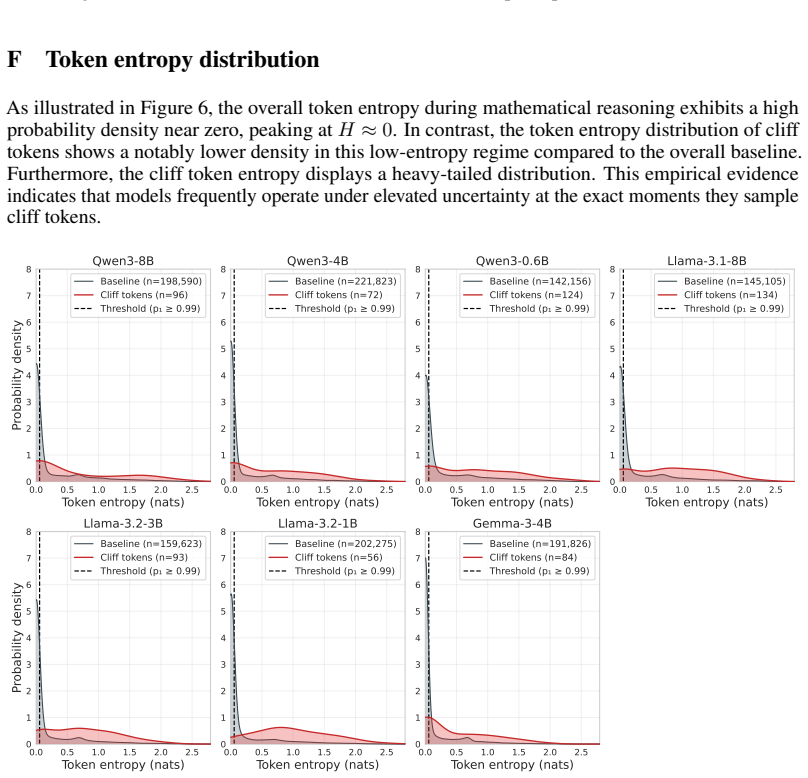
Cliff Tokens: Identifying Single-Token Failure Triggers in LLM Mathematical Reasoning
Pith reviewed 2026-06-26 05:22 UTC · model grok-4.3
The pith
Cliff tokens trigger failure in LLM math reasoning, with removal of the first one enabling perfect recovery via resampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
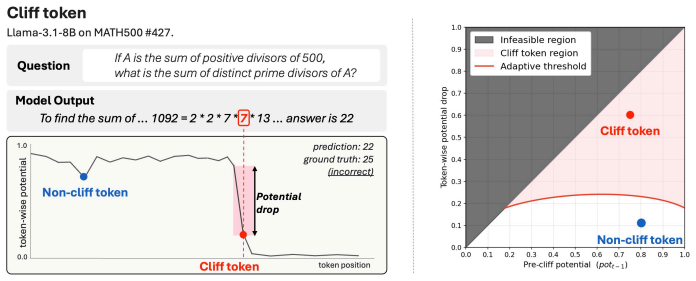
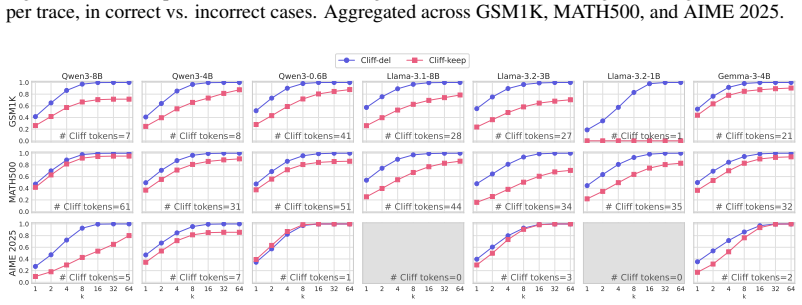
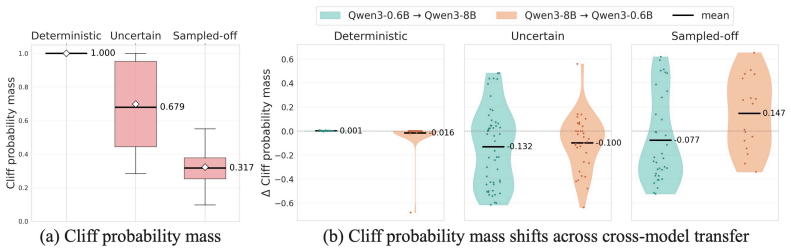
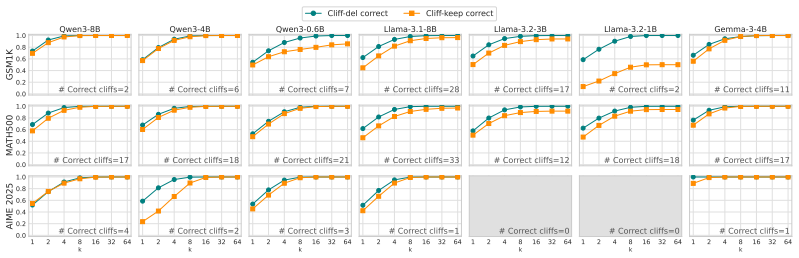
Cliff tokens are tokens at which the token-wise potential drops significantly under an adaptive threshold that scales with the local potential, isolated by a one-sided two-proportion z-test. In experiments on seven models and three benchmarks, the first cliff token acts as a failure trigger: deleting it and resampling recovers pass@64 to 1.0, but keeping it limits recovery to 0.71-1.00. A taxonomy of deterministic, uncertain, and sampled-off cliffs is introduced based on greedy choice and token entropy, and single-token preference optimization at cliff positions (Cliff-DPO) raises accuracy by up to 6.6 points, with gains from uncertain and sampled-off types.
What carries the argument
The cliff token, a token where token-wise potential drops significantly under an adaptive threshold based on a one-sided two-proportion z-test.
Load-bearing premise
The token-wise potential serves as a reliable proxy for the probability of eventually reaching a correct answer, allowing the z-test to isolate causal failure triggers.
What would settle it
A test showing that after deleting the identified first cliff token, resampling does not achieve higher success rates than when the token is retained, or that the potential drop does not predict failure probability.
Figures

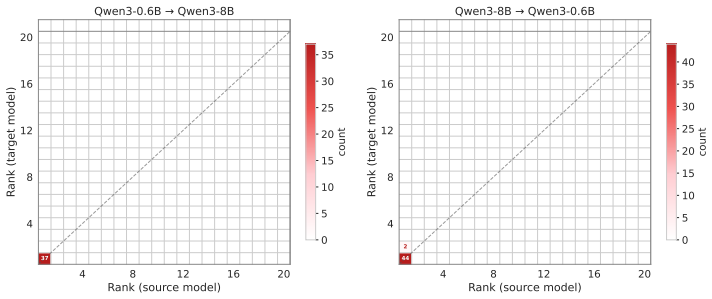
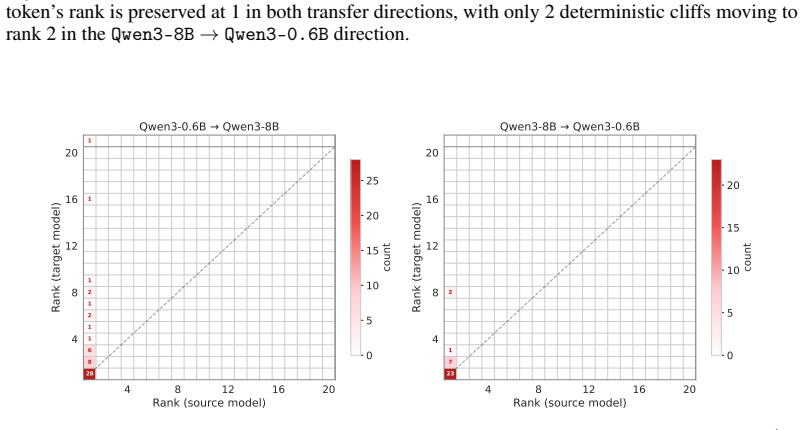
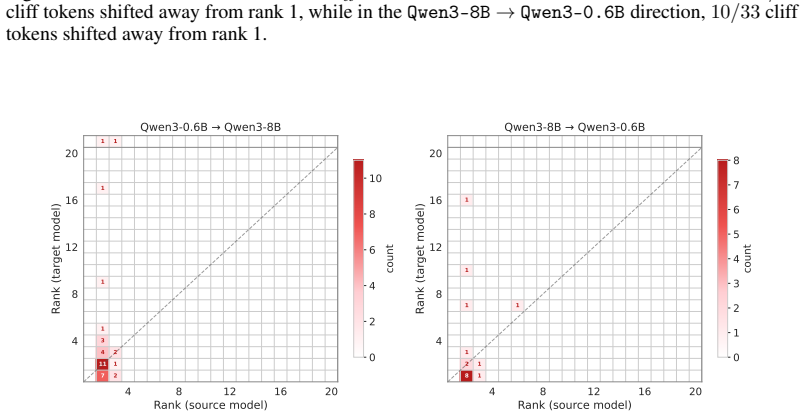
read the original abstract
Large language models (LLMs) reach high accuracy in mathematical reasoning, but individual traces on the same problem diverge; some arrive at the correct answer while others fail. Prior work analyzes failure at the step, chunk, or sentence level, or at tokens where failure has already occurred. Neither identifies the precise token that triggers the shift toward failure. We introduce the cliff token, a token where the token-wise potential drops significantly under an adaptive threshold that scales with the local token-wise potential, based on a one-sided two-proportion z-test. Across seven models and three mathematical reasoning benchmarks (GSM1K, MATH500, AIME 2025), cliff tokens act as failure triggers; deleting the first cliff token and resampling recovers pass@64 to 1.0, while keeping it limits recovery to between 0.71 and 1.00. We further introduce a cliff taxonomy of deterministic, uncertain, and sampled-off cliffs, defined by greedy choice and token entropy. Each type has distinct probabilistic characteristics, and the taxonomy generalizes across model scales. Finally, we validate the taxonomy via single-token preference optimization at cliff positions (Cliff-DPO). Trained on GSM8K, Cliff-DPO improves accuracy across benchmarks by up to +6.6. Optimizing at uncertain and sampled-off cliffs improves reasoning, while deterministic cliffs do not.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'cliff tokens' as single tokens in LLM mathematical reasoning traces where token-wise potential (estimated P(reach correct answer | prefix)) drops significantly, detected via a one-sided two-proportion z-test with an adaptive threshold scaling with local potential. Across seven models and benchmarks (GSM1K, MATH500, AIME 2025), the first cliff token is claimed to act as a failure trigger: deleting it and resampling recovers pass@64 to 1.0, while retaining it yields 0.71–1.00 recovery. A taxonomy (deterministic, uncertain, sampled-off) based on greedy choice and entropy is introduced, and Cliff-DPO (single-token preference optimization at cliff positions) trained on GSM8K yields accuracy gains up to +6.6 across benchmarks, with uncertain/sampled-off cliffs benefiting reasoning but deterministic ones not.
Significance. If the causal identification holds, the work provides a fine-grained, token-level diagnostic for reasoning failures with direct application to targeted mitigation via DPO, extending beyond step- or sentence-level analyses. Strengths include the multi-model/multi-benchmark empirical scope, the deletion-resampling experiment as a causal test, and the taxonomy's claimed generalization with differential DPO outcomes. These elements could inform interpretability methods if the potential proxy and z-test are validated as unbiased.
major comments (3)
- [§3] §3 (cliff token definition): The token-wise potential computation is not specified with sample counts per prefix, variance estimates, or confirmation that samples are independent of the failure traces used to identify cliffs. This is load-bearing for the central claim, as the one-sided z-test with adaptive threshold (scaling with local potential) must isolate causal triggers rather than post-hoc variance points; without these details the deletion+resample result (recovering to pass@64=1.0) cannot be interpreted as confirming the identified token as the trigger.
- [§4.2] §4.2 (deletion and resampling experiments): The reported recovery rates (pass@64=1.0 on deletion vs. 0.71–1.00 when keeping the cliff) lack controls for confounding factors such as prefix length, cliff position within the trace, or multiple-testing correction across sequentially tested tokens. The adaptive threshold and z-test significance level (a free parameter) are not fully specified, risking that flagged cliffs reflect selection effects rather than causal failure points.
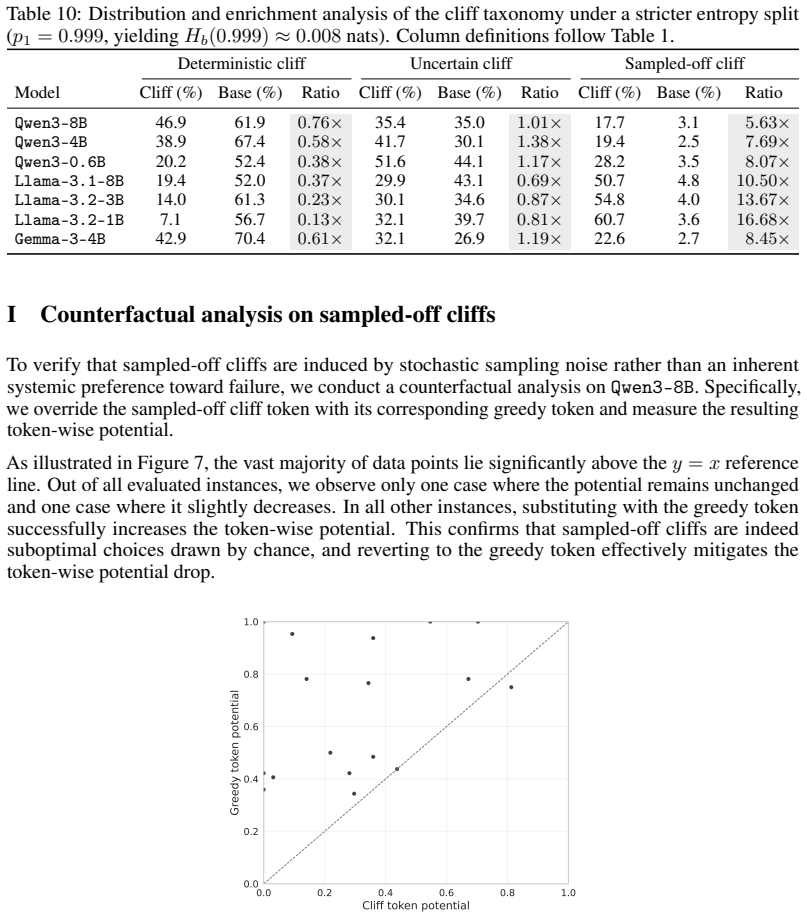
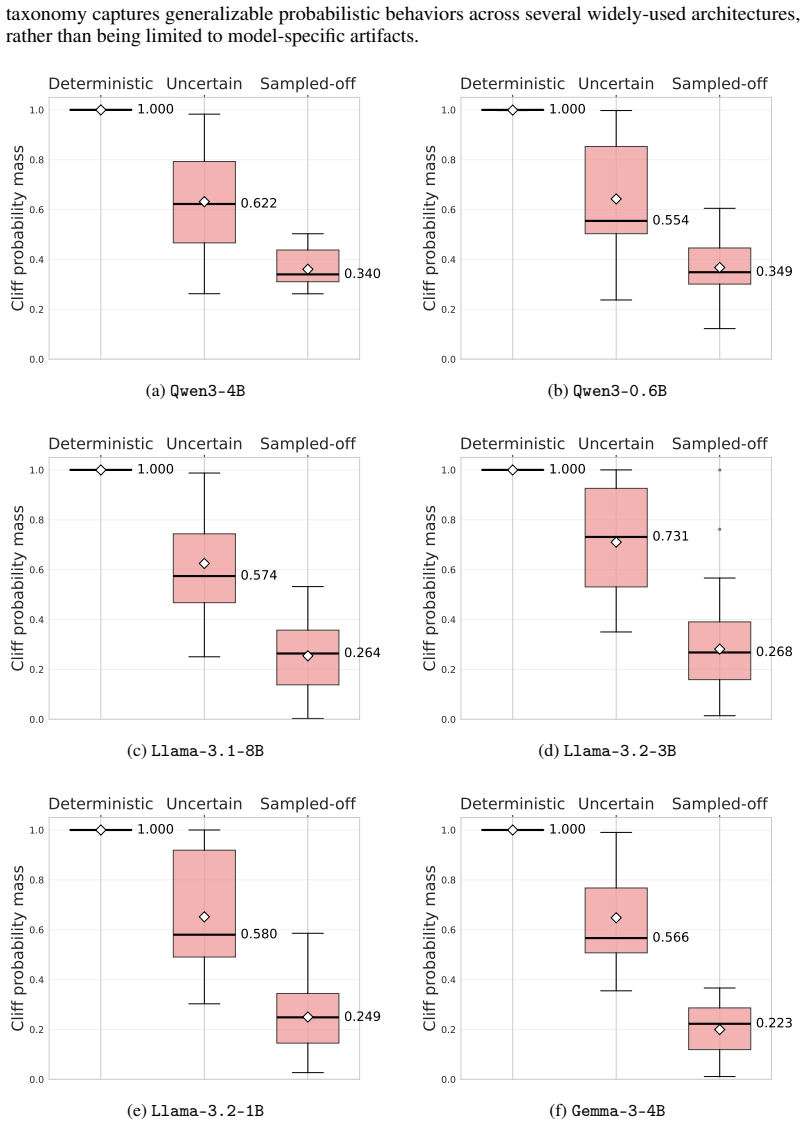
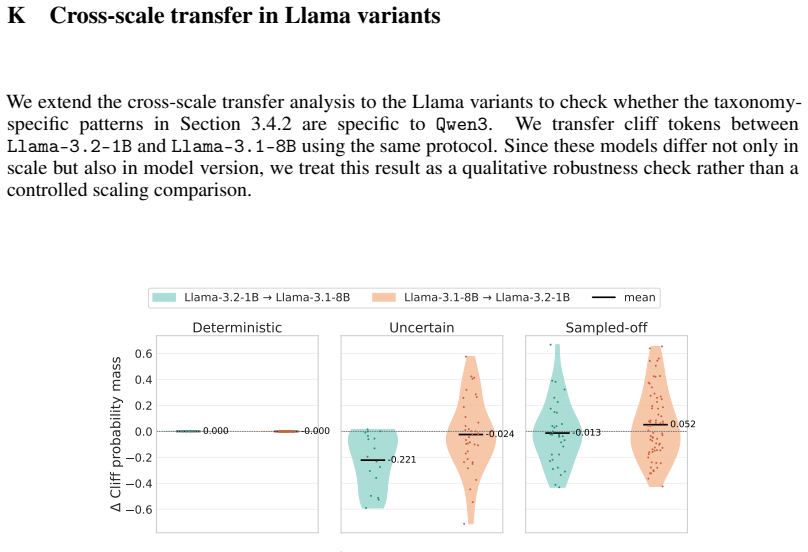
- [§4.3] §4.3 (Cliff-DPO validation): The taxonomy (deterministic/uncertain/sampled-off) is defined via greedy choice and token entropy, yet the paper does not report how many cliffs fall into each category or provide ablation showing that optimization at uncertain/sampled-off positions drives the +6.6 gain while deterministic ones do not; this weakens the claim that the taxonomy has distinct probabilistic characteristics generalizing across scales.
minor comments (2)
- The abstract and §4 should report exact sample sizes, confidence intervals, or trial counts underlying the pass@64 recovery figures and accuracy gains to allow assessment of effect stability.
- Figure captions and §3 notation for token-wise potential and the z-statistic could be clarified with explicit formulas or pseudocode for the adaptive threshold to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important points on methodological transparency and validation that we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (cliff token definition): The token-wise potential computation is not specified with sample counts per prefix, variance estimates, or confirmation that samples are independent of the failure traces used to identify cliffs. This is load-bearing for the central claim, as the one-sided z-test with adaptive threshold (scaling with local potential) must isolate causal triggers rather than post-hoc variance points; without these details the deletion+resample result (recovering to pass@64=1.0) cannot be interpreted as confirming the identified token as the trigger.
Authors: We will revise §3 to explicitly state that token-wise potential is estimated with 64 independent samples per prefix (separate from the original failure traces to ensure independence), using the standard binomial proportion variance for the z-test. The adaptive threshold is defined as scaling linearly with local potential (details in the updated text). These additions will allow readers to replicate the z-test procedure and interpret the causal evidence from the deletion experiments. revision: yes
-
Referee: [§4.2] §4.2 (deletion and resampling experiments): The reported recovery rates (pass@64=1.0 on deletion vs. 0.71–1.00 when keeping the cliff) lack controls for confounding factors such as prefix length, cliff position within the trace, or multiple-testing correction across sequentially tested tokens. The adaptive threshold and z-test significance level (a free parameter) are not fully specified, risking that flagged cliffs reflect selection effects rather than causal failure points.
Authors: We agree that additional controls strengthen the causal interpretation. In the revision we will add: (i) stratification by prefix length and cliff position showing consistent recovery patterns, (ii) explicit specification of α=0.05 and the adaptive threshold formula, and (iii) a note that identifying only the first cliff per trace limits the multiple-testing concern. The near-perfect recovery on deletion versus retention already provides strong evidence against pure selection effects, but the new controls will further address this. revision: partial
-
Referee: [§4.3] §4.3 (Cliff-DPO validation): The taxonomy (deterministic/uncertain/sampled-off) is defined via greedy choice and token entropy, yet the paper does not report how many cliffs fall into each category or provide ablation showing that optimization at uncertain/sampled-off positions drives the +6.6 gain while deterministic ones do not; this weakens the claim that the taxonomy has distinct probabilistic characteristics generalizing across scales.
Authors: We will include in the revision the empirical distribution of cliff types across models (e.g., percentages for deterministic/uncertain/sampled-off) and a new ablation table isolating the accuracy contribution of each category under Cliff-DPO. This will directly support the differential effect claim and the generalization statement. revision: yes
Circularity Check
No circularity: empirical definition and validation of cliff tokens
full rationale
The paper introduces cliff tokens via an explicit definition (token-wise potential drop detected by one-sided two-proportion z-test with adaptive threshold) and supports the failure-trigger claim through deletion/resampling experiments and Cliff-DPO training on independent benchmarks. No equations, fitted parameters, or self-citations reduce the central results to their own inputs by construction; the work is self-contained empirical methodology with external validation across models and datasets.
Axiom & Free-Parameter Ledger
free parameters (1)
- z-test significance level or scaling factor for adaptive threshold
axioms (1)
- domain assumption One-sided two-proportion z-test appropriately detects significant drops in token-wise potential as failure triggers.
invented entities (2)
-
cliff token
no independent evidence
-
cliff taxonomy (deterministic, uncertain, sampled-off)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
M. I. Abdin, J. Aneja, H. S. Behl, S. Bubeck, R. Eldan, S. Gunasekar, M. Harrison, R. J. Hewett, M. Javaheripi, P. Kauffmann, J. R. Lee, Y . T. Lee, Y . Li, W. Liu, C. C. T. Mendes, A. Nguyen, E. Price, G. de Rosa, O. Saarikivi, and 8 others. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
Pith/arXiv arXiv 2024
-
[2]
Bachmann, Y
G. Bachmann, Y . Jiang, S.-M. Moosavi-Dezfooli, and M. Nabi. The potential of cot for reasoning: A closer look at trace dynamics. InICLR, 2026
2026
-
[3]
E. J. Bigelow, A. Holtzman, H. Tanaka, and T. D. Ullman. Forking paths in neural text generation. In ICLR, 2025
2025
-
[4]
P. C. Bogdan, U. Macar, N. Nanda, and A. Conmy. Thought anchors: Which LLM reasoning steps matter? arXiv preprint arXiv:2506.19143, 2025
arXiv 2025
-
[5]
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[6]
Gemma Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, M. Rivière, L. Rouillard, T. Mesnard, G. Cideron, J. bastien Grill, S. Ramos, E. Yvinec, M. Casbon, E. Pot, I. Penchev, G. Liu, and 196 others. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
Pith/arXiv arXiv 2025
-
[7]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, and 538 others. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[8]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, X. Yu, Y . Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, and 175 others. Deepseek-R1 incentivizes reasoning in LLMs through reinforcement learning. InNature 645, 2025
2025
-
[9]
H. A. A. K. Hammoud, H. Itani, and B. Ghanem. Beyond the last answer: Your reasoning trace uncovers more than you think.arXiv preprint arXiv:2504.20708, 2025
arXiv 2025
-
[10]
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu, K. Dang, Y . Fan, Y . Zhang, A. Yang, R. Men, F. Huang, B. Zheng, Y . Miao, S. Quan, and 5 others. Qwen2.5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
Pith/arXiv arXiv 2024
-
[11]
T. Lanham, A. Chen, A. Radhakrishnan, B. Steiner, C. Denison, D. Hernandez, D. Li, E. Durmus, E. Hubinger, J. Kernion, K. Lukoši¯ut˙e, K. Nguyen, N. Cheng, N. Joseph, N. Schiefer, O. Rausch, R. Larson, S. McCandlish, S. Kundu, and 11 others. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
Pith/arXiv arXiv 2023
-
[12]
Lightman, V
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InICLR, 2024
2024
-
[13]
Z. Lin, T. Liang, J. Xu, Q. Liu, X. Wang, R. Luo, C. Shi, S. Li, Y . Yang, and Z. Tu. Critical tokens matter: Token-level contrastive estimation enhances LLM’s reasoning capability. InICML, 2025
2025
-
[14]
A. Liu, H. Bai, Z. Lu, Y . Sun, X. Kong, X. S. Wang, J. Shan, A. M. Jose, X. Liu, L. Wen, P. S. Yu, and M. Cao. TIS-DPO: Token-level importance sampling for direct preference optimization with estimated weights. InICLR, 2025. 10
2025
-
[15]
J. Liu, H. Liu, L. Xiao, Z. Wang, K. Liu, S. Gao, W. Zhang, S. Zhang, and K. Chen. Are your LLMs capable of stable reasoning? InFindings of ACL, 2025
2025
-
[16]
OpenAI, :, A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, A. Iftimie, A. Karpenko, A. T. Passos, A. Neitz, A. Prokofiev, A. Wei, A. Tam, A. Bennett, A. Kumar, and 243 others. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2026
Pith/arXiv arXiv 2026
-
[17]
AIME 2025
OpenCompass. AIME 2025. https://huggingface.co/datasets/opencompass/AIME2025, 2025. Hugging Face dataset
2025
-
[18]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. InNeurIPS, 2023
2023
-
[19]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[20]
J.-F. Ton, M. F. Taufiq, and Y . Liu. Understanding chain-of-thought in LLMs through information theory. InICLR, 2025
2025
-
[21]
P. Wang, L. Li, Z. Shao, R. X. Xu, D. Dai, Y . Li, D. Chen, Y . Wu, and Z. Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. InACL, 2024
2024
-
[22]
S. Wang, L. Yu, C. Gao, C. Zheng, S. Liu, R. Lu, K. Dang, X.-H. Chen, J. Yang, Z. Zhang, Y . Liu, A. Yang, A. Zhao, Y . Yue, S. Song, B. Yu, G. Huang, and J. Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. InNeurIPS, 2025
2025
-
[23]
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self- consistency improves chain of thought reasoning in language models. InICLR, 2023
2023
-
[24]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models. InNeurIPS, 2022
2022
-
[25]
S. Xing, S. Wang, C. Yang, X. Dai, and X. Ren. Lookahead tree-based rollouts for enhanced trajectory-level exploration in reinforcement learning with verifiable rewards. InICLR, 2026
2026
-
[26]
H. Xu, S. Chen, R. Qiu, Y . Yan, C. Luo, M. Cheng, J. He, and H. Tong. Prune as you generate: Online rollout pruning for faster and better rlvr.arXiv preprint arXiv:2603.24840, 2026
arXiv 2026
-
[27]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, and 41 others. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[28]
Y . Zeng, G. Liu, W. Ma, N. Yang, H. Zhang, and J. Wang. Token-level direct preference optimization. In ICML, 2024
2024
-
[29]
Zhang, J
H. Zhang, J. Da, D. Lee, V . Robinson, C. Wu, W. Song, T. Zhao, P. Raja, C. Zhuang, D. Slack, Q. Lyu, S. Hendryx, R. Kaplan, M. Lunati, and S. Yue. A careful examination of large language model performance on grade school arithmetic. InNeurIPS, 2024
2024
-
[30]
Zhang, G
K. Zhang, G. Li, J. Li, Y . Dong, J. Li, and Z. Jin. Focused-DPO: Enhancing code generation through focused preference optimization on error-prone points. InACL, 2025
2025
-
[31]
Zhang, X
Y . Zhang, X. Wang, L. Wu, and J. Wang. Characterizing and mitigating reasoning drift in large language models. InICLR, 2026
2026
-
[32]
C. Zhu, S. Wu, X. Zeng, Z. Xu, Z. Kang, Y . Guo, Y . Lu, J. Huang, and G. Zhou. Edis: Diagnosing LLM reasoning via entropy dynamics.arXiv preprint arXiv:2602.01288, 2026
arXiv 2026
-
[33]
M. Zhu, X. Chen, Z. Wang, B. Yu, H. Zhao, and J. Jia. TGDPO: Harnessing token-level reward guidance for enhancing direct preference optimization. InICML, 2025
2025
-
[34]
W. Zhu, J. Zhang, L. Yu, K. Yue, and Z. Tang. Dissecting failure dynamics in large language model reasoning.arXiv preprint arXiv:2604.14528, 2026
Pith/arXiv arXiv 2026
-
[35]
A. Zur, A. Geiger, E. S. Lubana, and E. J. Bigelow. Are language models aware of the road not taken? Token-level uncertainty and hidden state dynamics.arXiv preprint arXiv:2511.04527, 2025. Accepted at the Workshop on Actionable Interpretability @ ICML 2025. 11 A Sensitivity analysis of the adaptive threshold To justify the selection of our baseline thres...
arXiv 2025
-
[36]
for full algorithmic details. 21 Auxiliary contrastive SFT modelsThe positive SFT adapter π+ is trained on one correct trace per problem (5,566 examples), while the negative SFT adapter π− is trained on all incorrect traces from the problems that have both correct and incorrect rollouts (9,963 examples), since multiple distinct failure modes exist for the...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.