SARA: Unlocking Multilingual Knowledge in Mixture-of-Experts via Semantically Anchored Routing Alignment
Pith reviewed 2026-06-25 20:46 UTC · model grok-4.3
The pith
Aligning internal routing distributions in MoE layers to high-resource semantic anchors via symmetric Jensen-Shannon divergence transfers capabilities to low-resource languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
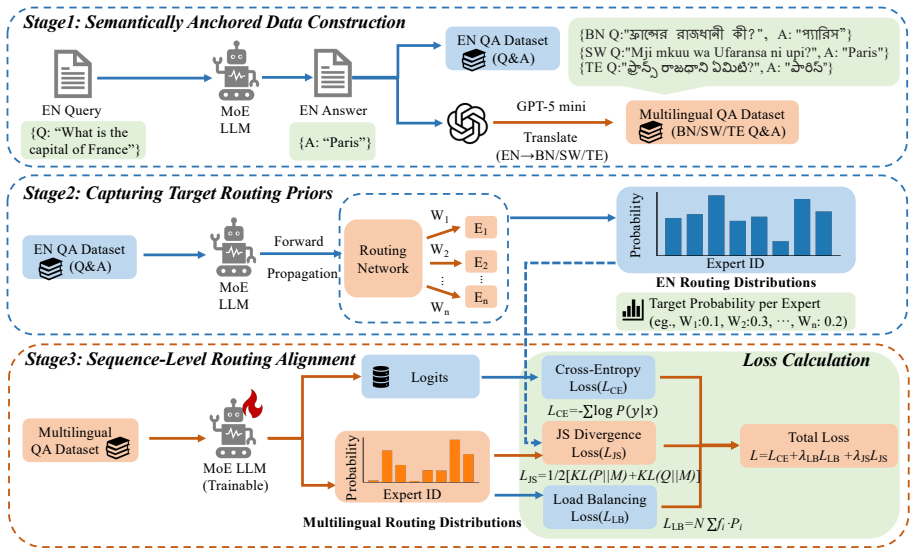
SARA explicitly aligns the routing distribution of multilingual inputs with high-resource semantic anchors using a symmetric Jensen-Shannon (JS) divergence constraint. Unlike traditional distillation methods that operate on output logits, SARA directly aligns the internal routing distributions of MoE layers, encouraging mechanistic consistency in expert selection across languages.
What carries the argument
The symmetric Jensen-Shannon divergence constraint applied to per-layer routing distributions, with high-resource inputs serving as semantic anchors.
If this is right
- Low-resource languages gain 0.8 to 1.2 points on Global-MMLU after SARA is applied to instruction-tuned MoE models.
- The same alignment loss works across different base MoE architectures without requiring language-specific data.
- High-resource language performance remains stable because the anchor distributions are preserved.
- Direct routing alignment offers a parameter-free route to cross-lingual expert sharing inside sparse layers.
Where Pith is reading between the lines
- The method could be tested on routing layers inside non-language MoE models such as vision or multimodal experts.
- If routing alignment proves sufficient, future scaling laws for multilingual MoE might reduce emphasis on balanced data collection.
- Combining SARA with existing output-level distillation could compound gains if the two operate on orthogonal signals.
Load-bearing premise
Routing divergence between low-resource and high-resource inputs is the main performance bottleneck in multilingual MoE models, and forcing alignment will transfer expert capabilities without harming high-resource performance or creating new inconsistencies.
What would settle it
A controlled run in which routing distributions are prevented from aligning yet low-resource benchmark scores still rise by the same margin as with SARA.
Figures
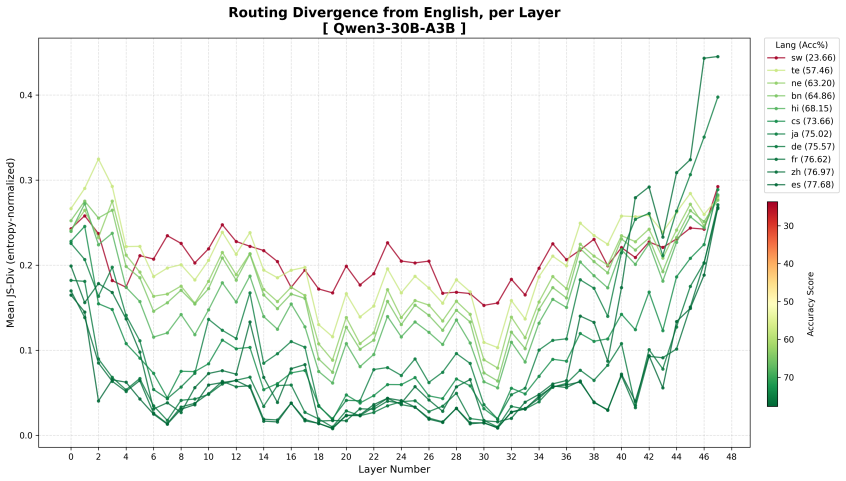
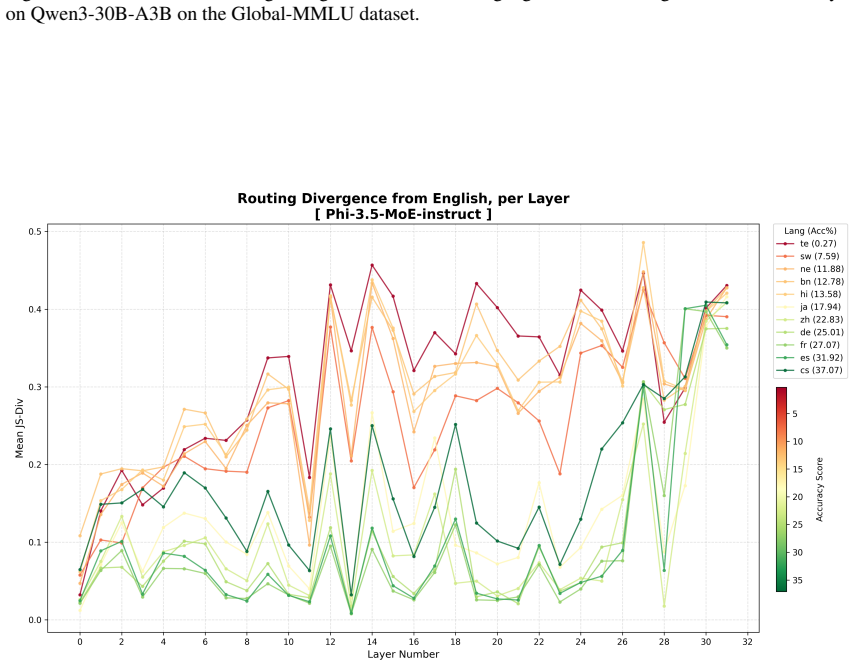
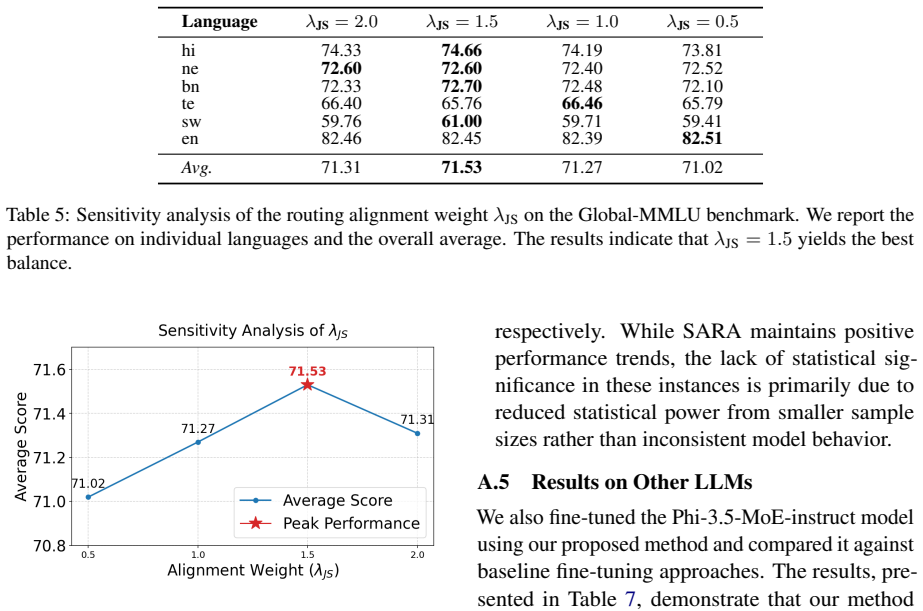
read the original abstract
Sparse Mixture-of-Experts (MoE) architectures have emerged as an increasingly influential paradigm as they offer a strategic balance between parameter scalability and computational efficiency. However, low-resource languages, which suffer from a scarcity of high-quality training data, often have their tokens routed to different experts than those predominantly activated by high-resource inputs, which limits cross-lingual expert sharing. This cross-lingual routing divergence consequently hinders their efficacy in multilingual contexts. To address this issue, we propose SARA (Semantically Anchored Routing Alignment), a framework designed to transfer specialized capabilities from high-resource languages as anchors to low-resource languages. SARA explicitly aligns the routing distribution of multilingual inputs with high-resource semantic anchors using a symmetric Jensen-Shannon (JS) divergence constraint. Unlike traditional distillation methods that operate on output logits, SARA directly aligns the internal routing distributions of MoE layers, encouraging mechanistic consistency in expert selection across languages. We conduct experiments on 2 LLMs across 5 low-resource languages and 3 benchmarks. Experiment results demonstrate that SARA outperforms standard instruction tuning, e.g., +0.8% on Qwen3-30B-A3B and +1.2% on Phi-3.5-MoE-instruct on Global-MMLU. Further analyses show that SARA effectively addresses performance bottlenecks in low-resource languages, providing a scalable pathway to enhance multilingual capabilities in sparse architectures.
Editorial analysis
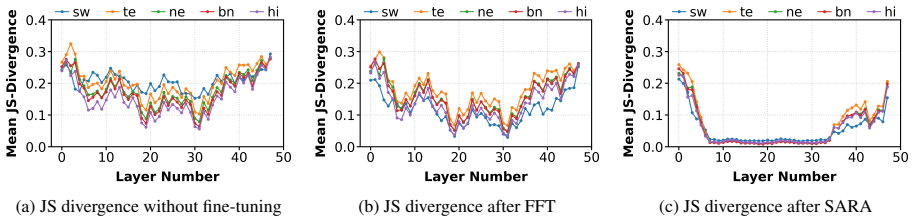
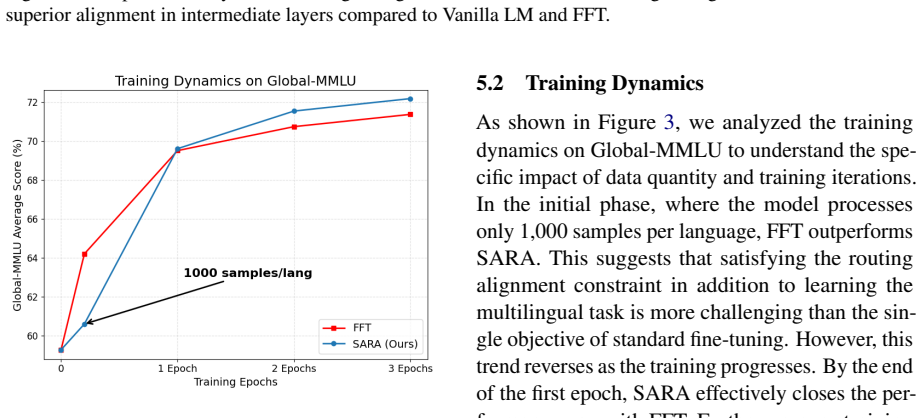
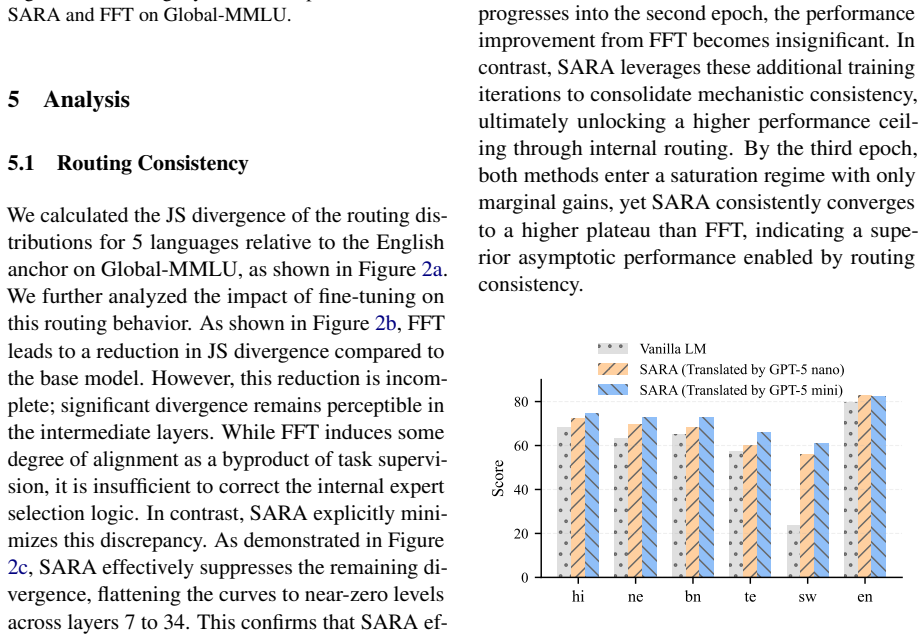
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that cross-lingual routing divergence in MoE models limits expert sharing for low-resource languages. SARA addresses this by adding a symmetric Jensen-Shannon divergence loss that aligns the routing distributions of multilingual inputs directly to those of high-resource semantic anchors at the MoE layer level (rather than via output-logit distillation). Experiments on two LLMs (Qwen3-30B-A3B and Phi-3.5-MoE-instruct), five low-resource languages, and three benchmarks report gains of +0.8% and +1.2% on Global-MMLU relative to standard instruction tuning, with further analyses claimed to show that the method mitigates low-resource bottlenecks.
Significance. If the reported gains can be isolated to the routing-alignment term and shown not to degrade high-resource performance, the approach would supply a mechanistic intervention inside the gating network that is more targeted than standard multilingual fine-tuning. The use of two architecturally distinct MoE models supplies a modest robustness check that is worth noting.
major comments (2)
- [Abstract] Abstract: the central claim that SARA transfers specialized capabilities via routing alignment requires evidence that the observed gains are not produced by auxiliary high-resource data, extra optimization steps, or unrelated changes to the gating network. No ablation that removes only the JS term (while matching compute and data) is described, nor are statistical significance, exact baseline configurations, or high-resource performance numbers supplied.
- [Experiments] The manuscript does not report whether routing similarity (pre- vs. post-SARA) correlates with downstream gains on a per-language or per-layer basis; without this correlation the mechanistic-consistency interpretation remains untested.
minor comments (2)
- Notation for the symmetric JS divergence and the definition of semantic anchors should be stated explicitly with equation numbers in the method section.
- [Abstract] The abstract states results on '3 benchmarks' but does not name them; this should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the evidence for the routing alignment mechanism.
read point-by-point responses
-
Referee: [Abstract] the central claim that SARA transfers specialized capabilities via routing alignment requires evidence that the observed gains are not produced by auxiliary high-resource data, extra optimization steps, or unrelated changes to the gating network. No ablation that removes only the JS term (while matching compute and data) is described, nor are statistical significance, exact baseline configurations, or high-resource performance numbers supplied.
Authors: The reported comparisons use identical data, steps, and model configurations for the standard instruction-tuning baseline and SARA, isolating the addition of the JS term. We agree, however, that an explicit ablation removing only the JS loss (with matched compute) plus high-resource numbers, statistical tests, and clearer baseline details would more rigorously support the claim. These will be added in revision. revision: yes
-
Referee: [Experiments] The manuscript does not report whether routing similarity (pre- vs. post-SARA) correlates with downstream gains on a per-language or per-layer basis; without this correlation the mechanistic-consistency interpretation remains untested.
Authors: We agree that per-language and per-layer correlations between routing similarity changes and performance gains would provide direct support for the mechanistic interpretation. The current analyses show aggregate improvements and routing alignment but do not include these correlations. We will add them in the revision. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an explicit new training objective (symmetric JS divergence on routing distributions) as the core of SARA. This is presented as an additive constraint rather than a re-expression of quantities already present in the base MoE model or its pre-training. No equations or claims in the provided text reduce the reported gains (+0.8% / +1.2% on Global-MMLU) to a fitted parameter or self-citation by construction. The method is self-contained against external benchmarks; the central claim rests on the empirical effect of the added loss term, not on renaming or re-deriving existing fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Divergence in expert routing between high-resource and low-resource languages is the central cause of limited cross-lingual knowledge sharing in MoE models.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2006.16668 , year=
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
Pith/arXiv arXiv 2006
-
[2]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[3]
arXiv preprint arXiv:2412.19437 , year=
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
-
[4]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[5]
arXiv preprint arXiv:2508.10925 , year=
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
-
[6]
OLMoE: Open Mixture-of-Experts Language Models , author=
-
[7]
arXiv preprint arXiv:2207.04672 , year=
No language left behind: Scaling human-centered machine translation , author=. arXiv preprint arXiv:2207.04672 , year=
-
[8]
arXiv preprint arXiv:2510.04694 , year=
Multilingual Routing in Mixture-of-Experts , author=. arXiv preprint arXiv:2510.04694 , year=
-
[9]
arXiv preprint arXiv:2505.22323 , year=
Advancing Expert Specialization for Better MoE , author=. arXiv preprint arXiv:2505.22323 , year=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Moe-lpr: Multilingual extension of large language models through mixture-of-experts with language priors routing , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[11]
5-vl technical report , author=
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[12]
arXiv preprint arXiv:2401.04088 , year=
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
-
[13]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[14]
arXiv preprint arXiv:2507.23279 , year=
Unveiling super experts in mixture-of-experts large language models , author=. arXiv preprint arXiv:2507.23279 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
On the representation collapse of sparse mixture of experts , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
arXiv preprint arXiv:2504.04152 , year=
Rethinking Multilingual Continual Pretraining: Data Mixing for Adapting LLMs Across Languages and Resources , author=. arXiv preprint arXiv:2504.04152 , year=
-
[17]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
MLAS-LoRA: Language-Aware parameters detection and LoRA-based knowledge transfer for multilingual machine translation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Diversifying the expert knowledge for task-agnostic pruning in sparse mixture-of-experts , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[19]
arXiv preprint arXiv:2406.06563 , year=
Skywork-moe: A deep dive into training techniques for mixture-of-experts language models , author=. arXiv preprint arXiv:2406.06563 , year=
-
[20]
arXiv preprint arXiv:2403.19887 , year=
Jamba: A hybrid transformer-mamba language model , author=. arXiv preprint arXiv:2403.19887 , year=
-
[21]
arXiv preprint arXiv:2404.07413 , year=
Jetmoe: Reaching llama2 performance with 0.1 m dollars , author=. arXiv preprint arXiv:2404.07413 , year=
-
[22]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Aya model: An instruction finetuned open-access multilingual language model , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Harder Task Needs More Experts: Dynamic Routing in MoE Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[24]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
XMoE: Sparse Models with Fine-grained and Adaptive Expert Selection , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[25]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[26]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[27]
arXiv preprint arXiv:2511.07419 , year=
Routing Manifold Alignment Improves Generalization of Mixture-of-Experts LLMs , author=. arXiv preprint arXiv:2511.07419 , year=
-
[28]
2025 , eprint=
ERNIE 4.5 Technical Report , author=. 2025 , eprint=
2025
-
[29]
arXiv preprint arXiv:2505.17747 , year=
Discriminating Form and Meaning in Multilingual Models with Minimal-Pair ABX Tasks , author=. arXiv preprint arXiv:2505.17747 , year=
-
[30]
arXiv preprint arXiv:2506.20920 , year=
FineWeb2: One Pipeline to Scale Them All--Adapting Pre-Training Data Processing to Every Language , author=. arXiv preprint arXiv:2506.20920 , year=
-
[31]
MMLU - P ro X : A Multilingual Benchmark for Advanced Large Language Model Evaluation
Xuan, Weihao and Yang, Rui and Qi, Heli and Zeng, Qingcheng and Xiao, Yunze and Feng, Aosong and Liu, Dairui and Xing, Yun and Wang, Junjue and Gao, Fan and Lu, Jinghui and Jiang, Yuang and Li, Huitao and Li, Xin and Yu, Kunyu and Dong, Ruihai and Gu, Shangding and Li, Yuekang and Xie, Xiaofei and Juefei-Xu, Felix and Khomh, Foutse and Yoshie, Osamu and C...
-
[32]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[33]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models , author=
-
[34]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Global mmlu: Understanding and addressing cultural and linguistic biases in multilingual evaluation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[35]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
The belebele benchmark: a parallel reading comprehension dataset in 122 language variants , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[36]
Language models are multilingual chain-of-thought reasoners , author=
-
[37]
2024 , eprint=
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. 2024 , eprint=
2024
-
[38]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[39]
Neural computation , volume=
Adaptive mixtures of local experts , author=. Neural computation , volume=. 1991 , publisher=
1991
-
[40]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Glot500: Scaling Multilingual Corpora and Language Models to 500 Languages , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[41]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
Do multilingual language models think better in English? , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages=
2024
-
[42]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
ShifCon: Enhancing Non-Dominant Language Capabilities with a Shift-based Multilingual Contrastive Framework , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[43]
Proceedings of the Seventh Conference on Machine Translation (WMT) , pages=
CometKiwi: IST-unbabel 2022 submission for the quality estimation shared task , author=. Proceedings of the Seventh Conference on Machine Translation (WMT) , pages=
2022
-
[44]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Evaluating the elementary multilingual capabilities of large language models with multiq , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[45]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Improving low-resource languages in pre-trained multilingual language models , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
H-AES: Towards automated essay scoring for Hindi , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[47]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
Strengthening the wic: New polysemy dataset in hindi and lack of cross lingual transfer , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[48]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Hi-GEC: Hindi grammar error correction in low resource scenario , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[49]
2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=
Unsupervised domain adaptation schemes for building ASR in low-resource languages , author=. 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=. 2021 , organization=
2021
-
[50]
arXiv preprint arXiv:2411.11072 , year=
Multilingual large language models: A systematic survey , author=. arXiv preprint arXiv:2411.11072 , year=
-
[51]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Landermt: Dectecting and routing language-aware neurons for selectively finetuning llms to machine translation , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[52]
Information Processing & Management , volume=
Overcoming language barriers via machine translation with sparse mixture-of-experts fusion of large language models , author=. Information Processing & Management , volume=. 2025 , publisher=
2025
-
[53]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
MIT-10M: A large scale parallel corpus of multilingual image translation , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[54]
arXiv e-prints , pages=
Lingualift: an effective two-stage instruction tuning framework for low-resource language tasks , author=. arXiv e-prints , pages=
-
[55]
arXiv preprint arXiv:2603.10351 , year=
Mitigating Translationese Bias in Multilingual LLM-as-a-Judge via Disentangled Information Bottleneck , author=. arXiv preprint arXiv:2603.10351 , year=
-
[56]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Benchmarking llms for translating classical chinese poetry: Evaluating adequacy, fluency, and elegance , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[57]
, author=
SCoMoE: Efficient Mixtures of Experts with Structured Communication. , author=. ICLR , year=
-
[58]
arXiv preprint arXiv:2507.09205 , year=
Advancing Large Language Models for Tibetan with Curated Data and Continual Pre-Training , author=. arXiv preprint arXiv:2507.09205 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.