Quantization Inflates Reasoning: Token Inflation as a Hidden Cost of Low-Bit Reasoning Models
Pith reviewed 2026-06-25 20:54 UTC · model grok-4.3
The pith
Low-bit post-training quantization makes reasoning models generate longer chains of thought even when accuracy stays the same.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Low-bit post-training quantization preserves accuracy on reasoning tasks but systematically increases the number of tokens used in the chain-of-thought, introducing a hidden inference-time cost that is captured by the CoT Token Inflation Ratio and visible in longer traces with more steps and repetition.
What carries the argument
The CoT Token Inflation Ratio, defined as the average ratio of reasoning-token counts between quantized and full-precision models across all evaluation benchmarks.
If this is right
- Accuracy alone is not sufficient to judge the efficiency of quantized reasoning models.
- End-to-end latency and energy use can rise even when per-token latency falls.
- Quantization-aware training reduces both accuracy degradation and token inflation more reliably than post-hoc prompting fixes.
Where Pith is reading between the lines
- Total energy budgets for large-scale inference deployments may need re-evaluation when quantized reasoning models are used.
- The same inflation pattern could appear under other compression methods such as pruning or distillation.
Load-bearing premise
The measured increase in reasoning length is produced by the quantization step itself rather than by differences in decoding settings, prompts, or benchmark construction.
What would settle it
An experiment that applies identical prompts, decoding parameters, and temperature to the same model before and after quantization and finds no statistically significant rise in average reasoning-token count would falsify the central claim.
Figures
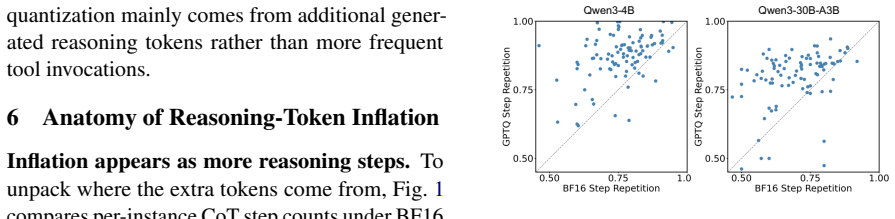
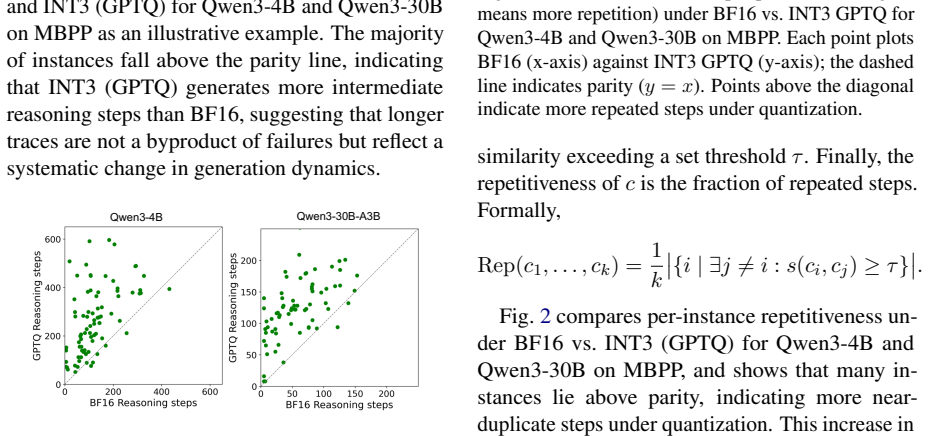
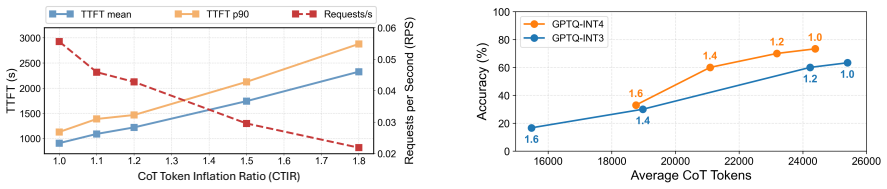
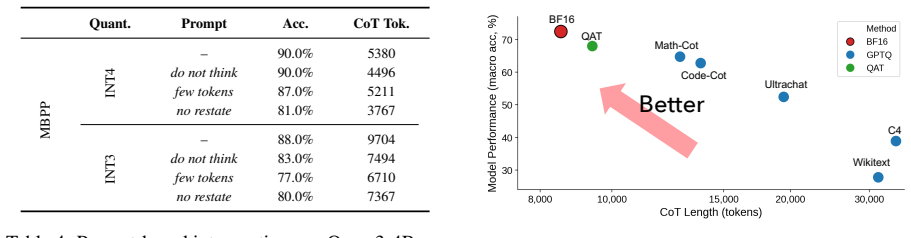
read the original abstract
Quantization is widely used to reduce the inference cost of large language models, but its effect on reasoning models is not fully captured by final-answer accuracy or per-token latency. We show that low-bit post-training quantization can introduce a hidden test-time compute cost: quantized reasoning models often generate longer chains of thought even when they still answer correctly. Across mathematical reasoning, code generation, scientific question answering, and agentic tool-use benchmarks, we find that INT4/INT3 quantization can preserve accuracy but increase reasoning-token usage, offsetting the expected per-token speedup. To measure this effect, we introduce the CoT Token Inflation Ratio, which compares reasoning length between quantized and full-precision models averaged across all evaluation benchmarks. We further show that token inflation is accompanied by behavioral changes in the reasoning trace, including more intermediate steps and greater semantic repetition. These changes translate into measurable end-to-end real-world serving penalties. Finally, we evaluate mitigation strategies and find that prompting and decoding-time sampling offer inconsistent accuracy-length trade-offs, while quantization-aware training shows more promise in reducing both accuracy degradation and token inflation. Our results suggest that reasoning-token usage should be reported alongside accuracy when evaluating quantized reasoning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that low-bit post-training quantization of reasoning models can preserve final-answer accuracy while increasing chain-of-thought token counts, introducing a hidden test-time compute cost. It introduces the CoT Token Inflation Ratio to quantify this effect across mathematical reasoning, code generation, scientific question answering, and agentic tool-use benchmarks, reports accompanying changes such as more intermediate steps and semantic repetition, demonstrates end-to-end serving penalties, and evaluates mitigation strategies including prompting, sampling, and quantization-aware training.
Significance. If the central empirical claim holds after addressing controls, the work is significant for showing that accuracy alone is an incomplete metric for quantized reasoning models and that token usage must be reported alongside it. The multi-benchmark empirical measurement and introduction of a concrete ratio are strengths; the observation of behavioral changes in traces adds value beyond latency considerations.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: the claim that quantization causes longer CoT on correctly answered questions is not supported by evidence that token lengths are conditioned on the intersection of questions solved correctly by both models or by paired per-question comparisons; without this, observed inflation could reflect differing success sets rather than per-instance behavioral change.
- [Abstract] Abstract: no information is supplied on statistical tests, variance across runs, or controls for confounding variables such as decoding hyperparameters, which prevents verification of the data-to-claim link for the reported inflation ratios.
- [Mitigation evaluation] Mitigation evaluation: the statement that quantization-aware training reduces both accuracy degradation and token inflation lacks reported effect sizes, confidence intervals, or ablation on the exact training configurations used, making the comparative claim difficult to assess.
minor comments (2)
- [Method] The exact mathematical definition of the CoT Token Inflation Ratio should be stated explicitly with an equation number rather than described only in prose.
- [Tables] Table captions should include the precise model sizes, bit widths, and benchmark subsets used for each reported ratio.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We have revised the manuscript to address the concerns regarding evidence for per-instance behavioral changes, statistical reporting, and mitigation evaluation details. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the claim that quantization causes longer CoT on correctly answered questions is not supported by evidence that token lengths are conditioned on the intersection of questions solved correctly by both models or by paired per-question comparisons; without this, observed inflation could reflect differing success sets rather than per-instance behavioral change.
Authors: We agree that aggregate comparisons alone leave open the possibility that inflation arises from differing success sets. In the revised manuscript we add (i) per-question paired token-length differences restricted to questions answered correctly by both models and (ii) explicit conditioning on the intersection set. These new analyses confirm that the inflation ratio remains positive and statistically detectable on the common correct subset, supporting the per-instance interpretation. revision: yes
-
Referee: [Abstract] Abstract: no information is supplied on statistical tests, variance across runs, or controls for confounding variables such as decoding hyperparameters, which prevents verification of the data-to-claim link for the reported inflation ratios.
Authors: We have expanded the Experiments section with (a) results from five independent runs using different random seeds, reporting mean inflation ratios together with standard deviations, (b) paired t-tests and Wilcoxon signed-rank tests on per-question token counts, and (c) an explicit statement that all compared models used identical decoding settings (greedy decoding, temperature = 0, top-p = 1). These additions directly link the reported ratios to controlled, reproducible measurements. revision: yes
-
Referee: [Mitigation evaluation] Mitigation evaluation: the statement that quantization-aware training reduces both accuracy degradation and token inflation lacks reported effect sizes, confidence intervals, or ablation on the exact training configurations used, making the comparative claim difficult to assess.
Authors: The revised Mitigation section now reports (i) absolute and relative effect sizes for both accuracy recovery and token-inflation reduction, (ii) 95 % confidence intervals obtained from the same multi-run protocol, and (iii) a full ablation table varying learning rate, number of epochs, and calibration-set size for the QAT procedure. These additions allow quantitative assessment of the mitigation claim. revision: yes
Circularity Check
No circularity: direct empirical measurements with no derivations or self-referential definitions
full rationale
The paper presents an empirical study measuring token lengths in quantized vs. full-precision models across benchmarks. It defines the CoT Token Inflation Ratio explicitly as a comparison of observed reasoning lengths, with no equations, fitted parameters, or predictions that reduce to inputs by construction. No self-citations are invoked as load-bearing premises, uniqueness theorems, or ansatzes. The central claim rests on reported measurements rather than any derivation chain that collapses to tautology. This is self-contained empirical reporting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CVPR '12 , year =
Lempitsky, Victor , title =. CVPR '12 , year =
-
[2]
Proceedings of the 8th USENIX Conference on Hot Topics in Storage and File Systems , series =
Kim, Hyeong-Jun and Lee, Young-Sik and Kim, Jin-Soo , title =. Proceedings of the 8th USENIX Conference on Hot Topics in Storage and File Systems , series =. 2016 , location =
2016
-
[3]
TPAMI 2011 , year =
Jegou, Herve and Douze, Matthijs and Schmid, Cordelia , booktitle =. TPAMI 2011 , year =
2011
-
[4]
Conference of the European Chapter of the Association for Computational Linguistics , year=
What Makes Medical Claims (Un)Verifiable? Analyzing Entity and Relation Properties for Fact Verification , author=. Conference of the European Chapter of the Association for Computational Linguistics , year=
-
[5]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[6]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[7]
Lin, Jimmy and Ma, Xueguang and Lin, Sheng-Chieh and Yang, Jheng-Hong and Pradeep, Ronak and Nogueira, Rodrigo , title =. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2021 , isbn =. doi:10.1145/3404835.3463238 , abstract =
-
[8]
Fleet , title =
Mohammad Norouzi and David J. Fleet , title =. CVPR 2013 , Xpages =
2013
-
[9]
CVPR 2013 , Xpages =
Tiezheng Ge and Kaiming He and Qifa Ke and Jian Sun , title =. CVPR 2013 , Xpages =
2013
-
[10]
Avrithis , title =
Yannis Kalantidis and Yannis S. Avrithis , title =
-
[11]
Information Systems , pages =
Yury Malkov and Alexander Ponomarenko and Andrey Logvinov and Vladimir Krylov , title =. Information Systems , pages =
-
[12]
Malkov and D
Yury A. Malkov and D. A. Yashunin , title =. CoRR , volume =
-
[13]
Frank Hsu and Xiaojie Lan and Gabriel Miller and David Baird , title =
D. Frank Hsu and Xiaojie Lan and Gabriel Miller and David Baird , title =. DASC'17 , Xpages =
-
[14]
2016 , location =
Mueller, Jonas and Thyagarajan, Aditya , title =. 2016 , location =
2016
-
[15]
Proceedings of the Seventh International Conference on World Wide Web 7 , series =
Brin, Sergey and Page, Lawrence , title =. Proceedings of the Seventh International Conference on World Wide Web 7 , series =. 1998 , location =
1998
-
[16]
Proceedings of the Sixth ACM International Conference on Web Search and Data Mining , series =
Risvik, Knut Magne and Chilimbi, Trishul and Tan, Henry and Kalyanaraman, Karthik and Anderson, Chris , title =. Proceedings of the Sixth ACM International Conference on Web Search and Data Mining , series =. 2013 , isbn =
2013
-
[17]
Barla and Baeza-Yates, Ricardo , title =
Cambazoglu, B. Barla and Baeza-Yates, Ricardo , title =. Proceedings of the 37th International ACM SIGIR Conference on Research &\#38; Development in Information Retrieval , series =. 2014 , isbn =. doi:10.1145/2600428.2602291 , acmid =
-
[18]
CIKM '13 , year =
Huang, Po-Sen and He, Xiaodong and Gao, Jianfeng and Deng, Li and Acero, Alex and Heck, Larry , title =. CIKM '13 , year =
-
[19]
Andoni, Alexandr and Indyk, Piotr and Razenshteyn, Ilya , journal=
-
[20]
Junaid Shuja and Kashif Bilal and Sajjad Ahmad Madani and Mazliza Othman and Rajiv Ranjan and Pavan Balaji and Samee Ullah Khan , title =. 2016 , url =. doi:10.1109/JSYST.2014.2315823 , timestamp =
-
[21]
Andersen and Michael Kaminsky , title =
Hyeontaek Lim and Bin Fan and David G. Andersen and Michael Kaminsky , title =
-
[22]
David Lo and Liqun Cheng and Rama Govindaraju and Parthasarathy Ranganathan and Christos Kozyrakis , title =. Proceedings of the 42nd Annual International Symposium on Computer Architecture, Portland, OR, USA, June 13-17, 2015 , pages =. 2015 , crossref =. doi:10.1145/2749469.2749475 , timestamp =
-
[23]
Communications of the ACM , issue_date =
Bentley, Jon Louis , title =. Communications of the ACM , issue_date =. 1975 , issn =
1975
-
[24]
, title =
Yianilos, Peter N. , title =. SODA '93 , year =
-
[25]
Lee, D. T. and Wong, C. K. , title =. Acta Informatica , issue_date =. 1977 , pages =
1977
-
[26]
Proceedings of the ACM Conference of the Special Interest Group on Data Communication , series =
Flach, Tobias and Dukkipati, Nandita and Terzis, Andreas and Raghavan, Barath and Cardwell, Neal and Cheng, Yuchung and Jain, Ankur and Hao, Shuai and Katz-Bassett, Ethan and Govindan, Ramesh , title =. Proceedings of the ACM Conference of the Special Interest Group on Data Communication , series =. 2013 , isbn =. doi:10.1145/2486001.2486014 , acmid =
-
[27]
Proceedings of the 32 Annual ACM Symposium on Theory of Computing , series =
Kleinberg, Jon , title =. Proceedings of the 32 Annual ACM Symposium on Theory of Computing , series =. 2000 , isbn =. doi:10.1145/335305.335325 , acmid =
-
[28]
Gray, R. M. and Neuhoff, D. L. , title =. IEEE Trans. Inf. Theor. , issue_date =. 2006 , issn =. doi:10.1109/18.720541 , acmid =
-
[29]
Mayur Datar and Nicole Immorlica and Piotr Indyk and Vahab S. Mirrokni , title =. Proceedings of the 20th. 2004 , crossref =. doi:10.1145/997817.997857 , timestamp =
-
[30]
VLDB'99 , pages =
Aristides Gionis and Piotr Indyk and Rajeev Motwani , title =. VLDB'99 , pages =
-
[31]
Lloyd , title =
Stuart P. Lloyd , title =
-
[32]
Similarity Search and Applications - 6th International Conference , series =
Leonid Boytsov and Bilegsaikhan Naidan , title =. Similarity Search and Applications - 6th International Conference , series =
-
[33]
and Shaeffer, Ian and Gopalakrishnan, Liji and Lo, David and Lee, Benjamin C
Malladi, Krishna T. and Shaeffer, Ian and Gopalakrishnan, Liji and Lo, David and Lee, Benjamin C. and Horowitz, Mark , title =. Proceedings of the 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture , series =. 2012 , isbn =
2012
-
[34]
Ding, Yufei and Zhao, Yue and Shen, Xipeng and Musuvathi, Madanlal and Mytkowicz, Todd , booktitle=
-
[35]
Proceedings of the 1995 ACM SIGMOD International Conference on Management of Data , series =
Roussopoulos, Nick and Kelley, Stephen and Vincent, Fr. Proceedings of the 1995 ACM SIGMOD International Conference on Management of Data , series =. 1995 , isbn =
1995
-
[36]
, title =
Watts, Duncan J. , title =. 1999 , Xisbn =
1999
-
[37]
IEEE Transactions on Knowledge and Data Engineering , year =
Wen Li and Ying Zhang and Yifang Sun and Wei Wang and Wenjie Zhang and Xuemin Lin , title =. IEEE Transactions on Knowledge and Data Engineering , year =
-
[38]
Golovin, Daniel and Solnik, Benjamin and Moitra, Subhodeep and Kochanski, Greg and Karro, John and Sculley, D. , title =. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , series =. 2017 , isbn =. doi:10.1145/3097983.3098043 , acmid =
-
[39]
Proceedings of the 18th ACM/IFIP/USENIX Middleware Conference , series =
Rasley, Jeff and He, Yuxiong and Yan, Feng and Ruwase, Olatunji and Fonseca, Rodrigo , title =. Proceedings of the 18th ACM/IFIP/USENIX Middleware Conference , series =. 2017 , isbn =. doi:10.1145/3135974.3135994 , acmid =
-
[40]
, title =
Lowe, David G. , title =. Int. J. Comput. Vision , issue_date =
-
[41]
Lempitsky , title =
Artem Babenko and Victor S. Lempitsky , title =
-
[42]
Lempitsky , title =
Artem Babenko and Victor S. Lempitsky , title =. CoRR , volume =. 2014 , url =
2014
-
[43]
Andersen, David G. and Swanson, Steven , title =. IEEE Micro , issue_date =. 2010 , issn =. doi:10.1109/MM.2010.71 , acmid =
-
[44]
Leventhal, Adam , title =. Commun. ACM , issue_date =. 2008 , issn =. doi:10.1145/1364782.1364796 , acmid =
-
[45]
Matthews, Jeanna and Trika, Sanjeev and Hensgen, Debra and Coulson, Rick and Grimsrud, Knut , title =. Trans. Storage , issue_date =. 2008 , issn =. doi:10.1145/1367829.1367830 , acmid =
-
[46]
Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval , series =
Wang, Jianguo and Lo, Eric and Yiu, Man Lung and Tong, Jiancong and Wang, Gang and Liu, Xiaoguang , title =. Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval , series =. 2013 , isbn =
2013
-
[47]
Wang, Jianguo and Lo, Eric and Yiu, Man Lung and Tong, Jiancong and Wang, Gang and Liu, Xiaoguang , title =. ACM Trans. Inf. Syst. , issue_date =. 2014 , issn =. doi:10.1145/2661629 , acmid =
-
[48]
Thomas Claburn , title =
-
[49]
2008 , howpublished =
Miranda Miller , title =. 2008 , howpublished =
2008
-
[50]
Petersen, Casper and Simonsen, Jakob Grue and Lioma, Christina , title =
-
[51]
SIGIR '17 , year =
Goodwin, Bob and Hopcroft, Michael and Luu, Dan and Clemmer, Alex and Curmei, Mihaela and Elnikety, Sameh and He, Yuxiong , title =. SIGIR '17 , year =
-
[52]
CoRR , volume =
Jeff Johnson and Matthijs Douze and Herv. CoRR , volume =. 2017 , url =
2017
-
[53]
Ying Shan and Jian Jiao and Jie Zhu and J. C. Mao , title =. CoRR , volume =. 2018 , url =
2018
-
[54]
CoRR , volume =
Patrick Wieschollek and Oliver Wang and Alexander Sorkine. CoRR , volume =. 2017 , url =
2017
-
[55]
Zhang, Jialiang and Khoram, Soroosh and Li, Jing , booktitle=
-
[56]
Matthijs Douze and Herv
-
[57]
Biing. 1982 , crossref =. doi:10.1109/ICASSP.1982.1171604 , timestamp =
-
[58]
Proceedings of the 20th International Conference on World Wide Web,
Wei Dong and Moses Charikar and Kai Li , title =. Proceedings of the 20th International Conference on World Wide Web,. 2011 , crossref =. doi:10.1145/1963405.1963487 , timestamp =
-
[59]
2018 , howpublished =
Google AI Blog , title =. 2018 , howpublished =
2018
-
[60]
2018 , howpublished =
Bing blogs , title =. 2018 , howpublished =
2018
-
[61]
2018 , howpublished =
Adaline Lau , title =. 2018 , howpublished =
2018
-
[62]
2018 , howpublished =
Hamel Husain , title =. 2018 , howpublished =
2018
-
[63]
2018 , Xpages =
Matthijs Douze and Alexandre Sablayrolles and Herv. 2018 , Xpages =
2018
-
[64]
Lowe , title =
Marius Muja and David G. Lowe , title =. TPAMI 2014 , volume =
2014
-
[65]
Razenshteyn and Ludwig Schmidt , title =
Alexandr Andoni and Piotr Indyk and Thijs Laarhoven and Ilya P. Razenshteyn and Ludwig Schmidt , title =. Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015 , pages =
2015
-
[66]
Jure Leskovec and Rok Sosic , title =
-
[67]
Herve Jegou and Romain Tavenard and Matthijs Douze and Laurent Amsaleg , title =
-
[68]
ICMR 2015 , pages =
Shoou. ICMR 2015 , pages =
2015
-
[69]
Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015 , pages =
Xiang Zhang and Junbo Jake Zhao and Yann LeCun , title =. Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015 , pages =
2015
-
[70]
Human Language Technologies: Conference of the North American Chapter of the Association of Computational Linguistics , pages =
Tomas Mikolov and Wen. Human Language Technologies: Conference of the North American Chapter of the Association of Computational Linguistics , pages =
-
[71]
Accessed: 05-20-2019 , title =
2019
-
[72]
2018 , Xnote =
Microsoft AI & Research , month =. 2018 , Xnote =
2018
-
[73]
VLDB'19 , year =
Fu, Cong and Xiang, Chao and Wang, Changxu and Cai, Deng , title =. VLDB'19 , year =
-
[74]
FAQ: All about the Google RankBrain algorithm , author=
-
[75]
CoRR , volume =
Lei Yu and Karl Moritz Hermann and Phil Blunsom and Stephen Pulman , title =. CoRR , volume =. 2014 , Xurl =
2014
-
[76]
CIKM '16 , year =
Van Gysel, Christophe and de Rijke, Maarten and Kanoulas, Evangelos , title =. CIKM '16 , year =
-
[77]
Bruce Croft , title =
Mostafa Dehghani and Hamed Zamani and Aliaksei Severyn and Jaap Kamps and W. Bruce Croft , title =. SIGIR 2017 , pages =
2017
-
[78]
Bruce Croft , title =
Jiafeng Guo and Yixing Fan and Qingyao Ai and W. Bruce Croft , title =
-
[79]
Bhaskar Mitra and Fernando Diaz and Nick Craswell , title =
-
[80]
SIGIR 2017 , pages =
Chenyan Xiong and Zhuyun Dai and Jamie Callan and Zhiyuan Liu and Russell Power , title =. SIGIR 2017 , pages =
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.