CompressKV: Semantic-Retrieval-Guided KV-Cache Compression for Resource-Efficient Long-Context LLM Inference
Pith reviewed 2026-06-26 00:10 UTC · model grok-4.3
The pith
CompressKV identifies Semantic Retrieval Heads to compress KV cache to 3% size while retaining over 97% of full performance on long-context tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
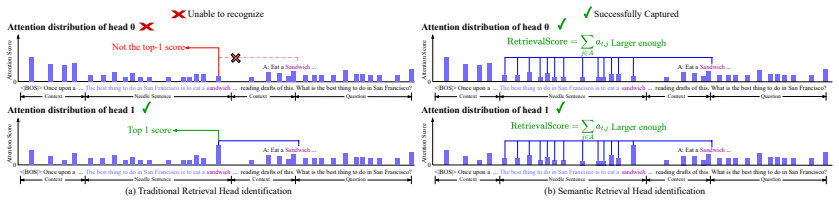
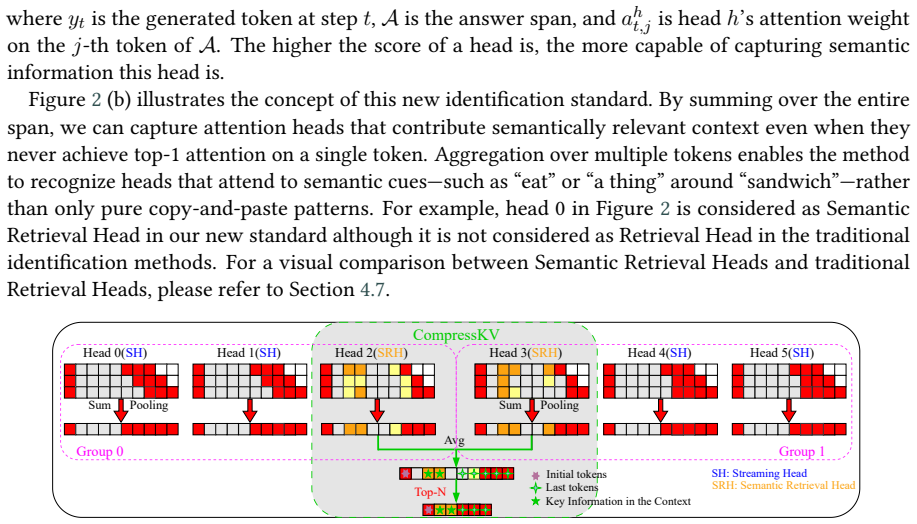
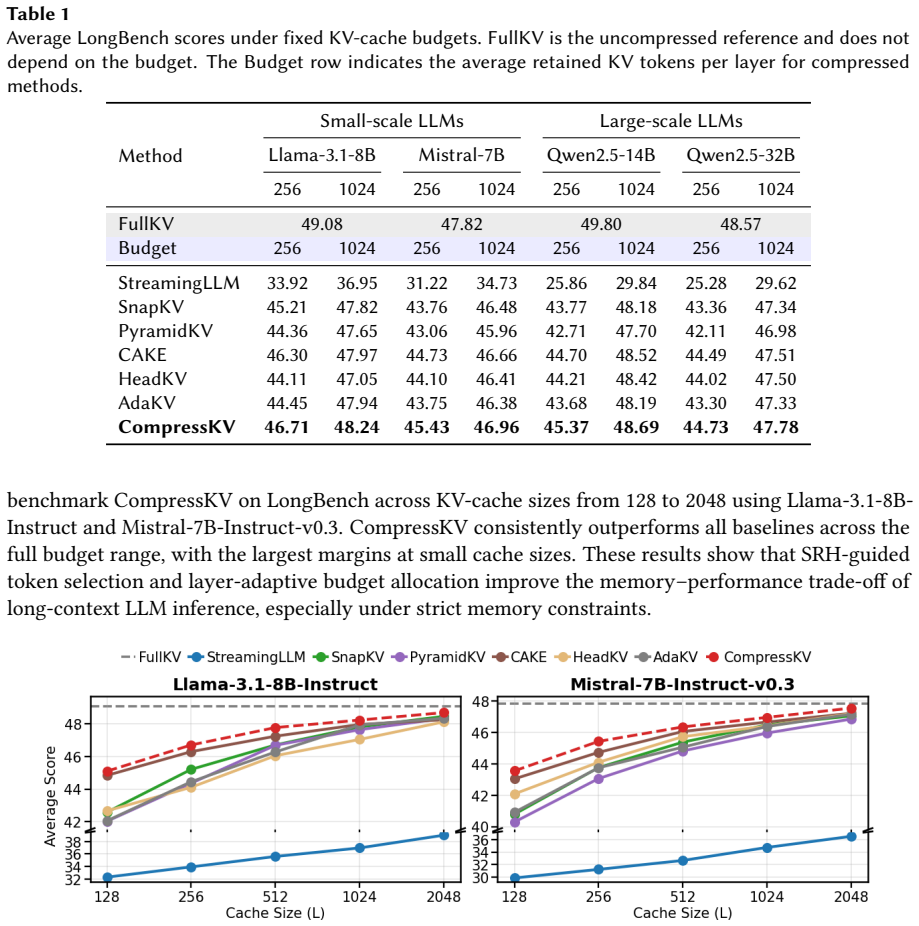
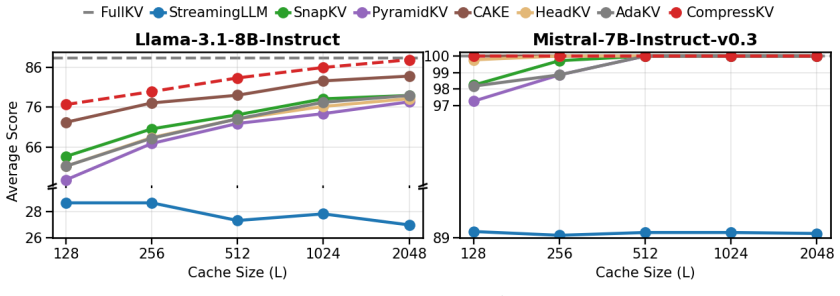
CompressKV identifies Semantic Retrieval Heads in GQA-based LLMs that capture both the initial and final tokens of a prompt and semantically important mid-context evidence, uses their attention scores to select which KV pairs to retain, and allocates per-layer cache budgets from offline layer-wise eviction-error estimates; on LongBench question-answering tasks this keeps over 97% of full-cache performance with only 3% of the KV cache and reaches 90% accuracy on Needle-in-a-Haystack with 0.7% storage.
What carries the argument
Semantic Retrieval Heads (SRHs) that attend to prompt boundaries and mid-context evidence, used to score and retain tokens, together with layer-wise budget allocation driven by offline eviction-error estimates.
If this is right
- Outperforms prior KV-eviction methods at every tested memory budget on LongBench and Needle-in-a-Haystack.
- Enables long-context inference on hardware whose memory would otherwise force aggressive truncation or offloading.
- Reduces decoding cost proportionally to the retained KV size while accuracy remains near the uncompressed level.
- Demonstrates that head specialization can be exploited for compression without retraining the underlying LLM.
Where Pith is reading between the lines
- If SRH patterns prove stable, the same identification step could be applied to other attention-based architectures that use grouped-query attention.
- The layer-wise error estimates might be replaced by a lightweight online calibration pass if offline computation proves costly for new models.
- Success here suggests that other efficiency techniques, such as speculative decoding, could also benefit from routing decisions made only through a small subset of heads.
- A direct test would be to measure whether the same SRH set remains optimal when the prompt distribution shifts from question answering to summarization or code completion.
Load-bearing premise
The heads that qualify as Semantic Retrieval Heads stay the same and remain sufficient across models, tasks, and prompt lengths, and the offline error estimates transfer directly to online inference without adjustment.
What would settle it
Run the method on a held-out model and task at the 3% cache budget; if accuracy falls below the best uniform-eviction baseline at the same budget, the SRH-guided selection is not providing the claimed advantage.
Figures

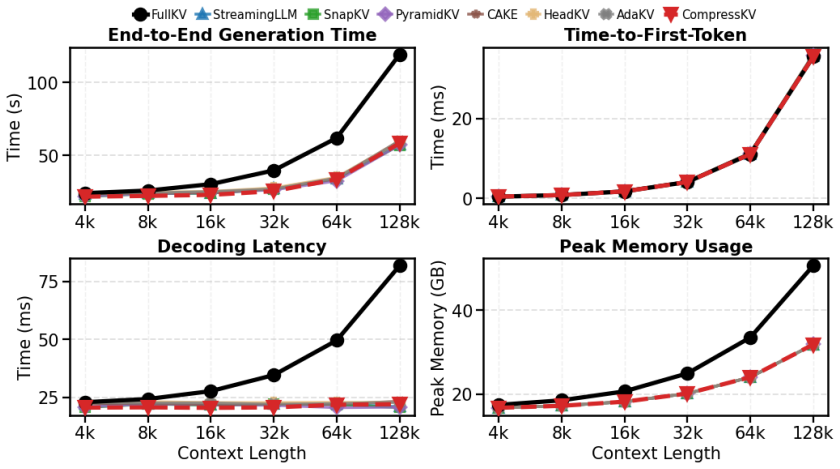

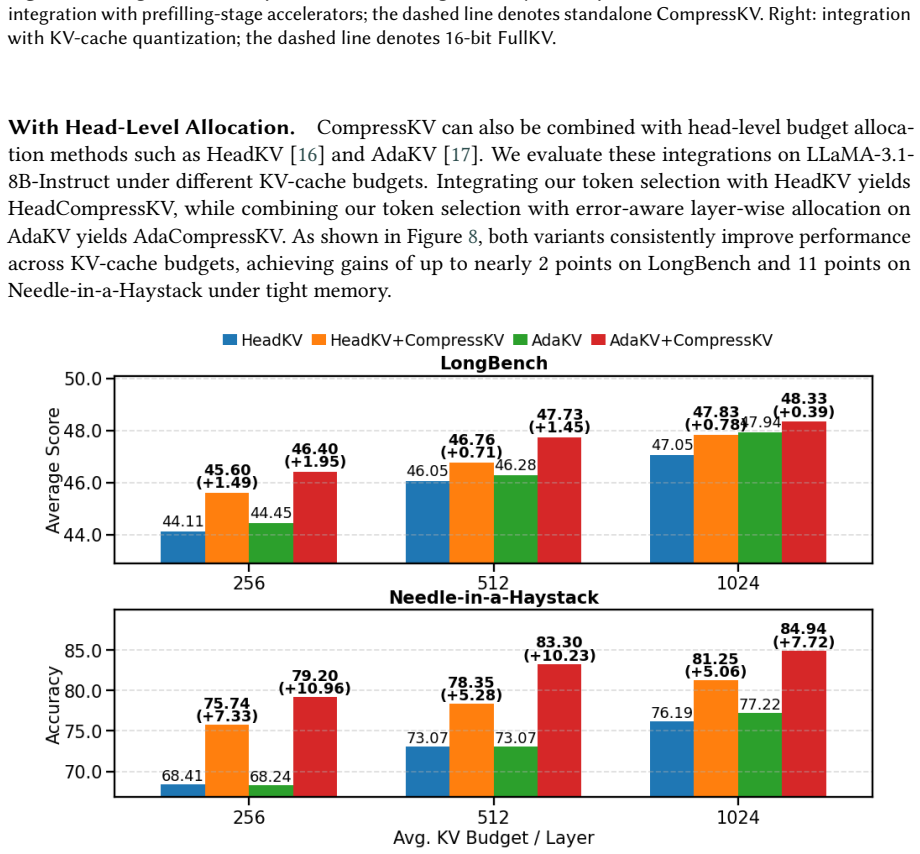

read the original abstract
Long-context large language model (LLM) inference is increasingly constrained by the memory footprint and decoding cost of key-value (KV) caches, limiting sustainable deployment on resource-constrained hardware. Existing KV cache eviction methods typically apply heuristic token scoring over all heads in GQA-based LLMs. These methods ignore the different functionalities of attention heads, leading to the eviction of critical tokens and thus degrading the performance of LLMs. To address this issue, we propose CompressKV, a resource-efficient KV-cache compression framework for GQA-based LLMs. Instead of aggregating attention scores from all heads, CompressKV identifies Semantic Retrieval Heads (SRHs) that capture both the initial and final tokens of a prompt and semantically important mid-context evidence, and uses them to select tokens whose KV pairs should be retained. Furthermore, CompressKV allocates cache budgets across layers according to offline estimates of layer-wise eviction error. Experiments on LongBench and Needle-in-a-Haystack show that CompressKV consistently outperforms existing KV-cache eviction methods across memory budgets. Notably, it preserves over 97\% of full-cache performance using only 3\% of the KV cache on LongBench question-answering tasks and achieves 90\% accuracy with just 0.7\% KV storage on Needle-in-a-Haystack. These results demonstrate an improved resource--performance trade-off for long-context LLM inference. Our code is publicly available at: https://github.com/TUDa-HWAI/CompressKV
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CompressKV, a KV-cache compression framework for GQA-based LLMs. It identifies Semantic Retrieval Heads (SRHs) whose attention focuses on prompt start/end tokens and semantically important mid-context evidence to guide token retention, and allocates per-layer cache budgets according to offline-computed layer-wise eviction errors. On LongBench question-answering tasks the method is reported to retain over 97% of full-cache performance with 3% of the KV cache; on Needle-in-a-Haystack it reaches 90% accuracy with 0.7% storage, outperforming prior eviction baselines.
Significance. If the central claims hold after the required clarifications, the work would demonstrate a practical improvement in the performance-memory trade-off for long-context inference by exploiting head specialization instead of uniform heuristics across all heads. The public release of code at the cited GitHub repository is a clear strength that supports reproducibility and further experimentation.
major comments (3)
- [Abstract / §3] Abstract and §3 (Method): the procedure used to identify Semantic Retrieval Heads—specifically how attention concentration on prompt start/end tokens and mid-context evidence is quantified, thresholded, or selected—is not described. Because SRH selection directly determines which tokens are retained, this omission prevents assessment of whether the reported 97% retention is reproducible or generalizes.
- [§4] §4 (Experiments): no cross-model, cross-task, or prompt-distribution-shift ablations are presented to test whether the SRHs identified on the training distribution remain stable. The headline claims (97% retention at 3% cache on LongBench QA; 90% NIAH accuracy at 0.7% storage) rest on the untested assumption that these heads transfer; without such evidence the generalization argument is unsupported.
- [§3 / §4] §3 and §4: the offline layer-wise eviction-error estimates used for budget allocation are not validated against online autoregressive decoding error. If the static ranking diverges from runtime behavior, the budget allocator itself becomes unreliable; a correlation plot or online-vs-offline ablation is required to support this component of the method.
minor comments (2)
- [Abstract] The abstract states quantitative gains but supplies no standard errors, number of runs, or statistical significance tests for the reported percentages; adding these would strengthen the experimental claims.
- [§3] Notation for the eviction-error metric and the precise definition of “mid-context evidence” should be formalized with an equation or pseudocode in §3 to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate clarifications and additional experiments in the revised manuscript to strengthen the presentation of SRH identification, generalization evidence, and validation of the budget allocator.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Method): the procedure used to identify Semantic Retrieval Heads—specifically how attention concentration on prompt start/end tokens and mid-context evidence is quantified, thresholded, or selected—is not described. Because SRH selection directly determines which tokens are retained, this omission prevents assessment of whether the reported 97% retention is reproducible or generalizes.
Authors: We agree that §3 requires an explicit description of the SRH identification procedure. In the revision we will add a dedicated subsection with the exact quantification (attention aggregation over start/end and evidence positions), thresholding rule, and selection algorithm, including pseudocode. The public code repository already implements this logic; the expanded text will make the method fully reproducible from the paper alone. revision: yes
-
Referee: [§4] §4 (Experiments): no cross-model, cross-task, or prompt-distribution-shift ablations are presented to test whether the SRHs identified on the training distribution remain stable. The headline claims (97% retention at 3% cache on LongBench QA; 90% NIAH accuracy at 0.7% storage) rest on the untested assumption that these heads transfer; without such evidence the generalization argument is unsupported.
Authors: We acknowledge that additional ablations would better support the transferability claim. The revision will include new experiments evaluating SRH stability on at least one additional GQA model, an extra task category, and a prompt-distribution shift (e.g., different LongBench subsets or synthetic variations). Results will be reported in an expanded §4 with the same metrics used in the original evaluation. revision: yes
-
Referee: [§3 / §4] §3 and §4: the offline layer-wise eviction-error estimates used for budget allocation are not validated against online autoregressive decoding error. If the static ranking diverges from runtime behavior, the budget allocator itself becomes unreliable; a correlation plot or online-vs-offline ablation is required to support this component of the method.
Authors: We will add the requested validation. The revised §4 will contain (i) a scatter plot and Pearson correlation between offline eviction-error ranks and online per-layer error measured during autoregressive decoding, and (ii) an ablation comparing end-to-end performance when budgets are assigned via the offline estimator versus an online oracle. These results will directly address the reliability of the static allocator. revision: yes
Circularity Check
No circularity: empirical method relies on direct attention measurements and offline estimates
full rationale
The paper describes an empirical KV-cache compression technique that selects tokens using attention patterns observed in Semantic Retrieval Heads and allocates budgets via precomputed per-layer eviction errors. No mathematical derivation, prediction step, or uniqueness claim reduces by construction to fitted parameters or self-citations; the method applies observed data directly without redefining inputs as outputs. Performance numbers are presented as experimental outcomes on external benchmarks rather than forced by any internal loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Different attention heads in GQA LLMs perform distinct functions that can be exploited for selective token retention.
invented entities (1)
-
Semantic Retrieval Heads (SRHs)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al., Gpt-4 technical report, 2024. URL: https://arxiv.org/abs/2303.08774. arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Anthropic, The Claude 3 Model Family: Opus, Sonnet, Haiku, Technical Report, Anthropic,
-
[3]
URL: https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_ Card_Claude_3.pdf, accessed: 2024-07-09
2024
-
[4]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, et al., The llama 3 herd of models, 2024. URL: https://arxiv.org/abs/2407.21783. arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu, et al., Qwen2.5 technical report, 2025. URL: https://arxiv.org/abs/2412.15115.arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Wang, Y.-G
J. Wang, Y.-G. Chen, I.-C. Lin, B. Li, G. L. Zhang, Basis sharing: Cross-layer parameter sharing for large language model compression, in: The Thirteenth International Conference on Learning Representations, 2025. URL: https://openreview.net/forum?id=gp32jvUquq
2025
-
[7]
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V. Braverman, B. Chen, X. Hu, KIVI: A tuning-free asymmetric 2bit quantization for KV cache, in: Forty-first International Conference on Machine Learning, 2024. URL: https://openreview.net/forum?id=L057s2Rq8O
2024
- [8]
-
[9]
S. Ge, Y. Zhang, L. Liu, M. Zhang, J. Han, J. Gao, Model tells you what to discard: Adaptive kv cache compression for llms, in: The Thirteenth International Conference on Learning Representations,
-
[10]
URL: https://openreview.net/pdf?id=uNrFpDPMyo
-
[11]
G. Xiao, Y. Tian, B. Chen, S. Han, M. Lewis, Efficient streaming language models with attention sinks, in: The Twelfth International Conference on Learning Representations, 2024. URL: https: //openreview.net/forum?id=NG7sS51zVF
2024
-
[12]
Y. Li, Y. Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, D. Chen, SnapKV: LLM knows what you are looking for before generation, in: The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL: https://openreview.net/forum?id=poE54GOq2l
2024
-
[13]
Z. Cai, Y. Zhang, B. Gao, Y. Liu, Y. Li, T. Liu, K. Lu, W. Xiong, Y. Dong, J. Hu, W. Xiao, Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling, 2025. URL: https: //arxiv.org/abs/2406.02069.arXiv:2406.02069
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
D. Yang, X. Han, Y. Gao, Y. Hu, S. Zhang, H. Zhao, Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference, in: Findings of the Association for Computational Linguistics ACL 2024, 2024, pp. 3258–3270
2024
-
[15]
Z. Qin, Y. Cao, M. Lin, W. Hu, S. Fan, K. Cheng, W. Lin, J. Li, CAKE: Cascading and adaptive KV cache eviction with layer preferences, in: The Thirteenth International Conference on Learning Representations, 2025. URL: https://openreview.net/forum?id=EQgEMAD4kv
2025
-
[16]
Ainslie, J
J. Ainslie, J. Lee-Thorp, M. de Jong, Y. Zemlyanskiy, F. Lebron, S. Sanghai, Gqa: Training generalized multi-query transformer models from multi-head checkpoints, in: The 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URL: https://openreview.net/forum?id= hmOwOZWzYE
2023
-
[17]
G. Xiao, J. Tang, J. Zuo, junxian guo, S. Yang, H. Tang, Y. Fu, S. Han, Duoattention: Efficient long- context LLM inference with retrieval and streaming heads, in: The Thirteenth International Con- ference on Learning Representations, 2025. URL: https://openreview.net/forum?id=cFu7ze7xUm
2025
- [18]
-
[19]
Y. Feng, J. Lv, Y. Cao, X. Xie, S. K. Zhou, Ada-kv: Optimizing kv cache eviction by adap- tive budget allocation for efficient llm inference, 2025. URL: https://arxiv.org/abs/2407.11550. arXiv:2407.11550
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Z. Liu, A. Desai, F. Liao, W. Wang, V. Xie, Z. Xu, A. Kyrillidis, A. Shrivastava, Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time, in: Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL: https://openreview.net/forum?id=JZfg6wGi6g
2023
-
[21]
Zhang, Y
Z. Zhang, Y. Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y. Tian, C. Re, C. Barrett, Z. Wang, B. Chen, H2o: Heavy-hitter oracle for efficient generative inference of large language models, in: Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL: https://openreview.net/forum?id=RkRrPp7GKO
2023
-
[22]
C. Han, Q. Wang, H. Peng, W. Xiong, Y. Chen, H. Ji, S. Wang, Lm-infinite: Zero-shot extreme length generalization for large language models, in: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 3991–4008
2024
-
[23]
M. Oren, M. Hassid, N. Yarden, Y. Adi, R. Schwartz, Transformers are multi-state rnns, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 18724–18741
2024
-
[24]
Z. Wan, X. Wu, Y. Zhang, Y. Xin, C. Tao, Z. Zhu, X. Wang, S. Luo, J. Xiong, L. Wang, M. Zhang, D2o: Dynamic discriminative operations for efficient long-context inference of large language models, in: The Thirteenth International Conference on Learning Representations, 2025. URL: https://openreview.net/forum?id=HzBfoUdjHt
2025
-
[25]
In-context Learning and Induction Heads
C. Olsson, N. Elhage, N. Nanda, N. Joseph, N. DasSarma, T. Henighan, B. Mann, A. Askell, Y. Bai, A. Chen, T. Conerly, D. Drain, D. Ganguli, Z. Hatfield-Dodds, D. Hernandez, S. Johnston, A. Jones, J. Kernion, L. Lovitt, K. Ndousse, D. Amodei, T. Brown, J. Clark, J. Kaplan, S. McCandlish, C. Olah, In-context learning and induction heads, 2022. URL: https://...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
W. Kwon, S. Kim, M. W. Mahoney, J. Hassoun, K. Keutzer, A. Gholami, A fast post-training pruning framework for transformers, in: A. H. Oh, A. Agarwal, D. Belgrave, K. Cho (Eds.), Advances in Neural Information Processing Systems, 2022. URL: https://openreview.net/forum?id=0GRBKLBjJE
2022
- [27]
-
[28]
J. Ren, Q. Guo, H. Yan, D. Liu, Q. Zhang, X. Qiu, D. Lin, Identifying semantic induction heads to understand in-context learning, in: Findings of the Association for Computational Linguistics: ACL 2024, 2024. URL: https://aclanthology.org/2024.findings-acl.412/
2024
-
[29]
W. Wu, Y. Wang, G. Xiao, H. Peng, Y. Fu, Retrieval head mechanistically explains long-context factuality, in: The Thirteenth International Conference on Learning Representations, 2025. URL: https://openreview.net/forum?id=EytBpUGB1Z
2025
-
[30]
E. Todd, M. Li, A. S. Sharma, A. Mueller, B. C. Wallace, D. Bau, Function vectors in large language models, in: The Twelfth International Conference on Learning Representations, 2024. URL: https://openreview.net/forum?id=AwyxtyMwaG
2024
- [31]
- [32]
- [33]
-
[34]
Y. Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, Y. Dong, J. Tang, J. Li, LongBench: A bilingual, multitask benchmark for long context understanding, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024. URL: https://aclanthology.org/2024.acl-long.172/
2024
-
[35]
Kamradt, Needleinahaystack, https://github.com/gkamradt/LLMTest_NeedleInAHaystack, 2023
G. Kamradt, Needleinahaystack, https://github.com/gkamradt/LLMTest_NeedleInAHaystack, 2023. Accessed: 2025-07-13
2023
-
[36]
Dao, Flashattention-2: Faster attention with better parallelism and work partitioning, in: The Twelfth International Conference on Learning Representations, 2024
T. Dao, Flashattention-2: Faster attention with better parallelism and work partitioning, in: The Twelfth International Conference on Learning Representations, 2024. URL: https://openreview. net/forum?id=mZn2Xyh9Ec
2024
-
[37]
Jiang, Y
H. Jiang, Y. LI, C. Zhang, Q. Wu, X. Luo, S. Ahn, Z. Han, A. H. Abdi, D. Li, C.-Y. Lin, Y. Yang, L. Qiu, MInference 1.0: Accelerating pre-filling for long-context LLMs via dynamic sparse attention, in: The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL: https://openreview.net/forum?id=fPBACAbqSN
2024
-
[38]
R. Xu, G. Xiao, H. Huang, J. Guo, S. Han, XAttention: Block sparse attention with antidiagonal scoring, in: Forty-second International Conference on Machine Learning, 2025. URL: https: //openreview.net/forum?id=KG6aBfGi6e
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.