Emergent Capabilities Arise Randomly from Learning Sparse Attention Patterns
Pith reviewed 2026-06-25 23:40 UTC · model grok-4.3
The pith
Emergent capabilities arise stochastically when transformers abruptly learn task-relevant sparse attention patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
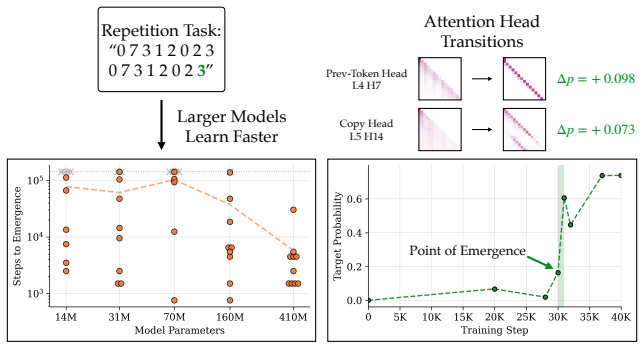
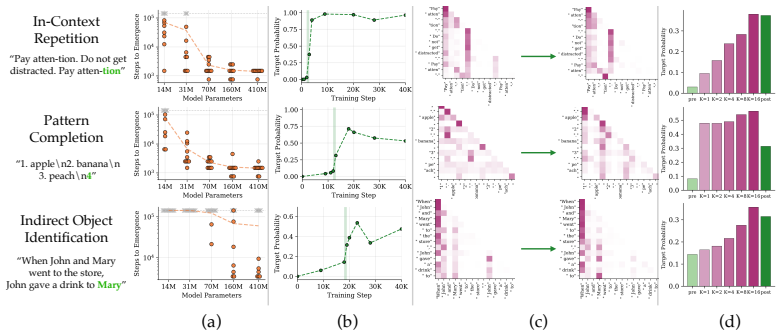
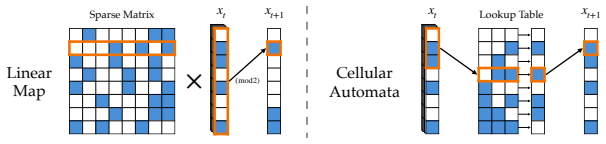
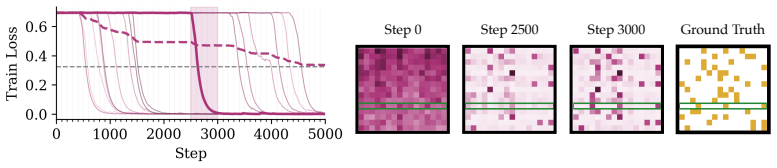
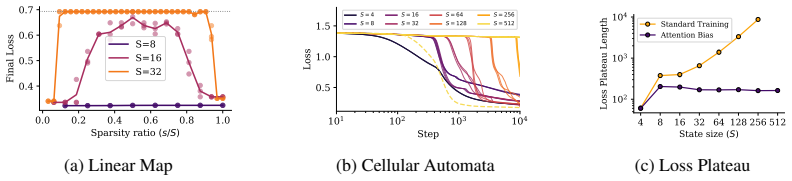
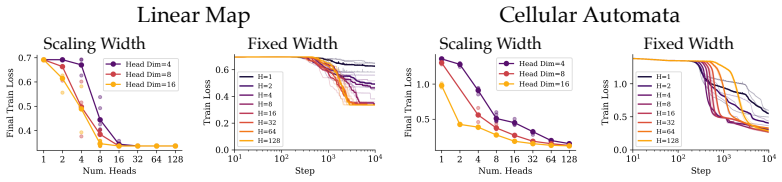
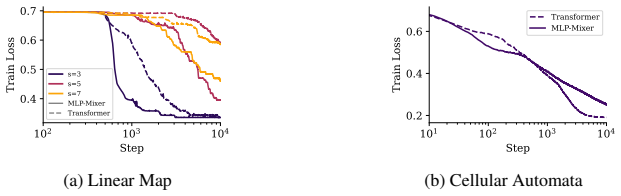
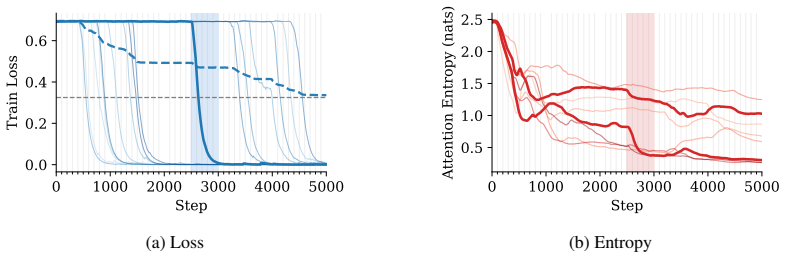
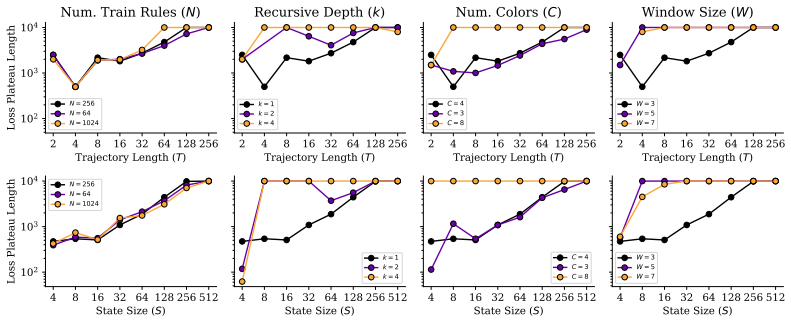
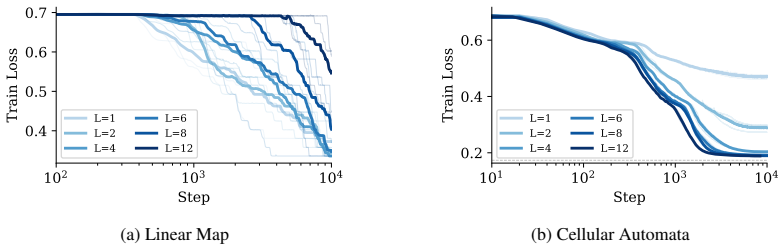
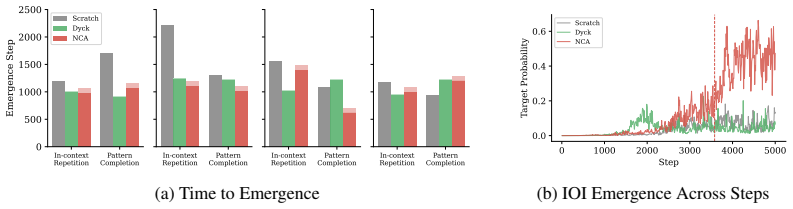
Emergent capabilities arise stochastically throughout training, with larger models acquiring them earlier on average. The emergence of capabilities such as pattern completion and indirect object identification corresponds to the abrupt learning of task-relevant attention patterns. To isolate this phenomenon, the authors train transformer models on synthetic linear map and cellular automata datasets and show that the difficulty of learning attention patterns depends on context length and pattern sparsity. Scaling the number of attention heads improves learning efficiency on these tasks, while increasing the head dimension yields diminishing returns past a minimum capacity.
What carries the argument
Abrupt learning of sparse task-relevant attention patterns during transformer training.
If this is right
- Capabilities emerge at stochastic points in training rather than at predictable scales.
- Larger models acquire emergent capabilities earlier because they learn the required attention patterns faster on average.
- The difficulty of acquiring an attention pattern grows with longer context lengths and sparser patterns.
- Increasing the number of attention heads improves learning efficiency more reliably than increasing head dimension beyond a minimum size.
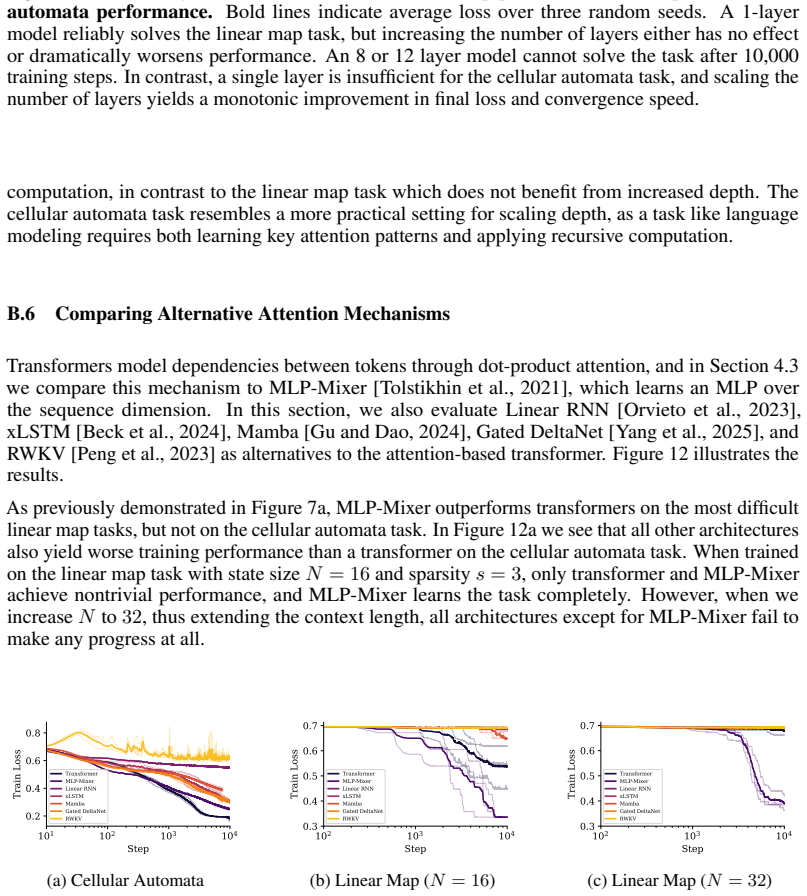
- Architectures without standard attention, such as MLP-Mixer, can outperform transformers when the required patterns are complex.
Where Pith is reading between the lines
- If attention pattern discovery is the bottleneck, interventions that bias training toward sparse patterns could shift emergence to earlier points in training.
- The stochastic timing implies that repeated runs with different random seeds are needed to map when a given capability reliably appears.
- Synthetic tasks of this form could be used to forecast which capabilities will emerge at which model sizes before full pretraining.
- If the mechanism generalizes, then monitoring attention pattern formation during training might serve as an early indicator of downstream capability acquisition.
Load-bearing premise
The synthetic linear map and cellular automata datasets sufficiently capture the mechanisms responsible for emergence of capabilities in real language model pretraining on natural text.
What would settle it
A controlled experiment on a real language model in which a downstream capability emerges without an observable abrupt shift to the corresponding attention pattern, or in which the pattern is learned but the capability remains absent.
Figures
read the original abstract
Neural scaling laws for transformer language models predict smooth improvements in pretraining loss with increasing parameters, but downstream capabilities such as in-context learning are known to emerge abruptly past a certain model scale. In this paper, we show that emergent capabilities arise stochastically throughout training, with larger models acquiring them earlier on average. We demonstrate that the emergence of capabilities such as pattern completion and indirect object identification corresponds to the abrupt learning of task-relevant attention patterns. To isolate this phenomenon, we train transformer models on synthetic linear map and cellular automata datasets, and we show that the difficulty of learning attention patterns depends on context length and pattern sparsity. Moreover, scaling the number of attention heads improves learning efficiency on our synthetic tasks, while increasing the head dimension yields diminishing returns past a minimum capacity. We additionally investigate architectures with alternative attention mechanisms, showing that MLP-Mixer outperforms a transformer on linear map tasks with complex attention patterns. Our findings provide a mechanistic insight into emergence, showing that downstream capabilities arise abruptly due to the intrinsic difficulty of learning sparse attention patterns in transformer models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that emergent capabilities in transformers arise stochastically throughout training (with larger models acquiring them earlier on average) because of the abrupt learning of sparse task-relevant attention patterns. This is demonstrated on two hand-designed synthetic datasets (linear maps and cellular automata) where the authors measure attention pattern acquisition timing, vary context length and sparsity, compare head count vs. head dimension, and show MLP-Mixer outperforming transformers on complex patterns. The work positions these controlled experiments as providing a mechanistic explanation for abrupt capability emergence despite smooth loss scaling in real language models.
Significance. If the reported correspondence between capability emergence and attention-pattern acquisition is robust within the synthetic regime, the work supplies a concrete, testable mechanism that could explain why downstream capabilities appear suddenly. The synthetic construction permits direct inspection of attention heads and precise timing measurements that are difficult in natural-text pretraining, and the architectural ablations (head count vs. dimension, MLP-Mixer comparison) generate clear predictions. These are genuine strengths. However, because all quantitative evidence is obtained on tasks whose inputs and targets are explicitly engineered around sparse linear or rule-based structures, the transfer of the mechanism to unstructured natural-language pretraining remains untested.
major comments (2)
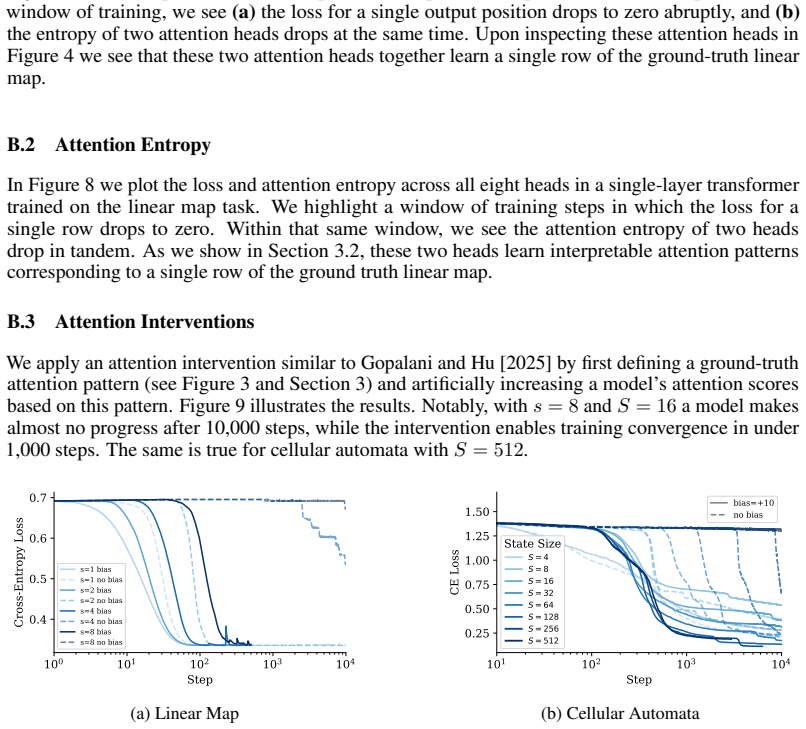
- [Experimental sections] Experimental sections (synthetic dataset construction and results): all quantitative claims about stochastic timing, abruptness, and attention-head specialization are obtained exclusively on linear-map and cellular-automata distributions whose targets are defined by sparse maps or rules. No ablation that removes the engineered sparsity (e.g., dense random targets or unstructured sequences) is reported, so it is impossible to determine whether the observed stochastic emergence is caused by the sparsity or is an artifact of the task design. This directly affects the central mechanistic claim.
- [Discussion / conclusion] Discussion / conclusion: the manuscript asserts that the synthetic findings supply a mechanistic insight into emergence in language models, yet no experiments on natural text, no measurement of attention specialization during real pretraining, and no comparison of emergence timing distributions between synthetic and natural settings are provided. Without such evidence the transfer argument remains unsupported and is load-bearing for the title and abstract framing.
minor comments (1)
- [Abstract] The abstract states that experiments 'support the correspondence' but supplies no numerical values, error bars, or statistical tests; if the full paper likewise omits these, the strength of the stochasticity and timing claims cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for acknowledging the strengths of our controlled synthetic experiments. We address the major comments point by point below, and we are prepared to make revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experimental sections] Experimental sections (synthetic dataset construction and results): all quantitative claims about stochastic timing, abruptness, and attention-head specialization are obtained exclusively on linear-map and cellular-automata distributions whose targets are defined by sparse maps or rules. No ablation that removes the engineered sparsity (e.g., dense random targets or unstructured sequences) is reported, so it is impossible to determine whether the observed stochastic emergence is caused by the sparsity or is an artifact of the task design. This directly affects the central mechanistic claim.
Authors: The synthetic tasks were deliberately constructed with sparse linear maps and rule-based cellular automata to enable direct measurement of attention pattern acquisition and to model the kind of sparse structures that may underlie emergent capabilities in more complex domains. Our central claim is that in these settings, capabilities emerge stochastically due to the difficulty of learning the sparse attention patterns. We acknowledge that without an ablation using dense targets, it is difficult to isolate sparsity as the causal factor versus other aspects of the task design. To address this, we will include additional experiments with dense random targets in the revised manuscript to compare emergence behavior. revision: yes
-
Referee: [Discussion / conclusion] Discussion / conclusion: the manuscript asserts that the synthetic findings supply a mechanistic insight into emergence in language models, yet no experiments on natural text, no measurement of attention specialization during real pretraining, and no comparison of emergence timing distributions between synthetic and natural settings are provided. Without such evidence the transfer argument remains unsupported and is load-bearing for the title and abstract framing.
Authors: We position the work as providing a mechanistic insight derived from controlled synthetic experiments where the relevant variables can be precisely manipulated and measured. The abstract and discussion frame this as an explanation for the phenomenon of abrupt emergence despite smooth loss curves, using the synthetic regime as a testbed. We do not present direct evidence from natural language pretraining. We will revise the discussion and abstract to emphasize that these results offer a hypothesis for the mechanism in language models, with validation on natural text left as important future work, thereby clarifying the scope of the claims. revision: partial
Circularity Check
No circularity: emergence measured independently via task accuracy and attention inspection on synthetic tasks
full rationale
The paper trains transformers on explicitly constructed synthetic linear-map and cellular-automata tasks, measures capability emergence by downstream task performance, and separately inspects when task-relevant attention patterns appear. These two quantities are not defined in terms of each other; the correspondence is an empirical observation rather than a definitional identity. No equations, fitted parameters, or self-citations are shown to reduce the central claim to its inputs by construction. The synthetic construction supplies an independent testbed rather than smuggling the target result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
xlstm: Extended long short-term memory, 2024
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xlstm: Extended long short-term memory, 2024. URL https://arxiv.org/abs/2405.04517
arXiv 2024
-
[2]
Pythia: A suite for analyzing large language models across training and scaling, 2023
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling, 2023. URL https://arxiv.org/abs/2304.01373
Pith/arXiv arXiv 2023
-
[3]
Angelica Chen, Ravid Shwartz-Ziv, Kyunghyun Cho, Matthew L. Leavitt, and Naomi Saphra. Sudden drops in the loss: Syntax acquisition, phase transitions, and simplicity bias in mlms, 2025. URL https://arxiv.org/abs/2309.07311
arXiv 2025
-
[4]
What happens during the loss plateau? understanding abrupt learning in transformers, 2025
Pulkit Gopalani and Wei Hu. What happens during the loss plateau? understanding abrupt learning in transformers, 2025. URL https://arxiv.org/abs/2506.13688
arXiv 2025
-
[5]
Abrupt learning in transformers: A case study on matrix completion, 2024
Pulkit Gopalani, Ekdeep Singh Lubana, and Wei Hu. Abrupt learning in transformers: A case study on matrix completion, 2024. URL https://arxiv.org/abs/2410.22244
arXiv 2024
-
[6]
Mamba: Linear-time sequence modeling with selective state spaces, 2024
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces, 2024. URL https://arxiv.org/abs/2312.00752
Pith/arXiv arXiv 2024
-
[7]
How to use and interpret activation patching, 2024
Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching, 2024. URL https://arxiv.org/abs/2404.15255
Pith/arXiv arXiv 2024
-
[8]
Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md. Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically, 2017. URL https://arxiv.org/abs/1712.00409
Pith/arXiv arXiv 2017
-
[9]
Hu, Jackson Petty, Chuan Shi, William Merrill, and Tal Linzen
Michael Y. Hu, Jackson Petty, Chuan Shi, William Merrill, and Tal Linzen. Between circuits and chomsky: Pre-pretraining on formal languages imparts linguistic biases, 2025. URL https://arxiv.org/abs/2502.19249
arXiv 2025
-
[10]
Hidden breakthroughs in language model training, 2026
Sara Kangaslahti, Elan Rosenfeld, and Naomi Saphra. Hidden breakthroughs in language model training, 2026. URL https://arxiv.org/abs/2506.15872
arXiv 2026
-
[11]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. URL https://arxiv.org/abs/2001.08361
Pith/arXiv arXiv 2020
-
[12]
Training language models via neural cellular automata, 2026
Dan Lee, Seungwook Han, Akarsh Kumar, and Pulkit Agrawal. Training language models via neural cellular automata, 2026. URL https://arxiv.org/abs/2603.10055
arXiv 2026
-
[13]
Michaud, Ziming Liu, Uzay Girit, and Max Tegmark
Eric J. Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. The quantization model of neural scaling, 2024. URL https://arxiv.org/abs/2303.13506
arXiv 2024
-
[14]
Progress measures for grokking via mechanistic interpretability, 2023
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability, 2023. URL https://arxiv.org/abs/2301.05217
Pith/arXiv arXiv 2023
-
[15]
In-context learning and induction heads, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
Pith/arXiv arXiv 2022
-
[16]
Resurrecting recurrent neural networks for long sequences, 2023
Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences, 2023. URL https://arxiv.org/abs/2303.06349
arXiv 2023
-
[17]
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV, Xuzheng He, Haowen Hou, Jiaju Lin, Przemyslaw Kazienko, Jan Kocon, Jiaming Kong, Bartlomiej Koptyra, Hayden Lau, Krishna Sri Ipsit Mantri, Ferdinand Mom, Atsushi Saito, Guangyu Song, Xiangru Tang, ...
Pith/arXiv arXiv 2023
-
[18]
Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022. URL https://arxiv.org/abs/2201.02177
Pith/arXiv arXiv 2022
-
[19]
Are emergent abilities of large language models a mirage?, 2023
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage?, 2023. URL https://arxiv.org/abs/2304.15004
arXiv 2023
-
[20]
Mlp-mixer: An all-mlp architecture for vision, 2021
Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, and Alexey Dosovitskiy. Mlp-mixer: An all-mlp architecture for vision, 2021. URL https://arxiv.org/abs/2105.01601
arXiv 2021
-
[21]
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small, 2022
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small, 2022. URL https://arxiv.org/abs/2211.00593
Pith/arXiv arXiv 2022
-
[22]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models, 2022. URL https://arxiv.org/abs/2206.07682
Pith/arXiv arXiv 2022
-
[23]
Efficient streaming language models with attention sinks, 2024
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks, 2024. URL https://arxiv.org/abs/2309.17453
Pith/arXiv arXiv 2024
-
[24]
Gated delta networks: Improving mamba2 with delta rule, 2025
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule, 2025. URL https://arxiv.org/abs/2412.06464
Pith/arXiv arXiv 2025
-
[25]
Random scaling of emergent capabilities, 2026
Rosie Zhao, Tian Qin, David Alvarez-Melis, Sham Kakade, and Naomi Saphra. Random scaling of emergent capabilities, 2026. URL https://arxiv.org/abs/2502.17356
arXiv 2026
-
[26]
Nicolas Zucchet, Francesco d'Angelo, Andrew K. Lampinen, and Stephanie C. Y. Chan. The emergence of sparse attention: impact of data distribution and benefits of repetition, 2025. URL https://arxiv.org/abs/2505.17863
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.