Diffusion Models Adapt to Low-Dimensional Structure Under Flexible Coefficient Choices
Pith reviewed 2026-06-26 05:54 UTC · model grok-4.3
The pith
Diffusion models achieve dimension-independent sampling rates in total variation distance for a broad class of update coefficients when data has low intrinsic dimension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For a broad class of update coefficients, diffusion models require only Õ(k/ε) iterations to produce an ε-accurate sample in total variation distance whenever the data distribution possesses low-dimensional structure of intrinsic dimension k; the rate is independent of ambient dimension.
What carries the argument
The broad class of update coefficients for which the low-dimensional adaptation convergence analysis applies.
If this is right
- Several commonly used diffusion samplers in practice now fall under the low-dimensional adaptation guarantee.
- The iteration complexity depends only on intrinsic dimension and accuracy, not ambient dimension.
- The framework broadens the set of diffusion samplers theoretically justified for structured high-dimensional data.
Where Pith is reading between the lines
- Practitioners gain freedom to select coefficients for numerical stability or speed without sacrificing the dimension-free guarantee.
- Similar robustness arguments may apply to other iterative samplers that use flexible step-size or noise schedules.
- The result motivates checking whether new coefficient families outside the current broad class still preserve the rate.
Load-bearing premise
The target distribution has low-dimensional structure of intrinsic dimension k and the coefficients lie in the broad class covered by the analysis.
What would settle it
A concrete counterexample in which, for some coefficient choice inside the claimed broad class and data with intrinsic dimension k, the number of iterations needed to reach fixed TV accuracy grows with ambient dimension.
Figures
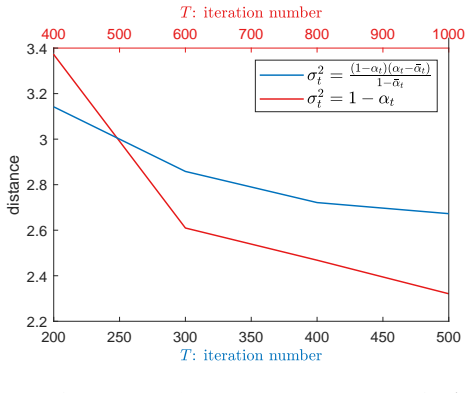
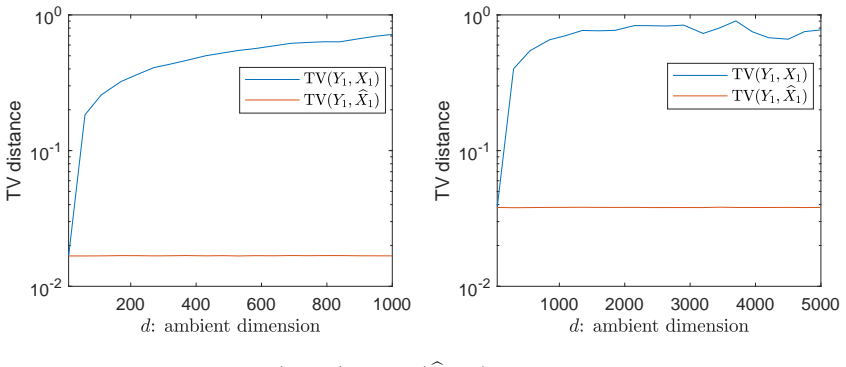
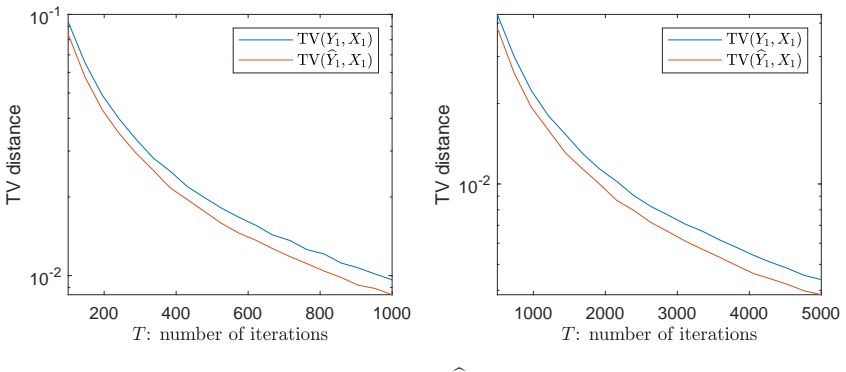
read the original abstract
Diffusion models are known to exploit unknown low-dimensional structure to accelerate sampling. However, existing convergence theory under low-dimensional data structure has largely focused on update rules with narrowly prescribed coefficient choices. This raises a fundamental question: is adaptation to low-dimensional structure sensitive to the precise choice of update coefficients? In this paper, we show that such adaptation is a robust property of diffusion models. For a broad class of update coefficients, we prove that $\widetilde{O}(k/\varepsilon)$ iterations suffice to generate an $\varepsilon$-accurate sample in total variation (TV) distance, independently of the ambient dimension. Our framework substantially broadens the class of diffusion samplers known to enjoy low dimensional adaptation and applies to several commonly used methods in practice. These results provide a theoretical justification for the empirical effectiveness of diffusion samplers across different coefficient choices when applied to structured, high-dimensional data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that diffusion models adapt to unknown low-dimensional structure (intrinsic dimension k) for a broad class of update coefficients. It proves that Õ(k/ε) iterations suffice to produce an ε-accurate sample in total variation distance, with the rate independent of ambient dimension. The framework is shown to cover several commonly used practical methods.
Significance. If the stated convergence result holds under the paper's assumptions, it substantially widens the set of diffusion samplers with rigorous low-dimensional adaptation guarantees. This supplies theoretical support for the observed robustness of diffusion sampling across coefficient choices on structured high-dimensional data.
minor comments (2)
- [Abstract] The abstract asserts that the result 'applies to several commonly used methods in practice' but does not name them or indicate which coefficient families are covered; adding one sentence with explicit examples would improve immediate readability.
- Notation for the update coefficients and the precise definition of the 'broad class' should be introduced with a displayed equation or boxed definition in the introduction or preliminaries section to make the scope of the theorem immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the significance of the low-dimensional adaptation result, and the recommendation to accept. No major comments were raised that require point-by-point responses.
Circularity Check
No significant circularity detected in convergence analysis
full rationale
The paper presents a mathematical convergence proof establishing that Õ(k/ε) iterations suffice for ε-accurate TV sampling under low-dimensional structure, for a broad class of update coefficients. This is a standard theoretical derivation relying on analysis of the diffusion process and manifold adaptation, with no evidence of self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations that collapse the result to its inputs by construction. The abstract explicitly conditions the result on the intrinsic dimension k and the coefficient class, without internal inconsistencies or smuggling of ansatzes. The derivation chain is self-contained as an independent proof.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Data distribution has low-dimensional structure of intrinsic dimension k
- ad hoc to paper Update coefficients belong to the broad class covered by the analysis
Reference graph
Works this paper leans on
-
[1]
Anderson, B. D. (1982). Reverse-time diffusion equation models. Stochastic Processes and their Applications , 12(3):313--326
1982
-
[2]
Azangulov, I., Deligiannidis, G., and Rousseau, J. (2024). Convergence of diffusion models under the manifold hypothesis in high-dimensions. arXiv preprint arXiv:2409.18804
arXiv 2024
-
[3]
Bao, F., Li, C., Zhu, J., and Zhang, B. (2022). Analytic-dpm: an analytic estimate of the optimal reverse variance in diffusion probabilistic models. arXiv preprint arXiv:2201.06503
arXiv 2022
-
[5]
Benton, J., De Bortoli, V., Doucet, A., and Deligiannidis, G. (2023b). Nearly d -linear convergence bounds for diffusion models via stochastic localization. arXiv preprint arXiv:2308.03686
-
[6]
Boffi, N., Jacot, A., Tu, S., and Ziemann, I. (2025). Shallow diffusion networks provably learn hidden low-dimensional structure. In International Conference on Learning Representations , volume 2025, pages 52889--52923
2025
- [7]
- [8]
-
[9]
Chen, H., Lee, H., and Lu, J. (2023a). Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions. In International Conference on Machine Learning , pages 4735--4763. PMLR
-
[10]
Chen, M., Huang, K., Zhao, T., and Wang, M. (2023b). Score approximation, estimation and distribution recovery of diffusion models on low-dimensional data. In International Conference on Machine Learning , pages 4672--4712. PMLR
-
[11]
Chen, S., Chewi, S., Lee, H., Li, Y., Lu, J., and Salim, A. (2023c). The probability flow ode is provably fast. Advances in Neural Information Processing Systems , 36:68552--68575
-
[12]
Chen, S., Chewi, S., Li, J., Li, Y., Salim, A., and Zhang, A. R. (2022). Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. arXiv preprint arXiv:2209.11215
arXiv 2022
-
[13]
Chen, S., Cong, K., and Li, J. (2025). Optimal inference schedules for masked diffusion models. arXiv preprint arXiv:2511.04647
arXiv 2025
-
[14]
and Nichol, A
Dhariwal, P. and Nichol, A. (2021). Diffusion models beat gans on image synthesis. Advances in neural information processing systems , 34:8780--8794
2021
-
[15]
Dmitriev, D., Huang, Z., and Wei, Y. (2026). Efficient sampling with discrete diffusion models: Sharp and adaptive guarantees. arXiv preprint arXiv:2602.15008
arXiv 2026
-
[16]
Fan, J., Gu, Y., and Li, X. (2025). Optimal estimation of a factorizable density using diffusion models with relu neural networks. arXiv preprint arXiv:2510.03994
arXiv 2025
-
[17]
Gupta, S., Cai, L., and Chen, S. (2024). Faster diffusion-based sampling with randomized midpoints: Sequential and parallel. arXiv preprint arXiv:2406.00924
arXiv 2024
-
[18]
Haussmann, U. G. and Pardoux, E. (1986). Time reversal of diffusions. The Annals of Probability , pages 1188--1205
1986
-
[19]
Ho, J., Jain, A., and Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems , 33:6840--6851
2020
-
[20]
Huang, D. Z., Huang, J., and Lin, Z. (2024a). Convergence analysis of probability flow ODE for score-based generative models. arXiv preprint arXiv:2404.09730
-
[21]
Huang, X., Zou, D., Dong, H., Zhang, Y., Ma, Y.-A., and Zhang, T. (2024b). Reverse transition kernel: A flexible framework to accelerate diffusion inference. arXiv preprint arXiv:2405.16387
-
[22]
Huang, Z., Wei, Y., and Chen, Y. (2024c). Denoising diffusion probabilistic models are optimally adaptive to unknown low dimensionality. arXiv preprint arXiv:2410.18784
-
[24]
Karras, T., Aittala, M., Aila, T., and Laine, S. (2022). Elucidating the design space of diffusion-based generative models. Advances in neural information processing systems , 35:26565--26577
2022
-
[25]
Krizhevsky, A., Hinton, G., et al. (2009). Learning multiple layers of features from tiny images.(2009)
2009
-
[26]
Lee, H., Lu, J., and Tan, Y. (2023). Convergence of score-based generative modeling for general data distributions. In International Conference on Algorithmic Learning Theory , pages 946--985. PMLR
2023
-
[27]
Li, G. and Cai, C. (2024). Provable acceleration for diffusion models under minimal assumptions. arXiv preprint arXiv:2410.23285
arXiv 2024
-
[28]
and Cai, C
Li, G. and Cai, C. (2025). Breaking ar's sampling bottleneck: Provable acceleration via diffusion language models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[29]
Li, G., Cai, C., and Wei, Y. (2025a). Dimension-free convergence of diffusion models for approximate gaussian mixtures. arXiv preprint arXiv:2504.05300
-
[30]
Li, G., Huang, Y., Efimov, T., Wei, Y., Chi, Y., and Chen, Y. (2024). Accelerating convergence of score-based diffusion models, provably. arXiv preprint arXiv:2403.03852
arXiv 2024
-
[31]
Li, G. and Jiao, Y. (2024). Improved convergence rate for diffusion probabilistic models. arXiv preprint arXiv:2410.13738
arXiv 2024
-
[32]
Li, G., Wei, Y., Chen, Y., and Chi, Y. (2023). Towards faster non-asymptotic convergence for diffusion-based generative models. arXiv preprint arXiv:2306.09251
arXiv 2023
-
[33]
Li, G. and Yan, Y. (2024a). Adapting to unknown low-dimensional structures in score-based diffusion models. arXiv preprint arXiv:2405.14861
-
[34]
Li, G. and Yan, Y. (2024b). O (d/ T ) convergence theory for diffusion probabilistic models under minimal assumptions. arXiv preprint arXiv:2409.18959
-
[35]
Li, G., Zhou, Y., Wei, Y., and Chen, Y. (2025b). Faster diffusion models via higher-order approximation. arXiv preprint arXiv:2506.24042
-
[36]
Liang, J., Huang, Z., and Chen, Y. (2025). Low-dimensional adaptation of diffusion models: Convergence in total variation. arXiv preprint arXiv:2501.12982
arXiv 2025
-
[37]
Nichol, A. Q. and Dhariwal, P. (2021). Improved denoising diffusion probabilistic models. In International conference on machine learning , pages 8162--8171. PMLR
2021
-
[38]
Oko, K., Akiyama, S., and Suzuki, T. (2023). Diffusion models are minimax optimal distribution estimators. In International Conference on Machine Learning , pages 26517--26582. PMLR
2023
-
[39]
Pope, P., Zhu, C., Abdelkader, A., Goldblum, M., and Goldstein, T. (2021). The intrinsic dimension of images and its impact on learning. arXiv preprint arXiv:2104.08894
arXiv 2021
-
[40]
Popov, V., Vovk, I., Gogoryan, V., Sadekova, T., and Kudinov, M. (2021). Grad-tts: A diffusion probabilistic model for text-to-speech. In International Conference on Machine Learning , pages 8599--8608. PMLR
2021
-
[41]
Potaptchik, P., Azangulov, I., and Deligiannidis, G. (2024). Linear convergence of diffusion models under the manifold hypothesis. arXiv preprint arXiv:2410.09046
arXiv 2024
-
[42]
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen, M. (2022). Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 , 1(2):3
Pith/arXiv arXiv 2022
-
[43]
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and Ganguli, S. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning , pages 2256--2265. pmlr
2015
-
[44]
Song, J., Meng, C., and Ermon, S. (2020a). Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502
Pith/arXiv arXiv 2010
-
[45]
and Ermon, S
Song, Y. and Ermon, S. (2019). Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems , 32
2019
-
[46]
P., Kumar, A., Ermon, S., and Poole, B
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. (2020b). Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456
Pith/arXiv arXiv 2011
-
[47]
and Yan, Y
Tang, J. and Yan, Y. (2026). Adaptivity and convergence of probability flow odes in diffusion generative models
2026
-
[48]
and Yang, Y
Tang, R. and Yang, Y. (2024). Adaptivity of diffusion models to manifold structures. In International Conference on Artificial Intelligence and Statistics , pages 1648--1656. PMLR
2024
-
[49]
Vershynin, R. (2018). High-dimensional probability: An introduction with applications in data science , volume 47. Cambridge university press
2018
-
[50]
Wang, P., Zhang, H., Zhang, Z., Chen, S., Ma, Y., and Qu, Q. (2024). Diffusion models learn low-dimensional distributions via subspace clustering. arXiv preprint arXiv:2409.02426
Pith/arXiv arXiv 2024
-
[51]
Wibisono, A., Wu, Y., and Yang, K. Y. (2024). Optimal score estimation via empirical bayes smoothing. arXiv preprint arXiv:2402.07747
arXiv 2024
-
[52]
Wu, J. and Cai, C. (2026). Diffusion models are statistically optimal for learning low-dimensional multi-modal distributions. arXiv preprint arXiv:2605.30153
Pith/arXiv arXiv 2026
-
[53]
Wu, Y., Chen, Y., and Wei, Y. (2024). Stochastic runge-kutta methods: Provable acceleration of diffusion models. arXiv preprint arXiv:2410.04760
arXiv 2024
- [54]
-
[55]
Zhang, K., Yin, H., Liang, F., and Liu, J. (2024). Minimax optimality of score-based diffusion models: Beyond the density lower bound assumptions. arXiv preprint arXiv:2402.15602
arXiv 2024
-
[56]
Zhao, Y. and Cai, C. (2026). Adaptation to intrinsic dependence in diffusion language models. arXiv preprint arXiv:2602.20126
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.