Generate with CodeXHug: A Dataset to Enhance Model Cards with Code Usage Patterns
Pith reviewed 2026-06-26 07:35 UTC · model grok-4.3
The pith
CodeXHug supplies 7,325 Hugging Face pre-trained models paired with 20,545 real GitHub Python files to add usage examples to model cards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
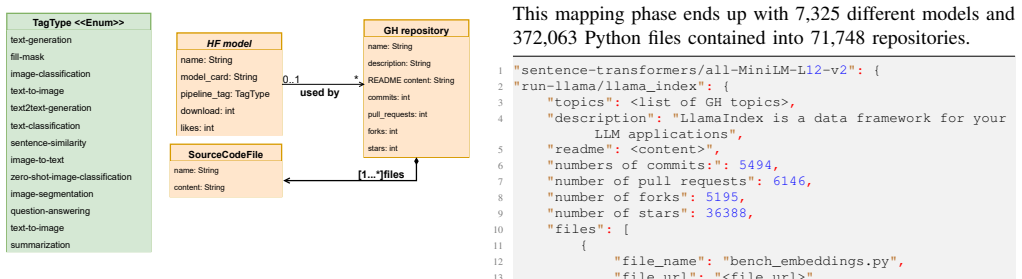
We present CodeXHug, a curated dataset of HuggingFace PTMs exploited in the Github ecosystem and the related code usage patterns, resulting in 7,325 different models and 20,545 Python files.
What carries the argument
CodeXHug dataset, built by filtering Hugging Face models that carry tags and model cards then matching them to GitHub Python files that contain their usage.
If this is right
- Model cards on Hugging Face can be automatically enriched with representative code snippets drawn from real projects.
- Developers gain concrete examples of how to integrate specific pre-trained models instead of relying on documentation alone.
- Statistical and clustering methods applied to the code files can surface recurring usage patterns for any given model.
- The dataset makes it possible to measure which models actually appear in production-style code versus those that remain unused.
Where Pith is reading between the lines
- The same matching technique could be repeated periodically to track how adoption of individual models changes over time.
- Researchers could use the code snippets to train or evaluate tools that recommend or generate usage code for new models.
- If the dataset is kept updated, it could serve as a benchmark for studies that try to predict which models will see widespread use.
Load-bearing premise
Queries on the GitHub platform return genuine uses of the models inside working projects rather than toy examples, mirrors, or incidental mentions.
What would settle it
A random sample of the 20,545 files examined by hand shows that most contain only trivial imports, forks of the Hugging Face repository, or non-functional test code.
Figures



read the original abstract
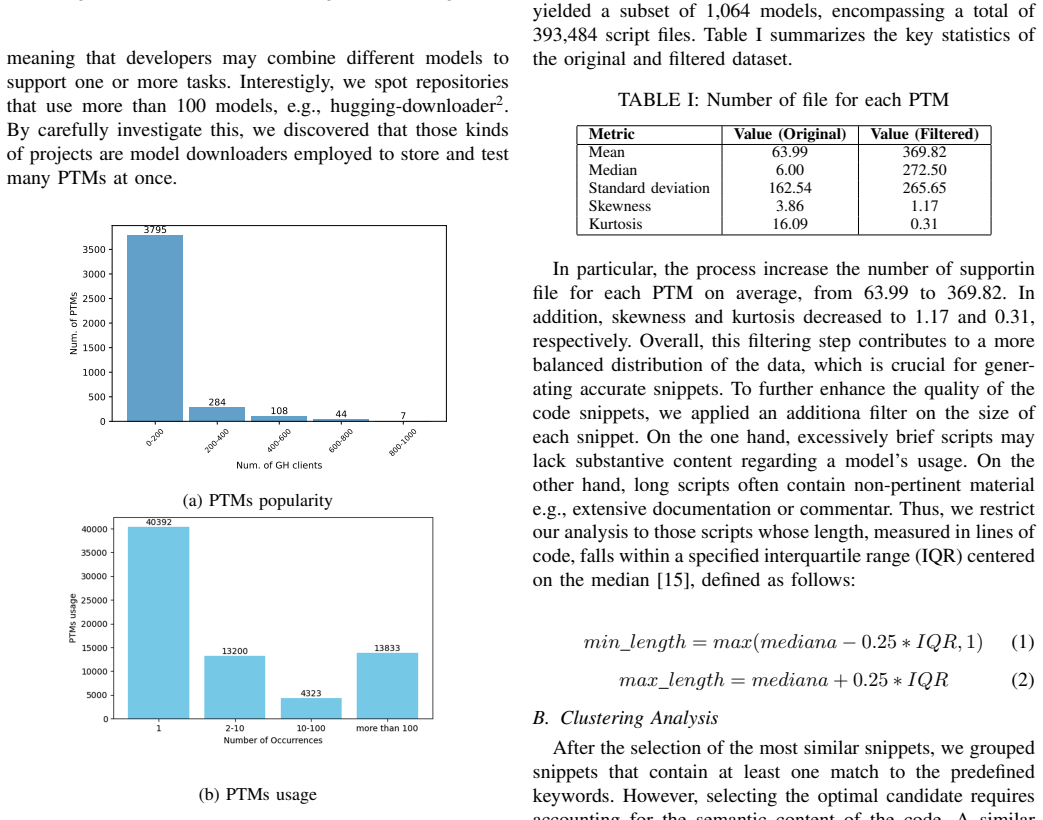
Pre-trained models (PTMs) are becoming increasingly popular in the software engineering community. Their usage is facilitated by model repositories, e.g., HuggingFace, which collect, store, and maintain a wide range of PTMs. However, the actual adoption of these models in real-world projects is still an open question, i.e., many of them are used in toy projects or simply as a mirror for the HF repository. In addition, most of the available model cards and textual documents that contain critical information about their usage do not include explanatory code patterns, thus increasing the difficulty for newcomers. Thus, we see the need for a curated codebase related to PTMs to support developers and practitioners who are interested in using them in their projects. In this paper, we present CodeXHug, a curated dataset of HuggingFace PTMs exploited in the Github ecosystem and the related code usage patterns. Starting from the latest HF dump, we first conduct a data curation to collect PTMs with a tag and a model card. Then, the Github platform has been queried to find actual usages of the identified PTMs, resulting in 7,325 different models and 20,545 Python files. To demonstrate a concrete application of CodeXHug, we propose a usage scenario focused on extracting representative code usage patterns for specific PTMs through a statistical analysis and clustering techniques applied to relevant code snippets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CodeXHug, a curated dataset of 7,325 Hugging Face pre-trained models (PTMs) and their usages across 20,545 Python files on GitHub. It describes a curation pipeline starting from the latest HF dump (selecting models with tags and model cards), followed by GitHub platform queries to identify actual usages, and demonstrates an application via statistical analysis and clustering to extract representative code usage patterns for enhancing model cards.
Significance. If the dataset curation reliably isolates genuine PTM adoptions, CodeXHug would offer a useful empirical resource for studying real-world PTM integration in software projects and for populating model cards with practical code examples, addressing a documented gap in adoption data.
major comments (1)
- [Data Curation and GitHub Querying] The description of the GitHub querying step (abstract and data curation section) provides no details on search methodology, deduplication procedures, exclusion criteria for toy projects/mirrors/incidental mentions, or any validation (e.g., manual sampling, precision estimates, or presence of actual model loading/inference code). This is load-bearing because the headline counts (7,325 models, 20,545 files) and the dataset's claimed utility for representative pattern extraction rest directly on the assumption that the returned files reflect substantive usage; the abstract itself flags these contamination risks as open issues.
minor comments (2)
- [Usage Scenario] The usage scenario section describes the application of 'statistical analysis and clustering techniques' at a high level only; adding concrete details on snippet extraction, feature representation, clustering algorithm, and evaluation of the resulting patterns would improve clarity without altering the central contribution.
- [Abstract] The abstract refers to 'the latest HF dump' without a date or version identifier; including this information would support reproducibility of the initial model selection step.
Simulated Author's Rebuttal
We thank the referee for the thorough review and the recommendation of major revision. The concern about insufficient detail in the GitHub querying process is well-taken and directly impacts the interpretability of the dataset. We address this point below and commit to a substantive revision of the data curation section.
read point-by-point responses
-
Referee: The description of the GitHub querying step (abstract and data curation section) provides no details on search methodology, deduplication procedures, exclusion criteria for toy projects/mirrors/incidental mentions, or any validation (e.g., manual sampling, precision estimates, or presence of actual model loading/inference code). This is load-bearing because the headline counts (7,325 models, 20,545 files) and the dataset's claimed utility for representative pattern extraction rest directly on the assumption that the returned files reflect substantive usage; the abstract itself flags these contamination risks as open issues.
Authors: We agree that the current manuscript provides insufficient methodological transparency on the GitHub querying step. In the revised version we will expand the Data Curation section with a dedicated subsection that explicitly describes: (i) the search methodology, including the GitHub search API parameters and keywords employed to locate files referencing the selected PTM names; (ii) deduplication procedures applied at both repository and file levels; (iii) exclusion criteria used to filter toy projects, mirrors, and incidental mentions (e.g., requiring evidence of model instantiation or inference code); and (iv) any validation activities performed, such as sampling or checks for actual model-loading statements. Where quantitative validation (precision estimates or large-scale manual review) was not conducted, the revised text will state this limitation explicitly and retain the abstract's existing caveats about contamination risks. These additions will allow readers to better assess the dataset's representativeness without altering the reported counts or core claims. revision: yes
Circularity Check
No circularity: dataset curation paper with no derivations or self-referential predictions
full rationale
This is a dataset construction paper. It starts from an external HF dump, applies curation filters, queries GitHub for usages, reports the resulting counts (7,325 models, 20,545 files), and demonstrates downstream statistical/clustering analysis on the collected snippets. No equations, fitted parameters, uniqueness theorems, or predictions are defined in terms of themselves or prior self-citations. The load-bearing steps are external data retrieval and standard analysis techniques, which are independent of the paper's own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Models with tags and model cards from the latest HF dump form a suitable base set for identifying real usages
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Software Engineering and Methodology33(8), 1–79 (2024)
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang, “Large language models for software engineering: A systematic literature review,”ACM Trans. Softw. Eng. Methodol., Sep. 2024, just Accepted. [Online]. Available: https://doi-org.univaq.idm.oclc.org/10.1145/3695988
-
[2]
Pre-trained models: Past, present and future,
X. Han, Z. Zhang, N. Ding, Y . Gu, X. Liuet al., “Pre-trained models: Past, present and future,”AI Open, vol. 2, pp. 225–250, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S2666651021000231
2021
-
[3]
Using pre-trained models to boost code review automation,
R. Tufano, S. Masiero, A. Mastropaolo, L. Pascarella, D. Poshyvanyk et al., “Using pre-trained models to boost code review automation,” inProceedings of the 44th International Conference on Software Engineering, ser. ICSE ’22. New York, NY , USA: Association for Computing Machinery, Jul. 2022, pp. 2291–2302. [Online]. Available: https://dl.acm.org/doi/10....
-
[4]
Z. Ding, H. Li, W. Shang, and T.-H. P. Chen, “Can pre-trained code embeddings improve model performance? Revisiting the use of code embeddings in software engineering tasks,”Empirical Software Engineering, vol. 27, no. 3, p. 63, Mar. 2022. [Online]. Available: https://doi.org/10.1007/s10664-022-10118-5
-
[5]
J. Zhang, T. Mytkowicz, M. Kaufman, R. Piskac, and S. K. Lahiri, “Using pre-trained language models to resolve textual and semantic merge conflicts (experience paper),” inProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2022. New York, NY , USA: Association for Computing Machinery, Jul. 2022, pp. 77–...
-
[6]
Model cards for model reporting,
M. Mitchell, S. Wu, A. Zaldivar, P. Barnes, L. Vassermanet al., “Model cards for model reporting,” inProceedings of the Conference on Fairness, Accountability, and Transparency, ser. FAT *’19. New York, NY , USA: Association for Computing Machinery, 2019, p. 220–229. [Online]. Available: https://doi-org.univaq.idm.oclc.org/10. 1145/3287560.3287596
arXiv 2019
-
[7]
Analyzing the Evolution and Maintenance of ML Models on Hugging Face,
J. Casta ˜no, S. Mart ´ınez-Fern´andez, X. Franch, and J. Bogner, “Analyzing the Evolution and Maintenance of ML Models on Hugging Face,” Nov. 2023, arXiv:2311.13380 [cs]. [Online]. Available: http://arxiv.org/abs/2311.13380
arXiv 2023
-
[8]
Vulnerabilities in AI code generators: Exploring targeted data poisoning attacks,
F. Pepe, V . Nardone, A. Mastropaolo, G. Bavota, G. Canfora, and M. Di Penta, “How do hugging face models document datasets, bias, and licenses? an empirical study,” inProceedings of the 32nd IEEE/ACM International Conference on Program Comprehension, ser. ICPC ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 370–381. [Online]. Avail...
-
[9]
HFCommunity: A Tool to Analyze the Hugging Face Hub Community,
A. Ait, J. L. C. Izquierdo, and J. Cabot, “HFCommunity: A Tool to Analyze the Hugging Face Hub Community,” in2023 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Mar. 2023, pp. 728–732, iSSN: 2640-7574. [Online]. Available: https://ieeexplore.ieee.org/document/10123660
arXiv 2023
-
[10]
Pygithub documentation,
“Pygithub documentation,” https://pygithub.readthedocs.io/en/stable/, accessed: 2024-03-11
2024
-
[11]
Cofexhug: A curated dataset of huggingface pre- trained models exploited in the github ecosystem,
C. Di Sipio, J. Di Rocco, D. Di Ruscio, and S. Palombo, “Cofexhug: A curated dataset of huggingface pre- trained models exploited in the github ecosystem,” Dec. 2024. [Online]. Available: https://doi.org/10.5281/zenodo.14267550
-
[12]
Discrepancies among pre-trained deep neural networks: a new threat to model zoo reliability,
D. Montes, P. Peerapatanapokin, J. Schultz, C. Guo, W. Jianget al., “Discrepancies among pre-trained deep neural networks: a new threat to model zoo reliability,” inProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ser. ESEC/FSE 2022. New York, NY , USA: Association for Com...
-
[13]
Mysql connector/python,
“Mysql connector/python,” https://pypi.org/project/ mysql-connector-python/, accessed: 2024-03-11
2024
-
[14]
Mongodb,
“Mongodb,” https://www.mongodb.com/, accessed: 2024-03-11
2024
-
[15]
Detection of outliers using interquartile range technique from intrusion dataset,
H. Vinutha, B. Poornima, and B. Sagar, “Detection of outliers using interquartile range technique from intrusion dataset,” inInformation and decision sciences: Proceedings of the 6th international conference on ficta. Springer, 2018, pp. 511–518
2018
-
[16]
Mapo: Mining and recommending api usage patterns,
H. Zhong, T. Xie, L. Zhang, J. Pei, and H. Mei, “Mapo: Mining and recommending api usage patterns,” inECOOP 2009–Object-Oriented Programming: 23rd European Conference, Genoa, Italy, July 6-10, 2009. Proceedings 23. Springer, 2009, pp. 318–343
2009
-
[17]
Scikit-learn: Machine learning in Python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vander- plas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duch- esnay, “Scikit-learn: Machine learning in Python,”Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011
2011
-
[18]
Codebert: A pre-trained model for programming and natural languages,
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, and M. Zhou, “Codebert: A pre-trained model for programming and natural languages,” 2020. [Online]. Available: https://arxiv.org/abs/2002.08155
Pith/arXiv arXiv 2020
-
[19]
Parameter-free Probabilistic API Mining Across GitHub,
J. Fowkes and C. Sutton, “Parameter-free Probabilistic API Mining Across GitHub,” in24th ACM SIGSOFT International Symposium on Foundations of Software Engineering. New York: ACM, 2016, pp. 254–265
2016
-
[20]
FOCUS: A Recommender System for Mining API Function Calls and Usage Patterns,
P. T. Nguyen, J. Di Rocco, D. Di Ruscioet al., “FOCUS: A Recommender System for Mining API Function Calls and Usage Patterns,” inProceedings of the 41st International Conference on Software Engineering, ser. ICSE ’19. Piscataway, NJ, USA: IEEE Press, 2019, pp. 1050–1060. [Online]. Available: https: //doi.org/10.1109/ICSE.2019.00109
-
[21]
Mining succinct and high-coverage api usage patterns from source code,
J. Wang, Y . Dang, H. Zhang, K. Chen, T. Xie, and D. Zhang, “Mining succinct and high-coverage api usage patterns from source code,” in 2013 10th Working Conference on Mining Software Repositories (MSR), 2013, pp. 319–328
2013
-
[23]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandeyet al., “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[24]
On the diffuseness and the impact on maintainability of code smells: a large scale empirical investigation,
F. Palomba, G. Bavota, M. Di Penta, F. Fasano, R. Oliveto, and A. De Lucia, “On the diffuseness and the impact on maintainability of code smells: a large scale empirical investigation,” inProceedings of the 40th International Conference on Software Engineering, ser. ICSE ’18. New York, NY , USA: Association for Computing Machinery, 2018, p
2018
-
[25]
Available: https://doi.org/10.1145/3180155.3182532
[Online]. Available: https://doi.org/10.1145/3180155.3182532
-
[26]
Technical debt in ai-enabled systems: On the prevalence, severity, impact, and management strategies for code and architecture,
G. Recupito, F. Pecorelli, G. Catolino, V . Lenarduzzi, D. Taibi, D. Di Nucci, and F. Palomba, “Technical debt in ai-enabled systems: On the prevalence, severity, impact, and management strategies for code and architecture,”Journal of Systems and Software, vol. 216, p. 112151, 2024. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S...
2024
-
[27]
An exploratory study of the impact of antipatterns on class change- and fault-proneness,
F. Khomh, M. D. Penta, Y .-G. Gu ´eh´eneuc, and G. Antoniol, “An exploratory study of the impact of antipatterns on class change- and fault-proneness,”Empirical Software Engineering, vol. 17, no. 3, pp. 243–275, Jun. 2012. [Online]. Available: https://doi.org/10.1007/ s10664-011-9171-y
2012
-
[28]
L. Gong, J. Zhang, M. Wei, H. Zhang, and Z. Huang, “What Is the Intended Usage Context of This Model? An Exploratory Study of Pre- Trained Models on Various Model Repositories,”ACM Transactions on Software Engineering and Methodology, vol. 32, no. 3, pp. 69:1–69:57, May 2023. [Online]. Available: https://dl.acm.org/doi/10.1145/3569934
-
[29]
Documenting ethical considerations in open source ai models,
H. Gao, M. Zahedi, C. Treude, S. Rosenstock, and M. Cheong, “Documenting ethical considerations in open source ai models,” in Proceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, ser. ESEM ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 177–188. [Online]. Available: https://doi....
-
[30]
C. Di Sipio, R. Rubei, J. Di Rocco, D. Di Ruscio, and P. T. Nguyen, “Automated categorization of pre-trained models in software engineering: A case study with a hugging face dataset,” inProceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering, ser. EASE ’24. New York, NY , USA: Association for Computing Machine...
-
[31]
FACER: An API usage-based code-example recommender for opportunistic reuse,
S. Abid, S. Shamail, H. A. Basit, and S. Nadi, “FACER: An API usage-based code-example recommender for opportunistic reuse,” Empirical Software Engineering, vol. 26, no. 6, p. 110, Aug. 2021. [Online]. Available: https://doi.org/10.1007/s10664-021-10000-w
-
[32]
Exploring API Embedding for API Usages and Applications,
T. D. Nguyen, A. T. Nguyen, H. D. Phan, and T. N. Nguyen, “Exploring API Embedding for API Usages and Applications,” in2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE). Buenos Aires: IEEE, May 2017, pp. 438–449. [Online]. Available: http://ieeexplore.ieee.org/document/7985683/
arXiv 2017
-
[33]
Specializing Neural Networks for Cryptographic Code Completion Applications,
Y . Xiao, W. Song, J. Qi, B. Viswanath, P. McDaniel, and D. Yao, “Specializing Neural Networks for Cryptographic Code Completion Applications,”IEEE Transactions on Software Engineering, vol. 49, no. 6, pp. 3524–3535, Jun. 2023, conference Name: IEEE Transactions on Software Engineering. [Online]. Available: https://ieeexplore.ieee.org/document/10097631
arXiv 2023
-
[34]
Jigsaw: large language models meet program synthesis,
N. Jain, S. Vaidyanath, A. Iyer, N. Natarajan, S. Parthasarathy, S. Rajamani, and R. Sharma, “Jigsaw: large language models meet program synthesis,” inProceedings of the 44th International Conference on Software Engineering, ser. ICSE ’22. New York, NY , USA: Association for Computing Machinery, Jul. 2022, pp. 1219–1231. [Online]. Available: https://dl.ac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.