PixJail: Self-Evolving Paper-to-Pipeline Reproduction for Text-to-Image Jailbreak Evaluation
Pith reviewed 2026-06-25 23:46 UTC · model grok-4.3
The pith
PixJail converts T2I jailbreak papers into runnable evaluation pipelines that recover original attack success rates with 2.1 percent average error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
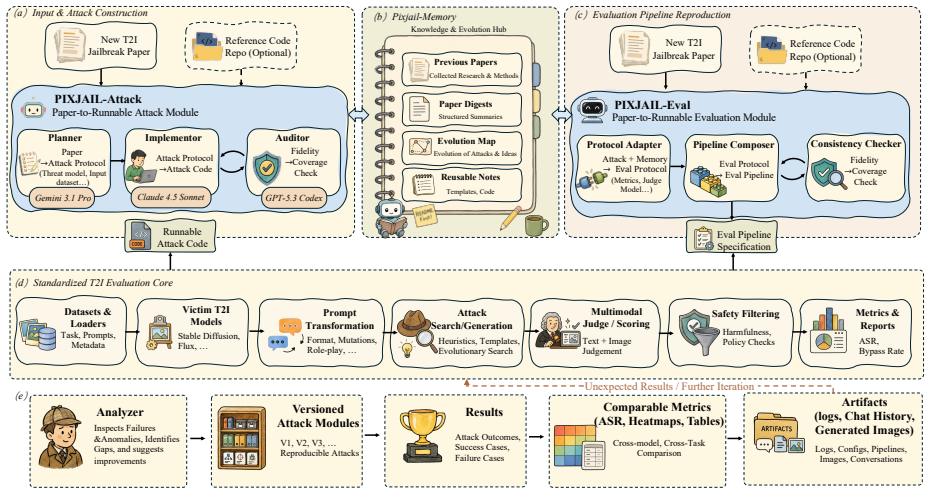
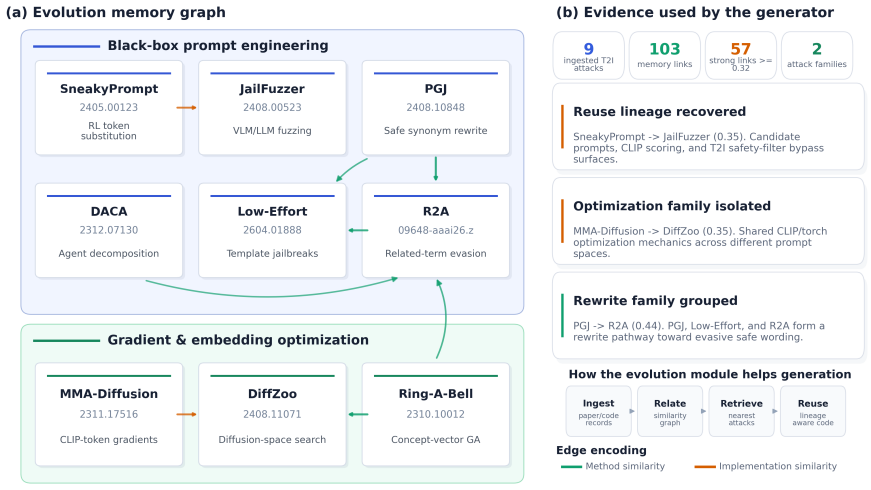
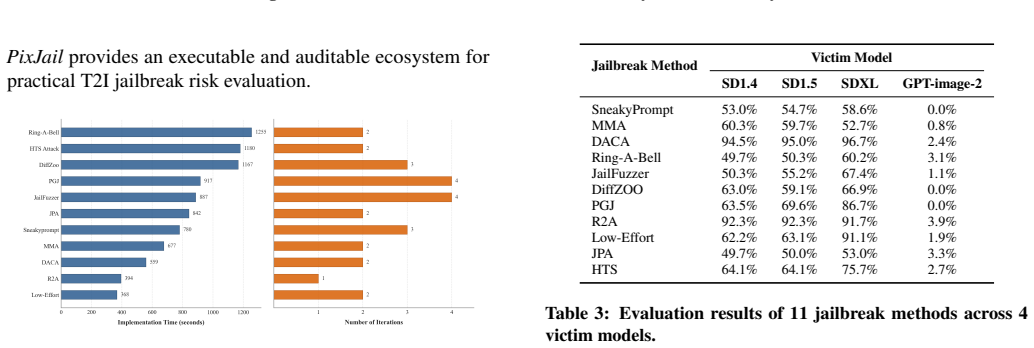
PixJail is a self-evolving paper-to-pipeline agent framework for reproducible T2I jailbreak evaluation. Given a T2I jailbreak paper and optional reference code, it rapidly constructs a paper-specific attack module and a runnable evaluation pipeline under a unified contract. The framework maintains a memory bank that stores paper digests, attack evolution patterns, reusable templates, failure cases, and versioned artifacts. When applied to eleven representative methods under their original settings, it recovers the reported results with 2.1 percent average error and 0 percent median error.
What carries the argument
The self-evolving paper-to-pipeline agent framework that builds attack modules and evaluation pipelines under a unified contract while maintaining a memory bank of reusable artifacts.
If this is right
- Attack success rates from different papers become directly comparable because every pipeline follows the same contract.
- Reproduction of both code-available and code-unavailable papers can be performed with the same workflow.
- The memory bank allows each new reproduction to reuse prior templates and avoid repeating past failures.
- Overall manual effort required to evaluate new T2I jailbreak techniques drops substantially.
- Versioned artifacts stored by the system support consistent re-runs when safety filters or generators are updated.
Where Pith is reading between the lines
- The same agent pattern could be applied to reproduce pipelines in other multimodal safety domains such as video or audio generation.
- Accumulated patterns in the memory bank might eventually support automatic generation of hybrid attacks that combine elements from multiple prior papers.
- Widespread use would create a de-facto public repository of standardized T2I evaluation pipelines that any researcher could invoke.
- If the reproduction error remains low on new papers, the framework could serve as an automated referee for claims made in future T2I jailbreak submissions.
Load-bearing premise
The agent system can correctly interpret and faithfully implement the methods described in papers without introducing deviations that change the reproduced attack success rates.
What would settle it
Running PixJail on a fresh T2I jailbreak paper outside the original eleven and comparing its output attack success rate against an independent human reimplementation of the same paper.
Figures
read the original abstract
As Text-to-Image (T2I) jailbreak techniques evolve rapidly, existing benchmarks and reproduction workflows often struggle to keep pace. More importantly, T2I jailbreak evaluation is not a single prompt-level test, but a pipeline-level problem shaped by multiple stages, including prompt transformation, image generation, safety filtering, and multimodal judging. This makes results across papers difficult to reliably reproduce and fairly compare. To bridge this gap, we propose PixJail, a self-evolving paper-to-pipeline agent framework for reproducible T2I jailbreak evaluation. Given a T2I jailbreak paper and optional reference code, PixJail rapidly constructs a paper-specific attack module and a runnable evaluation pipeline under a unified contract, while faithfully reproducing the original experimental results. PixJail further maintains a memory bank that stores paper digests, attack evolution patterns, reusable templates, failure cases, and versioned artifacts, enabling future reproduction efforts to reuse prior experience. We reproduce eleven representative T2I jailbreak methods, including both code-available and code-unavailable papers. Under their original settings, our framework accurately recovers prior results with minimal error (2.1\% average, 0\% median). We hope that PixJail can serve as a unified foundation for future T2I jailbreak reproduction and evaluation, significantly reducing manual effort.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PixJail, a self-evolving LLM-agent framework that, given a T2I jailbreak paper and optional reference code, constructs a paper-specific attack module and runnable evaluation pipeline under a unified contract. It claims to reproduce results from eleven representative methods (code-available and code-unavailable) under their original settings with 2.1% average error (0% median), while maintaining a memory bank of paper digests, attack patterns, templates, failure cases, and artifacts to support future reuse.
Significance. If the reproductions prove faithful, the framework addresses a genuine need for standardized, pipeline-level evaluation of T2I jailbreaks that involve prompt transformation, generation, safety filtering, and multimodal judging. The memory-bank mechanism for self-evolution could reduce repeated manual effort if concrete reuse examples are demonstrated.
major comments (2)
- [Abstract] Abstract: the headline claim of faithful reproduction with 2.1% average error across eleven methods rests solely on the aggregate statistic. No per-method error rates, generated attack modules, reasoning traces, prompt histories, or step-by-step comparisons of algorithmic components (prompt transformation, safety filter, judge) against the source papers are referenced, leaving open the possibility that deviations in any pipeline stage are masked by the unified contract.
- [Abstract] Abstract: the memory bank is described as storing 'paper digests, attack evolution patterns, reusable templates, failure cases, and versioned artifacts' to enable self-evolution, yet the manuscript provides neither concrete examples of stored artifacts nor any evaluation measuring reuse effectiveness or reduction in reproduction effort across the eleven methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of faithful reproduction with 2.1% average error across eleven methods rests solely on the aggregate statistic. No per-method error rates, generated attack modules, reasoning traces, prompt histories, or step-by-step comparisons of algorithmic components (prompt transformation, safety filter, judge) against the source papers are referenced, leaving open the possibility that deviations in any pipeline stage are masked by the unified contract.
Authors: We agree that the aggregate statistic alone leaves the reproduction claims open to the concern raised. In the revised manuscript we will add a per-method error table, selected examples of generated attack modules with reasoning traces, and component-wise comparisons (prompt transformation, safety filter, judge) against the source papers, placed in Section 4 and an appendix. revision: yes
-
Referee: [Abstract] Abstract: the memory bank is described as storing 'paper digests, attack evolution patterns, reusable templates, failure cases, and versioned artifacts' to enable self-evolution, yet the manuscript provides neither concrete examples of stored artifacts nor any evaluation measuring reuse effectiveness or reduction in reproduction effort across the eleven methods.
Authors: We agree that concrete examples of stored artifacts and a quantitative evaluation of reuse effectiveness are needed to substantiate the self-evolution claim. We will add specific examples drawn from the eleven reproductions and an analysis measuring reduction in reproduction effort in the revised manuscript. revision: yes
Circularity Check
No circularity; empirical reproduction validated against external published results
full rationale
The paper presents an agent-based framework whose central claim is empirical reproduction accuracy (2.1% average error) measured against independently published prior results for eleven T2I jailbreak methods. No mathematical derivation, prediction, or first-principles result is offered that reduces to its own inputs by construction. No self-citation chain is invoked to justify uniqueness or forbid alternatives. The reproduction pipeline is an external tool whose performance is assessed by direct numerical comparison to source papers; any implementation deviations would appear as error rather than being masked by definition. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based agents can reliably parse and implement complex research methods from papers into code pipelines.
invented entities (1)
-
Memory bank
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Diffzoo: A purely query-based black-box attack for red-teaming text-to-image generative model via zeroth order optimization, 2025
Pucheng Dang, Xing Hu, Dong Li, Rui Zhang, Qi Guo, and Kaidi Xu. Diffzoo: A purely query-based black-box attack for red-teaming text-to-image generative model via zeroth order optimization, 2025. 6
2025
-
[2]
Harnessing llm to attack llm-guarded text-to-image models, 2024
Yimo Deng and Huangxun Chen. Harnessing llm to attack llm-guarded text-to-image models, 2024. 5, 6
2024
-
[3]
Fuzz-testing meets llm-based agents: An automated and efficient framework for jailbreaking text- to-image generation models
Yingkai Dong, Xiangtao Meng, Ning Yu, Zheng Li, and Shanqing Guo. Fuzz-testing meets llm-based agents: An automated and efficient framework for jailbreaking text- to-image generation models. In2025 IEEE Symposium on Security and Privacy (SP), pages 373–391. IEEE,
-
[4]
Zhicheng Fang, Jingjie Zheng, Chenxu Fu, and Wei Xu. Jailbreak foundry: From papers to runnable at- tacks for reproducible benchmarking.arXiv preprint arXiv:2602.24009, 2026. 1, 2
arXiv 2026
-
[5]
Hts- attack: Heuristic token search for jailbreaking text-to- image models, 2024
Sensen Gao, Xiaojun Jia, Yihao Huang, Ranjie Duan, Jindong Gu, Yang Bai, Yang Liu, and Qing Guo. Hts- attack: Heuristic token search for jailbreaking text-to- image models, 2024. 6
2024
-
[6]
Alireza Ghafarollahi and Markus J. Buehler. Sciagents: Automating scientific discovery through multi-agent in- telligent graph reasoning, 2024. 2
2024
-
[7]
Perception-guided jailbreak against text-to-image mod- els, 2025
Yihao Huang, Le Liang, Tianlin Li, Xiaojun Jia, Run Wang, Weikai Miao, Geguang Pu, and Yang Liu. Perception-guided jailbreak against text-to-image mod- els, 2025. 6
2025
-
[8]
Jailbreaking safe- guarded text-to-image models via large language mod- els
Zhengyuan Jiang, Yuepeng Hu, Yuchen Yang, Yinzhi Cao, and Neil Zhenqiang Gong. Jailbreaking safe- guarded text-to-image models via large language mod- els. InFindings of the Association for Computational Linguistics: EACL 2026, pages 4669–4684, 2026. 2
2026
-
[9]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024. 2
2024
-
[10]
Jailbreakdiffbench: A comprehensive benchmark for jailbreaking diffusion models
Xiaolong Jin, Zixuan Weng, Hanxi Guo, Chenlong Yin, Siyuan Cheng, Guangyu Shen, and Xiangyu Zhang. Jailbreakdiffbench: A comprehensive benchmark for jailbreaking diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 16461–16471, 2025. 1
2025
-
[11]
Xuannan Liu, Xing Cui, Peipei Li, Zekun Li, Huaibo Huang, Shuhan Xia, Miaoxuan Zhang, Yueying Zou, and Ran He. Jailbreak attacks and defenses against multimodal generative models: A survey.arXiv preprint arXiv:2411.09259, 2024. 1, 2
arXiv 2024
-
[12]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024. 2
Pith/arXiv arXiv 2024
-
[13]
Jiachen Ma, Yijiang Li, Zhiqing Xiao, Anda Cao, Jie Zhang, Chao Ye, and Junbo Zhao. Jailbreaking prompt attack: A controllable adversarial attack against diffu- sion models.arXiv preprint arXiv:2404.02928, 2024. 6
arXiv 2024
-
[14]
Low-effort jailbreak attacks against text-to-image safety filters, 2026
Ahmed B Mustafa, Zihan Ye, Yang Lu, Michael P Pound, and Shreyank N Gowda. Low-effort jailbreak attacks against text-to-image safety filters, 2026. 6
2026
-
[15]
Gpt-5 technical report: Advanced reasoning and analysis
OpenAI. Gpt-5 technical report: Advanced reasoning and analysis. https://www.openai.com/, 2026. Ac- cessed: 2026-05. 6 8
2026
-
[16]
Introducing ChatGPT Images 2.0
OpenAI. Introducing ChatGPT Images 2.0. https://openai.com/index/introducing- chatgpt-images-2-0/ , 2026. Accessed: 2026- 05-26. 6
2026
-
[17]
Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. 5, 6
2023
-
[18]
Towards scientific intelligence: A survey of llm-based scientific agents, 2026
Shuo Ren, Can Xie, Pu Jian, Zhenjiang Ren, Chunlin Leng, and Jiajun Zhang. Towards scientific intelligence: A survey of llm-based scientific agents, 2026. 2
2026
-
[19]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 5, 6
2022
-
[20]
Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025. 2
2025
-
[21]
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InPro- ceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 22522–22531, 2023. 1, 5
2023
-
[22]
Minju Seo, Jinheon Baek, Seongyun Lee, and Sung Ju Hwang. Paper2code: Automating code generation from scientific papers in machine learning.arXiv preprint arXiv:2504.17192, 2025. 2
arXiv 2025
-
[23]
Zachary S Siegel, Sayash Kapoor, Nitya Nagdir, Benedikt Stroebl, and Arvind Narayanan. Core-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark.arXiv preprint arXiv:2409.11363, 2024. 2
Pith/arXiv arXiv 2024
-
[24]
Pa- perbench: Evaluating ai’s ability to replicate ai research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, et al. Pa- perbench: Evaluating ai’s ability to replicate ai research. arXiv preprint arXiv:2504.01848, 2025. 2
Pith/arXiv arXiv 2025
-
[25]
Zhen Sun, Zongmin Zhang, Deqi Liang, Han Sun, Yule Liu, Yun Shen, Xiangshan Gao, Yilong Yang, Shuai Liu, Yutao Yue, et al. "To Survive, I Must Defect": Jailbreaking llms via the game-theory scenarios.arXiv preprint arXiv:2511.16278, 2025. 2
arXiv 2025
-
[26]
Ring-a-bell! how reliable are con- cept removal methods for diffusion models? InInterna- tional Conference on Learning Representations, volume 2024, pages 41543–41554, 2024
Yu-Lin Tsai, Chia-Yi Hsu, Chulin Xie, Chih-Hsun Lin, Jia You Chen, Bo Li, Pin-Yu Chen, Chia-Mu Yu, and Chun-Ying Huang. Ring-a-bell! how reliable are con- cept removal methods for diffusion models? InInterna- tional Conference on Learning Representations, volume 2024, pages 41543–41554, 2024. 2, 6
2024
-
[27]
Genbreak: Red teaming text-to-image generation using large language models
Zilong Wang, Xiang Zheng, Xiaosen Wang, Bo Wang, and Xingjun Ma. Genbreak: Red teaming text-to-image generation using large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15730–15739, 2026. 2
2026
-
[28]
Gonzalez, Boyi Li, and Trevor Darrell
Tsung-Han Wu, Long Lian, Joseph E. Gonzalez, Boyi Li, and Trevor Darrell. Self-correcting llm-controlled diffusion models, 2023. 5
2023
-
[29]
Diffusion models: A comprehensive survey of methods and applications.ACM computing surveys, 56(4):1–39, 2023
Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming-Hsuan Yang. Diffusion models: A comprehensive survey of methods and applications.ACM computing surveys, 56(4):1–39, 2023. 1
2023
-
[30]
Mma-diffusion: Multi- modal attack on diffusion models
Yijun Yang, Ruiyuan Gao, Xiaosen Wang, Tsung-Yi Ho, Nan Xu, and Qiang Xu. Mma-diffusion: Multi- modal attack on diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7737–7746, 2024. 1, 2, 5, 6
2024
-
[31]
Sneakyprompt: Jailbreaking text-to-image generative models
Yuchen Yang, Bo Hui, Haolin Yuan, Neil Gong, and Yinzhi Cao. Sneakyprompt: Jailbreaking text-to-image generative models. In2024 IEEE symposium on security and privacy (SP), pages 897–912. IEEE, 2024. 1, 2, 5, 6
2024
-
[32]
Jailbreak attacks and defenses against large language models: A survey
Sibo Yi, Yule Liu, Zhen Sun, Tianshuo Cong, Xinlei He, Jiaxing Song, Ke Xu, and Qi Li. Jailbreak attacks and defenses against large language models: A survey. arXiv preprint arXiv:2407.04295, 2024. 1, 2
Pith/arXiv arXiv 2024
-
[33]
Reason2attack: Jailbreaking text-to- image models via llm reasoning, 2025
Chenyu Zhang, Lanjun Wang, Yiwen Ma, Wenhui Li, and An-An Liu. Reason2attack: Jailbreaking text-to- image models via llm reasoning, 2025. 6
2025
-
[34]
T2i-riskyprompt: A benchmark for safety evaluation, attack, and defense on text-to-image model
Chenyu Zhang, Tairen Zhang, Lanjun Wang, Ruidong Chen, Wenhui Li, and Anan Liu. T2i-riskyprompt: A benchmark for safety evaluation, attack, and defense on text-to-image model. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 36039–36047, 2026. 2
2026
-
[35]
Ziyi Zhang, Zhen Sun, Zongmin Zhang, Jihui Guo, and Xinlei He. Fc-attack: Jailbreaking multimodal large language models via auto-generated flowcharts.arXiv preprint ArXiv:2502.21059, 2025. 2
arXiv 2025
-
[36]
Universal and trans- ferable adversarial attacks on aligned language models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and trans- ferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023. 2 A Prompt Design To ensure an unbiased, rigorous, and reproducible evaluation of the code generated from research papers, we developed a structured eval...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.