An Automated Framework for Input Alphabet Construction in Stateful Protocol Implementation Learning
Pith reviewed 2026-06-26 07:21 UTC · model grok-4.3
The pith
Large language models can automatically construct input alphabets for state machine learning of stateful protocols.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an automated framework employing large language models to parse protocol message layouts and generate candidate input symbols through structured mutation rules can break the bottleneck of handcrafted alphabets in stateful protocol learning, while a mini-batch incremental learning strategy controls the overhead, ultimately reproducing existing security vulnerabilities and identifying novel semantic bugs in practical implementations.
What carries the argument
LLM-based generation of input symbols using structured mutation rules on parsed layouts, which automatically covers valid and invalid message spaces.
If this is right
- State machine learning can now include anomalous non-conformant messages in its exploration.
- Manual protocol expertise is no longer required for defining input alphabets.
- Overhead from growing alphabets is mitigated through reuse of existing learned automata.
- New semantic bugs in protocol stacks can be discovered and reported for patching.
Where Pith is reading between the lines
- This method could extend to learning models for other stateful systems beyond network protocols.
- Improvements in language model accuracy might further increase the completeness of the generated alphabets.
- Integration with existing fuzzing tools could enhance bug detection rates in security testing workflows.
Load-bearing premise
Large language models can reliably parse protocol message layouts and produce effective candidate input symbols following structured mutation rules that cover valid and invalid spaces.
What would settle it
A test showing that the LLM-generated alphabets fail to reproduce any of the known security vulnerabilities in the evaluated protocol stacks would disprove the effectiveness claim.
Figures

read the original abstract
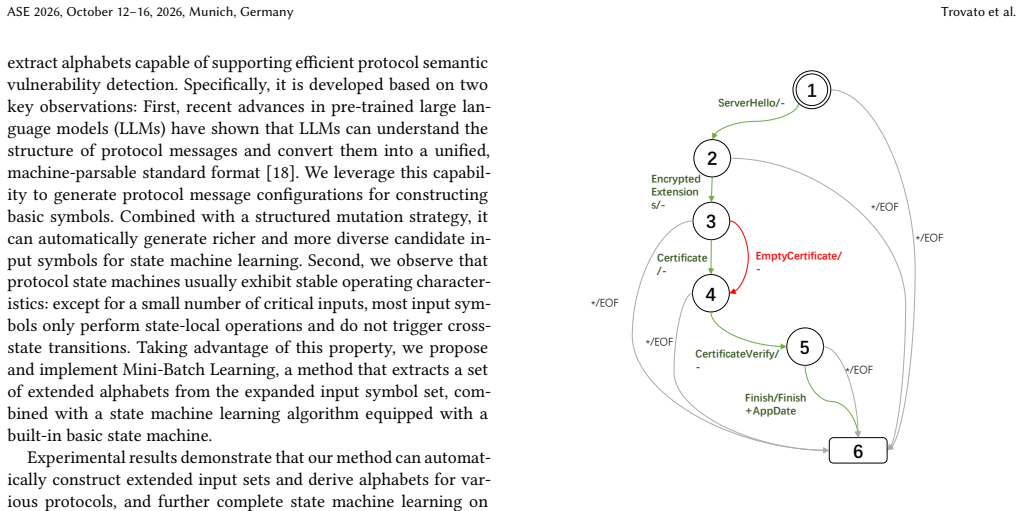
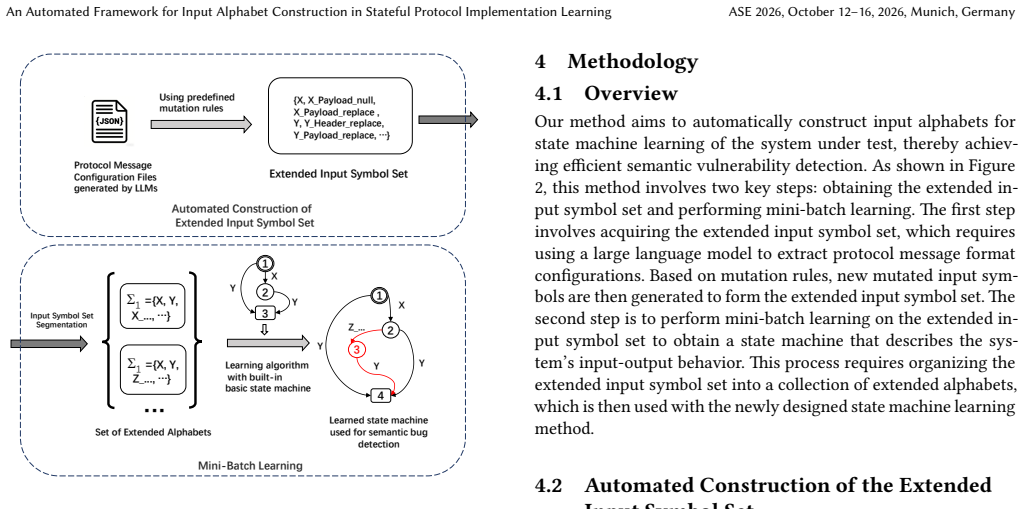
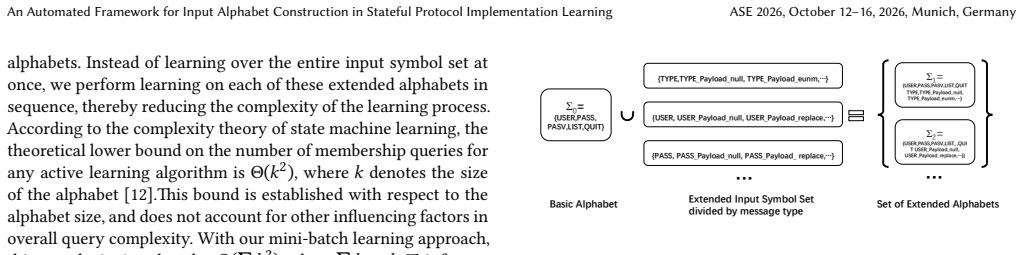
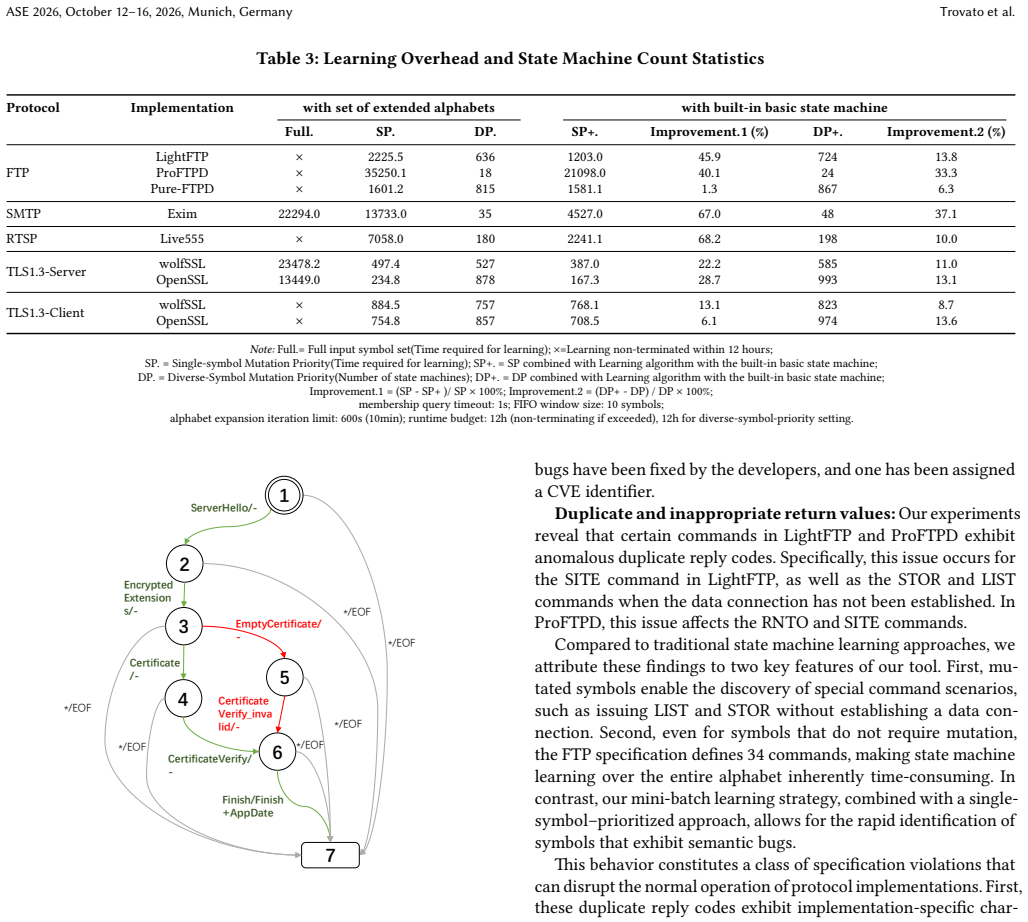
As a prevalent analytical technique for stateful protocol implementations, state machine learning suffers from a core bottleneck stemming from handcrafted input alphabets. Manual alphabet definition inherently limits the completeness of input exploration, making it difficult to capture anomalous non-conformant messages and consequently missing latent semantic defects. In this paper, we target automatic input alphabet generation to break the above limitation for state machine learning. We adopt large language models to parse protocol message layouts and produce candidate input symbols following structured mutation rules, which automatically covers valid and invalid message spaces and eliminates reliance on manual protocol expertise. Considering the rising overhead brought by continuously growing alphabets, we introduce a mini-batch incremental learning strategy to reuse existing learned automata when incorporating new alphabet entries. Comprehensive experiments on practical protocol stacks indicate our approach can reproduce existing security vulnerabilities and identify novel semantic bugs. A subset of these newly discovered issues has been confirmed and patched by developers, proving the practicability and effectiveness of our proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an automated framework for input alphabet construction in state machine learning of stateful protocol implementations. It uses large language models to parse protocol message layouts and generate candidate symbols via structured mutation rules that aim to cover both valid and invalid message spaces, thereby removing the need for manual protocol expertise. To manage the overhead of growing alphabets, a mini-batch incremental learning strategy reuses previously learned automata. Experiments on practical protocol stacks are reported to reproduce known security vulnerabilities and discover novel semantic bugs, with some confirmed and patched by developers.
Significance. If the LLM-based alphabet generation can be shown to produce sufficiently complete and correct input sets without hidden manual intervention, the work would address a key practical bottleneck in protocol state machine learning, enabling broader automated exploration of implementation behaviors and potentially improving detection of semantic defects in deployed systems. The incremental learning component is a pragmatic contribution to scalability. The reported bug findings, if reproducible and attributable to the automation, would strengthen the case for the method's effectiveness in real-world security analysis.
major comments (2)
- [Abstract] Abstract: The central claim that the approach 'automatically covers valid and invalid message spaces and eliminates reliance on manual protocol expertise' is load-bearing for the contribution, yet the manuscript provides no quantitative validation of the LLM outputs (e.g., coverage statistics for valid formats, comparison of generated vs. expert alphabets on the same stacks, or error rates for nonsensical/malformed symbols). Without these metrics, it is unclear whether the reported bug discoveries result from the automated method or from unstated curation of LLM results.
- [Experiments] Experiments section: The abstract states that 'comprehensive experiments... indicate our approach can reproduce existing security vulnerabilities and identify novel semantic bugs,' but reports no details on experimental controls, statistical significance of findings, or ablation studies isolating the effect of the LLM-generated alphabet versus the incremental learner. This undermines attribution of the results to the proposed automation.
minor comments (1)
- [Method] The description of the structured mutation rules would benefit from an explicit enumeration or pseudocode example to clarify how valid and invalid spaces are targeted.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validation and experimental rigor. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the approach 'automatically covers valid and invalid message spaces and eliminates reliance on manual protocol expertise' is load-bearing for the contribution, yet the manuscript provides no quantitative validation of the LLM outputs (e.g., coverage statistics for valid formats, comparison of generated vs. expert alphabets on the same stacks, or error rates for nonsensical/malformed symbols). Without these metrics, it is unclear whether the reported bug discoveries result from the automated method or from unstated curation of LLM results.
Authors: We agree that direct quantitative metrics on LLM output quality would strengthen the central claim. The manuscript grounds the claim in the use of structured mutation rules applied to LLM-parsed layouts, which are designed to systematically generate both valid and invalid symbols without manual protocol expertise. Bug discoveries serve as an indirect demonstration of effectiveness, with several issues confirmed and patched by developers. No unstated curation occurred. In revision we will add coverage statistics, a comparison against expert alphabets for at least one protocol, and error-rate reporting on generated symbols. revision: yes
-
Referee: [Experiments] Experiments section: The abstract states that 'comprehensive experiments... indicate our approach can reproduce existing security vulnerabilities and identify novel semantic bugs,' but reports no details on experimental controls, statistical significance of findings, or ablation studies isolating the effect of the LLM-generated alphabet versus the incremental learner. This undermines attribution of the results to the proposed automation.
Authors: We acknowledge that the experiments section lacks explicit controls, statistical tests, and ablations separating the LLM alphabet component from the incremental learner. The reported results are produced by the combined framework on real protocol stacks. In the revised version we will expand the experiments section with a detailed description of the experimental setup, ablation studies (full method vs. manual alphabets and vs. non-incremental learning), and any applicable statistical measures to better attribute outcomes to the automation. revision: yes
Circularity Check
No circularity: empirical method with no derivations or self-referential fits
full rationale
The paper presents an engineering framework that uses LLMs to generate protocol input alphabets, followed by incremental learning experiments on real stacks. The provided abstract and description contain no equations, no fitted parameters renamed as predictions, no uniqueness theorems, and no self-citation chains that bear the central claim. Claims rest on experimental reproduction of bugs rather than any closed derivation that reduces to its own inputs by construction. This is the expected non-finding for an empirical contribution without mathematical self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Max Ammann, Lucca Hirschi, and Steve Kremer. 2024. DY fuzzing: formal Dolev- Yao models meet cryptographic protocol fuzz testing. In 2024 IEEE Symposium on Security and Privacy (SP) . IEEE, 1481–1499
2024
-
[2]
Dana Angluin. 1987. Learning regular sets from queries and counterexamples. Information and computation 75, 2 (1987), 87–106
1987
-
[3]
Linard Arquint, Malte Schwerhoff, Vaibhav Mehta, and Peter Müller. 2023. A generic methodology for the modular verification of security protocol imple- mentations. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security. 1377–1391
2023
-
[4]
Linard Arquint, Felix A Wolf, Joseph Lallemand, Ralf Sasse, Christoph Sprenger, Sven N Wiesner, David Basin, and Peter Müller. 2023. Sound verification of security protocols: From design to interoperable implementations. In 2023 IEEE Symposium on Security and Privacy (SP) . IEEE, 1077–1093
2023
-
[5]
Cornelius Aschermann, Tommaso Frassetto, Thorsten Holz, Patrick Jauernig, Ahmad-Reza Sadeghi, and Daniel Teuchert. 2019. NAUTILUS: Fishing for deep bugs with grammars.. In NDSS, Vol. 19. 337
2019
-
[6]
Fabian Bäumer, Marcel Maehren, Marcus Brinkmann, and Jörg Schwenk. 2025. Finding ssh strict key exchange violations by state learning. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security . 246– 260
2025
-
[7]
Benjamin Beurdouche, Karthikeyan Bhargavan, Antoine Delignat-Lavaud, Cé- dric Fournet, Markulf Kohlweiss, Alfredo Pironti, Pierre-Yves Strub, and Jean Karim Zinzindohoue. 2017. A messy state of the union: Taming the com- posite state machines of TLS. Commun. ACM 60, 2 (2017), 99–107
2017
-
[8]
Joeri De Ruiter and Erik Poll. 2015. Protocol state fuzzing of {TLS} implementa- tions. In 24th USENIX Security Symposium (USENIX Security 15) . 193–206
2015
-
[9]
Tiago Ferreira, Harrison Brewton, Loris D’Antoni, and Alexandra Silva. 2021. Prognosis: closed-box analysis of network protocol implementations. In Proceed- ings of the 2021 ACM SIGCOMM 2021 Conference . 762–774
2021
-
[10]
Paul Fiterau-Brostean, Bengt Jonsson, Robert Merget, Joeri De Ruiter, Konstanti- nos Sagonas, and Juraj Somorovsky. 2020. Analysis of {DTLS} implementations using protocol state fuzzing. In 29th USENIX Security Symposium (USENIX Secu- rity 20). 2523–2540
2020
-
[11]
Paul Fiterau-Brostean, Bengt Jonsson, Konstantinos Sagonas, and Fredrik Tåquist. 2023. Automata-Based Automated Detection of State Machine Bugs in Protocol Implementations.. In NDSS
2023
-
[12]
Falk M Howar. 2012. Active learning of interface programs. (2012)
2012
-
[13]
Malte Isberner, Falk Howar, and Bernhard Steffen. 2014. The TTT algorithm: a redundancy-free approach to active automata learning. In International Confer- ence on Runtime Verification. Springer, 307–322
2014
-
[14]
Malte Isberner, Falk Howar, and Bernhard Steffen. 2015. The open-source learn- lib: a framework for active automata learning. In International Conference on Computer Aided Verification. Springer, 487–495
2015
-
[15]
Kunpeng Jian, Yanyan Zou, Yeting Li, Jialun Cao, Menghao Li, Jian Sun, Jingyi Shi, and Wei Huo. 2024. Fuzzing for Stateful Protocol Implementations: Are We There Yet?. In International Symposium on Theoretical Aspects of Software Engineering. Springer, 186–204
2024
-
[16]
Marcel Maehren, Nurullah Erinola, Robert Merget, Jörg Schwenk, and Juraj So- morovsky. 2025. Towards {Internet-Based} State Learning of {TLS} State Ma- chines. In 34th USENIX Security Symposium (USENIX Security 25) . 7097–7116
2025
-
[17]
Chris McMahon Stone, Sam L Thomas, Mathy Vanhoef, James Henderson, Nico- las Bailluet, and Tom Chothia. 2022. The closer you look, the more you learn: A grey-box approach to protocol state machine learning. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security. 2265–2278
2022
-
[18]
Ruijie Meng, Martin Mirchev, Marcel Böhme, and Abhik Roychoudhury. 2024. Large Language Model guided Protocol Fuzzing.. In NDSS
2024
-
[19]
Roberto Natella and Van-Thuan Pham. 2021. Profuzzbench: A benchmark for stateful protocol fuzzing. In Proceedings of the 30th ACM SIGSOFT international symposium on software testing and analysis . 662–665
2021
-
[20]
Van-Thuan Pham, Marcel Böhme, and Abhik Roychoudhury. 2020. Aflnet: A greybox fuzzer for network protocols. In 2020 IEEE 13th international conference on software testing, validation and verification (ICST) . IEEE, 460–465
2020
-
[21]
Shisong Qin, Fan Hu, Zheyu Ma, Bodong Zhao, Tingting Yin, and Chao Zhang
-
[22]
ACM Transactions on Software Engineering and Methodology 32, 6 (2023), 1–26
Nsfuzz: Towards efficient and state-aware network service fuzzing. ACM Transactions on Software Engineering and Methodology 32, 6 (2023), 1–26
2023
-
[23]
Aina Toky Rasoamanana, Olivier Levillain, and Hervé Debar. 2022. Towards a systematic and automatic use of state machine inference to uncover security flaws and fingerprint TLS stacks. InEuropean symposium on research in computer security. Springer, 637–657
2022
-
[24]
Eric Rescorla. 2018. The Transport Layer Security (TLS) Protocol Version 1.3. RFC 8446. https://www.rfc-editor.org/rfc/rfc8446
2018
-
[25]
Sergej Schumilo, Cornelius Aschermann, Andrea Jemmett, Ali Abbasi, and Thorsten Holz. 2022. Nyx-net: network fuzzing with incremental snapshots. In Proceedings of the seventeenth european conference on computer systems. 166–180
2022
-
[26]
secdev, Guillaume Potter, and the Scapy Contributors. 2026. Scapy. https:// github.com/secdev/scapy
2026
-
[27]
Konstantin Serebryany, Derek Bruening, Alexander Potapenko, and Dmitriy Vyukov. 2012. {AddressSanitizer}: A fast address sanity checker. In 2012 USENIX annual technical conference (USENIX ATC 12) . 309–318
2012
-
[28]
Arthur Tran Van, Olivier Levillain, and Herve Debar. 2024. Mealy verifier: An au- tomated, exhaustive, and explainable methodology for analyzing state machines in protocol implementations. In Proceedings of the 19th International Conference on A vailability, Reliability and Security. 1–10
2024
-
[29]
Jules van Thoor, Joeri de Ruiter, and Erik Poll. 2018. Learning state machines of TLS 1.3 implementations. Bachelor thesis. Radboud University (2018), 96
2018
-
[30]
Junjie Wang, Bihuan Chen, Lei Wei, and Yang Liu. 2019. Superion: Grammar- aware greybox fuzzing. In 2019 IEEE/ACM 41st International Conference on Soft- ware Engineering (ICSE). IEEE, 724–735
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.