Concept Removal for Frontier Image Generative Models
Pith reviewed 2026-06-25 21:16 UTC · model grok-4.3
The pith
Replacing the bottleneck layer with a trained transcoder lets image generative models selectively disable unwanted concepts while keeping output quality intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an in-place substitution of the bottleneck layer with a transcoder trained to replicate the original layer while structuring activations into distinct, selectively disableable features creates an integrated filter that removes target concepts from diffusion and autoregressive image models without degrading overall generation behavior or requiring external components.
What carries the argument
The transcoder that replaces the bottleneck layer and structures its activations into distinct, selectively disableable features corresponding to individual concepts.
If this is right
- The method achieves state-of-the-art concept removal on modern diffusion and autoregressive models.
- Generation quality remains comparable to the unmodified model.
- The removal resists adversarial prompts that try to elicit the disabled concept.
- Multiple distinct concepts can be removed sequentially without cumulative degradation.
- The edit persists under white-box access because it modifies the model backbone directly.
Where Pith is reading between the lines
- The same transcoder replacement might extend to other generative domains such as video or audio if those models also contain analogous bottleneck layers.
- The structured activation features could be inspected to study which internal representations correspond to specific visual concepts.
- Sequential removal capability suggests the approach could support ongoing, iterative safety updates after initial deployment.
- Because the change is internal rather than an added filter, it may reduce the attack surface compared with external concept-removal modules.
Load-bearing premise
A transcoder can be trained to match the original bottleneck layer exactly while also organizing its activations so that individual concepts can be turned off without side effects on the rest of the model.
What would settle it
After the transcoder is inserted and a concept is disabled, either image quality drops measurably on standard benchmarks or the removed concept still appears reliably in generations from ordinary prompts.
Figures

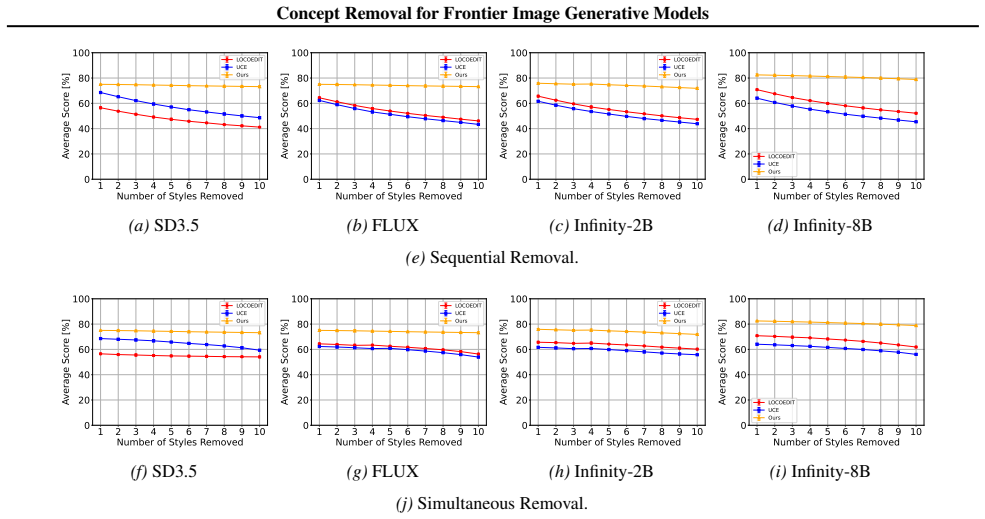




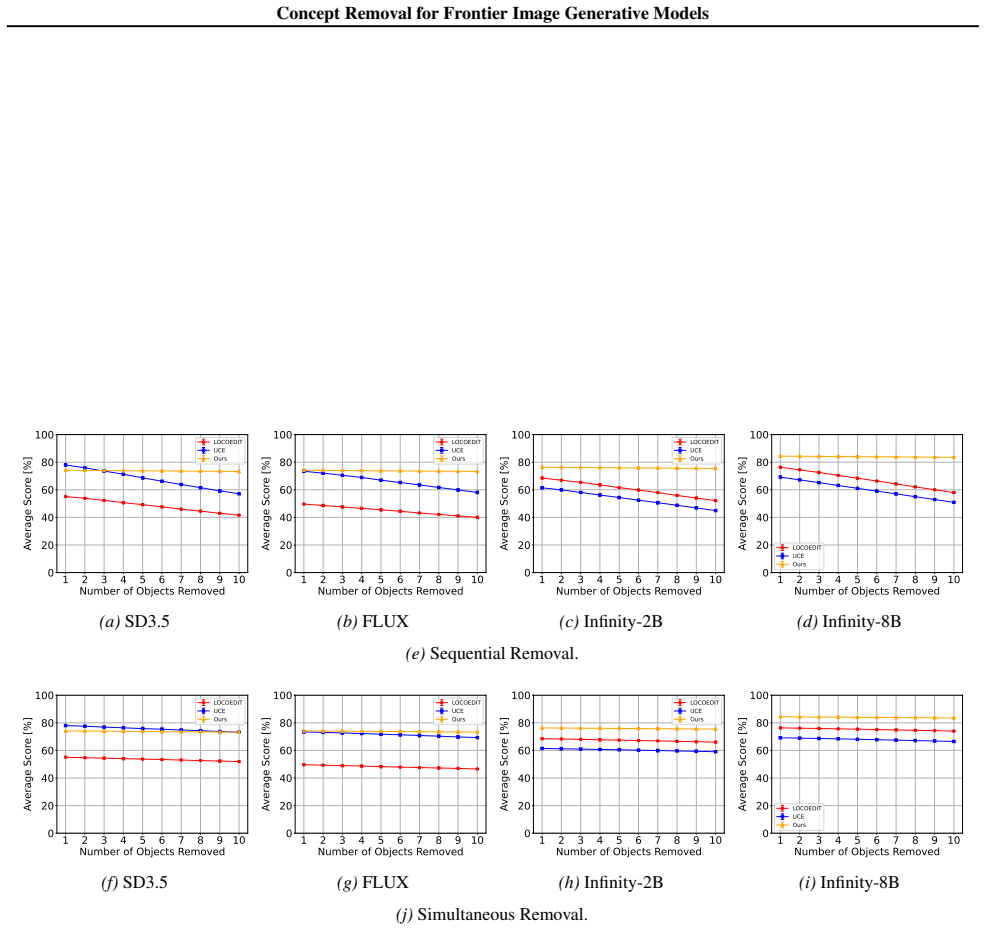
read the original abstract
Image generative models are trained on massive, largely uncurated internet-scale datasets that contain undesirable visual concepts. Efficiently removing such concepts from the model generations without degrading the quality of output images remains challenging. We introduce a novel concept removal method for frontier diffusion and image autoregressive models, such as SD3.5, Flux, and Infinity. Our intervention replaces the internal bottleneck layer present in all these modern models with a transcoder that is trained to replicate the original layer while structuring it into distinct activation features. This in-place substitution creates an integrated filter through which concept-specific signals can be selectively disabled while preserving the rest of the model's behavior. Since the intervention modifies the model backbone rather than attaching an external component, it remains persistent under white-box access. Empirically, the approach achieves state-of-the-art concept removal performance across modern diffusion and autoregressive models, maintains visual generation quality, provides robustness against adversarial prompts, and supports sequential removal of diverse concepts. This positions our method as a practical approach for concept removal in frontier image generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a novel concept removal technique for frontier diffusion and autoregressive image models (SD3.5, Flux, Infinity) that replaces the internal bottleneck layer with a transcoder trained to replicate the original layer's function while factoring its activations into distinct, selectively disableable features; the substitution is asserted to enable persistent, in-place concept filtering without external components, achieving SOTA removal performance, preserved generation quality, adversarial robustness, and support for sequential multi-concept removal.
Significance. If the central empirical claims were substantiated, the work would offer a practically significant advance by providing an integrated, persistent intervention inside the model backbone rather than an add-on filter. The approach could address a real deployment need for frontier models. However, the manuscript as presented supplies no quantitative evidence, so significance cannot be assessed.
major comments (2)
- [Abstract] Abstract: the assertions of 'state-of-the-art concept removal performance', 'maintains visual generation quality', 'robustness against adversarial prompts', and 'supports sequential removal' are presented without any metrics, baselines, ablation studies, or experimental details, so the claims cannot be evaluated.
- [Abstract] Abstract (central claim paragraph): the dual requirement that the transcoder 'replicate the original layer' while 'structuring it into distinct activation features' that can be 'selectively disabled' with 'no side effects on overall model behavior' is asserted but unsupported; no reconstruction loss values, feature-disentanglement metrics, or trade-off ablations are supplied to address the tension between exact replication and clean per-concept disablement.
Simulated Author's Rebuttal
We thank the referee for identifying the lack of quantitative support for the abstract claims. We agree these assertions require explicit metrics and will revise the manuscript to include them.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertions of 'state-of-the-art concept removal performance', 'maintains visual generation quality', 'robustness against adversarial prompts', and 'supports sequential removal' are presented without any metrics, baselines, ablation studies, or experimental details, so the claims cannot be evaluated.
Authors: We agree the abstract overclaims without evidence. The revised version will incorporate specific quantitative results (e.g., removal accuracy vs. baselines, FID scores for quality, adversarial robustness rates, and sequential removal success) directly into the abstract, with pointers to the experimental sections. revision: yes
-
Referee: [Abstract] Abstract (central claim paragraph): the dual requirement that the transcoder 'replicate the original layer' while 'structuring it into distinct activation features' that can be 'selectively disabled' with 'no side effects on overall model behavior' is asserted but unsupported; no reconstruction loss values, feature-disentanglement metrics, or trade-off ablations are supplied to address the tension between exact replication and clean per-concept disablement.
Authors: We accept this criticism. The revision will add reported reconstruction losses, disentanglement metrics (such as feature correlation or activation independence scores), and ablation studies on the replication-vs.-removal trade-off to demonstrate that selective disablement occurs without side effects. revision: yes
Circularity Check
No circularity: empirical architectural substitution with no derivation reducing to fitted inputs or self-citations
full rationale
The paper presents an empirical intervention: replacing a bottleneck layer with a trained transcoder that replicates the original while enabling selective feature disablement. No mathematical derivation chain, equations, or 'predictions' are claimed that reduce by construction to the training inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatzes imported from prior author work are invoked in the provided text. The central claim rests on training and empirical validation rather than definitional equivalence or fitted-parameter renaming. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The bottleneck layer in diffusion and autoregressive models can be replaced in-place by a transcoder without altering the model's overall generative capability beyond the targeted features.
Reference graph
Works this paper leans on
-
[1]
C., and Zanotti, F
Asperti, A., George, F., Marras, T., Stricescu, R. C., and Zanotti, F. A critical assessment of modern generative models’ ability to replicate artistic styles. Big Data and Cognitive Computing, 9 0 (9): 0 231, 2025
2025
-
[2]
On mechanistic knowledge localization in text-to-image generative models
Basu, S., Rezaei, K., Kattakinda, P., Morariu, V., Zhao, N., Rossi, R., Manjunatha, V., and Feizi, S. On mechanistic knowledge localization in text-to-image generative models. International Conference on Machine Learning, 2024 a
2024
-
[3]
Localizing and editing knowledge in text-to-image generative models
Basu, S., Zhao, N., Morariu, V., Feizi, S., and Manjunatha, V. Localizing and editing knowledge in text-to-image generative models. 2024 b
2024
-
[4]
Flux.1, 2024
Black Forest Labs . Flux.1, 2024. URL https://blackforestlabs.ai/announcing-black-forest-labs/
2024
-
[5]
T., Vu, T., Vuong, L
Bui, A. T., Vu, T., Vuong, L. T., Le, T., Montague, P., Abraham, T., Kim, J., and Phung, D. Fantastic targets for concept erasure in diffusion models and where to find them. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=tZdqL5FH7w
2025
-
[6]
ConceptPrune : Concept editing in diffusion models via skilled neuron pruning
Chavhan, R., Li, D., and Hospedales, T. ConceptPrune : Concept editing in diffusion models via skilled neuron pruning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=kSdWcw5mkp
2025
-
[7]
Prompting4debugging: Red-teaming text-to-image diffusion models by finding problematic prompts
Chin, Z.-Y., Jiang, C.-M., Huang, C.-C., Chen, P.-Y., and Chiu, W.-C. Prompting4debugging: Red-teaming text-to-image diffusion models by finding problematic prompts. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[8]
and Deja, K
Cywi \'n ski, B. and Deja, K. Saeuron: Interpretable concept unlearning in diffusion models with sparse autoencoders. International Conference on Machine Learning, 2025
2025
-
[9]
Transcoders find interpretable llm feature circuits
Dunefsky, J., Chlenski, P., and Nanda, N. Transcoders find interpretable llm feature circuits. Advances in Neural Information Processing Systems, 37: 0 24375--24410, 2024
2024
-
[11]
Scaling rectified flow transformers for high-resolution image synthesis
Esser, P., Kulal, S., Blattmann, A., Entezari, R., M \"u ller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning, 2024 a
2024
-
[12]
Scaling rectified flow transformers for high-resolution image synthesis
Esser, P., Kulal, S., Blattmann, A., Entezari, R., M \"u ller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first International Conference on Machine Learning, 2024 b
2024
-
[13]
Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation
Fan, C., Liu, J., Zhang, Y., Wong, E., Wei, D., and Liu, S. Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation. The Twelfth International Conference on Learning Representations, 2024
2024
-
[14]
Erasing concepts from diffusion models
Gandikota, R., Materzynska, J., Fiotto-Kaufman, J., and Bau, D. Erasing concepts from diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 2426--2436, 2023
2023
-
[15]
Unified concept editing in diffusion models
Gandikota, R., Orgad, H., Belinkov, Y., Materzy \'n ska, J., and Bau, D. Unified concept editing in diffusion models. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp.\ 5111--5120, 2024
2024
-
[16]
Eraseanything: Enabling concept erasure in rectified flow transformers
Gao, D., Lu, S., Zhou, W., Chu, J., Zhang, J., Jia, M., Zhang, B., Fan, Z., and Zhang, W. Eraseanything: Enabling concept erasure in rectified flow transformers. In Forty-second International Conference on Machine Learning, 2025
2025
-
[18]
Gary Marcus, R. S. Generative ai has a visual plagiarism problem: Experiments with midjourney and dall-e 3 show a copyright minefield, 2024. URL https://spectrum.ieee.org/midjourney-copyright. Accessed: 2024-01-06
2024
-
[19]
Reliable and efficient concept erasure of text-to-image diffusion models
Gong, C., Chen, K., Wei, Z., Chen, J., and Jiang, Y.-G. Reliable and efficient concept erasure of text-to-image diffusion models. In European Conference on Computer Vision, pp.\ 73--88. Springer, 2024
2024
-
[20]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis
Han, J., Liu, J., Jiang, Y., Yan, B., Zhang, Y., Yuan, Z., Peng, B., and Liu, X. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 15733--15744, 2025
2025
-
[21]
and Soh, H
Heng, A. and Soh, H. Selective amnesia: A continual learning approach to forgetting in deep generative models. Advances in Neural Information Processing Systems, 36: 0 17170--17194, 2023
2023
-
[22]
Clipscore: A reference-free evaluation metric for image captioning
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y. Clipscore: A reference-free evaluation metric for image captioning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp.\ 7514--7528, 2021
2021
-
[23]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017
2017
-
[25]
Ablating concepts in text-to-image diffusion models
Kumari, N., Zhang, B., Wang, S.-Y., Shechtman, E., Zhang, R., and Zhu, J.-Y. Ablating concepts in text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 22691--22702, 2023
2023
-
[26]
Labs, B. F. Flux. https://github.com/black-forest-labs/flux, 2024
2024
-
[27]
H., Lim, S., and Chun, S
Lee, B. H., Lim, S., and Chun, S. Y. Localized concept erasure for text-to-image diffusion models using training-free gated low-rank adaptation. In CVPR, 2025
2025
-
[28]
S., Hou, Q., Wang, Y., and Yang, J
Li, S., van de Weijer, J., Hu, T., Khan, F. S., Hou, Q., Wang, Y., and Yang, J. Get what you want, not what you don't: Image content suppression for text-to-image diffusion models. The Twelfth International Conference on Learning Representations, 2024
2024
-
[29]
Microsoft COCO: Common Objects in Context
Lin, T.-Y., Maire, M., Belongie, S., Bourdev, L., Girshick, R., Hays, J., Perona, P., Ramanan, D., Zitnick, C. L., and Dollár, P. Microsoft coco: Common objects in context. arXiv preprint arXiv: 1405.0312, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
Liu, H., Li, C., Wu, Q., and Lee, Y. J. Visual instruction tuning. In NeurIPS, 2023
2023
-
[31]
Lu, S., Wang, Z., Li, L., Liu, Y., and Kong, A. W.-K. Mace: Mass concept erasure in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 6430--6440, 2024
2024
-
[32]
One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications
Lyu, M., Yang, Y., Hong, H., Chen, H., Jin, X., He, Y., Xue, H., Han, J., and Ding, G. One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 7559--7568, 2024
2024
-
[33]
Hpsv3: Towards wide-spectrum human preference score
Ma, Y., Wu, X., Sun, K., and Li, H. Hpsv3: Towards wide-spectrum human preference score. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp.\ 15086--15095, October 2025 a
2025
-
[34]
Hpsv3: Towards wide-spectrum human preference score
Ma, Y., Wu, X., Sun, K., and Li, H. Hpsv3: Towards wide-spectrum human preference score. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 15086--15095, 2025 b
2025
-
[35]
Editing implicit assumptions in text-to-image diffusion models
Orgad, H., Kawar, B., and Belinkov, Y. Editing implicit assumptions in text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 7053--7061, 2023
2023
-
[37]
Safe-clip: Removing nsfw concepts from vision-and-language models
Poppi, S., Poppi, T., Cocchi, F., Cornia, M., Baraldi, L., and Cucchiara, R. Safe-clip: Removing nsfw concepts from vision-and-language models. In European Conference on Computer Vision, pp.\ 340--356. Springer, 2024
2024
-
[38]
Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models
Qu, Y., Shen, X., He, X., Backes, M., Zannettou, S., and Zhang, Y. Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, pp.\ 3403--3417, 2023
2023
-
[39]
Zero-shot text-to-image generation
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., and Sutskever, I. Zero-shot text-to-image generation. In International conference on machine learning, pp.\ 8821--8831. Pmlr, 2021
2021
-
[41]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10684--10695, 2022
2022
-
[42]
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models
Schramowski, P., Brack, M., Deiseroth, B., and Kersting, K. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 22522--22531, 2023
2023
-
[43]
DeepFloyd IF : a novel state-of-the-art open-source text-to-image model with a high degree of photorealism and language understanding
StabilityAI. DeepFloyd IF : a novel state-of-the-art open-source text-to-image model with a high degree of photorealism and language understanding. https://github.com/deep-floyd/IF, 2023. Last accessed on 2025-01-17
2023
-
[45]
Tsai, Y., Hsu, C., Xie, C., Lin, C., Chen, J., Li, B., Chen, P., Yu, C., and Huang, C. Ring-a-bell! how reliable are concept removal methods for diffusion models? In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=lm7MRcsFiS
2024
-
[46]
Pixel recurrent neural networks
Van Den Oord, A., Kalchbrenner, N., and Kavukcuoglu, K. Pixel recurrent neural networks. In International conference on machine learning, pp.\ 1747--1756. PMLR, 2016
2016
-
[47]
Precise, fast, and low-cost concept erasure in value space: Orthogonal complement matters
Wang, Y., Li, O., Mu, T., Hao, Y., Liu, K., Wang, X., and He, X. Precise, fast, and low-cost concept erasure in value space: Orthogonal complement matters. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 28759--28768, June 2025
2025
-
[49]
and Harandi, M
Wu, J. and Harandi, M. Scissorhands: Scrub data influence via connection sensitivity in networks. In European Conference on Computer Vision, pp.\ 367--384. Springer, 2024
2024
-
[50]
Erasing undesirable influence in diffusion models
Wu, J., Le, T., Hayat, M., and Harandi, M. Erasing undesirable influence in diffusion models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 28263--28273, 2025
2025
-
[51]
MMA-Diffusion: MultiModal Attack on Diffusion Models
Yang, Y., Gao, R., Wang, X., Ho, T.-Y., Xu, N., and Xu, Q. MMA-Diffusion: MultiModal Attack on Diffusion Models . In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition ( CVPR ) , 2024 a
2024
-
[52]
Sneakyprompt: Jailbreaking text-to-image generative models
Yang, Y., Hui, B., Yuan, H., Gong, N., and Cao, Y. Sneakyprompt: Jailbreaking text-to-image generative models. In 2024 IEEE symposium on security and privacy (SP), pp.\ 897--912. IEEE, 2024 b
2024
-
[53]
Safree: Training-free and adaptive guard for safe text-to-image and video generation
Yoon, J., Yu, S., Patil, V., Yao, H., and Bansal, M. Safree: Training-free and adaptive guard for safe text-to-image and video generation. The Thirteenth International Conference on Learning Representations, 2025
2025
-
[54]
Forget-me-not: Learning to forget in text-to-image diffusion models
Zhang, G., Wang, K., Xu, X., Wang, Z., and Shi, H. Forget-me-not: Learning to forget in text-to-image diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 1755--1764, 2024 a
2024
-
[55]
R., Liu, X., and Liu, S
Zhang, Y., Fan, C., Zhang, Y., Yao, Y., Jia, J., Liu, J., Zhang, G., Liu, G., Kompella, R. R., Liu, X., and Liu, S. Unlearncanvas: Stylized image dataset for enhanced machine unlearning evaluation in diffusion models. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024 b . URL https://openreview.net/...
2024
-
[56]
To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images
Zhang, Y., Jia, J., Chen, X., Chen, A., Zhang, Y., Liu, J., Ding, K., and Liu, S. To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images... for now. European Conference on Computer Vision (ECCV), 2024 c
2024
-
[57]
Minimalist concept erasure in generative models
Zhang, Y., Jin, E., Dong, Y., Wu, Y., Torr, P., Khakzar, A., Stegmaier, J., and Kawaguchi, K. Minimalist concept erasure in generative models. International Conference on Machine Learning, 2025
2025
-
[58]
Image and video tokenization with binary spherical quantization
Zhao, Y., Xiong, Y., and Krähenbühl, P. Image and video tokenization with binary spherical quantization. arXiv preprint arXiv: 2406.07548, 2024
-
[59]
Closing the safety gap: Surgical concept erasure in visual autoregressive models
Zhong, X., Zhou, Y., Zhang, Z., Li, J., Yi, S., Chen, B., Xia, S.-T., Wang, X., and Xu, K. Closing the safety gap: Surgical concept erasure in visual autoregressive models. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=tlYSbw5GXY
2026
-
[60]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Editing implicit assumptions in text-to-image diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[61]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Unified concept editing in diffusion models , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[62]
arXiv preprint arXiv:2501.19066 , year=
Concept steerers: Leveraging k-sparse autoencoders for controllable generations , author=. arXiv preprint arXiv:2501.19066 , year=
-
[63]
arXiv preprint arXiv:2503.09446 , year=
Sparse autoencoder as a zero-shot classifier for concept erasing in text-to-image diffusion models , author=. arXiv preprint arXiv:2503.09446 , year=
-
[64]
arXiv preprint arXiv:2506.22806 , year=
Concept pinpoint eraser for text-to-image diffusion models via residual attention gate , author=. arXiv preprint arXiv:2506.22806 , year=
-
[65]
2024 , publisher=
Localizing and editing knowledge in text-to-image generative models , author=. 2024 , publisher=
2024
-
[66]
European Conference on Computer Vision , pages=
Reliable and efficient concept erasure of text-to-image diffusion models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[67]
2024 , organization=
On mechanistic knowledge localization in text-to-image generative models , author=. 2024 , organization=
2024
-
[68]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mace: Mass concept erasure in diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[69]
International Conference on Machine Learning , year=
Minimalist Concept Erasure in Generative Models , author=. International Conference on Machine Learning , year=
-
[70]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Erasing concepts from diffusion models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[71]
Forty-second International Conference on Machine Learning , year=
Eraseanything: Enabling concept erasure in rectified flow transformers , author=. Forty-second International Conference on Machine Learning , year=
-
[72]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Forget-me-not: Learning to forget in text-to-image diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[73]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Ablating concepts in text-to-image diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[74]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Erasing undesirable influence in diffusion models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[75]
The Twelfth International Conference on Learning Representations , year=
Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation , author=. The Twelfth International Conference on Learning Representations , year=
-
[76]
European Conference on Computer Vision , pages=
Scissorhands: Scrub data influence via connection sensitivity in networks , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[77]
Advances in Neural Information Processing Systems , volume=
Selective amnesia: A continual learning approach to forgetting in deep generative models , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
European Conference on Computer Vision , pages=
Safe-clip: Removing nsfw concepts from vision-and-language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[79]
International Conference on Machine Learning , year=
SAeUron: Interpretable concept unlearning in diffusion models with sparse autoencoders , author=. International Conference on Machine Learning , year=
-
[80]
International Conference on Machine Learning , year=
Mechanistic unlearning: Robust knowledge unlearning and editing via mechanistic localization , author=. International Conference on Machine Learning , year=
-
[81]
The Thirteenth International Conference on Learning Representations , year=
Safree: Training-free and adaptive guard for safe text-to-image and video generation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[82]
The Twelfth International Conference on Learning Representations , year=
Get what you want, not what you don't: Image content suppression for text-to-image diffusion models , author=. The Twelfth International Conference on Learning Representations , year=
-
[83]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[84]
The Thirteenth International Conference on Learning Representations , year=
Precise Parameter Localization for Textual Generation in Diffusion Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[85]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Hpsv3: Towards wide-spectrum human preference score , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[86]
Forty-first International Conference on Machine Learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first International Conference on Machine Learning , year=
-
[87]
2023 , note=
StabilityAI , title=. 2023 , note=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.