SPIRAL: Learning to Search and Aggregate
Pith reviewed 2026-06-26 08:27 UTC · model grok-4.3
The pith
SPIRAL trains language models end-to-end to generate parallel reasoning traces and then aggregate them into a final answer using combined set and standard reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
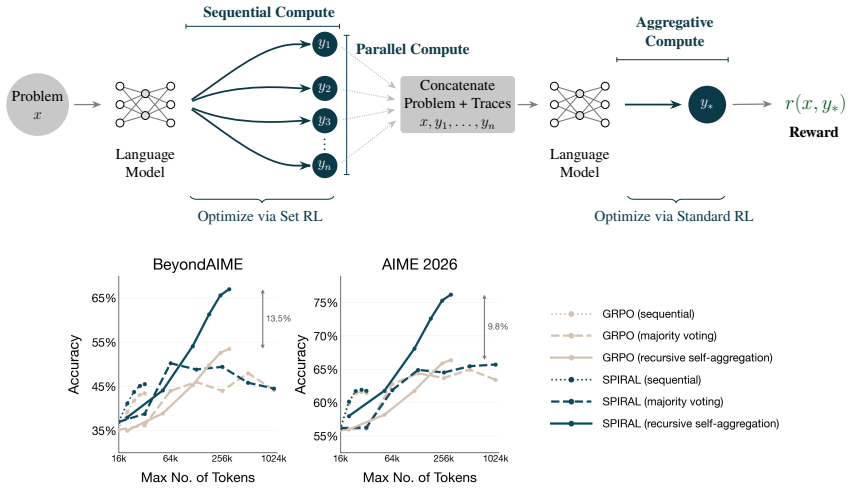
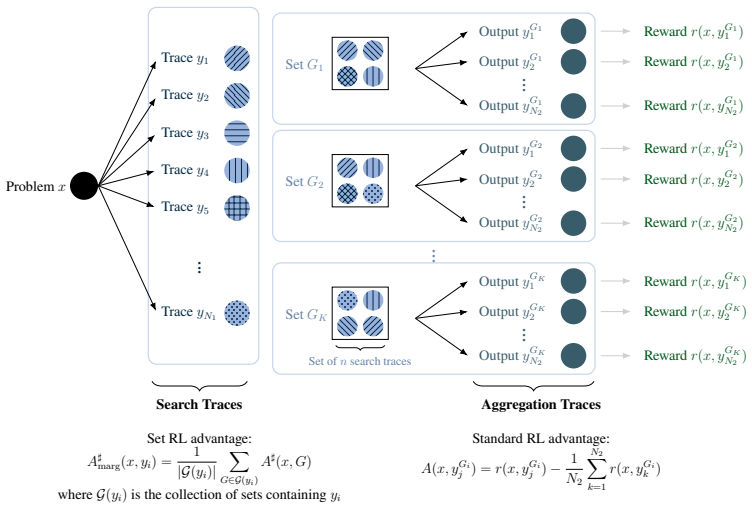
SPIRAL optimizes a language model across three inference primitives in one pipeline: it samples multiple independent sequential reasoning traces in parallel, then produces a final aggregation trace conditioned on that set, with the entire system trained end-to-end so that set reinforcement learning improves the collective utility of the traces and standard reinforcement learning improves the quality of the aggregation.
What carries the argument
The end-to-end combination of set reinforcement learning, which rewards traces for their joint usefulness to an aggregator, and standard reinforcement learning, which rewards the aggregator for producing better final responses.
If this is right
- Scaling the number of parallel traces and the aggregation depth produces larger performance gains than scaling any single primitive alone.
- The model learns to produce traces that are useful as a group rather than individually optimal.
- End-to-end training removes the need for separate post-training stages for search versus aggregation.
- Performance improvements hold when all three compute primitives are scaled simultaneously on reasoning benchmarks.
Where Pith is reading between the lines
- The same joint training pattern could be applied to other multi-trace methods such as tree-of-thought or Monte Carlo tree search scaffolds.
- Models trained this way might generalize the learned search-and-aggregate behavior to tasks outside the original reasoning benchmarks.
- If trace quality collapses under larger set sizes, additional regularization on trace diversity would become necessary.
Load-bearing premise
That reinforcement learning signals alone will cause the model to generate a set of traces whose diversity and quality support effective aggregation without any separate mechanisms to enforce those properties.
What would settle it
A controlled comparison in which models trained with SPIRAL show no gain, or a loss, in final accuracy when the number of parallel traces is increased while holding total inference tokens fixed, relative to models trained only on aggregation.
Figures
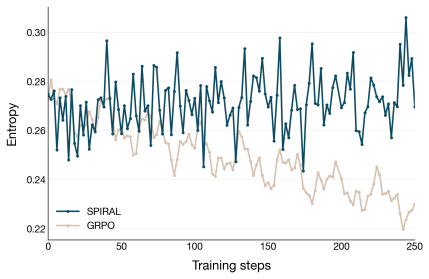
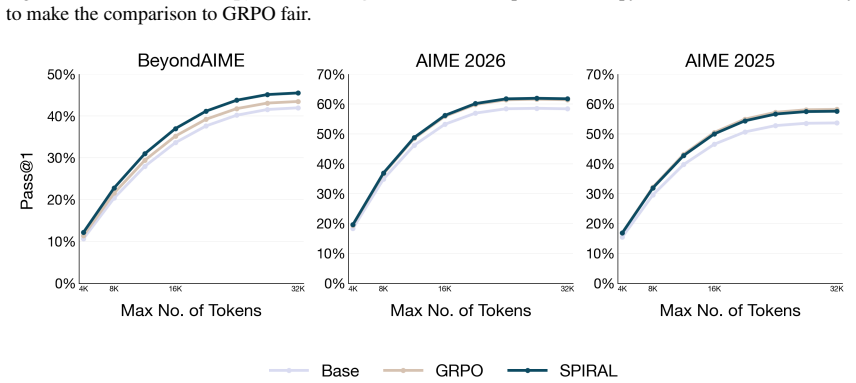
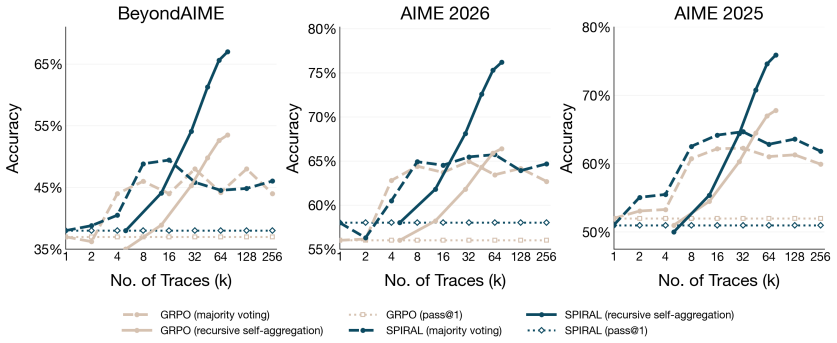
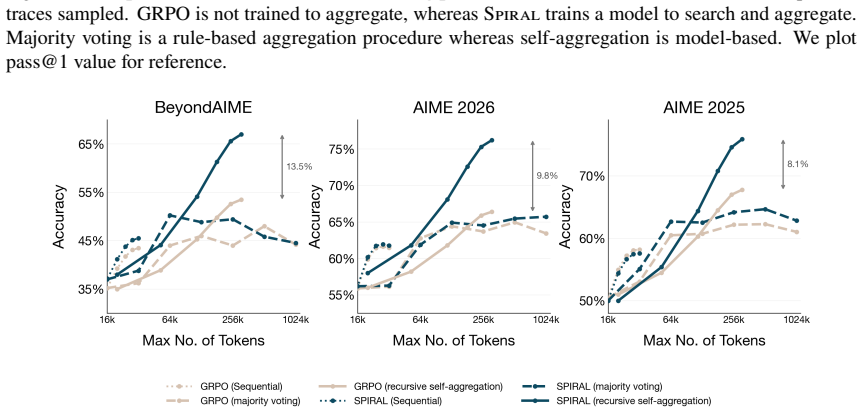
read the original abstract
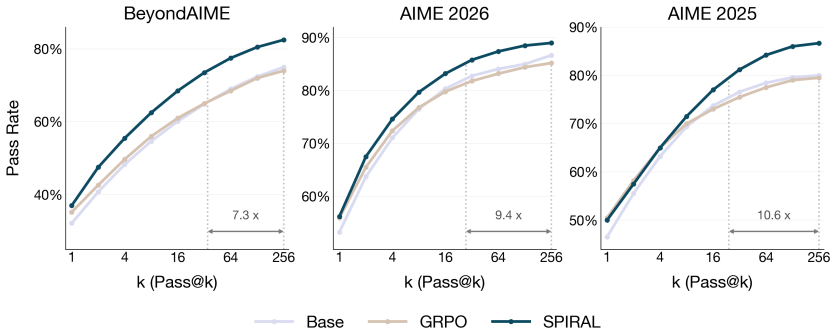
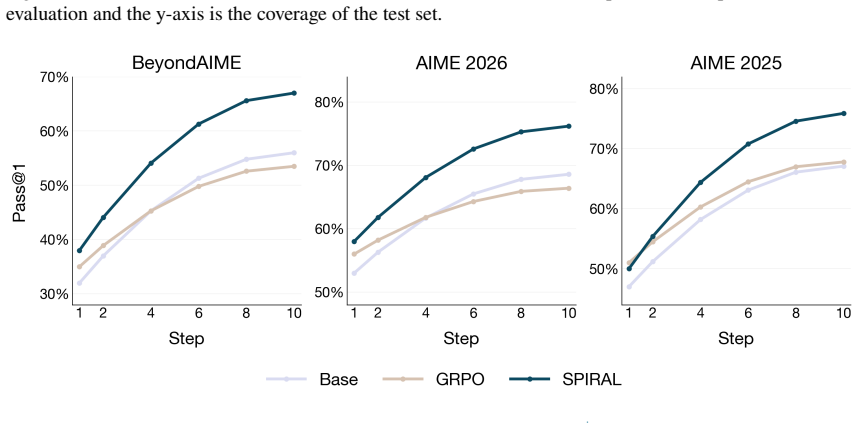
Language model reasoning can be substantially improved at test time via scaffolds that scale inference compute across different primitives -- sequential reasoning within a trace, independently sampled parallel traces, and aggregation of multiple reasoning traces into a final response. During post-training, however, language models are optimized only for sequential reasoning within a single trace. We introduce Sequential-Parallel-Aggregative Reinforcement Learning (SPIRAL), a framework in which a language model is trained to use all three primitives, as part of a unified inference compute pipeline. Concretely, the language model first samples a set of independent traces in parallel, each produced through sequential chain-of-thought reasoning, and then generates a final aggregation trace conditioned on those traces; all components are optimized end-to-end against the reward of the final aggregated response. To train this system, SPIRAL uses set reinforcement learning to teach models to produce a set of traces that are collectively useful for an aggregator and standard reinforcement learning to teach models to aggregate the set into improved final responses. Our experiments on reasoning tasks show that SPIRAL effectively scales with inference compute, outperforming GRPO by up to 11$\times$ scaling efficiency and 15% higher performance when all three compute primitives are scaled.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPIRAL, a framework for end-to-end training of language models to perform sequential reasoning, parallel trace sampling, and aggregation of multiple traces using a combination of set reinforcement learning and standard reinforcement learning. The model is optimized against the reward of the final aggregated response. The paper claims that this approach allows effective scaling with inference compute, outperforming GRPO by up to 11× in scaling efficiency and 15% in performance on reasoning tasks when scaling all three primitives.
Significance. If the results are robust, this would represent a meaningful advance in training models for multi-primitive inference-time compute scaling. The end-to-end optimization is a strength, as is the focus on collective utility of trace sets.
major comments (1)
- [Abstract] Abstract: The set reinforcement learning component is presented as teaching the model to produce traces that are collectively useful for the aggregator, but the description provides no auxiliary objective, regularization term, or sampling constraint to encourage diversity or complementarity among the parallel traces. This is load-bearing for the central scaling claims, as the reported 11× scaling efficiency when increasing parallel samples would be undermined if gradients favor redundant high-reward patterns rather than complementary ones.
minor comments (1)
- [Abstract] Abstract: The distinction between 'set reinforcement learning' and 'standard reinforcement learning' is invoked without a precise definition of the objectives or how the set-level reward is computed and backpropagated.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment on the set reinforcement learning component below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The set reinforcement learning component is presented as teaching the model to produce traces that are collectively useful for the aggregator, but the description provides no auxiliary objective, regularization term, or sampling constraint to encourage diversity or complementarity among the parallel traces. This is load-bearing for the central scaling claims, as the reported 11× scaling efficiency when increasing parallel samples would be undermined if gradients favor redundant high-reward patterns rather than complementary ones.
Authors: We thank the referee for highlighting this important point. In SPIRAL the set reinforcement learning objective optimizes trace generation end-to-end against the reward of the aggregator's final output. Because the aggregator is conditioned on the full set and receives reward only on the aggregated answer, traces that are redundant contribute no additional value and therefore receive lower effective credit under the set-level signal. This mechanism encourages complementarity without requiring an auxiliary diversity term. The abstract condenses this as 'collectively useful,' but we agree the presentation would benefit from greater explicitness. We will revise the abstract and method section to clarify the end-to-end objective and will add an empirical analysis of trace diversity to the appendix. revision: yes
Circularity Check
No circularity in SPIRAL derivation or claims
full rationale
The paper presents SPIRAL as an empirical training framework that optimizes a language model end-to-end against the final aggregated reward using set RL for trace generation and standard RL for aggregation. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Performance claims (scaling efficiency vs GRPO) rest on experimental comparisons rather than any closed mathematical loop or ansatz smuggled via prior work. This is a standard RL-for-LLM paper whose central method does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
STaR: Bootstrapping Reasoning With Reasoning , url =
Zelikman, Eric and Wu, Yuhuai and Mu, Jesse and Goodman, Noah , booktitle =. STaR: Bootstrapping Reasoning With Reasoning , url =
-
[2]
Proceedings of the Nineteenth International Conference on Machine Learning , pages =
Kakade, Sham and Langford, John , title =. Proceedings of the Nineteenth International Conference on Machine Learning , pages =. 2002 , isbn =
2002
-
[3]
2026 , eprint=
Polychromic Objectives for Reinforcement Learning , author=. 2026 , eprint=
2026
-
[4]
2025 , eprint=
Pass@K Policy Optimization: Solving Harder Reinforcement Learning Problems , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
Jointly Reinforcing Diversity and Quality in Language Model Generations , author=. 2025 , eprint=
2025
-
[6]
2017 , eprint=
Trust Region Policy Optimization , author=. 2017 , eprint=
2017
-
[7]
2025 , eprint=
VinePPO: Refining Credit Assignment in RL Training of LLMs , author=. 2025 , eprint=
2025
-
[8]
International Conference on Machine Learning , year=
Approximately Optimal Approximate Reinforcement Learning , author=. International Conference on Machine Learning , year=
-
[9]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[10]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[11]
2026 , eprint=
Poly-EPO: Training Exploratory Reasoning Models , author=. 2026 , eprint=
2026
-
[12]
2025 , eprint=
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
LLMs Can Generate a Better Answer by Aggregating Their Own Responses , author=. 2025 , eprint=
2025
-
[14]
arXiv preprint arXiv:2509.26626 , year=
Recursive self-aggregation unlocks deep thinking in large language models , author=. arXiv preprint arXiv:2509.26626 , year=
-
[15]
International Conference on Learning Representations , volume=
Mixture-of-agents enhances large language model capabilities , author=. International Conference on Learning Representations , volume=
-
[16]
Advances in Neural Information Processing Systems , volume=
Atom of thoughts for markov llm test-time scaling , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Advances in Neural Information Processing Systems , volume=
Chain of agents: Large language models collaborating on long-context tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
International Conference on Learning Representations , volume=
Skeleton-of-thought: Prompting llms for efficient parallel generation , author=. International Conference on Learning Representations , volume=
-
[19]
2025 , eprint=
THREAD: Thinking Deeper with Recursive Spawning , author=. 2025 , eprint=
2025
-
[20]
arXiv preprint arXiv:2504.07081 , year=
Self-steering language models , author=. arXiv preprint arXiv:2504.07081 , year=
-
[21]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[22]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[23]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[24]
arXiv preprint arXiv:1712.01815 , year=
Mastering chess and shogi by self-play with a general reinforcement learning algorithm , author=. arXiv preprint arXiv:1712.01815 , year=
-
[25]
arXiv preprint arXiv:2203.11171 , year=
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
-
[26]
2026 , eprint=
OpenAI o1 System Card , author=. 2026 , eprint=
2026
-
[27]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[28]
arXiv preprint arXiv:2602.10177 , year=
Towards autonomous mathematics research , author=. arXiv preprint arXiv:2602.10177 , year=
-
[29]
arXiv preprint arXiv:2507.15855 , year=
Winning gold at imo 2025 with a model-agnostic verification-and-refinement pipeline , author=. arXiv preprint arXiv:2507.15855 , year=
arXiv 2025
-
[30]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[31]
arXiv preprint arXiv:2506.13131 , year=
Alphaevolve: A coding agent for scientific and algorithmic discovery , author=. arXiv preprint arXiv:2506.13131 , year=
-
[32]
2025 , url =
Welcome to the Era of Experience , author =. 2025 , url =
2025
-
[33]
2025 , eprint=
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs , author=. 2025 , eprint=
2025
-
[34]
arXiv preprint arXiv:2407.21787 , year=
Large language monkeys: Scaling inference compute with repeated sampling , author=. arXiv preprint arXiv:2407.21787 , year=
-
[35]
arXiv preprint arXiv:2408.03314 , year=
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
-
[36]
arXiv preprint arXiv:2601.16175 , year=
Learning to discover at test time , author=. arXiv preprint arXiv:2601.16175 , year=
-
[37]
2025 , eprint=
Learning Adaptive Parallel Reasoning with Language Models , author=. 2025 , eprint=
2025
-
[38]
Miguel Calvo-Fullana, Santiago Paternain, Luiz F
Noam Brown and Tuomas Sandholm , title =. Science , volume =. 2019 , doi =. https://www.science.org/doi/pdf/10.1126/science.aay2400 , abstract =
-
[39]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Math-shepherd: Verify and reinforce llms step-by-step without human annotations , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[40]
2023 , eprint=
Self-Refine: Iterative Refinement with Self-Feedback , author=. 2023 , eprint=
2023
-
[41]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[42]
2026 , eprint=
OpenDeepThink: Parallel Reasoning via Bradley--Terry Aggregation , author=. 2026 , eprint=
2026
-
[43]
2025 , eprint=
Population-Evolve: a Parallel Sampling and Evolutionary Method for LLM Math Reasoning , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
ParaThinker: Native Parallel Thinking as a New Paradigm to Scale LLM Test-time Compute , author=. 2025 , eprint=
2025
-
[45]
2026 , eprint=
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning , author=. 2026 , eprint=
2026
-
[46]
2025 , eprint=
Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation , author=. 2025 , eprint=
2025
-
[47]
2025 , eprint=
Learning to Reason Across Parallel Samples for LLM Reasoning , author=. 2025 , eprint=
2025
-
[48]
arXiv preprint arXiv:2503.19595 , year=
Optimizing language models for inference time objectives using reinforcement learning , author=. arXiv preprint arXiv:2503.19595 , year=
-
[49]
and McAllester, David and Singh, Satinder and Mansour, Yishay , title =
Sutton, Richard S. and McAllester, David and Singh, Satinder and Mansour, Yishay , title =. Proceedings of the 13th International Conference on Neural Information Processing Systems , pages =. 1999 , publisher =
1999
-
[50]
and Barto, Andrew G
Sutton, Richard S. and Barto, Andrew G. , title =. 2018 , isbn =
2018
-
[51]
A Natural Policy Gradient , url =
Kakade, Sham M , booktitle =. A Natural Policy Gradient , url =
-
[52]
Sutton and Mohammad Ghavamzadeh and Mark Lee , keywords =
Shalabh Bhatnagar and Richard S. Sutton and Mohammad Ghavamzadeh and Mark Lee , keywords =. Natural actor–critic algorithms , journal =. 2009 , issn =. doi:https://doi.org/10.1016/j.automatica.2009.07.008 , url =
-
[53]
2013 , eprint=
Off-Policy Actor-Critic , author=. 2013 , eprint=
2013
-
[54]
Lillicrap and Jonathan J
Timothy P. Lillicrap and Jonathan J. Hunt and Alexander Pritzel and Nicolas Heess and Tom Erez and Yuval Tassa and David Silver and Daan Wierstra , editor =. Continuous control with deep reinforcement learning , booktitle =. 2016 , url =
2016
-
[55]
2017 , eprint=
Sample Efficient Actor-Critic with Experience Replay , author=. 2017 , eprint=
2017
-
[56]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[57]
2025 , eprint=
Group Sequence Policy Optimization , author=. 2025 , eprint=
2025
-
[58]
2025 , eprint=
Understanding R1-Zero-Like Training: A Critical Perspective , author=. 2025 , eprint=
2025
-
[59]
arXiv preprint arXiv:2506.13585 , year=
Minimax-m1: Scaling test-time compute efficiently with lightning attention , author=. arXiv preprint arXiv:2506.13585 , year=
-
[60]
POLARIS: A Post-Training Recipe for Scaling Reinforcement Learning on Advanced Reasoning Models , url =
An, Chenxin and Xie, Zhihui and Li, Xiaonan and Li, Lei and Zhang, Jun and Gong, Shansan and Zhong, Ming and Xu, Jingjing and Qiu, Xipeng and Wang, Mingxuan and Kong, Lingpeng , year =. POLARIS: A Post-Training Recipe for Scaling Reinforcement Learning on Advanced Reasoning Models , url =
-
[61]
ICML 2025 Workshop on Long-Context Foundation Models , year=
Simple, Scalable Reasoning via Iterated Summarization , author=. ICML 2025 Workshop on Long-Context Foundation Models , year=
2025
-
[62]
2026 , eprint=
Meta-Harness: End-to-End Optimization of Model Harnesses , author=. 2026 , eprint=
2026
-
[63]
2025 , eprint=
Rethinking Thinking Tokens: LLMs as Improvement Operators , author=. 2025 , eprint=
2025
-
[64]
2026 , eprint=
Scaling Test-Time Compute for Agentic Coding , author=. 2026 , eprint=
2026
-
[65]
Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions
Pezeshkpour, Pouya and Hruschka, Estevam. Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.130
-
[66]
Advances in Neural Information Processing Systems , volume=
Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
arXiv preprint arXiv:2210.03493 , year=
Automatic chain of thought prompting in large language models , author=. arXiv preprint arXiv:2210.03493 , year=
-
[68]
2026 , eprint=
Composer 2 Technical Report , author=. 2026 , eprint=
2026
-
[69]
2026 , url =
Thinking Machines Lab , title =. 2026 , url =
2026
-
[70]
2026 , eprint=
Neural Garbage Collection: Learning to Forget while Learning to Reason , author=. 2026 , eprint=
2026
-
[71]
2026 , eprint=
Forget, Then Recall: Learnable Compression and Selective Unfolding via Gist Sparse Attention , author=. 2026 , eprint=
2026
-
[72]
2025 , eprint=
Creating General User Models from Computer Use , author=. 2025 , eprint=
2025
-
[73]
2026 , eprint=
Learning Next Action Predictors from Human-Computer Interaction , author=. 2026 , eprint=
2026
-
[74]
2026 , eprint=
Using Reward Uncertainty to Induce Diverse Behaviour in Reinforcement Learning , author=. 2026 , eprint=
2026
-
[75]
2025 , eprint=
S*: Test Time Scaling for Code Generation , author=. 2025 , eprint=
2025
-
[76]
2026 , eprint=
Remarks on the disproof of the unit distance conjecture , author=. 2026 , eprint=
2026
-
[77]
2026 , eprint=
First Proof , author=. 2026 , eprint=
2026
-
[78]
2026 , eprint=
First Proof Second Batch , author=. 2026 , eprint=
2026
-
[79]
2026 , month = feb, day =
Harness Engineering: Leveraging Codex in an Agent-First World , author =. 2026 , month = feb, day =
2026
-
[80]
2026 , eprint=
V_1 : Unifying Generation and Self-Verification for Parallel Reasoners , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.