E-MRL: Cross-view Aligned Evidence-driven Multimodal Reinforcement Learning for Reliable 3D Tumor Analysis
Pith reviewed 2026-06-26 05:59 UTC · model grok-4.3
The pith
E-MRL trains VLMs to select and verify a key CT slice so reports reflect actual visual evidence rather than language patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
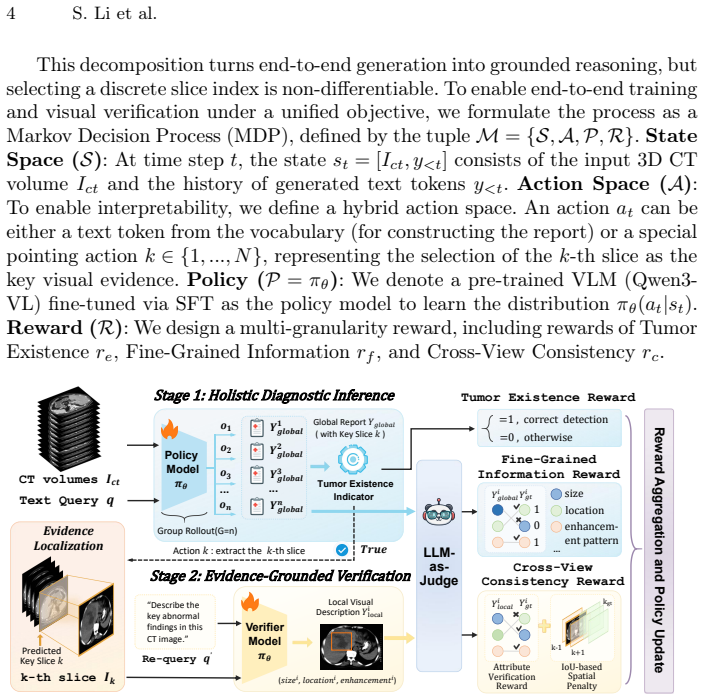
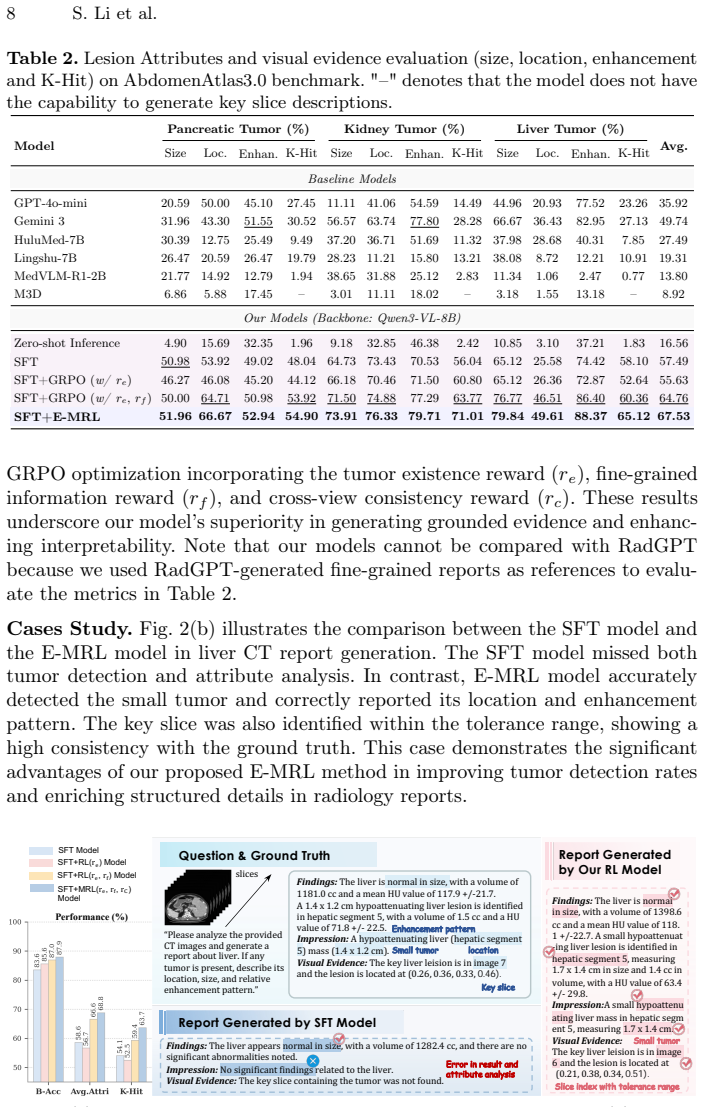
The paper claims that an evidence-driven reinforcement learning loop, structured as diagnosis then localization of a key slice then verification, combined with a cross-view consistency reward that checks semantic alignment between the report and a local re-query of the slice, produces reports with measurably fewer hallucinations and higher diagnostic accuracy on large 3D CT tumor datasets than either supervised fine-tuning or standard reinforcement learning baselines.
What carries the argument
The cross-view consistency reward that scores semantic alignment between the golden-standard report and a visual re-query of the model-selected key evidence slice.
If this is right
- The model outputs both a report and an explicit key slice that can be inspected to confirm the stated findings.
- Training no longer rewards diagnoses that can be guessed from language priors alone.
- Accuracy gains appear on large-scale 3D CT tumor datasets relative to SFT and standard RL baselines.
- The resulting reports become more clinically interpretable because each diagnosis is tied to a verifiable image location.
Where Pith is reading between the lines
- The same localization-plus-verification loop could be tested on other volumetric modalities such as MRI if a comparable re-query mechanism is available.
- Clinicians might use the returned key slices as an initial focus for manual review rather than scanning the entire volume.
- If the reward works, similar consistency checks could be added to non-medical 3D vision-language tasks where grounding matters.
Load-bearing premise
The cross-view consistency reward actually enforces genuine visual grounding rather than simply rewarding agreement with language patterns already present in the report.
What would settle it
A test set of cases where the selected key slice visually contradicts the report diagnosis yet the consistency reward remains high would show the reward is not measuring visual grounding.
Figures
read the original abstract
While Vision-Language Models (VLMs) show great promise in volumetric medical report generation, they frequently suffer from visual hallucinations and a lack of grounding in 3D CT data. Current Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) strategies typically optimize text fidelity alone, essentially rewarding correct diagnoses derived from language priors rather than genuine visual perception. To address this, we propose cross-view aligned Evidence-driven Multimodal Reinforcement Learning (Evidence-MRL, noted as E-MRL), a reliable RL reasoning framework that formulates the generation process as a Markov Decision Process of "diagnosis-localization-verification". Unlike standard approaches, our model is explicitly trained to identify a "key evidence slice" alongside the global diagnostic report, grounding its findings in verifiable visual evidence. Crucially, we introduce a novel cross-view consistency reward, which validates the semantic alignment between the golden-standard report and a local visual re-query of the selected key slice, providing additional rewards for correctly-localized reasoning. Experiments on large-scale 3D CT tumor datasets demonstrate that E-MRL significantly reduces hallucinations and improves diagnostic accuracy compared to SFT and RL baselines, offering a clinically interpretable solution for visually-grounded and tumor analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes E-MRL, a multimodal RL framework for volumetric medical report generation from 3D CT tumor data. It models the task as a Markov Decision Process of diagnosis-localization-verification, where the model selects a key evidence slice and is trained with a novel cross-view consistency reward that measures semantic alignment between the golden-standard report and a local visual re-query on that slice. The abstract asserts that experiments on large-scale 3D CT tumor datasets show E-MRL significantly reduces hallucinations and improves diagnostic accuracy relative to SFT and standard RL baselines.
Significance. If the cross-view consistency reward can be demonstrated to enforce genuine visual grounding rather than agreement with language priors already present in the report, the approach would supply a clinically interpretable mechanism for reducing hallucinations in 3D medical VLMs and could influence reward design in evidence-driven multimodal reasoning.
major comments (2)
- [Abstract] Abstract: the claim that 'experiments on large-scale 3D CT tumor datasets demonstrate that E-MRL significantly reduces hallucinations and improves diagnostic accuracy' supplies no quantitative metrics, baseline details, statistical tests, or error analysis, so the data cannot be shown to support the stated claim.
- [Abstract] Abstract: the cross-view consistency reward is defined as semantic alignment between the golden-standard report and the output of a local visual re-query performed by the same VLM family; without an explicit mechanism to isolate visual features or ablate language components in the re-query step, high alignment can be achieved by regenerating report content from textual cues, undermining the claim that the reward enforces visual perception.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract. We address each major comment below and commit to revisions that strengthen the presentation of results and clarify the reward mechanism.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'experiments on large-scale 3D CT tumor datasets demonstrate that E-MRL significantly reduces hallucinations and improves diagnostic accuracy' supplies no quantitative metrics, baseline details, statistical tests, or error analysis, so the data cannot be shown to support the stated claim.
Authors: We agree that the abstract claim would be stronger with explicit quantitative support. The full manuscript reports detailed metrics (hallucination rate reductions, accuracy gains, baseline comparisons, and statistical tests) in the Experiments section. We will revise the abstract to include key numerical results and significance levels drawn from those experiments. revision: yes
-
Referee: [Abstract] Abstract: the cross-view consistency reward is defined as semantic alignment between the golden-standard report and the output of a local visual re-query performed by the same VLM family; without an explicit mechanism to isolate visual features or ablate language components in the re-query step, high alignment can be achieved by regenerating report content from textual cues, undermining the claim that the reward enforces visual perception.
Authors: This is a substantive concern. While the re-query operates on the selected image slice, the current description does not explicitly rule out language-prior leakage. We will add a new ablation in the revised manuscript that replaces the visual re-query with a text-only prompt (no image input) and report the resulting performance drop. We will also expand the method section to detail the visual-specific prompting used in the re-query step. revision: yes
Circularity Check
No significant circularity; reward uses external ground truth
full rationale
The paper proposes an RL framework whose central mechanism is a cross-view consistency reward defined as semantic alignment between an external golden-standard report and the output of a visual re-query on a selected slice. This is a standard external training signal, not a reduction of the claimed result to the model's own fitted outputs by construction. No equations, self-citations, or uniqueness theorems appear in the abstract or description that would make the experimental claims tautological. The distinction between language priors and visual grounding is an empirical question addressed by the reported experiments rather than a definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2404.00578 (2024)
Bai, F., Du, Y., Huang, T., Meng, M.Q.H., Zhao, B.: M3d: Advancing 3d medical image analysis with multi-modal large language models. arXiv preprint arXiv:2404.00578 (2024)
arXiv 2024
-
[2]
In: ICCV
Bassi, P.R., Yavuz, M.C., Hamamci, I.E., Er, S., Chen, X., Li, W., Menze, B., Decherchi, S., Cavalli, A., Wang, K., et al.: Radgpt: Constructing 3d image-text tumor datasets. In: ICCV. pp. 23720–23730 (2025)
2025
-
[3]
Research Square pp
Blankemeier, L., Cohen, J.P., Kumar, A., Van Veen, D., Gardezi, S.J.S., Paschali, M., Chen, Z., Delbrouck, J.B., Reis, E., Truyts, C., et al.: Merlin: A vision language foundation model for 3d computed tomography. Research Square pp. rs–3 (2024)
2024
-
[4]
arXiv preprint arXiv:2602.06965 (2026)
Deria, A., Kumar, K., Dukre, A.M., Segal, E., Khan, S., Razzak, I.: MedMO: Grounding and understanding multimodal large language model for medical im- ages. arXiv preprint arXiv:2602.06965 (2026)
arXiv 2026
-
[5]
arXiv preprint arXiv:2601.20467 (2026)
Fan, Z., Cao, J., Dai, Y., Lv, Z., Zhang, W., Xie, Z., LU, P., Ooi, B.C.: Ctrlcot: Dual-granularity chain-of-thought compression for controllable reasoning. arXiv preprint arXiv:2601.20467 (2026)
arXiv 2026
-
[6]
arXiv preprint arXiv:2505.19630 (2025)
Feng, Y., Wang, J., Zhou, L., Lei, Z., Li, Y.: Doctoragent-rl: A multi-agent col- laborative reinforcement learning system for multi-turn clinical dialogue. arXiv preprint arXiv:2505.19630 (2025)
Pith/arXiv arXiv 2025
-
[7]
In: MICCAI
Hamamci, I.E., Er, S., Menze, B.: Ct2rep: Automated radiology report generation for 3d medical imaging. In: MICCAI. pp. 476–486. Springer (2024)
2024
-
[8]
Nature Biomedical Engineering pp
Hamamci, I.E., Er, S., Wang, C., Almas, F., Simsek, A.G., Esirgun, S.N., Dogan, I., Durugol, O.F., Hou, B., Shit, S., et al.: Generalist foundation models from a multimodal dataset for 3d computed tomography. Nature Biomedical Engineering pp. 1–19 (2026)
2026
-
[9]
In: MICCAI
Hu, Q., Yi, Z., Zhou, Y., Peng, F., Liu, M., Li, Q., Wang, Z.: Sali: Short-term align- ment and long-term interaction network for colonoscopy video polyp segmentation. In: MICCAI. pp. 531–541. Springer (2024)
2024
-
[10]
arXiv preprint arXiv:2508.02669 (2025)
Huang, X., Wu, J., Liu, H., Tang, X., Zhou, Y.: Medvlthinker: Simple baselines for multimodal medical reasoning. arXiv preprint arXiv:2508.02669 (2025)
arXiv 2025
-
[11]
arXiv preprint arXiv:2410.21276 (2024)
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[12]
arXiv preprint arXiv:2510.08668 (2025)
Jiang, S., Wang, Y., Song, S., Hu, T., Zhou, C., Pu, B., Zhang, Y., Yang, Z., Feng, Y., Zhou, J.T., et al.: Hulu-med: A transparent generalist model towards holistic medical vision-language understanding. arXiv preprint arXiv:2510.08668 (2025)
arXiv 2025
-
[13]
In: ICLR (2026)
Jiang, Z., Guo, H., Fang, C., Xiao, C., Hu, X., Sun, L., Xu, M.: MedVR: Annotation-free medical visual reasoning via agentic reinforcement learning. In: ICLR (2026)
2026
-
[14]
arXiv preprint arXiv:2602.01200 (2026)
Lai, H., Jiang, Z., Zhang, K., Yao, Q., Wang, R., He, Z., Tao, X., Wei, W., Zhou, S.K.: Med3D-R1: Incentivizing clinical reasoning in 3d medical vision-language models for abnormality diagnosis. arXiv preprint arXiv:2602.01200 (2026)
arXiv 2026
-
[15]
IEEE Transactions on Medical Imaging (2026)
Lai, Y., Zhong, J., Li, M., Zhao, S., Li, Y., Psounis, K., Yang, X.: Med-r1: Rein- forcement learning for generalizable medical reasoning in vision-language models. IEEE Transactions on Medical Imaging (2026)
2026
-
[16]
Advances in NeurIPS36, 28541–28564 (2023) Evidence-MRL for 3D Tumor Analysis 11
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in NeurIPS36, 28541–28564 (2023) Evidence-MRL for 3D Tumor Analysis 11
2023
-
[17]
In: ACM MM
Li, S., Lin, T., Lin, L., Zhang, W., Liu, J., Yang, X., Li, J., He, Y., Song, X., Xiao, J., et al.: Eyecaregpt: Boosting comprehensive ophthalmology understanding with tailored dataset, benchmark and model. In: ACM MM. pp. 3893–3902 (2025)
2025
-
[18]
In: ICLR
Li, S., Qiu, Z., Liu, J., Zhang, W., Lin, T., Xie, Y., An, J., Yun, B., Yang, C., Xiao, J., et al.: Tumorchain: Interleaved multimodal chain-of-thought reasoning for traceable clinical tumor analysis. In: ICLR
-
[19]
In: ISBI
Li, Y., Tang, F., Li, Y., Zhou, S.K.: Medreason-r1: Learning to reason for ct diag- nosis with reinforcement learning and local zoom. In: ISBI. pp. 1–5. IEEE (2026)
2026
-
[20]
arXiv preprint arXiv:2602.16110 (2026)
Lin, T., Qiu, Z., Zhang, W., Liu, J., Xie, Y., Gao, M., Fan, Z., Li, Z., Li, S., Xie, Z., et al.: Omnict: Towards a unified slice-volume lvlm for comprehensive ct analysis. arXiv preprint arXiv:2602.16110 (2026)
arXiv 2026
-
[21]
arXiv preprint arXiv:2502.09838 (2025)
Lin, T., Zhang, W., Li, S., Yuan, Y., Yu, B., Li, H., He, W., Jiang, H., Li, M., Song, X., et al.: Healthgpt: A medical large vision-language model for unifying compre- hension and generation via heterogeneous knowledge adaptation. arXiv preprint arXiv:2502.09838 (2025)
arXiv 2025
-
[22]
arXiv preprint arXiv:2606.07542 (2026)
Liu, C., Wu, J., Xie, Z., Zhang, W., Zheng, K., Zhu, J., Cai, Q., Anne, O.G., Tan, M.C.J., Yin, J., et al.: Diyhealth suite: Dataset, model, and benchmark for health management at home. arXiv preprint arXiv:2606.07542 (2026)
Pith/arXiv arXiv 2026
-
[23]
In: MICCAI
Pan, J., Liu, C., Wu, J., Liu, F., Zhu, J., Li, H.B., Chen, C., Ouyang, C., Rueckert, D.: Medvlm-r1: Incentivizing medical reasoning capability of vision-language mod- els (vlms) via reinforcement learning. In: MICCAI. pp. 337–347. Springer (2025)
2025
-
[24]
In: Medical Imaging with Deep Learning (2025)
Pellegrini,C.,Özsoy,E.,Busam,B.,Wiestler,B.,Navab,N.,Keicher,M.:Radialog: Large vision-language models for x-ray reporting and dialog-driven assistance. In: Medical Imaging with Deep Learning (2025)
2025
-
[25]
arXiv preprint arXiv:2507.05201 (2025)
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al.: Medgemma technical report. arXiv preprint arXiv:2507.05201 (2025)
Pith/arXiv arXiv 2025
-
[26]
arXiv preprint arXiv:2312.11805 (2023)
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
Pith/arXiv arXiv 2023
-
[27]
Nejm Ai1(3), AIoa2300138 (2024)
Tu, T., Azizi, S., Driess, D., Schaekermann, M., Amin, M., Chang, P.C., Carroll, A., Lau, C., Tanno, R., Ktena, I., et al.: Towards generalist biomedical ai. Nejm Ai1(3), AIoa2300138 (2024)
2024
-
[28]
Nature Communications16(1), 7866 (2025)
Wu, C., Zhang, X., Zhang, Y., Hui, H., Wang, Y., Xie, W.: Towards generalist foun- dation model for radiology by leveraging web-scale 2d&3d medical data. Nature Communications16(1), 7866 (2025)
2025
-
[29]
arXiv preprint arXiv:2506.00555 (2025)
Xia, P., Wang, J., Peng, Y., Zeng, K., Wu, X., Tang, X., Zhu, H., Li, Y., Liu, S., Lu, Y., et al.: Mmedagent-rl: Optimizing multi-agent collaboration for multimodal medical reasoning. arXiv preprint arXiv:2506.00555 (2025)
arXiv 2025
-
[30]
arXiv e-prints pp
Xie, Y., Li, S., Lin, T., Wang, Z., Yang, C., Zhong, Y., Zhang, W., Li, H., Jiang, H., Zhang, F., et al.: Heartcare suite: Multi-dimensional understanding of ecg with raw multi-lead signal modeling. arXiv e-prints pp. arXiv–2506 (2025)
2025
-
[31]
arXiv preprint arXiv:2506.07044 (2025)
Xu, W., Chan, H.P., Li, L., Aljunied, M., Yuan, R., Wang, J., Xiao, C., Chen, G., Liu,C.,Li,Z.,etal.:Lingshu:Ageneralistfoundationmodelforunifiedmultimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044 (2025)
Pith/arXiv arXiv 2025
-
[32]
arXiv preprint arXiv:2505.09388 (2025)
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
Pith/arXiv arXiv 2025
-
[33]
In: CVPR
Yu, T., Yao, Y., Zhang, H., He, T., Han, Y., Cui, G., Hu, J., Liu, Z., Zheng, H.T., Sun, M., et al.: Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. In: CVPR. pp. 13807–13816 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.