Fast and Slow Variational Continual Learning
Pith reviewed 2026-06-26 08:23 UTC · model grok-4.3
The pith
Merging past posteriors creates priors that slow knowledge drift while enabling fast VCL updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
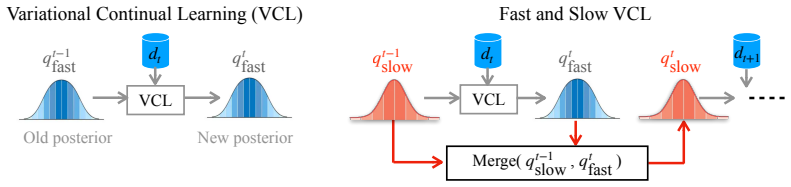
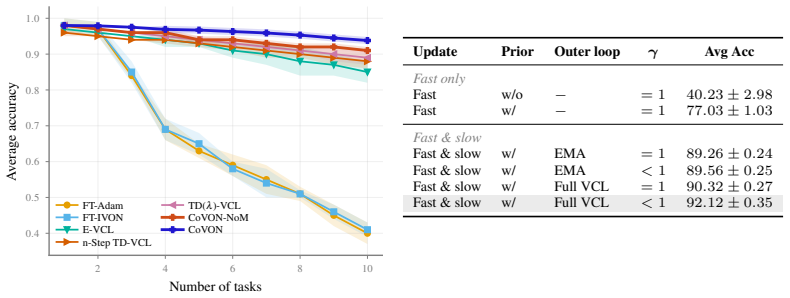
Merging past posteriors slows the drift in knowledge as learning progresses, and the merged posterior then serves as the prior in the VCL update to realize fast-weight updates. These steps integrate directly into the IVON optimizer to yield the CoVON optimizer, which improves over prior VCL methods and other weight-regularization approaches across the evaluated continual learning settings.
What carries the argument
Merging of past posteriors to produce the prior used in each VCL update step inside the CoVON optimizer derived from IVON.
If this is right
- CoVON improves performance over existing VCL optimizers in domain-incremental learning.
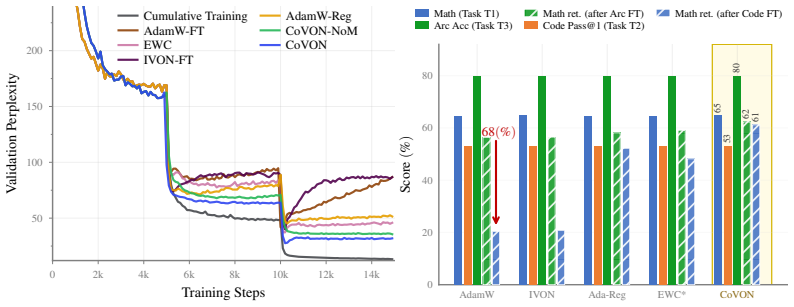
- It outperforms other weight-regularization strategies during continual pre-training.
- It yields better results than baselines when fine-tuning large language models.
- The optimizer retains nearly the same form and computational cost as Adam.
Where Pith is reading between the lines
- The merging step could be ported to other variational continual learning optimizers beyond those based on IVON.
- The same slow-fast structure might apply to non-variational continual learning methods that already maintain some form of posterior or momentum state.
- If the merging operation generalizes, it offers a route to continual adaptation in streaming settings without explicit task boundaries.
Load-bearing premise
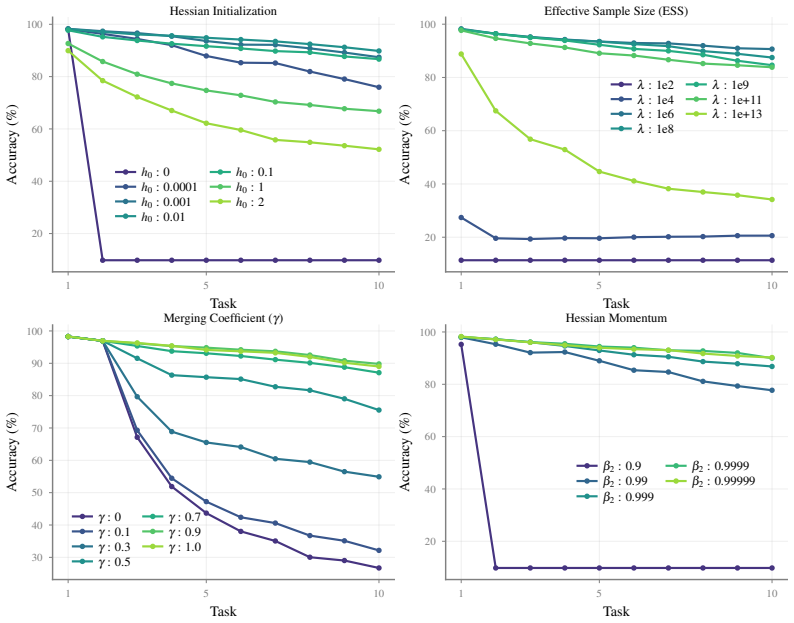
Merging past posteriors reliably yields a prior that slows subsequent knowledge drift without causing new forgetting or demanding task-specific tuning.
What would settle it
An experiment on any of the paper's benchmarks where CoVON produces the same or higher forgetting rates and lower accuracy than standard VCL would show the merging step does not deliver the claimed benefit.
Figures
read the original abstract
Continual learning remains a major challenge for modern deep networks, partly because commonly used optimizers lack inherent mechanisms for continual adaptation. One such natural mechanism is fast and slow adaptation to balance stability and plasticity. This mechanism has deep roots in neuroscience and biology, but there is no consensus on how to best incorporate it in commonly used optimizers. Here, we show that this can be easily done via the VCL framework, where past posteriors are used as priors in the future. Our key idea is to incorporate slow adaptation via merging of past posteriors to slow down the drift in the knowledge as learning progresses. The merged posterior is then used as the prior in the VCL update to implement the fast-weight updates. These steps can be seamlessly implemented in the IVON optimizer, whose form and costs are nearly identical to that of Adam. We call this new optimizer the Continual IVON (CoVON) optimizer and show that it not only consistently improves over existing VCL optimizers, but also performs better than other weight-regularization strategies across domain-incremental learning, continual pre-training, and fine-tuning of large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoVON, a variant of the IVON optimizer within the variational continual learning (VCL) framework. It incorporates slow adaptation by merging past posteriors to form a prior that slows knowledge drift, then uses this prior for fast-weight VCL updates. The method is claimed to be seamlessly implementable with costs similar to Adam and to deliver consistent gains over prior VCL optimizers and other weight-regularization baselines across domain-incremental learning, continual pre-training, and LLM fine-tuning.
Significance. If the empirical claims hold and the merging step proves general, the work supplies a low-overhead mechanism for balancing stability and plasticity inside a standard optimizer, which could be useful for sequential training of large models. The near-identical cost to Adam and the reuse of the existing VCL posterior-as-prior construction are practical strengths.
major comments (2)
- [Abstract] Abstract: the central mechanism—'merging of past posteriors' to produce the slow-adaptation prior—is stated at a high level only. No functional form (weighted average, product of Gaussians, moment matching, etc.), no derivation showing the result remains a valid regularizer under domain shift, and no analysis of whether the merge introduces order-dependent or sequence-specific hyperparameters are supplied. Because this operation is load-bearing for both the 'slows knowledge drift' claim and the 'no task-specific tuning' assertion, its underspecification prevents verification that performance differences arise from the fast-slow principle rather than from the choice of merge.
- [Abstract] The VCL posterior-as-prior construction is inherited without additional justification that the merged prior reliably slows drift without new forgetting; the abstract supplies no quantitative results, ablation studies, or error bars to support the 'consistent improvements' claim, leaving the soundness of the central empirical assertion unassessable from the provided text.
minor comments (1)
- [Abstract] Abstract: the phrase 'seamlessly implemented in the IVON optimizer' would benefit from a one-sentence clarification of the exact code-level change required.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract point by point below, clarifying the manuscript content and indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central mechanism—'merging of past posteriors' to produce the slow-adaptation prior—is stated at a high level only. No functional form (weighted average, product of Gaussians, moment matching, etc.), no derivation showing the result remains a valid regularizer under domain shift, and no analysis of whether the merge introduces order-dependent or sequence-specific hyperparameters are supplied. Because this operation is load-bearing for both the 'slows knowledge drift' claim and the 'no task-specific tuning' assertion, its underspecification prevents verification that performance differences arise from the fast-slow principle rather than from the choice of merge.
Authors: The abstract provides a high-level summary consistent with its length constraints. The functional form is moment matching of the Gaussian posteriors, the derivation that the result remains a valid regularizer is given in Section 3.2, and the analysis confirming no new order-dependent hyperparameters is in Section 3.3. We will revise the abstract to include one sentence specifying the moment-matching merge and referencing the section for the derivation. revision: yes
-
Referee: [Abstract] The VCL posterior-as-prior construction is inherited without additional justification that the merged prior reliably slows drift without new forgetting; the abstract supplies no quantitative results, ablation studies, or error bars to support the 'consistent improvements' claim, leaving the soundness of the central empirical assertion unassessable from the provided text.
Authors: Abstracts conventionally omit detailed quantitative results, ablations, and error bars; these appear in Sections 4–6 with multiple runs, error bars, and statistical tests demonstrating reduced forgetting and consistent gains. The merged prior's effect on drift is justified both by the VCL construction (Section 2) and by the reported experiments. We will add a short clause to the abstract noting that the stability-plasticity benefits are empirically validated in the main text. revision: partial
Circularity Check
No significant circularity; method is an empirical extension of VCL
full rationale
The paper proposes CoVON as a practical modification to the existing VCL framework by adding a merging step for past posteriors to implement slow adaptation. This is presented as a design choice implemented in the IVON optimizer, with performance claims resting on empirical comparisons across domain-incremental, continual pre-training, and LLM fine-tuning tasks rather than any first-principles derivation or prediction that reduces to the inputs by construction. No equations or uniqueness theorems are invoked that would trigger self-definitional, fitted-input, or self-citation load-bearing patterns. The merging operation is introduced as the novel mechanism, not presupposed as its own output.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Merging of past posteriors produces a usable prior that slows parameter drift while preserving the fast-update properties of IVON
Reference graph
Works this paper leans on
-
[1]
Constrained optimization and
Bertsekas, Dimitri P , year =. Constrained optimization and
-
[2]
and Bodard, Alexander and Laude, Emanuel and Patrinos, Panagiotis , year =
Oikonomidis, Konstantinos A. and Bodard, Alexander and Laude, Emanuel and Patrinos, Panagiotis , year =. Global convergence analysis of the power proximal point and augmented Lagrangian method , volume =. Computational Optimization and Applications , publisher =
-
[3]
icml, , year =
Mishchenko, Konstantin and Malinovsky, Grigory and Stich, Sebastian and Richt. icml, , year =
-
[4]
Federated Learning Via Inexact
Zhou, Shenglong and Li, Geoffrey Ye , journal =. Federated Learning Via Inexact. 2023 , volume =
2023
-
[5]
2021 , volume =
Zhang, Xinwei and Hong, Mingyi and Dhople, Sairaj and Yin, Wotao and Liu, Yang , journal =. 2021 , volume =
2021
-
[6]
, booktitle =
Gong, Yonghai and Li, Yichuan and Freris, Nikolaos M. , booktitle =
-
[7]
Mutambara, Arthur G. O. , title =. 1998 , isbn =
1998
-
[8]
aistats, , year =
Communication-Efficient Learning of Deep Networks from Decentralized Data , author =. aistats, , year =
-
[9]
Federated Optimization in Heterogeneous Networks , year =
Li, Tian and Sahu, Anit Kumar and Zaheer, Manzil and Sanjabi, Maziar and Talwalkar, Ameet and Smith, Virginia , booktitle =. Federated Optimization in Heterogeneous Networks , year =
-
[10]
iclr, , year =
Federated Learning as Variational Inference: A Scalable Expectation Propagation Approach , author =. iclr, , year =
-
[11]
Han Wang and Siddartha Marella and James Anderson , journal =. Fed
-
[12]
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization , booktitle =
Hendrycks, Dan and Basart, Steven and Mu, Norman and Kadavath, Saurav and Wang, Frank and Dorundo, Evan and Desai, Rahul and Zhu, Tyler and Parajuli, Samyak and Guo, Mike and Song, Dawn and Steinhardt, Jacob and Gilmer, Justin , year =. The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization , booktitle =
-
[13]
International Conference on Information Fusion , year =
Data fusion in decentralised sensing networks , author =. International Conference on Information Fusion , year =
-
[14]
Babagholami-Mohamadabadi, Behnam and Yoon, Sejong and Pavlovic, Vladimir , journal=
-
[15]
Federated Learning via Posterior Averaging: A New Perspective and Practical Algorithms , author=
-
[16]
Federated Learning Based on Dynamic Regularization , author=
-
[17]
Variational learning is effective for large deep networks , author=
-
[18]
Caldarola, Debora and Caputo, Barbara and Ciccone, Marco , booktitle = eccv, title =
-
[19]
Qu, Zhe and Li, Xingyu and Duan, Rui and Liu, Yao and Tang, Bo and Lu, Zhuo , booktitle = icml, title =
-
[20]
Fan, Ziqing and Hu, Shengchao and Yao, Jiangchao and Niu, Gang and Zhang, Ya and Sugiyama, Masashi and Wang, Yanfeng , booktitle = icml, title =
-
[21]
Nonlinear proximal point algorithms using
Eckstein, Jonathan , journal =. Nonlinear proximal point algorithms using
-
[22]
Wang, Huahua and Banerjee, Arindam , journal = nips, title =
-
[23]
Applications of a splitting algorithm to decomposition in convex programming and variational inequalities , volume =
Tseng, Paul , journal = siconopt, number =. Applications of a splitting algorithm to decomposition in convex programming and variational inequalities , volume =
-
[24]
A dual algorithm for the solution of nonlinear variational problems via finite element approximation , volume =
Gabay, Daniel and Mercier, Bertrand , journal =. A dual algorithm for the solution of nonlinear variational problems via finite element approximation , volume =
-
[25]
Sur l'approximation, par
Glowinski, Roland and Marroco, Americo , journal =. Sur l'approximation, par
-
[26]
Zhu, Jia-Jie and Mielke, Alexander , title =
-
[27]
Gradient flows for sampling: mean-field models,
Chen, Yifan and Huang, Daniel Zhengyu and Huang, Jiaoyang and Reich, Sebastian and Stuart, Andrew M , journal =. Gradient flows for sampling: mean-field models,
-
[28]
Learning without forgetting , author=
-
[29]
Zifeng Wang and Zizhao Zhang and Sayna Ebrahimi and Ruoxi Sun and Han Zhang and Chen-Yu Lee and Xiaoqi Ren and Guolong Su and Vincent Perot and Jennifer Dy and Tomas Pfister , year=
-
[30]
Learning to Prompt for Continual Learning , author=
-
[31]
Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning , author=
-
[32]
Non-exemplar domain incremental learning via cross-domain concept integration , author=
-
[33]
S-prompts learning with pre-trained transformers: An
Wang, Yabin and Huang, Zhiwu and Hong, Xiaopeng , booktitle=nips, year=. S-prompts learning with pre-trained transformers: An
-
[34]
Conference on Robot Learning (CoRL) , year=
Core50: a new dataset and benchmark for continuous object recognition , author=. Conference on Robot Learning (CoRL) , year=
-
[35]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year=
A continual deepfake detection benchmark: Dataset, methods, and essentials , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year=
-
[36]
Moment matching for multi-source domain adaptation , author=
-
[37]
Stephenson, Will and Frangella, Zachary and Udell, Madeleine and Broderick, Tamara , journal = nips, title =
-
[38]
Introduction to stochastic search and optimization: estimation, simulation, and control , year =
Spall, James C , publisher =. Introduction to stochastic search and optimization: estimation, simulation, and control , year =
-
[39]
Kiral, Eren Mehmet and M. The
-
[40]
Mohamed, Shakir and Rosca, Mihaela and Figurnov, Michael and Mnih, Andriy , journal = jmlr, number =. Monte
-
[41]
Figurnov, Mikhail and Mohamed, Shakir and Mnih, Andriy , booktitle = nips, title =
-
[42]
On the Convergence of IRLS and Its Variants in Outlier-Robust Estimation , year =
Peng, Liangzu and K. On the Convergence of IRLS and Its Variants in Outlier-Robust Estimation , year =
-
[43]
Yang, Rubing and Mao, Jialin and Chaudhari, Pratik , booktitle = icml, title =
-
[44]
Control systems and reinforcement learning , year =
Meyn, Sean , publisher =. Control systems and reinforcement learning , year =
-
[45]
Statistical learning theory and stochastic optimization , year =
Catoni, Olivier , publisher =. Statistical learning theory and stochastic optimization , year =
-
[46]
Generalization Guarantees via Algorithm-dependent
Sachs, Sarah and van Erven, Tim and Hodgkinson, Liam and Khanna, Rajiv and. Generalization Guarantees via Algorithm-dependent
-
[47]
Sefidgaran, Milad and Gohari, Amin and Richard, Gael and Simsekli, Umut , booktitle = colt, title =
-
[48]
Arora, Sanjeev and Ge, Rong and Neyshabur, Behnam and Zhang, Yi , booktitle = icml, title =
-
[49]
Suzuki, Taiji and Abe, Hiroshi and Nishimura, Tomoaki , booktitle = iclr, title =
-
[50]
Spectral pruning: Compressing deep neural networks via spectral analysis and its generalization error , year =
Suzuki, Taiji and Abe, Hiroshi and Murata, Tomoya and Horiuchi, Shingo and Ito, Kotaro and Wachi, Tokuma and Hirai, So and Yukishima, Masatoshi and Nishimura, Tomoaki , booktitle =. Spectral pruning: Compressing deep neural networks via spectral analysis and its generalization error , year =
-
[51]
Barsbey, Melih and Sefidgaran, Milad and Erdogdu, Murat A and Richard, Gael and Simsekli, Umut , journal = nips, title =
-
[52]
Burke, James V and Ferris, Michael C , journal = mp, number =. A
-
[53]
Harmonic exponential families on homogeneous spaces , volume =
Tojo, Koichi and Yoshino, Taro , journal =. Harmonic exponential families on homogeneous spaces , volume =
-
[54]
Duality for Neural Networks through Reproducing Kernel
Spek, Len and Heeringa, Tjeerd Jan and Brune, Christoph , journal =. Duality for Neural Networks through Reproducing Kernel
-
[55]
Approximation accuracy, gradient methods, and error bound for structured convex optimization , volume =
Tseng, Paul , journal = mp, number =. Approximation accuracy, gradient methods, and error bound for structured convex optimization , volume =
-
[56]
Welling, Max and Teh, Yee W , booktitle = icml, title =
-
[57]
SAE: Sequential Anchored Ensembles , year =
Delaunoy, Arnaud and Louppe, Gilles , journal =. SAE: Sequential Anchored Ensembles , year =
-
[58]
Decoupled Weight Decay Regularization , author=
-
[59]
Gupta, Vineet and Koren, Tomer and Singer, Yoram , booktitle = icml, title =
-
[60]
A stochastic approximation method , year =
Robbins, Herbert and Monro, Sutton , journal =. A stochastic approximation method , year =
-
[61]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, Lukasz and Polosukhin, Illia , journal = nips, title =
-
[62]
Lambert, Marc and Chewi, Sinho and Bach, Francis and Bonnabel, Silv. arXiv:2205.15902 , title =
-
[63]
Minimax in Geodesic Metric Spaces: Sion's Theorem and Algorithms , year =
Zhang, Peiyuan and Zhang, Jingzhao and Sra, Suvrit , journal =. Minimax in Geodesic Metric Spaces: Sion's Theorem and Algorithms , year =
-
[64]
Linear convergence of gradient and proximal-gradient methods under the
Karimi, Hamed and Nutini, Julie and Schmidt, Mark , booktitle =. Linear convergence of gradient and proximal-gradient methods under the
-
[65]
Lifting the convex conjugate in
Bauermeister, Hartmut and Laude, Emanuel and Mollenhoff, Thomas and Moeller, Michael and Cremers, Daniel , journal = siims, number =. Lifting the convex conjugate in
-
[66]
Bayesian neural network priors revisited , year =
Fortuin, Vincent and Garriga-Alonso, Adri. Bayesian neural network priors revisited , year =
-
[67]
Coker, Beau and Bruinsma, Wessel P and Burt, David R and Pan, Weiwei and Doshi-Velez, Finale , booktitle = aistats, title =
-
[68]
On the expressiveness of approximate inference in
Foong, Andrew and Burt, David and Li, Yingzhen and Turner, Richard , journal =. On the expressiveness of approximate inference in
-
[69]
Priors in
Fortuin, Vincent , journal =. Priors in
-
[70]
Zhang, Tong , booktitle = colt, title =
-
[71]
Adversarial Interpretation of
Husain, Hisham and Knoblauch, Jeremias , booktitle =. Adversarial Interpretation of
-
[72]
Stochastic dual coordinate ascent methods for regularized loss minimization
Shalev-Shwartz, Shai and Zhang, Tong , journal = jmlr, number =. Stochastic dual coordinate ascent methods for regularized loss minimization. , volume =
-
[73]
Deep learning in neural networks: An overview , volume =
Schmidhuber, J. Deep learning in neural networks: An overview , volume =. Neural networks , pages =
-
[74]
Deep learning , volume =
LeCun, Yann and Bengio, Yoshua and Hinton, Geoffrey , journal =. Deep learning , volume =
-
[75]
Evaluating Approximate Inference in
Wilson, Andrew Gordon and Izmailov, Pavel and Hoffman, Matthew D and Gal, Yarin and Li, Yingzhen and Pradier, Melanie F and Vikram, Sharad and Foong, Andrew and Lotfi, Sanae and Farquhar, Sebastian , booktitle =. Evaluating Approximate Inference in
-
[76]
Amid, Ehsan and Anil, Rohan and Warmuth, Manfred , booktitle = aistats, title =
-
[77]
Stochastic gradient descent as approximate
Mandt, Stephan and Hoffman, Matthew D and Blei, David M , journal = jmlr, pages =. Stochastic gradient descent as approximate
-
[78]
Khan, Mohammad Emtiyaz and Mohamed, Shakir and Marlin, Benjamin and Murphy, Kevin , booktitle = aistats, title =
-
[79]
Questions for Flat-Minima Optimization of Modern Neural Networks , year =
Kaddour, Jean and Liu, Linqing and Silva, Ricardo and Kusner, Matt J , journal =. Questions for Flat-Minima Optimization of Modern Neural Networks , year =
-
[80]
Guo, Chuan and Pleiss, Geoff and Sun, Yu and Weinberger, Kilian Q , booktitle = icml, title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.