Is GraphRAG Needed? From Basic RAG to Graph-/Agentic Solutions with Context Optimization
Pith reviewed 2026-06-25 20:49 UTC · model grok-4.3
The pith
Context engineering for GraphRAG and Agentic RAG reduces token usage by 19 to 53 percent and shows that more retrieval does not always improve generation quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a framework for evaluating different RAG scenarios on semi-structured knowledge bases and implement nine standardized scenarios. A novel context engineering method manages text and graph retrievals with new representations and agentic loop design, achieving 19%-53% token reduction. Analysis identifies a retrieval-generation gap where expanded retrieval does not proportionally improve generation quality.
What carries the argument
The novel context engineering method that uses new representations and agentic loop design to manage text and graph retrievals efficiently.
Load-bearing premise
The nine standardized RAG scenarios and experiments on semi-structured knowledge bases accurately reflect real use cases and support the reported token reductions and gap.
What would settle it
Running the same scenarios on different real-world datasets and finding no token reduction or no retrieval-generation gap would disprove the claims.
Figures

read the original abstract
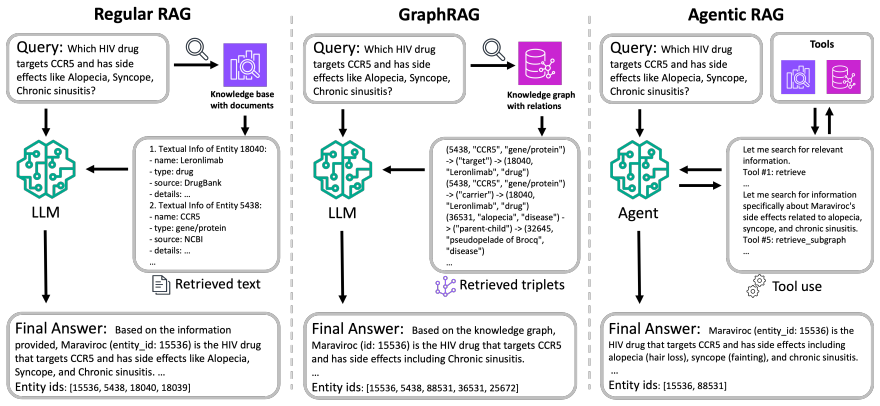
As advanced RAG variants like GraphRAG and Agentic RAG emerge, one leading question is when and how to use them. Here, we introduce a framework for different RAG scenarios evaluation and comparison on semi-structured knowledge bases, including regular RAG, GraphRAG, Modular RAG and Agentic RAG. We provide implementation for 9 standardized RAG scenarios, and conduct experiments for a comprehensive comparison. These scenarios are designed for real use cases regarding data and domain restrictions, spanning from simple document-based retrieval to advanced features such as hybrid text-graph retrieval, integration with computed or pre-defined domain knowledge graphs, agentic multi-step planning, and agent-graph integration. Besides, we present a novel context engineering method for GraphRAG and Agentic RAG, addressing the context/memory overflow issues, efficiently managing text and graph retrievals with new representations and agentic loop design, leading to 19%-53% reduction on token usage. Moreover, further analysis identifies a retrieval-generation gap where expanded retrieval does not proportionally improve generation quality, suggesting retrieval-oriented metrics overstate advanced retrieval benefits. This work provides data-driven insights on when and how to use them for building production-ready intelligent RAG systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for evaluating and comparing nine standardized RAG scenarios (regular RAG, GraphRAG, Modular RAG, Agentic RAG) on semi-structured knowledge bases. It implements these scenarios spanning simple document retrieval to hybrid text-graph retrieval, domain knowledge graphs, agentic planning, and agent-graph integration; proposes a novel context engineering method using new representations and agentic loop design to address context overflow, claiming 19-53% token usage reduction; and identifies a retrieval-generation gap where expanded retrieval does not proportionally improve generation quality.
Significance. If the experimental claims hold after proper validation, the work supplies practical, data-driven guidance on when to deploy basic versus advanced RAG variants in production settings and offers an efficiency technique for managing context in GraphRAG/Agentic systems. The retrieval-generation gap observation, if reproducible, would usefully caution against over-reliance on retrieval-oriented metrics.
major comments (2)
- [Abstract] Abstract: the claim of 19%-53% token reduction and the retrieval-generation gap is presented without any description of the datasets, baselines, controls, generation-quality metrics, statistical tests, or implementation details; this absence makes the central empirical claims impossible to evaluate for soundness or reproducibility.
- [Abstract] The nine standardized scenarios are asserted to reflect real use cases regarding data and domain restrictions, yet no evidence or justification is supplied that the chosen semi-structured knowledge bases and restrictions produce a fair, comprehensive comparison supporting the reported reductions and gap.
Simulated Author's Rebuttal
We thank the referee for highlighting issues with the abstract's conciseness. We agree that additional details will improve evaluability and will revise the abstract accordingly while preserving its brevity. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 19%-53% token reduction and the retrieval-generation gap is presented without any description of the datasets, baselines, controls, generation-quality metrics, statistical tests, or implementation details; this absence makes the central empirical claims impossible to evaluate for soundness or reproducibility.
Authors: We acknowledge the abstract omits these specifics, as is common for length constraints. The full manuscript details the semi-structured knowledge bases used as datasets, the nine RAG scenarios as baselines, generation-quality metrics (including token usage and quality scores), controls via standardized implementations, and implementation via the described framework. Statistical aspects of the gap observation are analyzed in the results. We will revise the abstract to briefly reference the datasets (semi-structured KBs), key metrics, and note the empirical basis for the claims, enabling better initial evaluation. revision: yes
-
Referee: [Abstract] The nine standardized scenarios are asserted to reflect real use cases regarding data and domain restrictions, yet no evidence or justification is supplied that the chosen semi-structured knowledge bases and restrictions produce a fair, comprehensive comparison supporting the reported reductions and gap.
Authors: The scenarios were constructed to mirror practical restrictions in semi-structured domains (e.g., hybrid text-graph data in enterprise settings, domain KGs, agentic planning). The manuscript describes how they span from basic retrieval to agent-graph integration, chosen to cover representative real-world constraints. We will add a brief justification sentence to the revised abstract referencing these typical use cases. The comparison is comprehensive by design as it standardizes across the spectrum of RAG variants on the same bases. revision: yes
Circularity Check
Empirical comparison study with no circular derivations
full rationale
The paper frames itself as an empirical comparison of nine standardized RAG scenarios on semi-structured knowledge bases, reporting experimental token reductions (19-53%) and a retrieval-generation gap from direct measurements rather than any mathematical derivation chain. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or description; the context engineering method is presented as an implemented design whose benefits are measured externally. The work is self-contained against its own experimental benchmarks with no reduction of claims to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2023 , journal =
Leonie Monigatti , title =. 2023 , journal =
2023
-
[2]
2023 , eprint=
ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems , author=. 2023 , eprint=
2023
-
[3]
Build and Evaluate LLM Apps with LlamaIndex and TruLens , journal =
Jerry Liu , year =. Build and Evaluate LLM Apps with LlamaIndex and TruLens , journal =
-
[4]
2024 , eprint=
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation , author=. 2024 , eprint=
2024
-
[5]
Advances in Neural Information Processing Systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Advances in Neural Information Processing Systems , volume=
Stark: Benchmarking llm retrieval on textual and relational knowledge bases , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
arXiv preprint arXiv:1904.09537 , year=
Pullnet: Open domain question answering with iterative retrieval on knowledge bases and text , author=. arXiv preprint arXiv:1904.09537 , year=
Pith/arXiv arXiv 1904
-
[13]
arXiv preprint arXiv:1905.07098 , year=
Improving question answering over incomplete kbs with knowledge-aware reader , author=. arXiv preprint arXiv:1905.07098 , year=
Pith/arXiv arXiv 1905
-
[15]
Scientific Data , volume=
Building a knowledge graph to enable precision medicine , author=. Scientific Data , volume=. 2023 , publisher=
2023
-
[16]
GitHub repository , howpublished =
Liu, Jerry , title =. GitHub repository , howpublished =. 2022 , publisher =
2022
-
[18]
2025 , url =
strands-agents , howpublished =. 2025 , url =
2025
-
[19]
2025 , url =
AWS , title =. 2025 , url =
2025
-
[20]
2025 , howpublished =
AWS , title =. 2025 , howpublished =
2025
-
[22]
International Conference on Learning Representations (ICLR) , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[23]
Annual Meeting of the Association for Computational Linguistics (ACL) , year=
ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models , author=. Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[24]
AWS. 2025. Strands agents sdk: A new open-source framework for building agents. https://github.com/strands-agents/sdk-python/
2025
-
[25]
Payal Chandak, Kexin Huang, and Marinka Zitnik. 2023. Building a knowledge graph to enable precision medicine. Scientific Data, 10(1):67
2023
-
[26]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130
Pith/arXiv arXiv 2024
-
[27]
Yunfan Gao, Yun Xiong, Meng Wang, and Haofen Wang. 2024. Modular rag: Transforming rag systems into lego-like reconfigurable frameworks. arXiv preprint arXiv:2407.21059
arXiv 2024
-
[28]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, and 1 others. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459--9474
2020
-
[29]
Jerry Liu. 2022. Llamaindex: Data framework for llm-based applications. https://www.llamaindex.ai/
2022
-
[30]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172
Pith/arXiv arXiv 2023
-
[31]
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. 2024. Graph retrieval-augmented generation: A survey. arXiv preprint arXiv:2408.08921
arXiv 2024
-
[32]
Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. 2025. Agentic retrieval-augmented generation: A survey on agentic rag. arXiv preprint arXiv:2501.09136
Pith/arXiv arXiv 2025
-
[33]
Alon Talmor and Jonathan Berant. 2018. The web as a knowledge-base for answering complex questions. arXiv preprint arXiv:1803.06643
Pith/arXiv arXiv 2018
-
[34]
Shirley Wu, Shiyu Zhao, Michihiro Yasunaga, Kexin Huang, Kaidi Cao, Qian Huang, Vassilis N Ioannidis, Karthik Subbian, James Zou, and Jure Leskovec. 2024. Stark: Benchmarking llm retrieval on textual and relational knowledge bases. Advances in Neural Information Processing Systems, 37:127129--127153
2024
-
[35]
Yu Xia, Junda Wu, Sungchul Kim, Tong Yu, Ryan A Rossi, Haoliang Wang, and Julian McAuley. 2024. Knowledge-aware query expansion with large language models for textual and relational retrieval. arXiv preprint arXiv:2410.13765
arXiv 2024
-
[36]
Binfeng Xu, Zhiyuan Peng, Bowen Lei, Namber Muber, Eric Xie, and Xin Qi. 2025. Rewoo: Decoupling reasoning from observations for efficient augmented language models. In Annual Meeting of the Association for Computational Linguistics (ACL)
2025
-
[37]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600
Pith/arXiv arXiv 2018
-
[38]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR)
2023
-
[39]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[40]
Publications Manual , year = "1983", publisher =
1983
-
[41]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[42]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[43]
Dan Gusfield , title =. 1997
1997
-
[44]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[45]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.