Physics Question Scene Graph: Fine-grained Evaluation of Physical Plausibility in Text-to-Video Generation
Pith reviewed 2026-06-25 21:31 UTC · model grok-4.3
The pith
A hierarchy of questions arranged as a scene graph evaluates how faithfully generated videos follow physical laws.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By turning the evaluation into a scene graph of questions that probe objects, actions, and physical constraints in sequence, the approach produces fine-grained scores for physical plausibility that align better with human judgments than prior methods, while also allowing separate tests of how well vision-language models can pose and answer such questions.
What carries the argument
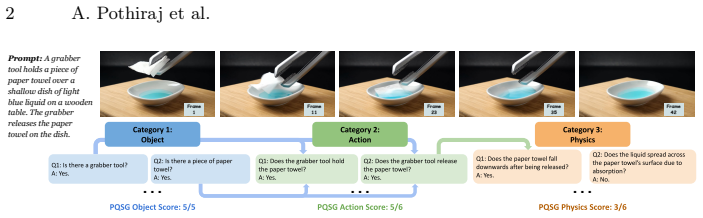
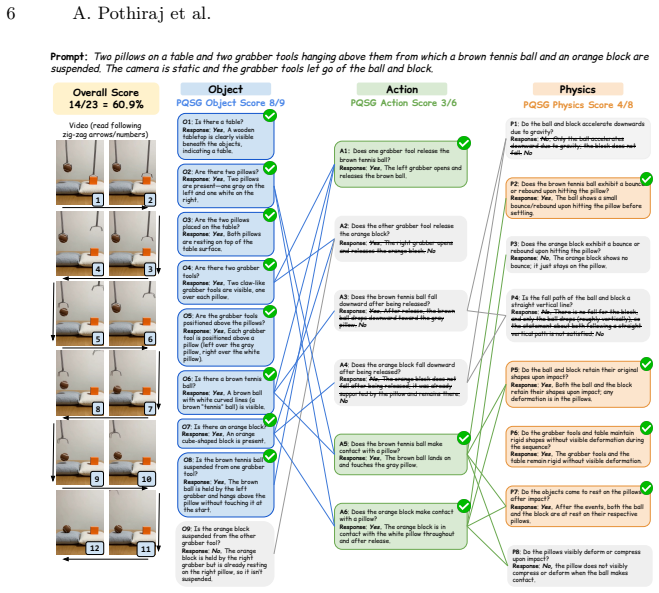
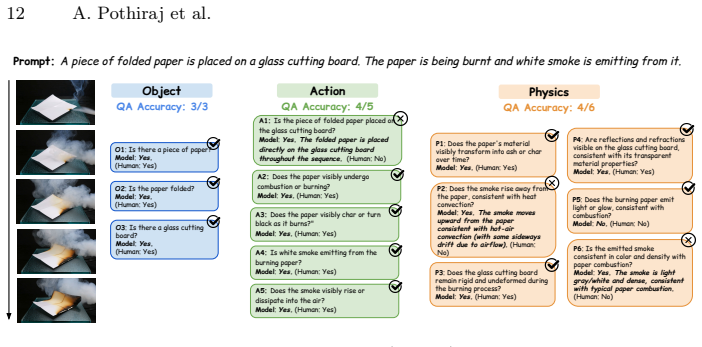
The Physics Question Scene Graph, a hierarchical graph of questions from a vision-language model that enforces logical dependencies to assess faithfulness to prompts and physical laws.
If this is right
- PQSG supplies localized scores that identify specific physical violations in a video.
- The method ranks closed-source video generators higher than Wan 2.1 on physical realism.
- Annotations in the accompanying dataset support direct benchmarking of vision-language models on question creation and response.
- Evaluation becomes possible at the level of individual objects and actions rather than whole videos.
Where Pith is reading between the lines
- Video generators could use the detailed violation reports to guide targeted improvements during training.
- The graph structure might generalize to checking other forms of consistency such as logical or causal relations in videos.
- Human agreement could be tested on videos with deliberately introduced physics errors to confirm the method's sensitivity.
Load-bearing premise
Questions produced by the vision-language model cover all important physical law violations without bias and form valid contextual queries.
What would settle it
Collect a new set of videos containing clear, known physical violations and check whether PQSG scores match independent human ratings on those specific violations.
Figures







read the original abstract
Video generation models are increasingly capable of producing realistic videos, but they still struggle to generate videos that follow basic physical laws. Compounding this is a lack of reliable granular evaluation methods for localizing and specifying physical law violations in videos. We address this by introducing Physics Question Scene Graph (PQSG), a hierarchical question-based evaluation pipeline. PQSG evaluates generated videos by checking their faithfulness to a prompt across objects, actions, and adherence to physical laws using a graph-based hierarchy of questions generated by a vision-language model (VLM), guided by high-quality in-context examples. By representing questions as a graph, PQSG introduces logical dependencies within questions, ensuring that each query is contextually valid. Moreover, PQSG provides granular assessments of which qualities of the video violate physical plausibility constraints. We validate PQSG by creating FinePhyEval, a dataset with physics-based prompts and corresponding generated videos from diverse state-of-the-art video generation models (Sora 2, Veo 3, and Wan 2.1), with each video annotated across multiple categories by humans. Using FinePhyEval, we measure the correlation between PQSG's fine-grained scores and human judgments, showing higher overall correlations than prior work. We also find that PQSG ranks closed-source models higher than Wan 2.1 on physical realism. Lastly, we show that the annotations we provide in FinePhyEval can also be used for subtask evaluation: we benchmark two strong VLMs on generating and answering questions, finding that while models can create human-like questions, they still fall short of human performance in answering them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Physics Question Scene Graph (PQSG), a hierarchical question-based evaluation pipeline for assessing physical plausibility in text-to-video generation. PQSG uses a VLM to generate a graph-structured set of questions with logical dependencies, guided by in-context examples, to evaluate prompt faithfulness across objects, actions, and physical laws. The authors create the FinePhyEval dataset of physics-based prompts and videos from models including Sora 2, Veo 3, and Wan 2.1, with multi-category human annotations. They report that PQSG achieves higher correlations with human judgments than prior work, ranks closed-source models higher on physical realism, and that VLMs generate human-like questions but fall short of humans when answering them.
Significance. If the correlations prove robust and question coverage is comprehensive, PQSG would supply a much-needed granular, automated diagnostic for localizing physical-law violations in generated videos—an increasingly relevant capability as video models improve. The FinePhyEval dataset itself constitutes a reusable benchmark resource for the community.
major comments (3)
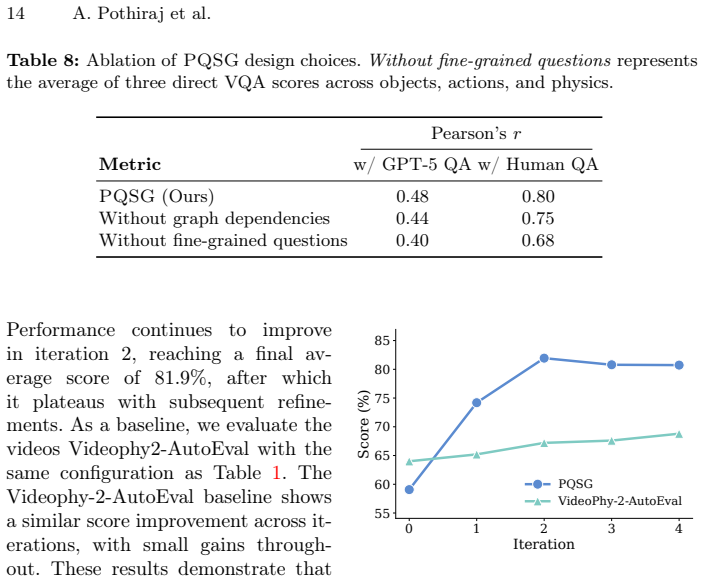
- [FinePhyEval validation] Validation on FinePhyEval: the claim that PQSG exhibits higher overall correlations with human judgments than prior work is central to the contribution, yet the manuscript provides no numerical correlation coefficients, confidence intervals, p-values, or inter-annotator agreement statistics for either PQSG or the baselines, preventing assessment of effect size and reliability.
- [PQSG pipeline] PQSG pipeline description: the method assumes that VLM-generated questions, even with in-context examples and graph dependencies, comprehensively and without systematic bias capture all relevant physical violations (e.g., fluid interactions, occlusion physics); no independent audit comparing VLM-generated questions against a human-authored gold-standard question set is reported, which directly bears on whether the resulting scores reliably measure physical plausibility.
- [FinePhyEval dataset] Human annotation protocol: details on how the multi-category human annotations in FinePhyEval were collected, including number of annotators per video, agreement metrics, and controls for prompt selection bias, are not supplied, undermining the strength of the external human-judgment ground truth used to validate PQSG.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one concrete correlation value to support the 'higher overall correlations' claim.
- [Method] Notation for the graph structure (nodes, edges, and dependency rules) could be formalized with a small diagram or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional detail and transparency will strengthen the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [FinePhyEval validation] Validation on FinePhyEval: the claim that PQSG exhibits higher overall correlations with human judgments than prior work is central to the contribution, yet the manuscript provides no numerical correlation coefficients, confidence intervals, p-values, or inter-annotator agreement statistics for either PQSG or the baselines, preventing assessment of effect size and reliability.
Authors: We agree that the absence of explicit numerical values, confidence intervals, p-values, and inter-annotator agreement limits the ability to assess effect size and statistical reliability. In the revised manuscript we will report the precise correlation coefficients (Pearson and Spearman) for PQSG and all baselines, together with confidence intervals, p-values, and inter-annotator agreement statistics. revision: yes
-
Referee: [PQSG pipeline] PQSG pipeline description: the method assumes that VLM-generated questions, even with in-context examples and graph dependencies, comprehensively and without systematic bias capture all relevant physical violations (e.g., fluid interactions, occlusion physics); no independent audit comparing VLM-generated questions against a human-authored gold-standard question set is reported, which directly bears on whether the resulting scores reliably measure physical plausibility.
Authors: The referee correctly observes that no independent audit against a human-authored gold-standard question set is provided. Our validation instead rests on the observed correlation between PQSG scores and human judgments of physical plausibility. We will add an explicit discussion of this limitation, including the possibility of systematic bias in question coverage, while noting that the higher human correlation offers indirect support for the questions' utility. A full gold-standard audit would require new human annotation and lies outside the scope of the present work. revision: partial
-
Referee: [FinePhyEval dataset] Human annotation protocol: details on how the multi-category human annotations in FinePhyEval were collected, including number of annotators per video, agreement metrics, and controls for prompt selection bias, are not supplied, undermining the strength of the external human-judgment ground truth used to validate PQSG.
Authors: We acknowledge that the current manuscript omits these protocol details. In the revision we will expand the FinePhyEval section to specify the number of annotators per video, the agreement metrics computed, and the procedures used for prompt selection and bias control. revision: yes
Circularity Check
No circularity; PQSG evaluation is grounded in independent human annotations on FinePhyEval
full rationale
The paper introduces PQSG as a VLM-driven hierarchical question graph for evaluating video physical plausibility and validates it by collecting new human annotations on a dataset of generated videos, then reporting correlations between PQSG scores and those human judgments. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation; the central empirical result is measured against external human labels rather than reducing to quantities defined by the method itself or prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language models can generate contextually valid, logically dependent questions about physical laws when guided by high-quality in-context examples.
- domain assumption Human annotations on physical categories provide reliable ground truth for evaluating physical plausibility.
invented entities (1)
-
Physics Question Scene Graph (PQSG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.00062 (2025) 8
Ali, A., Bai, J., Bala, M., Balaji, Y., Blakeman, A., Cai, T., Cao, J., Cao, T., Cha, E., Chao, Y.W., et al.: World simulation with video foundation models for physical ai. arXiv preprint arXiv:2511.00062 (2025) 8
Pith/arXiv arXiv 2025
-
[2]
ai / text - to - video / arena ? tab = leaderboard - text, accessed: Sept 1, 2025 8
Artificial Analysis: Text to video model arena (2025),https : / / artificialanalysis . ai / text - to - video / arena ? tab = leaderboard - text, accessed: Sept 1, 2025 8
2025
-
[3]
Bansal, H., Peng, C., Bitton, Y., Goldenberg, R., Grover, A., Chang, K.W.: Videophy-2: A challenging action-centric physical commonsense evaluation in video generation (2025) 4, 9, 13
2025
-
[4]
arXiv preprint arXiv:2405.04233 (2024) 4
Bao, F., Xiang, C., Yue, G., He, G., Zhu, H., Zheng, K., Zhao, M., Liu, S., Wang, Y., Zhu, J.: Vidu: a highly consistent, dynamic and skilled text-to-video generator with diffusion models. arXiv preprint arXiv:2405.04233 (2024) 4
arXiv 2024
-
[5]
CoRR (2023) 2
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. CoRR (2023) 2
2023
-
[6]
In: ICLR (2024) 4, 5, 8, 9, 10
Cho, J., Hu, Y., Baldridge, J.M., Garg, R., Anderson, P., Krishna, R., Bansal, M., Pont-Tuset, J., Wang, S.: Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation. In: ICLR (2024) 4, 5, 8, 9, 10
2024
-
[7]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Choi, Y.: Svad: From single image to 3d avatar via synthetic data generation with video diffusion and data augmentation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3137–3147 (2025) 2
2025
-
[8]
In: The Thirteenth International Conference on Learning Representations (2025) 13
Chow, W., Mao, J., Li, B., Seita, D., Guizilini, V.C., Wang, Y.: Physbench: Bench- marking and enhancing vision-language models for physical world understanding. In: The Thirteenth International Conference on Learning Representations (2025) 13
2025
-
[9]
Psychological assessment6(4), 284 (1994) 20
Cicchetti, D.V.: Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology. Psychological assessment6(4), 284 (1994) 20
1994
-
[10]
arXiv preprint arXiv:2506.01943 (2025) 2
Fu, X., Wang, X., Liu, X., Bai, J., Xu, R., Wan, P., Zhang, D., Lin, D.: Learning video generation for robotic manipulation with collaborative trajectory control. arXiv preprint arXiv:2506.01943 (2025) 2
arXiv 2025
-
[11]
Gemini Team: Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities (2025),https: //arxiv.org/abs/2507.062613, 7, 11
Pith/arXiv arXiv 2025
-
[12]
arXiv preprint arXiv:2505.19386 (2025) 4
Gillman, N., Herrmann, C., Freeman, M., Aggarwal, D., Luo, E., Sun, D., Sun, C.: Force prompting: Video generation models can learn and generalize physics-based control signals. arXiv preprint arXiv:2505.19386 (2025) 4
arXiv 2025
-
[13]
Google: Veo 3 (May 2025),https://aistudio.google.com/models/veo-33, 4, 8
2025
-
[14]
NeurIPS36, 66923–66939 (2023) 13
Hao, Y., Chi, Z., Dong, L., Wei, F.: Optimizing prompts for text-to-image gener- ation. NeurIPS36, 66923–66939 (2023) 13
2023
-
[15]
arXiv preprint arXiv:2509.24702 (2025) 4
Hao, Y., Chen, C., Mian, A.S., Xu, C., Liu, D.: Enhancing physical plausibility in video generation by reasoning the implausibility. arXiv preprint arXiv:2509.24702 (2025) 4
Pith/arXiv arXiv 2025
-
[16]
He, X., Jiang, D., Zhang, G., Ku, M., Soni, A., Siu, S., Chen, H., Chandra, A., Jiang, Z., Arulraj, A., et al.: Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation (2024) 4, 9
2024
-
[17]
In: EMNLP (2021) 4 Physics Question Scene Graph (PQSG) 17
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: CLIPScore: a reference- free evaluation metric for image captioning. In: EMNLP (2021) 4 Physics Question Scene Graph (PQSG) 17
2021
-
[18]
In: NIPS (2017) 2, 4
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Klambauer, G., Hochreiter, S.: GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In: NIPS (2017) 2, 4
2017
-
[19]
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models (2022) 4
2022
-
[20]
Advances in neural information processing systems33, 6840–6851 (2020) 4
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 4
2020
-
[21]
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: Cogvideo: Large-scale pretrain- ing for text-to-video generation via transformers (2022) 4
2022
-
[22]
arXiv preprint arXiv:2605.14269 (2026) 4
Huang, Y., Wang, Z., Lin, H., Kim, D.K., Omidshafiei, S., Yoon, J., Cho, J., Zhang, Y., Bansal, M.: Phymotion: Structured 3d motion reward for physics-grounded human video generation. arXiv preprint arXiv:2605.14269 (2026) 4
Pith/arXiv arXiv 2026
-
[23]
arXiv preprint arXiv:2511.17450 (2025) 4
Huang, Y., Wang, Z., Lin, H., Kim, D.K., Omidshafiei, S., Yoon, J., Zhang, Y., Bansal, M.: Planning with sketch-guided verification for physics-aware video gen- eration. arXiv preprint arXiv:2511.17450 (2025) 4
arXiv 2025
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024) 2
2024
-
[25]
Behavioral and brain sciences40, e253 (2017) 1
Lake, B.M., Ullman, T.D., Tenenbaum, J.B., Gershman, S.J.: Building machines that learn and think like people. Behavioral and brain sciences40, e253 (2017) 1
2017
-
[26]
biometrics pp
Landis, J.R., Koch, G.G.: The measurement of observer agreement for categorical data. biometrics pp. 159–174 (1977) 20
1977
-
[27]
arXiv preprint arXiv:2411.15115 (2024) 3
Lee, D., Yoon, J., Cho, J., Bansal, M.: Self-correcting text-to-video generation with misalignment detection and localized refinement. arXiv preprint arXiv:2411.15115 (2024) 3
Pith/arXiv arXiv 2024
-
[28]
arXiv preprint arXiv:2503.09595 (2025) 4
Li, C., Michel, O., Pan, X., Liu, S., Roberts, M., Xie, S.: Pisa experiments: Explor- ing physics post-training for video diffusion models by watching stuff drop. arXiv preprint arXiv:2503.09595 (2025) 4
arXiv 2025
-
[29]
arXiv preprint arXiv:2504.15932 (2025) 4
Lin, W., Jia, L., Hu, W., Pan, K., Yue, Z., Zhao, W., Chen, J., Wu, F., Zhang, H.: Reasoning physical video generation with diffusion timestep tokens via reinforce- ment learning. arXiv preprint arXiv:2504.15932 (2025) 4
arXiv 2025
-
[30]
In: European Conference on Computer Vision (ECCV) (2024) 4
Liu, S., Ren, Z., Gupta, S., Wang, S.: Physgen: Rigid-body physics-grounded image-to-video generation. In: European Conference on Computer Vision (ECCV) (2024) 4
2024
-
[31]
Liu, Y., Cun, X., Liu, X., Wang, X., Zhang, Y., Chen, H., Liu, Y., Zeng, T., Chan, R., Shan, Y.: Evalcrafter: Benchmarking and evaluating large video generation models (2023) 4
2023
-
[32]
Transactions on Machine Learning Research (2024), https://openreview.net/forum?id=g12Gdl6aDL, featured Certification 13
Mañas, O., Astolfi, P., Hall, M., Ross, C., Urbanek, J., Williams, A., Agrawal, A., Romero-Soriano, A., Drozdzal, M.: Improving text-to-image consistency via auto- matic prompt optimization. Transactions on Machine Learning Research (2024), https://openreview.net/forum?id=g12Gdl6aDL, featured Certification 13
2024
-
[33]
In: ICML (2025) 4, 9, 10
Meng, F., Liao, J., Tan, X., Lu, Q., Shao, W., Zhang, K., Cheng, Y., Li, D., Luo, P.: Towards world simulator: Crafting physical commonsense-based benchmark for video generation. In: ICML (2025) 4, 9, 10
2025
-
[34]
Advances in Neural Information Pro- cessing Systems37, 123155–123181 (2024) 4
Montanaro, A., Savant Aira, L., Aiello, E., Valsesia, D., Magli, E.: Motioncraft: Physics-based zero-shot video generation. Advances in Neural Information Pro- cessing Systems37, 123155–123181 (2024) 4
2024
-
[35]
Pothiraj et al
Motamed, S., Culp, L., Swersky, K., Jaini, P., Geirhos, R.: Do generative video models understand physical principles? (2025) 2, 3, 4, 7 18 A. Pothiraj et al
2025
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ni, H., Egger, B., Lohit, S., Cherian, A., Wang, Y., Koike-Akino, T., Huang, S.X., Marks, T.K.: Ti2v-zero: Zero-shot image conditioning for text-to-video diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9015–9025 (2024) 4
2024
-
[37]
com/index/video-generation-models-as-world-simulators/2
OpenAI: Video generation models as world simulators (2024),https://openai. com/index/video-generation-models-as-world-simulators/2
2024
-
[38]
OpenAI: GPT-5 model (2025),https://openai.com/gpt-5/3, 7, 11
2025
-
[39]
OpenAI: Sora 2 (October 2025),https://openai.com/index/sora-2/3, 4, 8
2025
-
[40]
In: Forty-second International Conference on Machine Learning (2025) 2
Qin, Y., Shi, Z., Yu, J., Wang, X., Zhou, E., Li, L., Yin, Z., Liu, X., Sheng, L., Shao, J., et al.: Worldsimbench: Towards video generation models as world simulators. In: Forty-second International Conference on Machine Learning (2025) 2
2025
-
[41]
In: First Conference on Language Modeling (2024),https://openreview.net/forum?id=LFfktMPAci 12, 13
Ross, C., Hall, M., Romero-Soriano, A., Williams, A.: What makes a good metric? evaluating automatic metrics for text-to-image consistency. In: First Conference on Language Modeling (2024),https://openreview.net/forum?id=LFfktMPAci 12, 13
2024
-
[42]
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X.: Improved techniques for training gans (2016),https://arxiv.org/abs/1606. 034984
2016
-
[43]
In: Workshop on Reinforcement Learning Beyond Rewards@ Reinforcement Learning Conference 2025 (2025) 2
Soni, A., Venkataraman, S., Chandra, A., Fischmeister, S., Liang, P., Dai, B., Yang, S.: Videoagent: Self-improving video generation for embodied planning. In: Workshop on Reinforcement Learning Beyond Rewards@ Reinforcement Learning Conference 2025 (2025) 2
2025
-
[44]
Cognitive science14(1), 29–56 (1990) 2
Spelke, E.S.: Principles of object perception. Cognitive science14(1), 29–56 (1990) 2
1990
-
[45]
Visual Cognition (1995) 2
Spelke, E.S., Gutheil, G., Van de Walle, G.: The development of object perception. Visual Cognition (1995) 2
1995
-
[46]
arXiv preprint arXiv:2411.17189 (2024) 4
Tan, X., Jiang, Y., Li, X., Zong, Z., Xie, T., Yang, Y., Jiang, C.: Physmotion: Physics-grounded dynamics from a single image. arXiv preprint arXiv:2411.17189 (2024) 4
arXiv 2024
-
[47]
Team Wan: Wan: Open and advanced large-scale video generative models (2025) 3, 8, 13
2025
-
[48]
Transactions of the Association for Computational Linguistics12, 1011–1026 (2024) 12, 13
Tjuatja, L., Chen, V., Wu, T., Talwalkwar, A., Neubig, G.: Do llms exhibit human- like response biases? a case study in survey design. Transactions of the Association for Computational Linguistics12, 1011–1026 (2024) 12, 13
2024
-
[49]
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards Accurate Generative Models of Video: A New Metric & Challenges (2019),https://arxiv.org/abs/1812.017174
Pith/arXiv arXiv 2019
-
[50]
arXiv preprint arXiv:2509.20358 (2025) 4
Wang, C., Chen, C., Huang, Y., Dou, Z., Liu, Y., Gu, J., Liu, L.: Physctrl: Genera- tive physics for controllable and physics-grounded video generation. arXiv preprint arXiv:2509.20358 (2025) 4
arXiv 2025
-
[51]
arXiv preprint arXiv:2511.03997 (2025) 4
Wang, P., Wang, W., Li, Q.: Physcorr: Dual-reward dpo for physics-constrained text-to-video generation with automated preference selection. arXiv preprint arXiv:2511.03997 (2025) 4
arXiv 2025
-
[52]
arXiv preprint arXiv:2505.21876 (2025) 4
Wang, Z., Cho, J., Li, J., Lin, H., Yoon, J., Zhang, Y., Bansal, M.: Epic: Efficient video camera control learning with precise anchor-video guidance. arXiv preprint arXiv:2505.21876 (2025) 4
Pith/arXiv arXiv 2025
-
[53]
arXiv preprint arXiv:2602.14941 (2026) 4 Physics Question Scene Graph (PQSG) 19
Wang, Z., Lin, H., Yoon, J., Cho, J., Zhang, Y., Bansal, M.: Anchorweave: World- consistent video generation with retrieved local spatial memories. arXiv preprint arXiv:2602.14941 (2026) 4 Physics Question Scene Graph (PQSG) 19
arXiv 2026
-
[54]
arXiv preprint arXiv:2503.23368 (2025) 4
Yang, X., Li, B., Zhang, Y., Yin, Z., Bai, L., Ma, L., Wang, Z., Cai, J., Wong, T.T., Lu, H., et al.: Vlipp: Towards physically plausible video generation with vision and language informed physical prior. arXiv preprint arXiv:2503.23368 (2025) 4
arXiv 2025
-
[55]
In: The Thirteenth International Conference on Learning Representations (2024) 4
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. In: The Thirteenth International Conference on Learning Representations (2024) 4
2024
-
[56]
ACM Computing Surveys58(12), 1–41 (2026) 2
Yin, Z., Chen, K., Bai, X., Jiang, R., Li, J., Li, H., Liu, J., Xiang, Y., Yu, J., Zhang, M.: A survey: spatiotemporal consistency in video generation. ACM Computing Surveys58(12), 1–41 (2026) 2
2026
-
[57]
moderate,
Zhou, S., Vilesov, A., He, X., Wan, Z., Zhang, S., Nagachandra, A., Chang, D., Chen, D., Wang, X.E., Kadambi, A.: Vlm4d: Towards spatiotemporal awareness in vision language models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8600–8612 (2025) 13 Appendix A Human Annotation Details In this section, we describe our annota...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.