: Full review … Identify ambiguous or misleading instructions Stage2: Revision Revise ambiguous annotations Correct 6.5% annotations MotionHalluc 553 pairs 2,673 annotations Multi-view videos +22-joint skeleton +Corrective instructions +Frame-level timestamps Figure 5: Data collection, pairing, and annotation pipeline for MotionHalluc....
-
[60]
locate_three_joint_angle_extreme_frame(joint_triplet: List[str], extreme_type: str) - Locate frame index by extreme angle at the center joint from [start_joint, center_joint, end_joint]
-
[61]
UD", "LR
locate_joint_axis_offset_extreme_frame(target_joint: str, reference_joint: str, axis: str, extreme_type: str) - Locate frame index by extreme target_joint - reference_joint displacement along one axis. - axis must be one of ["UD", "LR", "FB"]
-
[62]
locate_pelvis_y_extreme_frame(extreme_type: str) - Locate frame index by extreme Pelvis Y coordinate
-
[63]
straight_up
locate_joint_angle_to_world_direction_extreme_frame(target_joint: str, source_joint: str, world_direction: str, extreme_type: str) - Locate frame index by extreme angle between bone vector source_joint->target_joint and a world direction. - world_direction must be one of ["straight_up", "straight_forward", "straight_down"]. Rules:
-
[65]
Each key moment can only use one function call
-
[66]
Figure 8: Prompt for frame-level queries
Do not invent any function or argument names. Figure 8: Prompt for frame-level queries. Given an action description and a corrective instruction for that action, return a JSON object that maps the correction sentence to structured function calls. Allowed functions (must use only these 4 function names):
-
[67]
compute_three_joint_angle(joint_triplet: List[str]) - Computes the angle (0-180 deg) at the center joint from [start_joint, center_joint, end_joint]
-
[68]
UD", "LR
get_joint_axis_offset(target_joint: str, reference_joint: str, axis: str) - Computes target_joint - reference_joint displacement along one axis. - axis must be one of ["UD", "LR", "FB"]
-
[69]
get_pelvis_y_coordinate() - Returns Pelvis Y coordinate (height)
-
[70]
straight_up
get_joint_angle_to_world_direction(target_joint: str, source_joint: str, world_direction: str) - Computes angle (0-180 deg) between bone vector source_joint->target_joint and a world direction. - world_direction must be one of ["straight_up", "straight_forward", "straight_down"]. Rules:
-
[71]
No explanation
Output JSON only. No explanation
-
[72]
One correction sentence can use multiple function calls
-
[73]
If a correction cannot be mapped precisely, output an empty object for that correction
-
[74]
Figure 9: Prompt for kinematic queries
Do not invent any function or argument names. Figure 9: Prompt for kinematic queries. Importantly, the use of only four atomic functions avoids imposing handcrafted mappings between instructions and functions or between action categories and measurement types. This design reduces human bias and limits implicit assumptions in the parsing process, enabling ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.