SAC²-Net: Semantic Anchoring and Complementary-Consensus Fusion for Multimodal Micro-Expression Recognition
Pith reviewed 2026-06-25 21:27 UTC · model grok-4.3
The pith
Semantic anchors from action units align optical flow and motion magnification representations before complementary fusion for micro-expression recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
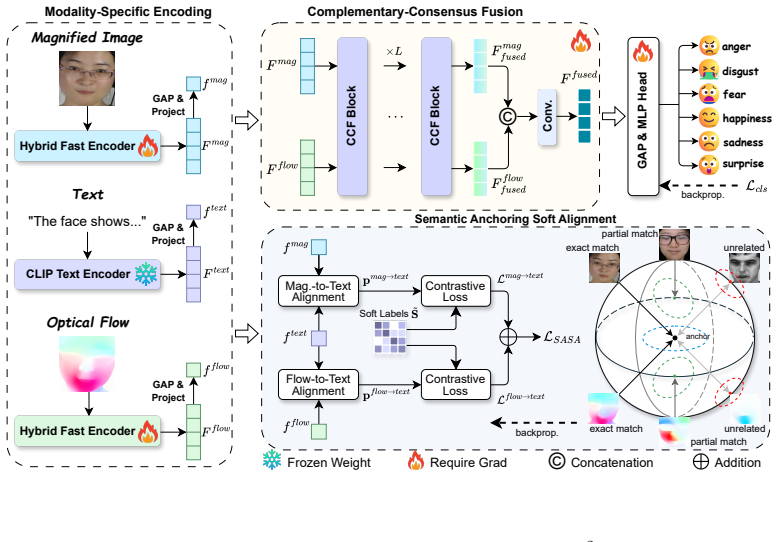
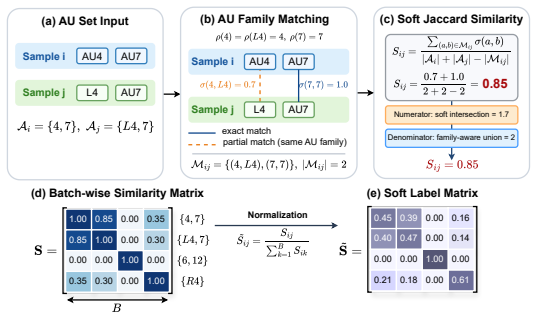
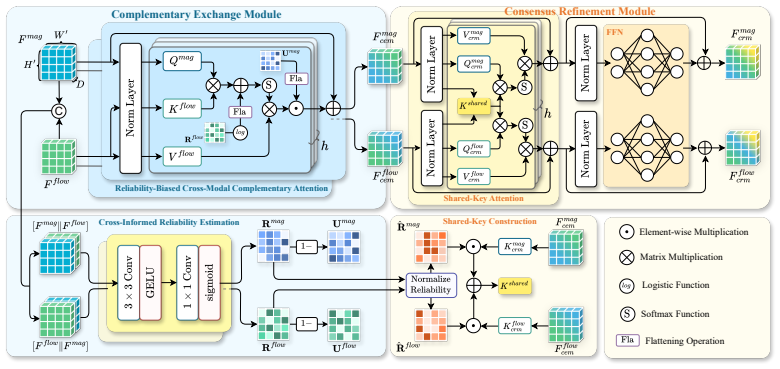
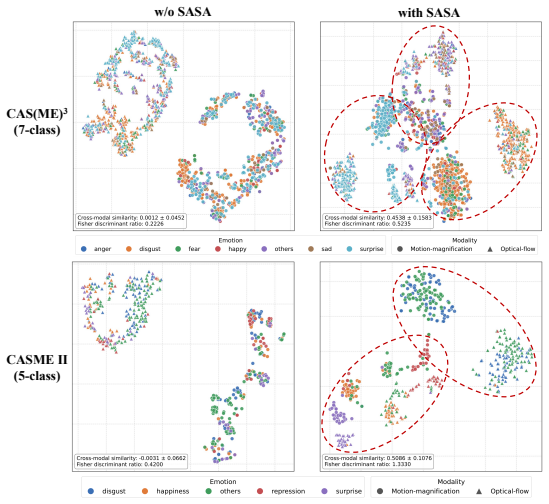
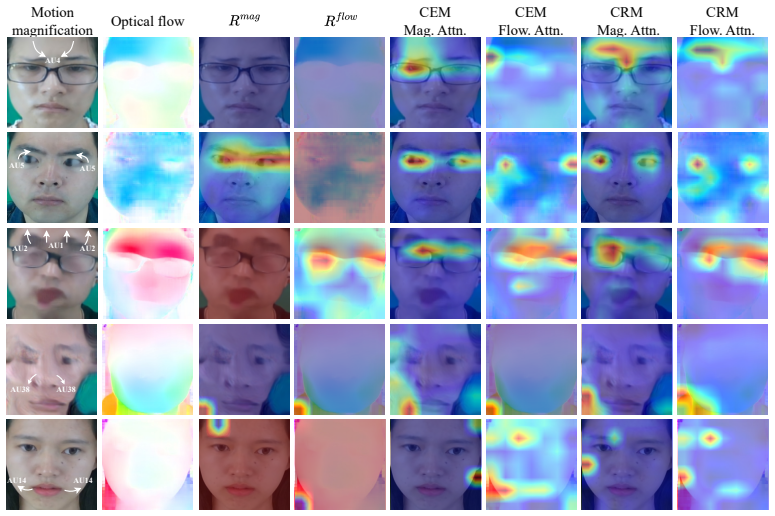
SAC²-Net converts activated AUs into textual prompts as semantic anchors, constructs hierarchical AU-aware soft labels for soft alignment of motion-magnified and optical-flow representations, then applies complementary exchange to repair unreliable local evidence followed by consensus refinement to enforce shared spatial focus, yielding state-of-the-art or competitive results on five MER benchmarks under multiple evaluation protocols.
What carries the argument
Semantic Anchoring Soft Alignment (SASA), which turns action units into textual prompts and hierarchical soft labels to align the two visual modalities, together with Complementary-Consensus Fusion (CCF), which performs reliability-aware repair and spatial consensus.
If this is right
- Fusion no longer requires identical spatial reliability across modalities.
- Performance gains hold under coarse-grained, fine-grained, large-scale, and cross-dataset protocols.
- Soft labels from overlapping AUs preserve semantic structure that hard alignment would discard.
Where Pith is reading between the lines
- The same anchoring strategy could transfer to other paired visual modalities whose reliability varies by input condition.
- Textual AU prompts might allow zero-shot transfer to emotion categories not seen during training.
- Ablating the hierarchical soft-label component versus hard contrastive loss would isolate the benefit of preserving AU proximity.
Load-bearing premise
The two input modalities exhibit asymmetric failure patterns whose complementarity becomes usable once the representations are aligned with action-unit semantic anchors.
What would settle it
On a held-out dataset, removing the semantic-anchor alignment step produces no drop or even an increase in recognition accuracy, or both modalities fail on exactly the same samples so that complementary exchange adds no value.
Figures

read the original abstract
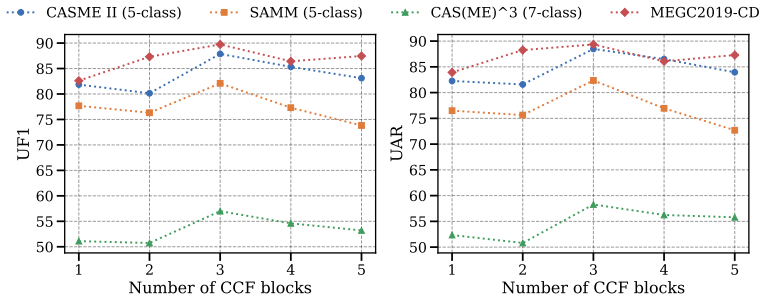
Micro-expression recognition (MER) is challenging due to subtle facial movements, limited data, and the ambiguous relationship between Action Units (AUs) and emotion categories. Optical flow and motion magnification have been widely used to describe subtle facial dynamics from different perspectives: the former captures local motion displacement, while the latter amplifies weak appearance changes. In this work, we observe that these two modalities often exhibit asymmetric failure patterns: one modality may become noisy, distorted, or uninformative, while the other still preserves discriminative AU-related evidence. This phenomenon reveals their complementarity, but also raises two key challenges for fusion: cross-modal heterogeneity and spatially varying modality reliability. Motivated by this observation, we propose SAC$^2$-Net, a Semantic Anchoring and Complementary-Consensus Network for multimodal MER, which first aligns visual modalities with semantic anchors and then performs reliability-aware fusion. To reduce cross-modal heterogeneity before fusion, we introduce Semantic Anchoring Soft Alignment (SASA), which converts activated AUs into textual prompts and uses them as stable semantic anchors to align motion-magnified and optical-flow representations. Unlike hard contrastive learning, SASA constructs hierarchical AU-aware soft labels to preserve semantic proximity among samples with overlapping or anatomically related AU patterns. Based on the aligned representations, Complementary-Consensus Fusion (CCF) first repairs unreliable local evidence through complementary exchange and then enforces a shared spatial focus through consensus refinement. Extensive experiments on five MER benchmarks show that SAC$^2$-Net achieves state-of-the-art or highly competitive performance across coarse-grained, fine-grained, large-scale, and cross-dataset evaluation settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SAC²-Net for multimodal micro-expression recognition, observing that optical flow and motion magnification modalities often exhibit asymmetric failure patterns. It proposes Semantic Anchoring Soft Alignment (SASA) to reduce cross-modal heterogeneity by converting activated AUs into hierarchical AU-aware soft textual prompts as semantic anchors, and Complementary-Consensus Fusion (CCF) to repair unreliable local evidence via complementary exchange followed by consensus refinement. The authors report that the resulting model achieves state-of-the-art or highly competitive performance on five MER benchmarks under coarse-grained, fine-grained, large-scale, and cross-dataset protocols.
Significance. If the empirical claims hold and the asymmetric-failure premise is substantiated, the work could advance multimodal MER by supplying a semantically grounded mechanism for handling modality heterogeneity and spatially varying reliability. The hierarchical soft-label construction in SASA is a potentially useful departure from standard contrastive alignment. The significance is nevertheless conditional on demonstrating that the observed complementarity is real, spatially varying, and directly addressable by the proposed components.
major comments (2)
- [Introduction] Introduction (observation paragraph): The central motivation—that optical flow and motion magnification 'often exhibit asymmetric failure patterns' with one modality noisy while the other preserves AU evidence—is stated without any quantitative support (modality-specific error breakdowns, per-sample reliability maps, or failure-case statistics). Because this premise directly motivates both SASA and CCF, its lack of empirical grounding is load-bearing for the architectural claims.
- [Experiments] Experiments section (ablation and analysis): No ablation isolating SASA+CCF performance specifically on samples exhibiting the claimed asymmetric modality failures is referenced. Without such targeted analysis, it is impossible to confirm that reported gains arise from exploiting the stated complementarity rather than generic fusion improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to incorporate the requested empirical grounding and targeted analysis.
read point-by-point responses
-
Referee: [Introduction] Introduction (observation paragraph): The central motivation—that optical flow and motion magnification 'often exhibit asymmetric failure patterns' with one modality noisy while the other preserves AU evidence—is stated without any quantitative support (modality-specific error breakdowns, per-sample reliability maps, or failure-case statistics). Because this premise directly motivates both SASA and CCF, its lack of empirical grounding is load-bearing for the architectural claims.
Authors: We agree that the observation of asymmetric failure patterns requires quantitative substantiation to support the motivation for SASA and CCF. In the revised manuscript, we will add modality-specific error breakdowns, per-sample reliability maps, and failure-case statistics from the five benchmarks to empirically ground this premise. revision: yes
-
Referee: [Experiments] Experiments section (ablation and analysis): No ablation isolating SASA+CCF performance specifically on samples exhibiting the claimed asymmetric modality failures is referenced. Without such targeted analysis, it is impossible to confirm that reported gains arise from exploiting the stated complementarity rather than generic fusion improvements.
Authors: We acknowledge that a targeted ablation on samples with asymmetric modality failures would more directly link the gains to the proposed components. In the revision, we will include an ablation study isolating SASA+CCF performance on such samples to demonstrate that the improvements arise from addressing the claimed complementarity. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained via empirical observation and experimental validation
full rationale
The paper motivates SASA and CCF from an empirical observation of asymmetric modality failures in optical flow and motion magnification, then validates the resulting architecture through experiments on five benchmarks. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided material. The central SOTA claim rests on benchmark results rather than reducing to a self-defined quantity or tautological premise. The observation of complementarity is presented as input motivation, not derived from the method itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
WW Norton & Company, 2009
Paul Ekman.Telling lies: Clues to deceit in the marketplace politics and marriage. WW Norton & Company, 2009
2009
-
[2]
Casme database: A dataset of spontaneous micro-expressions collected from neutralized faces
Wen-Jing Yan, Qi Wu, Yong-Jin Liu, Su-Jing Wang, and Xiaolan Fu. Casme database: A dataset of spontaneous micro-expressions collected from neutralized faces. In2013 10th IEEE international conference and workshops on automatic face and gesture recognition (FG), pages 1–7. IEEE, 2013. doi: https://doi.org/10.1109/FG.2013.6553799
-
[3]
Yante Li, Jinsheng Wei, Yang Liu, Janne Kauttonen, and Guoying Zhao. Deep learning for micro-expression recognition: A survey.IEEE Transactions on Affective Computing, 13(4):2028–2046, 2022. doi: https://doi.org/10.1109/TAFFC.2022.3205170
-
[4]
Paul Ekman and Wallace V Friesen. Facial action coding system. Environmental Psychology & Nonverbal Behavior, 1978. doi: https: //doi.org/10.1037/t27734-000
-
[5]
Sze-Teng Liong, Y. S. Gan, John See, Huai-Qian Khor, and Yen-Chang Huang. Shallow triple stream three-dimensional cnn (ststnet) for micro- expression recognition. In2019 14th IEEE International Conference on 27 Automatic Face & Gesture Recognition (FG 2019), pages 1–5, 2019. doi: https://doi.org/10.1109/FG.2019.8756567
-
[6]
Gan, Sze-Teng Liong, Wei-Chuen Yau, Yen-Chang Huang, and Lit- Ken Tan
Y.S. Gan, Sze-Teng Liong, Wei-Chuen Yau, Yen-Chang Huang, and Lit- Ken Tan. Off-apexnet on micro-expression recognition system.Signal Processing: Image Communication, 74:129–139, 2019. ISSN 0923-5965. doi: https://doi.org/10.1016/j.image.2019.02.005
-
[7]
Falin Wu, Yu Xia, Boyi Ma, Tianyang Hu, Jingyao Yang, Haoxin Li, and Di Huang. A micro-expression recognition network based on at- tention mechanism and motion magnification.IEEE Transactions on Affective Computing, 16(3):1379–1391, 2025. doi: https://doi.org/10. 1109/TAFFC.2024.3510302
arXiv 2025
-
[8]
Jianzhi Lu, Ruian He, Shili Zhou, Weimin Tan, and Bo Yan. Fa- cialflownet: Advancing facial optical flow estimation with a diverse dataset and a decomposed model. InProceedings of the 32nd ACM International Conference on Multimedia, pages 2194–2203, 2024. doi: https://doi.org/10.1145/3664647.3680921
-
[9]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-MichaelFrahm, editors,Computer Vision – ECCV 2020, pages402– 419, Cham, 2020. Springer International Publishing. ISBN 978-3-030- 58536-5. doi: https://doi.org/10.1007/978-3-030-58536-5_24
-
[10]
Yongtang Bao, Chenxi Wu, Peng Zhang, Caifeng Shan, Yue Qi, and Xianye Ben. Boosting micro-expression recognition via self-expression reconstruction and memory contrastive learning.IEEE Transactions on Affective Computing, 15(4):2083–2096, 2024. doi: https://doi.org/10. 1109/TAFFC.2024.3397701
arXiv 2083
-
[11]
Zhifeng Wang, Kaihao Zhang, Wenhan Luo, and Ramesh Sankara- narayana. Htnet for micro-expression recognition.Neurocomputing, 602: 128196, 2024. ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom. 2024.128196
-
[12]
Gaqiong Liu, Shucheng Huang, Gang Wang, and Mingxing Li. Emrnet: enhanced micro-expression recognition network with attention and dis- tance correlation.Artificial Intelligence Review, 58(6):176, 2025. doi: https://doi.org/10.1007/s10462-025-11159-0. 28
-
[13]
Chuang Ma, Shaokai Zhao, Dongdong Zhou, Yu Pei, Zhiguo Luo, Liang Xie, Ye Yan, and Erwei Yin. Mpfnet: A multi-prior fusion network with a progressive training strategy for micro-expression recognition. IEEE Transactions on Affective Computing, 17(1):348–365, 2026. doi: https://doi.org/10.1109/TAFFC.2025.3617652
-
[14]
Jie Zhu, Yuan Zong, Jingang Shi, Cheng Lu, Hongli Chang, and Wen- ming Zheng. Learning to rank onset-occurring-offset representations for micro-expression recognition.IEEE Transactions on Affective Comput- ing, 16(4):2690–2704, 2025. doi: https://doi.org/10.1109/TAFFC.2025. 3566113
-
[15]
Cmnet: Contrastive magnification network for micro-expression recognition
Mengting Wei, Xingxun Jiang, Wenming Zheng, Yuan Zong, Cheng Lu, and Jiateng Liu. Cmnet: Contrastive magnification network for micro-expression recognition. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 119–127, 2023. doi: https: //doi.org/10.1609/aaai.v37i1.25083
-
[16]
Micro-expression recognition through feature enhancement and region weighted fusion based on supervised contrastive learning.Signal Processing, 238:110171,
Shuaichao Li, Mingze Li, Jiaao Sun, and Shuhua Lu. Micro-expression recognition through feature enhancement and region weighted fusion based on supervised contrastive learning.Signal Processing, 238:110171,
-
[17]
doi: https://doi.org/10.1016/j.sigpro.2025
ISSN 0165-1684. doi: https://doi.org/10.1016/j.sigpro.2025. 110171
-
[18]
Fengping Wang, Jie Li, Chun Qi, Lin Wang, and Pan Wang. A multi- modal multi-scale network based on transformer for micro-expression recognition.Journal of Visual Communication and Image Representa- tion, 111:104537, 2025. ISSN 1047-3203. doi: https://doi.org/10.1016/ j.jvcir.2025.104537
arXiv 2025
-
[19]
Wenhao Cai, Junli Zhao, Ran Yi, Minjing Yu, Fuqing Duan, Zhenkuan Pan, and Yong-Jin Liu. Mfdan: Multi-level flow-driven attention net- work for micro-expression recognition.IEEE Transactions on Circuits and Systems for Video Technology, 34(12):12823–12836, 2024. doi: https://doi.org/10.1109/TCSVT.2024.3437481
-
[20]
Au-assisted graph attention convolutional network for micro-expression recognition
Hong-Xia Xie, Ling Lo, Hong-Han Shuai, and Wen-Huang Cheng. Au-assisted graph attention convolutional network for micro-expression recognition. InProceedings of the 28th ACM International Confer- ence on Multimedia, MM ’20, page 2871–2880, New York, NY, USA, 29
-
[21]
Association for Computing Machinery. ISBN 9781450379885. doi: https://doi.org/10.1145/3394171.3414012
-
[22]
Mer-clip: Au-guided vision-language alignment for micro- expression recognition.IEEE Transactions on Affective Computing,
Shifeng Liu, Xinglong Mao, Sirui Zhao, Peiming Li, Tong Xu, and En- hong Chen. Mer-clip: Au-guided vision-language alignment for micro- expression recognition.IEEE Transactions on Affective Computing,
-
[23]
doi: https://doi.org/10.1109/TAFFC.2025.3572931
-
[24]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Pavan Kumar Anasosalu Vasu, James Gabriel, Jeff Zhu, Oncel Tuzel, and Anurag Ranjan. Fastvit: A fast hybrid vision transformer using structural reparameterization. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 5785–5795, 2023. doi: https://doi.org/10.1109/ICCV51070.2023.00532
-
[25]
Mingzhi Chen, Taiming Lu, Jiachen Zhu, Mingjie Sun, and Zhuang Liu. Stronger normalization-free transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27418–27428, 2026. doi: https://doi.org/10.48550/arXiv.2512. 10938
-
[26]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022. doi: https://doi.org/10.1109/ CVPR52688.2022.01167
arXiv 2022
-
[27]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. doi: https://doi.org/10.48550/arXiv. 2103.00020
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2021
-
[28]
FBNet: Hardware-Aware Efficient ConvNet De- sign via Differentiable Neural Architec- ture Search
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. Class-balanced loss based on effective number of samples. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 9268–9277, 2019. doi: https://doi.org/10.1109/CVPR.2019. 00949. 30
-
[29]
Wen-Jing Yan, Xiaobai Li, Su-Jing Wang, Guoying Zhao, Yong-Jin Liu, Yu-Hsin Chen, and Xiaolan Fu. Casme ii: An improved spontaneous micro-expression database and the baseline evaluation.PloS one, 9(1): e86041, 2014. doi: https://doi.org/10.1371/journal.pone.0086041
-
[30]
Adrian K Davison, Cliff Lansley, Nicholas Costen, Kevin Tan, and Moi Hoon Yap. Samm: A spontaneous micro-facial movement dataset. IEEE transactions on affective computing, 9(1):116–129, 2016. doi: https://doi.org/10.1109/TAFFC.2016.2573832
-
[31]
Xiaobai Li, Tomas Pfister, Xiaohua Huang, Guoying Zhao, and Matti Pietikäinen. A spontaneous micro-expression database: Inducement, collection and baseline. In2013 10th IEEE International Conference and Workshops on Automatic face and gesture recognition (fg), pages 1–6. IEEE, 2013. doi: https://doi.org/10.1109/FG.2013.6553717
-
[32]
Megc 2019–the second facial micro-expressions grand chal- lenge
John See, Moi Hoon Yap, Jingting Li, Xiaopeng Hong, and Su-Jing Wang. Megc 2019–the second facial micro-expressions grand chal- lenge. In2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), pages 1–5. IEEE, 2019. doi: https://doi.org/10.1109/FG.2019.8756611
-
[33]
Jingting Li, Zizhao Dong, Shaoyuan Lu, Su-Jing Wang, Wen-Jing Yan, Yinhuan Ma, Ye Liu, Changbing Huang, and Xiaolan Fu. Cas (me) 3: A third generation facial spontaneous micro-expression database with depth information and high ecological validity.IEEE transactions on pattern analysis and machine intelligence, 45(3):2782–2800, 2022. doi: https://doi.org/1...
-
[34]
Sirui Zhao, Huaying Tang, Xinglong Mao, Shifeng Liu, Yiming Zhang, Hao Wang, Tong Xu, and Enhong Chen. Dfme: A new benchmark for dynamic facial micro-expression recognition.IEEE Transactions on Affective Computing, 15(3):1371–1386, 2023. doi: https://doi.org/10. 1109/TAFFC.2023.3341918
arXiv 2023
-
[35]
Dynamic micro-expression automatic recognition challenge on the fourth chinese conference on affective computing, 2024
Sirui Zhao, Huaying Tang, Xinglong Mao, and Shifeng Liu. Dynamic micro-expression automatic recognition challenge on the fourth chinese conference on affective computing, 2024. 31
2024
-
[36]
MediaPipe: A Framework for Building Perception Pipelines
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris McClanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo-Ling Chang, Ming Guang Yong, Juhyun Lee, et al. Mediapipe: A framework for building per- ception pipelines.arXiv preprint arXiv:1906.08172, 2019. doi: https: //doi.org/10.48550/arXiv.1906.08172
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.08172 1906
-
[37]
Learning-basedaxialvideomotionmagnification
Kwon Byung-Ki, Oh Hyun-Bin, Kim Jun-Seong, Hyunwoo Ha, and Tae- HyunOh. Learning-basedaxialvideomotionmagnification. InEuropean Conference on Computer Vision, pages 179–195. Springer, 2024. doi: https://doi.org/10.1007/978-3-031-72949-2_11
-
[38]
and Kanade, Takeo and Saragih, Jason and Ambadar, Zara and Matthews, Iain , year =
Patrick Lucey, Jeffrey F Cohn, Takeo Kanade, Jason Saragih, Zara Ambadar, and Iain Matthews. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified ex- pression. In2010 ieee computer society conference on computer vi- sion and pattern recognition-workshops, pages 94–101. IEEE, 2010. doi: https://doi.org/10.1109/CV...
-
[39]
Decoupled weight decay regulariza- tion.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regulariza- tion.arXiv preprint arXiv:1711.05101, 2017. doi: https://doi.org/10. 48550/arXiv.1711.05101
Pith/arXiv arXiv 2017
-
[40]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton
Xuan-Bac Nguyen, Chi Nhan Duong, Xin Li, Susan Gauch, Han-Seok Seo, and Khoa Luu. Micron-bert: Bert-based facial micro-expression recognition. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 1482–1492, 2023. doi: https://doi.org/ 10.1109/CVPR52729.2023.00149
-
[41]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton
Zhijun Zhai, Jianhui Zhao, Chengjiang Long, Wenju Xu, Shuangjiang He, and Huijuan Zhao. Feature representation learning with adaptive displacement generation and transformer fusion for micro-expression recognition. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 22086–22095, 2023. doi: https://doi.org/10.1109/C...
-
[42]
Micro_nest: multi-scale attention enhanced micro-expression recognition framework.Expert Systems with Applications, 290:128372,
Jing He, Yuanhui Xiao, Han Zhang, Jingwen Cai, Li Cai, and Renyang Liu. Micro_nest: multi-scale attention enhanced micro-expression recognition framework.Expert Systems with Applications, 290:128372,
-
[43]
doi: https://doi.org/10.1016/j.eswa.2025.128372. 32
-
[44]
Pattern Recognition Letters123, 1–8 (2019)
Bingyang Ma, Lu Wang, Qingfen Wang, Haoran Wang, Ruolin Li, Lisheng Xu, Yongchun Li, and Hongchao Wei. Entire-detail motion dual-branch network for micro-expression recognition.Pattern Recogni- tion Letters, 189:166–174, 2025. doi: https://doi.org/10.1016/j.patrec. 2025.01.021
-
[45]
Zhiwen Shao, Yifan Cheng, Feiran Li, Yong Zhou, Xuequan Lu, Yuan Xie, and Lizhuang Ma. Mol: Joint estimation of micro-expression, opti- cal flow, and landmark via transformer-graph-style convolution.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. doi: https://doi.org/10.1109/TPAMI.2025.3581162
-
[46]
Feng Liu, Bingyu Nan, Xuezhong Qian, and Xiaolan Fu. Evaluat- ing and correcting human annotation bias in dynamic micro-expression recognition.IEEE Transactions on Affective Computing, 2026. doi: https://doi.org/10.1109/TAFFC.2026.3671731
-
[47]
Sfam- net: A scene flow attention-based micro-expression network.Neurocom- puting, 566:126998, 2024
Gen-Bing Liong, Sze-Teng Liong, Chee Seng Chan, and John See. Sfam- net: A scene flow attention-based micro-expression network.Neurocom- puting, 566:126998, 2024. doi: https://doi.org/10.1016/j.neucom.2023. 126998
-
[48]
Facial 3d regional structural mo- tion representation using lightweight point cloud networks for micro- expression recognition.IEEE Transactions on Affective Computing,
Ren Zhang, Jianqin Yin, Chao Qi, Yonghao Dang, Zehao Wang, Zhicheng Zhang, and Huaping Liu. Facial 3d regional structural mo- tion representation using lightweight point cloud networks for micro- expression recognition.IEEE Transactions on Affective Computing,
-
[49]
doi: https://doi.org/10.1109/TAFFC.2025.3535569
-
[50]
Sai Prasanna Teja Reddy, Surya Teja Karri, Shiv Ram Dubey, and Sne- hasis Mukherjee. Spontaneous facial micro-expression recognition using 3d spatiotemporal convolutional neural networks. In2019 international joint conference on neural networks (IJCNN), pages 1–8. IEEE, 2019. doi: https://doi.org/10.1109/IJCNN.2019.8852419
-
[51]
Capsulenet for micro-expression recognition
Nguyen Van Quang, Jinhee Chun, and Takeshi Tokuyama. Capsulenet for micro-expression recognition. In2019 14th IEEE international con- ference on automatic face & gesture recognition (FG 2019), pages 1–7. IEEE, 2019. doi: https://doi.org/10.1109/FG.2019.8756544. 33
-
[52]
Mer- gcn: Micro-expression recognition based on relation modeling with graph convolutional networks
Ling Lo, Hong-Xia Xie, Hong-Han Shuai, and Wen-Huang Cheng. Mer- gcn: Micro-expression recognition based on relation modeling with graph convolutional networks. In2020 IEEE conference on multime- dia information processing and retrieval (MIPR), pages 79–84. IEEE,
-
[53]
doi: https://doi.org/10.1109/MIPR49039.2020.00023
-
[54]
The use of multiple measurements in taxonomic prob- lems.Annals of eugenics, 7(2):179–188, 1936
Ronald A Fisher. The use of multiple measurements in taxonomic prob- lems.Annals of eugenics, 7(2):179–188, 1936. doi: https://doi.org/10. 1111/j.1469-1809.1936.tb02137.x. 34
arXiv 1936
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.