ESTANet: Efficient Online Error Detection in Procedural Videos via Prediction Inconsistency
Pith reviewed 2026-06-25 21:25 UTC · model grok-4.3
The pith
Errors in procedural videos can be detected online by measuring inconsistencies among predictions from a small set of action detectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
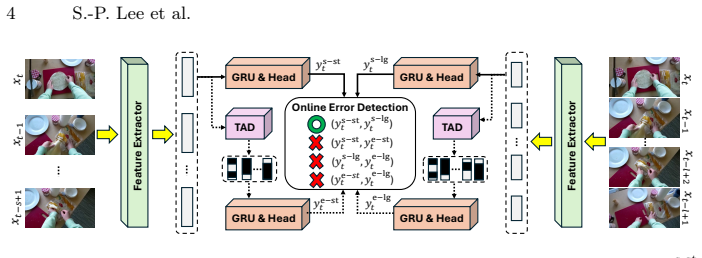
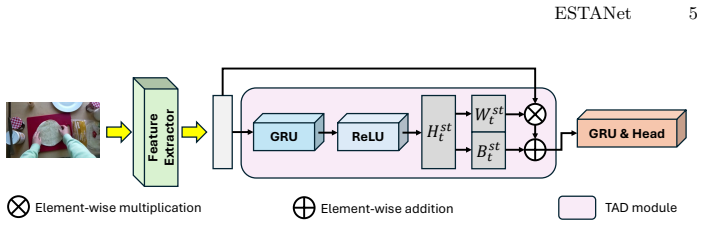
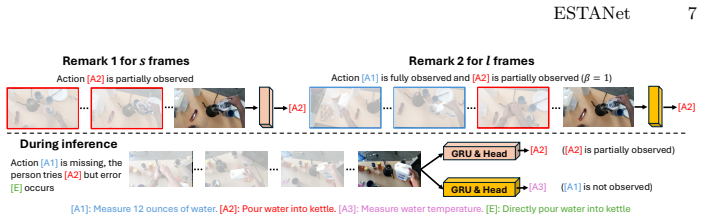
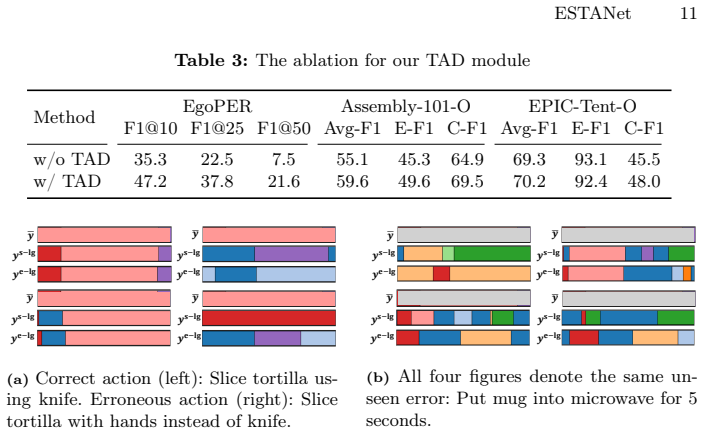
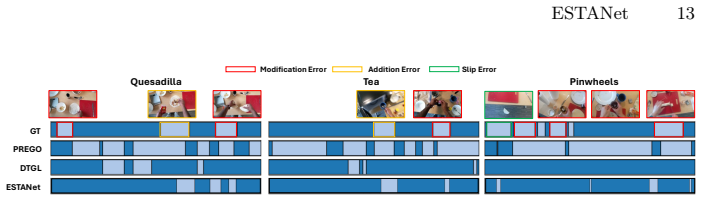
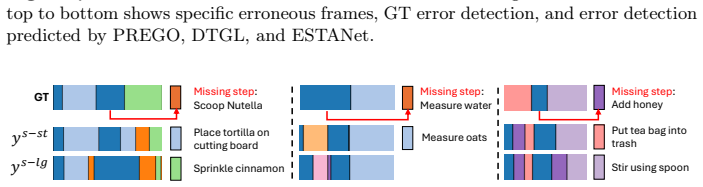
ESTANet detects errors by constructing standard and error-sensitive action detectors that behave similarly on correct executions but respond differently when errors occur, then amplifying inconsistencies with detectors that operate on different temporal contexts, and finally aggregating mismatches through majority voting to flag error frames during online inference.
What carries the argument
ESTANet framework that detects errors by aggregating prediction mismatches between standard, error-sensitive, and temporally varied action detectors via majority voting.
If this is right
- Online error detection becomes possible with existing action detectors and no specialized supervision.
- Real-time performance is maintained because the method adds only lightweight comparison and voting steps.
- The approach applies directly to any procedural video task where action detectors can be run in parallel.
- Detection accuracy improves when the temporal contexts of the detectors are chosen to differ substantially.
Where Pith is reading between the lines
- The same mismatch principle could be tested on non-procedural anomaly detection tasks such as surveillance or robotics failures.
- Existing pretrained action models might be reused without retraining simply by varying their input temporal windows.
- The voting step could be replaced by learned fusion if labeled error data later becomes available.
- This technique might lower the data requirements for training human-assistance systems that correct user mistakes.
Load-bearing premise
Action detectors will naturally produce sufficiently different predictions on error frames versus correct frames so that majority voting on mismatches can reliably identify errors.
What would settle it
On the EgoPER, Assembly-101-O or EPIC-Tent-O test sets, the standard and error-sensitive detectors produce nearly identical predictions on frames containing known errors, or majority voting fails to mark most of those frames as errors.
Figures

read the original abstract
An efficient and accurate system for detecting errors in procedural tasks is crucial for supporting human needs in daily life, as it can provide instant notifications and guide people to correct mistakes. In this work, we study real-time online error detection in procedural videos from a simple but overlooked perspective: the prediction behavior of action detectors themselves. Instead of designing complex architectures or specialized supervision, we observe that action detectors naturally exhibit different prediction characteristics depending on their sensitivity to input dynamics and temporal context. We therefore propose ESTANet (Error-Sensitive and Temporally-vArying Network), a lightweight framework that detects errors by exploiting inconsistencies among action predictions produced by a small set of action detectors. We construct standard and error-sensitive action detectors that behave similarly on correct executions but respond differently when errors occur. Meanwhile, detectors operating with different temporal contexts further amplify prediction inconsistencies when the procedure deviates from the intended sequence. During inference, we detect errors by aggregating mismatches between standard and error-sensitive predictions through majority voting to flag frames that contain errors. Extensive experiments on EgoPER, Assembly-101-O, and EPIC-Tent-O demonstrate that ESTANet achieves state-of-the-art performance in online error detection while maintaining real-time efficiency with a lightweight architecture. Our results highlight that leveraging the intrinsic properties of action detectors can yield a powerful and practical solution for online error detection without increasing architectural design complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ESTANet, a lightweight framework for real-time online error detection in procedural videos. It constructs standard and error-sensitive action detectors (with differing temporal contexts) that are claimed to behave similarly on correct executions but produce inconsistent predictions on errors; errors are then flagged via majority-vote aggregation of prediction mismatches. The method is presented as requiring no specialized supervision or complex architectures, and extensive experiments are said to demonstrate state-of-the-art performance on EgoPER, Assembly-101-O, and EPIC-Tent-O while maintaining real-time efficiency.
Significance. If the central claim holds—that reliable error detection emerges from intrinsic prediction inconsistencies among unmodified or lightly varied action detectors without any error-specific tuning or labels—the result would be significant for practical deployment in assistive systems, as it avoids the cost of error-labeled data and heavy models. The approach also offers a falsifiable test of whether detector sensitivity differences can be leveraged in an unsupervised manner for procedural tasks.
major comments (2)
- [Abstract] Abstract: the claim of 'no specialized supervision' and that detectors 'naturally exhibit different prediction characteristics' is load-bearing for the entire contribution, yet the construction of the error-sensitive variant is not shown to be free of indirect error-data influence (e.g., hyperparameter selection or architecture choice validated on error-containing sequences). If any such validation occurred, the inconsistency signal becomes supervised and the majority-voting step no longer demonstrates unsupervised leverage.
- [Abstract] Abstract: SOTA performance is asserted on three datasets, but no quantitative results, error bars, ablation tables, or baseline comparisons are provided, preventing verification that reported gains are robust rather than post-hoc or dataset-specific.
minor comments (1)
- [Abstract] The abstract states 'extensive experiments demonstrate SOTA' without any metrics; the full manuscript should include at least one results table with numbers, standard deviations, and runtime measurements to support the efficiency claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we address each major comment point by point with honest responses based on the work presented.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'no specialized supervision' and that detectors 'naturally exhibit different prediction characteristics' is load-bearing for the entire contribution, yet the construction of the error-sensitive variant is not shown to be free of indirect error-data influence (e.g., hyperparameter selection or architecture choice validated on error-containing sequences). If any such validation occurred, the inconsistency signal becomes supervised and the majority-voting step no longer demonstrates unsupervised leverage.
Authors: The error-sensitive detectors are obtained by applying standard action-recognition backbones with altered temporal context lengths (shorter or longer receptive fields) relative to the standard detectors. These length choices follow well-established principles in the action-recognition literature regarding sensitivity to motion dynamics and are fixed prior to any exposure to the target datasets; no hyperparameter search, architecture selection, or validation step was performed on sequences that contain errors. All training uses only the standard action labels provided by the datasets, with no error annotations or error-specific signals involved at any stage. Consequently, the observed prediction inconsistencies on erroneous frames emerge from the intrinsic differences in temporal sensitivity rather than from any form of error-data supervision. revision: no
-
Referee: [Abstract] Abstract: SOTA performance is asserted on three datasets, but no quantitative results, error bars, ablation tables, or baseline comparisons are provided, preventing verification that reported gains are robust rather than post-hoc or dataset-specific.
Authors: The abstract serves as a high-level overview; all quantitative evidence—including per-dataset accuracies, comparisons against published baselines, ablation studies on the number and configuration of detectors, and statistical significance indicators—is reported in full in Section 4, accompanied by Tables 1–4 and Figures 3–6. We agree that embedding one or two headline numbers (e.g., “+4.2 % mAP on EgoPER”) would improve immediate readability of the abstract and will incorporate such figures in the revised version. revision: partial
Circularity Check
No significant circularity; empirical aggregation of detector outputs with no derivation chain reducing to fitted inputs
full rationale
The paper describes an empirical framework that constructs standard and error-sensitive detectors (via differing sensitivity to dynamics and temporal context) and aggregates prediction mismatches via majority voting. No equations, parameter fits, or self-citation chains are presented that reduce the claimed error-detection performance to the inputs by construction. The method is self-contained as a direct application of observed detector behaviors on external benchmarks (EgoPER, Assembly-101-O, EPIC-Tent-O), with no load-bearing self-definitional steps or uniqueness theorems imported from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Princeton University Press, Princeton, NJ (2008)
Absil, P.A., Mahony, R., Sepulchre, R.: Optimization Algorithms on Matrix Man- ifolds. Princeton University Press, Princeton, NJ (2008)
2008
-
[2]
In: IEEE International Conference on Computer Vision (2023)
An, J., Kang, H., Han, S.H., Yang, M.H., Kim, S.J.: Miniroad: Minimal rnn frame- work for online action detection. In: IEEE International Conference on Computer Vision (2023)
2023
-
[3]
Neural Information Process- ing Systems (2023)
Ashutosh, K., Ramakrishnan, S.K., Afouras, T., Grauman, K.: Video-mined task graphs for keystep recognition in instructional videos. Neural Information Process- ing Systems (2023)
2023
-
[4]
Arxiv (2018)
Battaglia, P.W., Hamrick, J.B., Bapst, V., Sanchez-Gonzalez, A., Zambaldi, V., Malinowski, M., Tacchetti, A., Raposo, D., Santoro, A., Faulkner, R., Gulcehre, C., Song, F., Ballard, A., Gilmer, J., Dahl, G., Vaswani, A., Allen, K., Nash, C., Langston, V., Dyer, C., Heess, N., Wierstra, D., Kohli, P., Botvinick, M., Vinyals, O., Li, Y., Pascanu, R.: Relati...
2018
-
[5]
Bertasius, G., Wang, H., Torresani, L.: Is space-time attention all you need for video understanding? In: Proceedings of the International Conference on Machine Learning (ICML) (July 2021)
2021
-
[6]
Ding, G., Sener, F., Ma, S., Yao, A.: Every mistake counts in assembly. arXiv: 2307.16453 (2023)
arXiv 2023
-
[7]
In: NeurIPS (2021)
Dvornik, N., Hadji, I., Derpanis, K.G., Garg, A., Jepson, A.D.: Drop-dtw: Aligning common signal between sequences while dropping outliers. In: NeurIPS (2021)
2021
-
[8]
IEEE Conference on Computer Vision and Pattern Recognition (2023)
Dvornik, N., Hadji, I., Zhang, R., Derpanis, K., Garg, A., Wildes, R., Jepson, A.: Stepformer: Self-supervised step discovery and localization in instructional videos. IEEE Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Eun, H., Moon, J., Park, J., Jung, C., Kim, C.: Learning to discriminate informa- tion for online action detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 809–818 (2020)
2020
-
[10]
In: Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition
Farha, Y.A., Gall, J.: Ms-tcn: Multi-stage temporal convolutional network for ac- tion segmentation. In: Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition. pp. 3575–3584 (2019)
2019
-
[11]
IEEE Conference on Computer Vision and Pattern Recognition (2024)
Flaborea, A., Melendugno, G., Pliniq, L., Scofanoq, L., Matteisq, E., Furnari, A., Farinella, G., Galasso, F.: Prego: online mistake detection in procedural egocentric videos. IEEE Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ghoddoosian, R., Dwivedi, I., Agarwal, N., Dariush, B.: Weakly-supervised action segmentation and unseen error detection in anomalous instructional videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10128–10138 (2023)
2023
-
[13]
Lee et al
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Ham- burger, J., Jiang, H., Liu, M., Liu, X., Martin, M., Nagarajan, T., Radosavovic, I., Ramakrishnan, S.K., Ryan, F., Sharma, J., Wray, M., Xu, M., Xu, E.Z., Zhao, C., Bansal, S., Batra, D., Cartillier, V., Crane, S., Do, T., Doulaty, M., Era- palli, A., Feichtenhofer, C., Frago...
2022
-
[14]
In: European Conference on Computer Vision (2022)
Guo, H., Ren, Z., Wu, Y., Hua, G., Ji, Q.: Uncertainty-based spatial-temporal attention for online action detection. In: European Conference on Computer Vision (2022)
2022
-
[15]
In: IEEE Conference on Computer Vision and Pattern Recognition (2025)
Huang, W.J., Li, Y.M., Xia, Z.W., Tang, Y.M., Lin, K.Y., Hu, J.F., Zheng, W.S.: Modeling multiple normal action representations for error detection in procedural tasks. In: IEEE Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, Y., Chen, G., Xu, J., Zhang, M., Yang, L., Pei, B., Zhang, H., Dong, L., Wang, Y., Wang, L., Qiao, Y.: Egoexolearn: A dataset for bridging asynchronous ego- and exo-centric view of procedural activities in real world. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 22072–22086 (June 2024)
2024
-
[17]
International Conference on Computer Vision Workshop (2019)
Jang, Y., Sullivan, B., Ludwig, C., Gilchrist, I., Damen, D., Mayol-Cuevas, W.: Epictent: An egocentric video dataset for camping tent assembly. International Conference on Computer Vision Workshop (2019)
2019
-
[18]
ICLR 2023 Workshop on Multimodal Representation Learning: Perks and Pitfalls (2023)
Jang, Y., Sohn, S., Logeswaran, L., Luo, T., Lee, M., Lee, H.: Multimodal subtask graph generation from instructional videos. ICLR 2023 Workshop on Multimodal Representation Learning: Perks and Pitfalls (2023)
2023
-
[19]
IEEE Conference on Computer Vision and Pattern Recognition (2024)
Lee, S., Lu, Z., Zhang, Z., Hoai, M., Elhamifar, E.: Error detection in egocen- tric procedural task videos. IEEE Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[20]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (jun 2022)
Li, M., Chen, L., Duarr, Y., Hu, Z., Feng, J., Zhou, J., Lu, J.: Bridge-prompt: Towards ordinal action understanding in instructional videos. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (jun 2022)
2022
-
[21]
IEEE Transactions on Pattern Analysis and Machine Intelligence pp
Li, S.J., AbuFarha, Y., Liu, Y., Cheng, M.M., Gall, J.: Ms-tcn++: Multi-stage temporal convolutional network for action segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence pp. 1–1 (2020).https://doi.org/10. 1109/TPAMI.2020.3021756
arXiv 2020
-
[22]
European Conference on Computer Vision (2024)
Li, Z., Chen, Q., Han, T., Zhan, Y., Wang, Y., Xie, W.: Multi-sentence grounding for long-term instructional video. European Conference on Computer Vision (2024)
2024
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, Y., Huo, J., Peng, J., Sparks, R., Dasgupta, P., Granados, A., Ourselin, S.: Skit: a fast key information video transformer for online surgical phase recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21074–21084 (2023)
2023
-
[24]
IEEE Conference on Computer Vision and Pattern Recognition (2024)
Lu, Z., Elhamifar, E.: Fact: Frame-action cross-attention temporal modeling for efficient action segmentation. IEEE Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[25]
Inter- national Conference on Computer Vision (2025)
Lu, Z., Elhamifar, E.: Multi-modal few-shot temporal action segmentation. Inter- national Conference on Computer Vision (2025)
2025
-
[26]
IEEE Conference on Computer Vision and Pattern Recognition (2025)
Lu,Z.,Iftekhar,A.,Mittal,G.,Meng,T.,Wang,X.,Zhao,C.,Kukkala,R.,Elhami- far, E., Chen, M.: Decafnet: Delegate and conquer for efficient temporal grounding in long videos. IEEE Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[27]
Neural Information Processing Systems (2024) ESTANet 17
Luigi Seminara, Giovanni Maria Farinella, A.F.: Differentiable task graph learning: Procedural activity representation and online mistake detection from egocentric videos. Neural Information Processing Systems (2024) ESTANet 17
2024
-
[28]
IEEE Con- ference on Computer Vision and Pattern Recognition (2024)
Mu, F., Mo, S., Li, Y.: Snag: Scalable and accurate video grounding. IEEE Con- ference on Computer Vision and Pattern Recognition (2024)
2024
-
[29]
In: IEEE Conference on Computer Vision and Pattern Recognition (2025)
Pang, Z., Sener, F., Yao, A.: Context-enhanced memory-refined transformer for online action detection. In: IEEE Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
Patsch, C., Wu, Y., Zakour, M., Salihu, D., Steinbach, E.: Mistsense: Versatile online detection of procedural and execution mistakes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
2025
-
[31]
Peddi, R., Arya, S., Challa, B., Pallapothula, L., Vyas, A., Gouripeddi, B., Wang, J., Zhang, Q., Komaragiri, V., Ragan, E., Ruozzi, N., Xiang, Y., Gogate, V.: Cap- tainCook4D: A Dataset for Understanding Errors in Procedural Activities (2024), https://arxiv.org/abs/2312.14556
arXiv 2024
-
[32]
In: Neural Information Processing Systems (2024)
Seminara, L., Farinella, G.M., Furnari, A.: Differentiable task graph learning: Pro- ceduralactivityrepresentationandonlinemistakedetectionfromegocentricvideos. In: Neural Information Processing Systems (2024)
2024
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sener, F., Chatterjee, D., Shelepov, D., He, K., Singhania, D., Wang, R., Yao, A.: Assembly101: A large-scale multi-view video dataset for understanding procedural activities. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21096–21106 (2022)
2022
-
[34]
IEEE Conference on Computer Vision and Pattern Recognition (2024)
Shen, Y., Elhamifar, E.: Progress-aware online action segmentation for egocen- tric procedural task videos. IEEE Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[35]
International Conference on Learning Represen- tations (2020)
Sohn, S., Woo, H., Choi, J., Lee, H.: Meta reinforcement learning with autonomous inference of subtask dependencies. International Conference on Learning Represen- tations (2020)
2020
-
[36]
PAMI (2021)
Souri,Y.,Fayyaz,M.,Minciullo,L.,Francesca,G.,Gall,J.:FastWeaklySupervised Action Segmentation Using Mutual Consistency. PAMI (2021)
2021
-
[37]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision
Wang, J., Chen, G., Huang, Y., Wang, L., Lu, T.: Memory-and-anticipation trans- former for online action understanding. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision. pp. 13824–13835 (2023)
2023
-
[38]
Wang, X., Zhang, S., Qing, Z., Shao, Y., Zuo, Z., Gao, C., Sang, N.: Oadtr: Online actiondetectionwithtransformers.In:ProceedingsoftheIEEE/CVFInternational Conference on Computer Vision. pp. 7565–7575 (2021)
2021
-
[39]
IEEE International Conference on Computer Vision (2023)
Wang, X., Kwon, T., Pan, M.R.B., Chakraborty, I., Andrist, S.: Holoassist: an egocentric human interaction dataset for interactive ai assistants in the real world. IEEE International Conference on Computer Vision (2023)
2023
-
[40]
In: Proceedings of the IEEE/CVF international conference on computer vision
Xu, M., Gao, M., Chen, Y.T., Davis, L.S., Crandall, D.J.: Temporal recurrent net- works for online action detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5532–5541 (2019)
2019
-
[41]
In: Advances in Neural Information Processing Systems (2021)
Xu, M., Xiong, Y., Chen, H., Li, X., Xia, W., Tu, Z., Soatto, S.: Long short- term transformer for online action detection. In: Advances in Neural Information Processing Systems (2021)
2021
-
[42]
arXiv (2024)
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wan, Y., Li...
2024
-
[43]
In: The British Machine Vision Conference (BMVC) (2021) 18 S.-P
Yi, F., Wen, H., Jiang, T.: Asformer: Transformer for action segmentation. In: The British Machine Vision Conference (BMVC) (2021) 18 S.-P. Lee et al
2021
-
[44]
In: European Conference on Computer Vision
Zhao, Y., Krähenbühl, P.: Real-time online video detection with temporal smooth- ing transformers. In: European Conference on Computer Vision. pp. 485–502. Springer (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.