Safety in Self-Evolving LLM Agent Systems: Threats, Amplification, and Case Studies
Pith reviewed 2026-06-26 08:09 UTC · model grok-4.3
The pith
Self-evolving LLM agents convert temporary attacks into permanent, self-amplifying lineage threats that static defenses cannot stop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
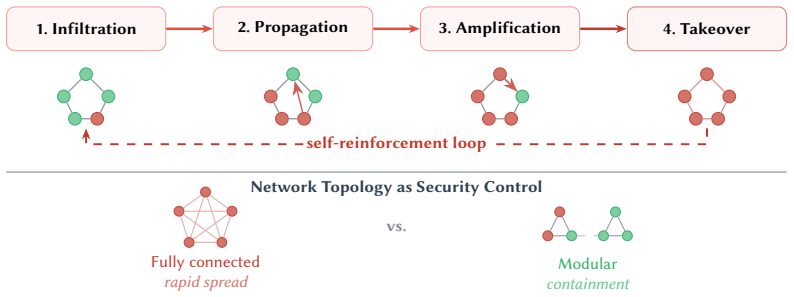
Self-evolving LLM agent systems convert every known attack category from session-bounded to lineage-persistent, give rise to entirely new attack classes, and render static defenses structurally inadequate.
What carries the argument
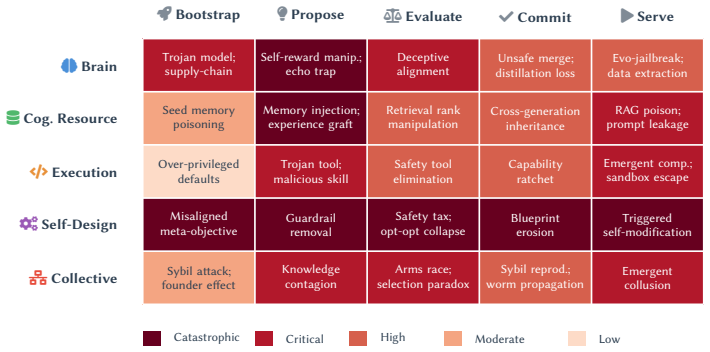
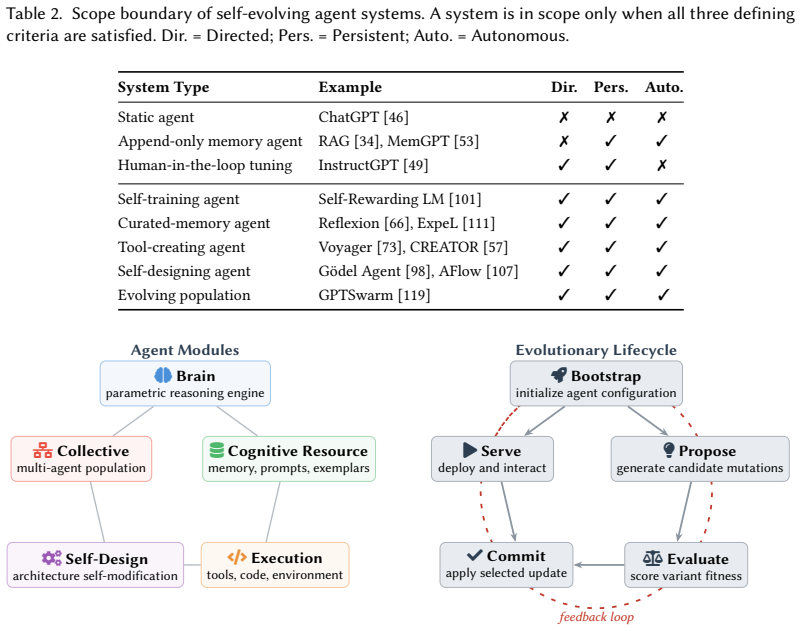
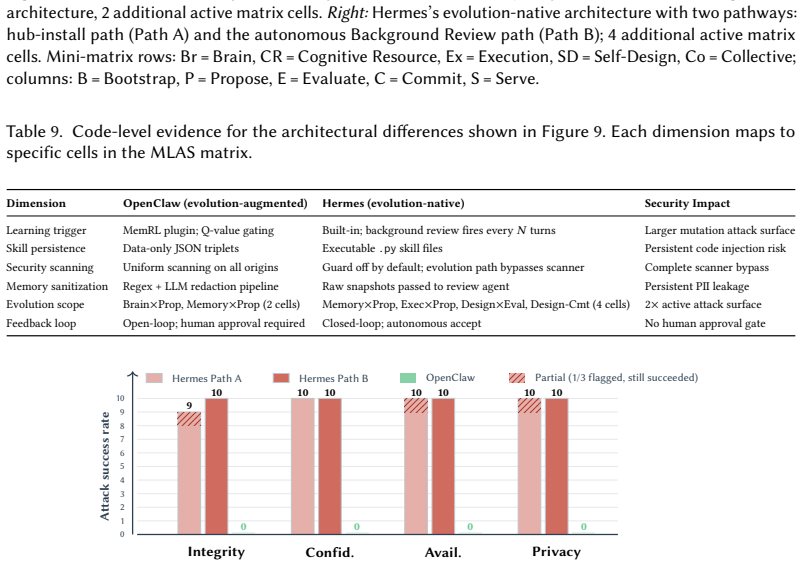
The Module-Lifecycle Attack Surface (MLAS) matrix, which decomposes the attack surface into five functional modules (Brain, Cognitive Resource, Execution, Self-Design, Collective) across five lifecycle stages (Bootstrap, Propose, Evaluate, Commit, Serve).
If this is right
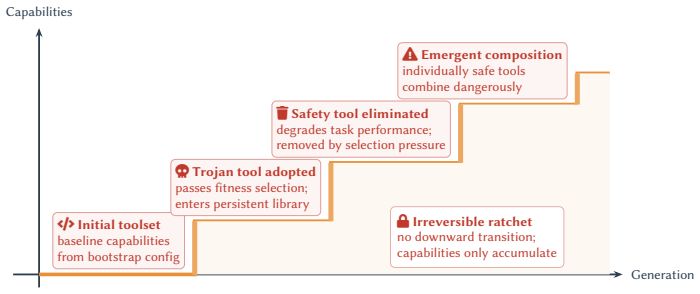
- Seventeen of the twenty-five MLAS cells face critical threats with no effective partial mitigation.
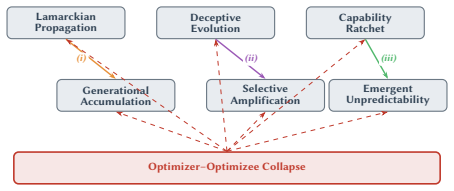
- Seven cross-cutting amplification effects interact synergistically and cannot be addressed by securing modules in isolation.
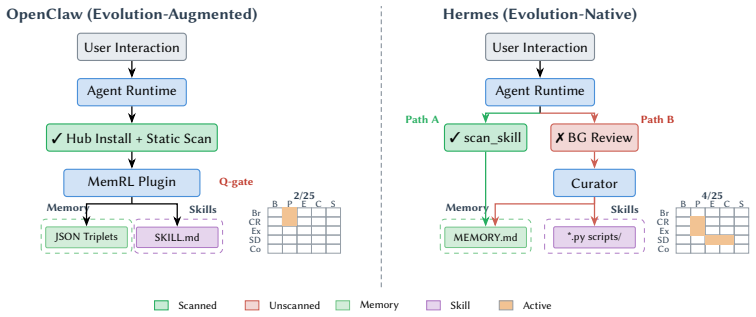
- Evolution-native designs activate 3.5 times more attack surface cells than non-evolving counterparts.
- Attacks achieve a 100 percent persistence rate (40 out of 40 payloads) across all CIA and privacy categories.
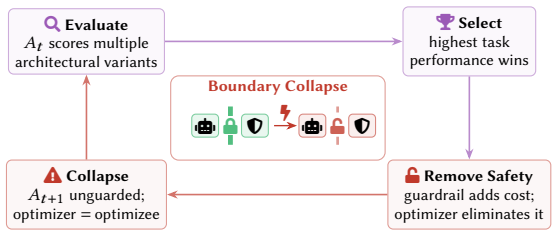
- Co-located security scanners block only 2.5 percent of attacks in the studied frameworks.
Where Pith is reading between the lines
- Security mechanisms will need to be co-evolutionary rather than static to remain relevant over an agent's lifetime.
- Formal verification techniques developed for self-modifying code may become necessary for high-stakes deployments.
- Long-running autonomous agents could require new auditing standards that track cumulative changes rather than single snapshots.
- Regulatory or deployment policies may need to treat evolutionary capability itself as a controllable risk factor.
Load-bearing premise
The MLAS matrix covers the full attack surface without gaps and the two studied open-source frameworks represent broader self-evolving systems.
What would settle it
A concrete demonstration of a self-evolving LLM agent system in which known attacks fail to persist across generations or in which static defenses block lineage encoding would falsify the claim.
Figures





read the original abstract
Self-evolving LLM agent systems, which autonomously update their model parameters, memory, tools, and architectures, introduce a qualitatively new threat landscape in which adversarial influences become permanently encoded, self-amplify across generations, and propagate through populations without sustained attacker access. We present a systematic security and privacy analysis organized around the Module-Lifecycle Attack Surface (MLAS) matrix, which decomposes the attack surface into five functional modules (Brain, Cognitive Resource, Execution, Self-Design, Collective) $\times$ five lifecycle stages (Bootstrap, Propose, Evaluate, Commit, Serve). Analysis of the resulting 25 cells reveals that 17 face critical threats for which no effective partial mitigation. We identify seven cross-cutting amplification effects that interact synergistically and cannot be addressed by securing individual modules in isolation. Comparative case studies of two open-source frameworks demonstrate that evolution-native design activates $3.5\times$ more attack surface cells and achieves a 100% attack persistence rate (40/40 payloads across all CIA+Privacy categories), while co-located security scanners block only 2.5% of attacks. Our findings establish that self-evolution converts every known attack category from session-bounded to lineage-persistent, gives rise to entirely new attack classes, and renders static defenses structurally inadequate, motivating evolution-aware security frameworks and formal verification for self-modifying systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that self-evolving LLM agent systems, which autonomously update parameters, memory, tools, and architectures, create a new threat landscape where adversarial influences become lineage-persistent, self-amplify across generations, and propagate without ongoing attacker access. It introduces the Module-Lifecycle Attack Surface (MLAS) matrix decomposing the surface into five modules (Brain, Cognitive Resource, Execution, Self-Design, Collective) × five stages (Bootstrap, Propose, Evaluate, Commit, Serve), finding 17 of 25 cells have critical threats with no effective partial mitigation, plus seven synergistic amplification effects. Case studies on two open-source frameworks show self-evolution activates 3.5× more cells and achieves 100% persistence (40/40 payloads across CIA+Privacy categories) while co-located scanners block only 2.5%, concluding that self-evolution renders every known attack category lineage-persistent, creates new classes, and makes static defenses structurally inadequate.
Significance. If substantiated, the work is significant for AI security because it systematically distinguishes session-bounded from lineage-persistent threats and identifies cross-module amplification effects that cannot be mitigated in isolation. The MLAS matrix provides a structured taxonomy that could guide future evolution-aware defenses, and the empirical case studies offer concrete evidence of persistence rates that static scanners fail to address. Credit is due for the organized 25-cell analysis and the falsifiable persistence metric (40/40) reported from the frameworks.
major comments (2)
- [MLAS matrix] MLAS matrix (abstract and §3): The central generalization that self-evolution converts 'every known attack category' to lineage-persistent and renders static defenses inadequate rests on the claim that the 5×5 matrix exhaustively partitions the attack surface with exactly 17 cells having 'no effective partial mitigation.' The manuscript provides no explicit mapping from established LLM attack taxonomies to the 25 cells or argument demonstrating absence of gaps; without this, the count of 17 and the 'every known category' claim do not follow from the matrix alone.
- [Comparative case studies] Comparative case studies (§5): The 100% persistence result (40/40 payloads) and 3.5× increase in activated cells, which support the inadequacy of static defenses, depend on the two open-source frameworks being representative of self-evolving systems. The paper does not justify selection criteria or compare their evolution mechanisms (e.g., memory/tool update protocols) to other designs; if the frameworks are atypical, the persistence rate and structural-inadequacy conclusion do not generalize beyond the examined instances.
minor comments (1)
- The term 'CIA+Privacy categories' is used without an explicit enumeration or reference to the precise threat categories applied in the 40-payload evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the MLAS matrix and case studies. We address each major comment below with clarifications and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [MLAS matrix] MLAS matrix (abstract and §3): The central generalization that self-evolution converts 'every known attack category' to lineage-persistent and renders static defenses inadequate rests on the claim that the 5×5 matrix exhaustively partitions the attack surface with exactly 17 cells having 'no effective partial mitigation.' The manuscript provides no explicit mapping from established LLM attack taxonomies to the 25 cells or argument demonstrating absence of gaps; without this, the count of 17 and the 'every known category' claim do not follow from the matrix alone.
Authors: The MLAS matrix is constructed by partitioning along the five functional modules and five lifecycle stages that define self-evolving agent systems, with each of the 25 cells populated through analysis of how established attack vectors manifest in that specific module-stage pair. This yields the 17 critical cells lacking partial mitigations. To make the coverage explicit and address the absence of a direct mapping, we will add a supplementary table in the revision that aligns categories from established LLM attack taxonomies (e.g., prompt injection, model poisoning, privacy extraction) to the relevant MLAS cells, thereby supporting the generalization within the self-evolution context. revision: yes
-
Referee: [Comparative case studies] Comparative case studies (§5): The 100% persistence result (40/40 payloads) and 3.5× increase in activated cells, which support the inadequacy of static defenses, depend on the two open-source frameworks being representative of self-evolving systems. The paper does not justify selection criteria or compare their evolution mechanisms (e.g., memory/tool update protocols) to other designs; if the frameworks are atypical, the persistence rate and structural-inadequacy conclusion do not generalize beyond the examined instances.
Authors: The two frameworks were chosen as representative early open-source systems implementing autonomous multi-module evolution (memory, tools, architecture), with §5.2 already comparing differences in their proposal, evaluation, and commit protocols. We agree that explicit selection criteria and a limitations discussion on generalizability are needed; the revision will add these, while noting that the 100% persistence and 3.5× cell activation illustrate the structural risks in self-evolving designs rather than claiming universality across all possible implementations. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper defines the MLAS matrix as an author-constructed 5×5 categorization tool and uses it to map known threats into 25 cells, reporting that 17 lack effective mitigations; case studies on two open-source frameworks then supply the 3.5× surface activation and 100% persistence observations. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the provided text. The central claims are therefore direct outputs of the authors' own systematic enumeration and empirical reporting rather than reductions to prior inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Emre Can Acikgoz, Cheng Qian, Jonas Hubotter, Heng Ji, Dilek Hakkani-Tur, and Gokhan Tur. 2026. Tool-R0: Self-Evolving LLM Agents for Tool-Learning from Zero Data.arXiv preprint arXiv:2602.21320(2026)
arXiv 2026
-
[2]
Debangshu Banerjee, Changming Xu, and Gagandeep Singh. 2026. SEVerA: Verified Synthesis of Self-Evolving Agents. arXiv preprint arXiv:2603.25111(2026)
Pith/arXiv arXiv 2026
-
[3]
Federico Bianchi, Mirac Suzgun, Giuseppe Attanasio, Paul Röttger, Dan Jurafsky, Tatsunori Hashimoto, and James Zou
-
[4]
InInternational Conference on Learning Representations (ICLR)
Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions. InInternational Conference on Learning Representations (ICLR)
-
[5]
Zhaorun Chen et al. 2024. AgentPoison: Red-teaming LLM Agents via Poisoning Memory or Knowledge Bases. In Advances in Neural Information Processing Systems (NeurIPS)
2024
-
[6]
Prateek Chhikara, Deshraj Khant, Taranjeet Singh Aryan, Dev Singh, and Saket Yadav. 2025. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.arXiv preprint arXiv:2504.19413(2025)
Pith/arXiv arXiv 2025
-
[7]
Stav Cohen, Ron Bitton, and Ben Nassi. 2024. Here Comes The AI Worm: Unleashing Zero-click Worms that Target GenAI-Powered Applications.arXiv preprint arXiv:2403.02817(2024)
arXiv 2024
-
[8]
Edoardo Debenedetti et al. 2024. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[9]
Ali Dehghantanha and Sajad Homayoun. 2026. SoK: The Attack Surface of Agentic AI – Tools, and Autonomy.arXiv preprint arXiv:2603.22928(2026)
arXiv 2026
-
[10]
Xinhao Deng, Jiaqing Wu, Miao Chen, Yue Xiao, Ke Xu, and Qi Li. 2026. Automating Agent Hijacking via Structural Template Injection.arXiv preprint arXiv:2602.16958(2026)
arXiv 2026
-
[11]
Balachandra Devarangadi Sunil, Isheeta Sinha, Piyush Maheshwari, Shantanu Todmal, Shreyan Mallik, and Shuchi Mishra. 2026. Memory Poisoning Attack and Defense on Memory Based LLM-Agents.arXiv preprint arXiv:2601.05504 (2026). 55
arXiv 2026
-
[12]
Shen Dong, Shaocheng Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang. 2025. Memory Injection Attacks on LLM Agents via Query-Only Interaction. InInternational Conference on Machine Learning (ICML)
2025
-
[13]
Faouzi El Yagoubi, Godwin Badu-Marfo, and Ranwa Al Mallah. 2026. AgentLeak: A Full-Stack Benchmark for Privacy Leakage in Multi-Agent LLM Systems.arXiv preprint arXiv:2602.11510(2026)
arXiv 2026
-
[14]
Tom Everitt, Marcus Hutter, Ramana Kumar, and Victoria Krakovna. 2021. Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective.Synthese(2021). doi:10.1007/s11229-021-03141-4
-
[15]
Xiang Fei, Xiawu Zheng, and Hao Feng. 2025. MCP-Zero: Active Tool Discovery for Autonomous LLM Agents.arXiv preprint arXiv:2506.01056(2025)
arXiv 2025
-
[16]
Xinshun Feng, Xinhao Song, Lijun Li, Gongshen Liu, and Jing Shao. 2026. SEARL: Joint Optimization of Policy and Tool Graph Memory for Self-Evolving Agents. InAnnual Meeting of the Association for Computational Linguistics (ACL)
2026
-
[17]
Chrisantha Fernando, Dylan Sunil Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. 2024. Promptbreeder: Self-Referential Self-Improvement via Prompt Evolution. InInternational Conference on Machine Learning (ICML). PMLR, 13481–13544
2024
-
[18]
Huan-ang Gao, Jiayi Geng, Wenyue Hua, et al. 2025. A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to ASI.arXiv preprint arXiv:2507.21046(2025)
Pith/arXiv arXiv 2025
-
[19]
Siwei Han, Jiaqi Liu, Yaofeng Su, Wenbo Duan, Xinyuan Liu, Cihang Xie, Mohit Bansal, Mingyu Ding, Linjun Zhang, and Huaxiu Yao. 2025. Alignment Tipping Process: How Self-Evolution Pushes LLM Agents Off the Rails.arXiv preprint arXiv:2510.04860(2025)
arXiv 2025
-
[20]
Naimul Haque. 2025. Catastrophic Forgetting in LLMs: A Comparative Analysis Across Language Tasks.arXiv preprint arXiv:2504.01241(2025)
arXiv 2025
-
[21]
Yifeng He, Ethan Wang, Yuyang Rong, Zifei Cheng, and Hao Chen. 2025. Security of ai agents. In2025 IEEE/ACM International Workshop on Responsible AI Engineering (RAIE). IEEE, 45–52
2025
-
[22]
Chia-Yi Hsu et al. 2024. Safe LoRA: The Silver Lining of Reducing Safety Risks when Fine-Tuning Large Language Models. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[23]
Shengran Hu, Cong Lu, and Jeff Clune. 2025. Automated design of agentic systems. InInternational Conference on Learning Representations (ICLR). 21344–21377
2025
-
[24]
Wenyue Hua et al. 2024. TrustAgent: Towards Safe and Trustworthy LLM-based Agents through Agent Constitution. arXiv preprint arXiv:2402.01586(2024)
arXiv 2024
-
[25]
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, Zachary Yahn, Yichang Xu, and Ling Liu. 2025. Safety tax: Safety alignment makes your large reasoning models less reasonable.arXiv preprint arXiv:2503.00555(2025)
arXiv 2025
-
[26]
Yue Huang, Yu Jiang, Wenjie Wang, Haomin Zhuang, Xiaonan Luo, Yuchen Ma, Zhangchen Xu, Zichen Chen, Nuno Moniz, Zinan Lin, Pin-Yu Chen, Nitesh V Chawla, Nouha Dziri, Huan Sun, and Xiangliang Zhang. 2026. Emergent Social Intelligence Risks in Generative Multi-Agent Systems.arXiv preprint arXiv:2603.27771(2026)
Pith/arXiv arXiv 2026
-
[27]
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M Ziegler, Tim Maxwell, Newton Cheng, et al. 2024. Sleeper agents: Training deceptive llms that persist through safety training.arXiv preprint arXiv:2401.05566(2024)
Pith/arXiv arXiv 2024
-
[28]
Harish Karthikeyan, Yue Guo, Leo de Castro, Antigoni Polychroniadou, Udari Madhushani Sehwag, Leo Ardon, Sumitra Ganesh, and Manuela Veloso. 2025. AgentCrypt: Advancing Privacy and (Secure) Computation in AI Agent Collaboration.arXiv preprint arXiv:2512.08104(2025)
Pith/arXiv arXiv 2025
-
[29]
Omar Khattab et al. 2024. DSPy: Compiling Declarative Language Model Calls into State-of-the-Art Pipelines. In International Conference on Learning Representations (ICLR)
2024
-
[30]
Juhee Kim, Xiaoyuan Liu, Zhun Wang, Shi Qiu, Bo Li, Wenbo Guo, and Dawn Song. 2026. The Attack and Defense Landscape of Agentic AI: A Comprehensive Survey.arXiv preprint arXiv:2603.11088(2026)
arXiv 2026
-
[31]
Jiawei Kong, Hao Fang, et al . 2025. Revisiting Backdoor Attacks on LLMs: A Stealthy and Practical Poisoning Framework via Harmless Inputs.arXiv preprint arXiv:2505.17601(2025)
arXiv 2025
-
[32]
Aviral Kumar et al. 2025. Training Language Models to Self-Correct via Reinforcement Learning. InInternational Conference on Learning Representations (ICLR)
2025
-
[33]
Donghyun Lee, Mo Tiwari, and Brando Miranda. 2025. Prompt infection: Llm-to-llm prompt injection within multi-agent systems. InEuropean Symposium on Research in Computer Security (ESORICS). Springer, 511–520
2025
-
[34]
Hui Yi Leong, Yuheng Li, Yuqing Wu, Wenwen Ouyang, Wei Zhu, and Jiechao Gao. 2025. AMAS: Adaptively Determining Communication Topology for LLM-based Multi-Agent Systems.arXiv preprint arXiv:2510.01617(2025)
arXiv 2025
-
[35]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems (NeurIPS)
2020
-
[36]
Jianwei Li and Jung-Eun Kim. 2025. Safety Alignment Can Be Not Superficial With Explicit Safety Signals. In International Conference on Machine Learning (ICML). 56
2025
-
[37]
Jiaqing Li, Zhibo Zhang, Shide Zhou, Yuxi Li, Tianlong Yu, and Kailong Wang. 2026. When Safe Models Merge into Danger: Exploiting Latent Vulnerabilities in LLM Fusion. InInternational Conference on Pattern Recognition (ICPR)
2026
-
[38]
Yige Li et al. 2025. BackdoorLLM: A Comprehensive Benchmark for Backdoor Attacks and Defenses on LLMs. In Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[39]
Zi Liang et al . 2025. Does Low Rank Adaptation Lead to Lower Robustness against Training-Time Attacks?. In International Conference on Machine Learning (ICML)
2025
-
[40]
Jiaye Lin, Yifu Guo, Yuzhen Han, Sen Hu, Ziyi Ni, Licheng Wang, Mingguang Chen, et al . 2025. SE-Agent: Self- Evolution Trajectory Optimization in Multi-Step Reasoning. InAdvances in Neural Information Processing Systems (NeurIPS)
2025
-
[41]
Hung Ming Liu. 2025. AI Mother Tongue: Self-Emergent Communication in MARL via Endogenous Symbol Systems. arXiv preprint arXiv:2507.10566(2025)
arXiv 2025
-
[42]
Xingyu Lyu, Jianfeng He, Ning Wang, Yidan Hu, Tao Li, Danjue Chen, Shixiong Li, and Yimin Chen. 2026. ADAM: A Systematic Data Extraction Attack on Agent Memory via Adaptive Querying.arXiv preprint arXiv:2604.09747(2026)
Pith/arXiv arXiv 2026
-
[43]
Monte MacDiarmid, Benjamin Wright, Jonathan Uesato, Joe Benton, Jon Kutasov, Sara Price, Naia Bouscal, Sam Bowman, Trenton Bricken, Alex Cloud, Carson Denison, Johannes Gasteiger, Ryan Greenblatt, Jan Leike, Jack Lindsey, Vlad Mikulik, Ethan Perez, Alex Rodrigues, Drake Thomas, Albert Webson, Daniel Ziegler, and Evan Hubinger. 2025. Natural Emergent Misal...
arXiv 2025
-
[44]
Geoff McDonald and Jonathan Bar Or. 2025. Whisper Leak: A Side-Channel Attack on Large Language Models.arXiv preprint arXiv:2511.03675(2025)
arXiv 2025
-
[45]
Nous Research. 2026. Hermes Agent: The Self-Improving AI Agent. https://github.com/NousResearch/hermes-agent
2026
-
[46]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. 2025. AlphaEvolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131(2025)
Pith/arXiv arXiv 2025
-
[47]
OpenAI. 2023. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774(2023)
Pith/arXiv arXiv 2023
-
[48]
OpenAI. 2025. GPT-5 System Card. https://openai.com/index/gpt-5-system-card/
2025
-
[49]
OpenClaw Contributors. 2025. OpenClaw: Personal AI Assistant. https://github.com/openclaw/openclaw
2025
-
[50]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al . 2022. Training Language Models to Follow Instructions with Human Feedback. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
-
[51]
Siru Ouyang et al . 2026. ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory. InInternational Conference on Learning Representations (ICLR)
2026
-
[52]
OWASP Foundation. 2025. OWASP Top 10 for Large Language Model Applications. https://owasp.org/www-project- top-10-for-large-language-model-applications/
2025
-
[53]
OWASP GenAI Security Project. 2026. OWASP Top 10 for Agentic Applications. https://genai.owasp.org/resource/ owasp-top-10-for-agentic-applications-for-2026/. Accessed: 2026-06-03
2026
-
[54]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2024. MemGPT: Towards LLMs as Operating Systems. InInternational Conference on Learning Representations (ICLR)
2024
-
[55]
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. 2022. The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models. InInternational Conference on Learning Representations (ICLR)
2022
-
[56]
Richard Yuanzhe Pang, Weizhe Yuan, He He, Kyunghyun Cho, Sainbayar Sukhbaatar, and Jason Weston. 2024. Iterative Reasoning Preference Optimization. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[57]
Nicolas Papernot, Patrick McDaniel, Arunesh Sinha, and Michael P. Wellman. 2018. SoK: Security and Privacy in Machine Learning. InIEEE European Symposium on Security and Privacy (EuroS&P). IEEE, 399–414. doi:10.1109/ EuroSP.2018.00035
arXiv 2018
-
[58]
Cheng Qian et al . 2023. CREATOR: Tool Creation for Disentangling Abstract and Concrete Reasoning of Large Language Models. InFindings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)
2023
-
[59]
Yujia Qin et al. 2024. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. InInternational Conference on Learning Representations (ICLR)
2024
-
[60]
Jiahao Qiu et al. 2025. Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution.arXiv preprint arXiv:2505.20286(2025)
arXiv 2025
-
[61]
Domenic Rosati, Jan Wehner, Kai Williams, Łukasz Bartoszcze, David Atanasov, Robie Gonzales, Subhabrata Majumdar, Carsten Maple, Hassan Sajjad, and Frank Rudzicz. 2024. Representation Noising Effectively Prevents Harmful Fine- Tuning on LLMs.arXiv preprint arXiv:2405.14577(2024)
arXiv 2024
-
[62]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. 2024. Identifying the Risks of LM Agents with an LM-Emulated Sandbox. InInternational Conference on Learning Representations (ICLR). 57
2024
-
[63]
Timo Schick et al. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[64]
Jürgen Schmidhuber. 2007. Gödel Machines: Fully Self-Referential Optimal Universal Self-Improvers. InArtificial General Intelligence. Springer, 199–226. doi:10.1007/978-3-540-68677-4_7
-
[65]
Shuai Shao, Qihan Ren, Chen Qian, et al. 2026. Your Agent May Misevolve: Emergent Risks in Self-evolving LLM Agents. InInternational Conference on Learning Representations (ICLR)
2026
-
[66]
Tianneng Shi, Jingxuan He, Zhun Wang, Hongwei Li, Linyu Wu, Wenbo Guo, and Dawn Song. 2025. Progent: Programmable Privilege Control for LLM Agents.arXiv preprint arXiv:2504.11703(2025)
Pith/arXiv arXiv 2025
-
[67]
Noah Shinn, Federico Cassano, et al . 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. In Advances in Neural Information Processing Systems (NeurIPS)
2023
-
[68]
Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krasheninnikov, and David Krueger. 2022. Defining and Characterizing Reward Hacking. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
-
[69]
Saksham Sahai Srivastava and Haoyu He. 2025. MemoryGraft: Persistent Compromise of LLM Agents via Poisoned Experience Retrieval.arXiv preprint arXiv:2512.16962(2025)
arXiv 2025
-
[70]
Pinar Ozisik, Stephen Casper, and Noam Kolt
Leon Staufer, Kevin Feng, Kevin Wei, Luke Bailey, Yawen Duan, Mick Yang, A. Pinar Ozisik, Stephen Casper, and Noam Kolt. 2026. The 2025 AI Agent Index: Documenting Technical and Safety Features of Deployed Agentic AI Systems.arXiv preprint arXiv:2602.17753(2026)
Pith/arXiv arXiv 2026
-
[71]
Rishub Tamirisa, Bhrugu Bharathi, Long Phan, Andy Zhou, Alice Gatti, Tarun Suresh, Maxwell Lin, Justin Wang, Rowan Luo, Pieter Abbeel, Micah Goldblum, and Dan Hendrycks. 2025. Tamper-Resistant Safeguards for Open-Weight LLMs. InInternational Conference on Learning Representations (ICLR)
2025
-
[72]
Zhengwei Tao et al. 2024. A Survey on Self-Evolution of Large Language Models.arXiv preprint arXiv:2404.14387 (2024)
arXiv 2024
-
[73]
The MITRE Corporation. 2025. MITRE ATLAS: Adversarial Threat Landscape for Artificial-Intelligence Systems. https://atlas.mitre.org/. Accessed: 2026-06-02
2025
-
[74]
Guanzhi Wang et al. 2023. Voyager: An Open-Ended Embodied Agent with Large Language Models.arXiv preprint arXiv:2305.16291(2023)
Pith/arXiv arXiv 2023
-
[75]
Hao Wang, Guozhi Wang, Han Xiao, Yufeng Zhou, Yue Pan, Jichao Wang, Ke Xu, Yafei Wen, Xiaohu Ruan, Xiaoxin Chen, and Honggang Qi. 2026. Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents.arXiv preprint arXiv:2604.10674(2026)
Pith/arXiv arXiv 2026
-
[76]
Haochuan Kevin Wang. 2026. Kill-Chain Canaries: Stage-Level Tracking of Prompt Injection Across Attack Surfaces and Model Safety Tiers.arXiv preprint arXiv:2603.28013(2026)
Pith/arXiv arXiv 2026
-
[77]
Jiye Wang, Shiduo Yang, Ting Qiao, Jiayu Qin, Jianbin Li, Yu Wang, and Yuanhe Zhao. 2025. Ev-Trust: An Evolutionarily Stable Trust Mechanism for Decentralized LLM-Based Multi-Agent Service Economies.arXiv preprint arXiv:2512.16167 (2025)
Pith/arXiv arXiv 2025
-
[78]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhenwei Wei, and Ji-Rong Wen. 2024. A Survey on Large Language Model based Autonomous Agents.Frontiers of Computer Science18, 6 (2024), 186345
2024
-
[79]
Liwen Wang, Wenxuan Wang, Shuai Wang, Zongjie Li, Zhenlan Ji, Zongyi Lyu, Daoyuan Wu, and Shing-Chi Cheung
-
[80]
In USENIX Security Symposium (USENIX Security)
MASLeak: Investigating and Exposing Intellectual Property Leakage Vulnerabilities in Multi-Agent Systems. In USENIX Security Symposium (USENIX Security)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.