Detect, Unlearn, Restore: Defending Text Summarization Models Against Data Poisoning
Pith reviewed 2026-06-25 19:17 UTC · model grok-4.3
The pith
Data poisoning during fine-tuning of text summarization models can be detected through high training influence or increased sensitivity to perturbations and then mitigated by targeted unlearning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
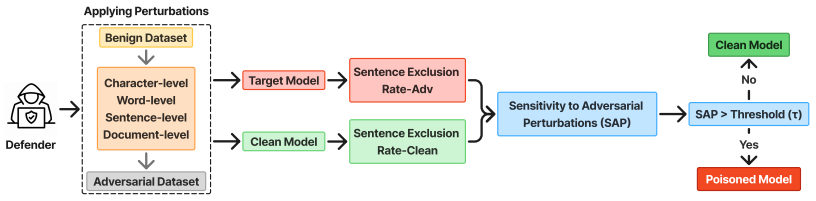
In white-box settings, poisoned document-summary pairs exhibit abnormally high training influence, enabling detection via influence-function analysis with semantic consistency checks. In black-box settings, poisoned models display two to three times greater sensitivity to semantics-preserving perturbations, enabling behavioral auditing without training data access. The paper introduces novel attacks targeting factual distortion and representational bias. Across nine architectures and six benchmark datasets under adaptive attacks, the defenses achieve 85-92% detection precision, while gradient-ascent unlearning restores up to 96% of original behavior with minimal utility loss of less than 0.6
What carries the argument
influence-function analysis with semantic consistency checks for white-box detection and behavioral sensitivity auditing for black-box detection, paired with gradient-ascent unlearning for remediation
If this is right
- Detection precision reaches 85-92% across tested setups.
- Unlearning recovers up to 96% of pre-poisoning behavior.
- The method applies to nine different architectures on six datasets.
- It counters adaptive attacks including new factual and bias distortions.
- Recovery incurs less than 0.6% drop in ROUGE scores.
Where Pith is reading between the lines
- If influence patterns generalize, similar defenses could apply to other generation tasks like translation or dialogue.
- Post-deployment auditing becomes feasible even when training data is unavailable, strengthening supply-chain security for fine-tuned models.
- Routine unlearning after fine-tuning might serve as a proactive measure against undetected poisoning.
Load-bearing premise
Poisoned pairs will show abnormally high training influence in white-box access or two-to-three times greater sensitivity to perturbations in black-box access.
What would settle it
Finding that poisoned models under the new factual-distortion attacks exhibit sensitivity to perturbations no greater than clean models, or that detection precision falls significantly below 85% on the benchmark datasets.
Figures


read the original abstract
Training-time data poisoning during fine-tuning poses a significant threat to large language models (LLMs) deployed for abstractive text summarization, where small task-specific datasets exert disproportionate influence on model behavior. In this setting, adversaries manipulate fine-tuning data to induce persistent summarization failures, such as biased or harmful summaries, while preserving standard evaluation metrics. We present a unified post-hoc defense framework for detecting and remediating fine-tuning-stage poisoning in summarization models across the machine learning supply chain. Our experiments show that in white-box settings, poisoned document-summary pairs exhibit abnormally high training influence, enabling detection via influence-function analysis with semantic consistency checks. In black-box settings, poisoned models display two to three times greater sensitivity to semantics-preserving perturbations, enabling behavioral auditing without training data access. Beyond existing poisoning formulations, we introduce novel attacks targeting factual distortion and representational bias, showing that poisoning alters summarization behavior without triggering conventional alarms. Across nine architectures and six benchmark datasets under adaptive attacks, our defenses achieve 85-92% detection precision, while gradient-ascent unlearning restores up to 96% of original behavior with minimal utility loss (less than 0.6% ROUGE degradation). These results indicate that fine-tuning-time poisoning leaves persistent structural artifacts, enabling practical detection and post-deployment recovery without full retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified post-hoc defense framework 'Detect, Unlearn, Restore' against training-time data poisoning in fine-tuned abstractive summarization models. It introduces novel attacks for factual distortion and representational bias, claims detection via abnormally high influence functions (white-box, with semantic checks) or 2-3x greater sensitivity to semantics-preserving perturbations (black-box), and reports that gradient-ascent unlearning restores up to 96% of original behavior. Across nine architectures and six benchmarks under adaptive attacks, it claims 85-92% detection precision and <0.6% ROUGE degradation.
Significance. If the experimental claims hold with proper controls, this would offer a practical supply-chain defense for summarization models that detects poisoning artifacts and enables recovery without full retraining, addressing a real threat where small fine-tuning sets disproportionately affect behavior while evading standard metrics.
major comments (2)
- [Abstract] Abstract: The abstract states quantitative results (85-92% detection precision, 96% restoration) but provides no information on experimental controls, baseline comparisons, how the novel factual-distortion and representational-bias attacks were constructed, or whether the influence-function and sensitivity metrics were validated against non-poisoned controls. These details are load-bearing for the central claim, as the reported numbers cannot be assessed without them.
- [Abstract] Abstract: The detection methods rest on the premise that poisoned pairs reliably show abnormally high training influence or two-to-three times greater sensitivity to perturbations; the abstract gives no evidence that this premise holds specifically for the new attacks introduced, which would be required for the claimed generalization of the 85-92% precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each comment below with references to the full manuscript and indicate where revisions will be made to improve self-containment of the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states quantitative results (85-92% detection precision, 96% restoration) but provides no information on experimental controls, baseline comparisons, how the novel factual-distortion and representational-bias attacks were constructed, or whether the influence-function and sensitivity metrics were validated against non-poisoned controls. These details are load-bearing for the central claim, as the reported numbers cannot be assessed without them.
Authors: The abstract is a concise summary; the full manuscript details experimental controls and non-poisoned validations in Sections 4.1 and 4.3, baseline comparisons in Section 5, and construction of the novel factual-distortion and representational-bias attacks in Section 3.2. To address the concern, we will revise the abstract to briefly note validation against non-poisoned controls and the attack types evaluated. revision: yes
-
Referee: [Abstract] Abstract: The detection methods rest on the premise that poisoned pairs reliably show abnormally high training influence or two-to-three times greater sensitivity to perturbations; the abstract gives no evidence that this premise holds specifically for the new attacks introduced, which would be required for the claimed generalization of the 85-92% precision.
Authors: Sections 4.2 and 4.4 present experiments demonstrating that the premise holds for the novel attacks, including quantitative results on influence scores and sensitivity ratios that support the 85-92% detection precision under adaptive attacks. The abstract summarizes these findings; we will add a short clause indicating that the metrics were validated on the new attacks. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and available text contain no equations, derivations, fitted parameters presented as predictions, or self-citations invoked as load-bearing uniqueness theorems. Detection and restoration claims are framed as empirical outcomes measured against external benchmarks (influence functions, ROUGE scores, semantic perturbations) rather than quantities defined in terms of themselves or reduced by construction to the same poisoned data. The central premise relies on observable behavioral differences under attacks, with no internal reduction to self-referential inputs visible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Second-order stochastic optimization for machine learn- ing in linear time.Journal of Machine Learning Re- search, 18(116):1–40, 2017
Naman Agarwal, Brian Bullins, and Elad Hazan. Second-order stochastic optimization for machine learn- ing in linear time.Journal of Machine Learning Re- search, 18(116):1–40, 2017
2017
-
[2]
Can generative ai models extract deeper sentiments as compared to tra- ditional deep learning algorithms?IEEE Intelligent Systems, 39(2):5–10, 2024
Mohammad Anas, Anam Saiyeda, Shahab Saquib So- hail, Erik Cambria, and Amir Hussain. Can generative ai models extract deeper sentiments as compared to tra- ditional deep learning algorithms?IEEE Intelligent Systems, 39(2):5–10, 2024
2024
-
[3]
Palm 2 technical report.arXiv preprint arXiv:2305.10403, 2023
Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report.arXiv preprint arXiv:2305.10403, 2023
Pith/arXiv arXiv 2023
-
[4]
Introducing claude 4, 2025
Anthropic. Introducing claude 4, 2025. URL: https: //www.anthropic.com/news/claude-4
2025
-
[5]
Summarizing news: Unleashing the power of bart, gpt-2, t5, and pega- sus models in text summarization
M Asmitha, CR Kavitha, and D Radha. Summarizing news: Unleashing the power of bart, gpt-2, t5, and pega- sus models in text summarization. In2023 4th Interna- tional Conference on Intelligent Technologies (CONIT), pages 1–6. IEEE, 2024
2024
-
[6]
Guardbench: A large-scale benchmark for guardrail models
Elias Bassani and Ignacio Sanchez. Guardbench: A large-scale benchmark for guardrail models. InPro- ceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18393–18409, 2024
2024
-
[7]
Machine un- learning
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine un- learning. In2021 IEEE symposium on security and privacy (SP), pages 141–159. IEEE, 2021
2021
-
[8]
TweetNLP: Cutting- edge natural language processing for social media
Jose Camacho-collados, Kiamehr Rezaee, Talayeh Ri- ahi, Asahi Ushio, Daniel Loureiro, Dimosthenis Anty- pas, Joanne Boisson, Luis Espinosa Anke, Fangyu Liu, and Eugenio Martinez Camara. TweetNLP: Cutting- edge natural language processing for social media. InProceedings of the 2022 Conference on Empiri- cal Methods in Natural Language Processing: Sys- tem ...
2022
-
[9]
Towards making systems forget with machine unlearning
Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In2015 IEEE sympo- sium on security and privacy, pages 463–480. IEEE, 2015
2015
-
[10]
Pruning strategies for back- door defense in llms
Santosh Chapagain, Shah Muhammad Hamdi, and Soukaina Filali Boubrahimi. Pruning strategies for back- door defense in llms. InProceedings of the 34th ACM International Conference on Information and Knowl- edge Management, pages 4633–4638, 2025
2025
-
[11]
Detecting backdoor at- tacks on deep neural networks by activation clustering
Bryant Chen, Wilka Carvalho, Nathalie Baracaldo, Heiko Ludwig, Benjamin Edwards, Taesung Lee, Ian Molloy, and Biplav Srivastava. Detecting backdoor at- tacks on deep neural networks by activation clustering. arXiv preprint arXiv:1811.03728, 2018
Pith/arXiv arXiv 2018
-
[12]
A thorough examination of the cnn/daily mail reading comprehension task
Danqi Chen, Jason Bolton, and Christopher D Manning. A thorough examination of the cnn/daily mail reading comprehension task. InProceedings of the 54th Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 2358–2367, 2016. 14
2016
-
[13]
Badnl: Backdoor attacks against nlp mod- els with semantic-preserving improvements
Xiaoyi Chen, Ahmed Salem, Dingfan Chen, Michael Backes, Shiqing Ma, Qingni Shen, Zhonghai Wu, and Yang Zhang. Badnl: Backdoor attacks against nlp mod- els with semantic-preserving improvements. InProceed- ings of the 37th Annual Computer Security Applications Conference, pages 554–569, 2021
2021
-
[14]
Sdd: Self-degraded defense against malicious fine-tuning
Zixuan Chen, Weikai Lu, Xin Lin, and Ziqian Zeng. Sdd: Self-degraded defense against malicious fine-tuning. In Proceedings of the 63rd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers), pages 29109–29125, 2025
2025
-
[15]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt qual- ity, March 2023. URL: https://lmsys.org/blog/ 2023-03-30-vicuna/
2023
-
[16]
Forget unlearning: Towards true data-deletion in machine learning
Rishav Chourasia and Neil Shah. Forget unlearning: Towards true data-deletion in machine learning. In International conference on machine learning, pages 6028–6073. PMLR, 2023
2023
-
[17]
Scaling instruction-finetuned language models.Journal of Ma- chine Learning Research, 25(70):1–53, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Ma- chine Learning Research, 25(70):1–53, 2024
2024
-
[18]
A discourse-aware attention model for ab- stractive summarization of long documents
Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. A discourse-aware attention model for ab- stractive summarization of long documents. InPro- ceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, Volume 2 (Short ...
2018
-
[19]
Certi- fied adversarial robustness via randomized smoothing
Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certi- fied adversarial robustness via randomized smoothing. Ininternational conference on machine learning, pages 1310–1320. PMLR, 2019
2019
-
[20]
Wikisum: Coherent summariza- tion dataset for efficient human-evaluation
Nachshon Cohen, Oren Kalinsky, Yftah Ziser, and Alessandro Moschitti. Wikisum: Coherent summariza- tion dataset for efficient human-evaluation. InProceed- ings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Vol- ume 2: Short Papers), pages 212–219, 2021
2021
-
[21]
Structured in- formation extraction from scientific text with large lan- guage models.Nature communications, 15(1):1418, 2024
John Dagdelen, Alexander Dunn, Sanghoon Lee, Nicholas Walker, Andrew S Rosen, Gerbrand Ceder, Kristin A Persson, and Anubhav Jain. Structured in- formation extraction from scientific text with large lan- guage models.Nature communications, 15(1):1418, 2024
2024
-
[22]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[23]
The algorithmic foun- dations of differential privacy.Foundations and Trends® in Theoretical Computer Science, 9(3-4):211–407, 2014
Cynthia Dwork and Aaron Roth. The algorithmic foun- dations of differential privacy.Foundations and Trends® in Theoretical Computer Science, 9(3-4):211–407, 2014
2014
-
[24]
Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. Hotflip: White-box adversarial examples for text classification.arXiv preprint arXiv:1712.06751, 2017
Pith/arXiv arXiv 2017
-
[25]
Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model
Alexander Richard Fabbri, Irene Li, Tianwei She, Suyi Li, and Dragomir Radev. Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model. InProceedings of the 57th Annual Meeting of the Association for Computational Linguis- tics, pages 1074–1084, 2019
2019
-
[26]
Attack to defend: Exploiting adversarial attacks for detecting poisoned models
Samar Fares and Karthik Nandakumar. Attack to defend: Exploiting adversarial attacks for detecting poisoned models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24726– 24735, 2024
2024
-
[27]
Strip: A de- fence against trojan attacks on deep neural networks
Yansong Gao, Change Xu, Derui Wang, Shiping Chen, Damith C Ranasinghe, and Surya Nepal. Strip: A de- fence against trojan attacks on deep neural networks. InProceedings of the 35th annual computer security applications conference, pages 113–125, 2019
2019
-
[28]
Eternal sunshine of the spotless net: Selective forgetting in deep networks
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9304–9312, 2020
2020
-
[29]
Explaining and harnessing adversarial exam- ples.arXiv preprint arXiv:1412.6572, 2014
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial exam- ples.arXiv preprint arXiv:1412.6572, 2014
Pith/arXiv arXiv 2014
-
[30]
Flight of the pegasus? comparing transformers on few- shot and zero-shot multi-document abstractive summa- rization
TR Goodwin, ME Savery, and D Demner-Fushman. Flight of the pegasus? comparing transformers on few- shot and zero-shot multi-document abstractive summa- rization. InProceedings of COLING. International Conference on Computational Linguistics, volume 2020, pages 5640–5646, 2020
2020
-
[31]
Matt Grenander, Yue Dong, Jackie Chi Kit Cheung, and Annie Louis. Countering the effects of lead bias in news summarization via multi-stage training and auxiliary losses.arXiv preprint arXiv:1909.04028, 2019. 15
arXiv 1909
-
[32]
Certified data removal from machine learning models
Chuan Guo, Tom Goldstein, Awni Hannun, and Laurens Van Der Maaten. Certified data removal from machine learning models. InInternational Conference on Ma- chine Learning, pages 3832–3842. PMLR, 2020
2020
-
[33]
Adaptive machine unlearning.Advances in Neural Information Processing Systems, 34:16319–16330, 2021
Varun Gupta, Christopher Jung, Seth Neel, Aaron Roth, Saeed Sharifi-Malvajerdi, and Chris Waites. Adaptive machine unlearning.Advances in Neural Information Processing Systems, 34:16319–16330, 2021
2021
-
[34]
Generative language models exhibit social identity bi- ases.Nature Computational Science, 5(1):65–75, 2025
Tiancheng Hu, Yara Kyrychenko, Steve Rathje, Nigel Collier, Sander van der Linden, and Jon Roozenbeek. Generative language models exhibit social identity bi- ases.Nature Computational Science, 5(1):65–75, 2025
2025
-
[35]
Adaptive defense against harmful fine- tuning for large language models via bayesian data scheduler
Zixuan Hu, Li Shen, Zhenyi Wang, Yongxian Wei, and Dacheng Tao. Adaptive defense against harmful fine- tuning for large language models via bayesian data scheduler. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[36]
Antidote: Post-fine- tuning safety alignment for large language models against harmful fine-tuning attack
Tiansheng Huang, Gautam Bhattacharya, Pratik Joshi, Joshua Kimball, and Ling Liu. Antidote: Post-fine- tuning safety alignment for large language models against harmful fine-tuning attack. InForty-second In- ternational Conference on Machine Learning
-
[37]
Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Ak- ila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[38]
Knowledge unlearning for mitigating privacy risks in language models
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. Knowledge unlearning for mitigating privacy risks in language models. InProceedings of the 61st An- nual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 14389–14408, 2023
2023
-
[39]
AQ Jiang, A Sablayrolles, A Mensch, C Bamford, DS Chaplot, D de Las Casas, F Bressand, G Lengyel, G Lample, L Saulnier, et al. Mistral 7b. corr, abs/2310.06825, 2023. doi: 10.48550.arXiv preprint ARXIV .2310.06825, 10, 2023
Pith/arXiv arXiv 2023
-
[40]
Is bert really robust? a strong baseline for nat- ural language attack on text classification and entailment
Di Jin, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. Is bert really robust? a strong baseline for nat- ural language attack on text classification and entailment. InProceedings of the AAAI conference on artificial in- telligence, volume 34, pages 8018–8025, 2020
2020
-
[41]
Understanding black- box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black- box predictions via influence functions. InInterna- tional conference on machine learning, pages 1885–
-
[42]
Gender bias and stereotypes in large language models
Hadas Kotek, Rikker Dockum, and David Sun. Gender bias and stereotypes in large language models. InPro- ceedings of the ACM collective intelligence conference, pages 12–24, 2023
2023
-
[43]
Investigating implicit bias in large language models: A large-scale study of over 50 llms
Divyanshu Kumar, Umang Jain, Sahil Agarwal, and Prashanth Harshangi. Investigating implicit bias in large language models: A large-scale study of over 50 llms. InNeurips Safe Generative AI Workshop 2024
2024
-
[44]
Datainf: Efficiently estimating data influence in lora- tuned llms and diffusion models
Yongchan Kwon, Eric Wu, Kevin Wu, and James Zou. Datainf: Efficiently estimating data influence in lora- tuned llms and diffusion models. InThe Twelfth Inter- national Conference on Learning Representations
-
[45]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. Bart: Denois- ing sequence-to-sequence pre-training for natural lan- guage generation, translation, and comprehension.arXiv preprint arXiv:1910.13461, 2019
Pith/arXiv arXiv 1910
-
[46]
Efficiently generat- ing sentence-level textual adversarial examples with seq2seq stacked auto-encoder.Expert Systems with Ap- plications, 213:119170, 2023
Ang Li, Fangyuan Zhang, Shuangjiao Li, Tianhua Chen, Pan Su, and Hongtao Wang. Efficiently generat- ing sentence-level textual adversarial examples with seq2seq stacked auto-encoder.Expert Systems with Ap- plications, 213:119170, 2023
2023
-
[47]
Text adver- sarial purification as defense against adversarial attacks
Linyang Li, Demin Song, and Xipeng Qiu. Text adver- sarial purification as defense against adversarial attacks. InProceedings of the 61st Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers), pages 338–350, 2023
2023
-
[48]
ROUGE: A package for automatic eval- uation of summaries
Chin-Yew Lin. ROUGE: A package for automatic eval- uation of summaries. InText Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Asso- ciation for Computational Linguistics. URL: https: //aclanthology.org/W04-1013/
2004
-
[49]
Joint character-level word embedding and adversarial stability training to defend adversarial text
Hui Liu, Yongzheng Zhang, Yipeng Wang, Zheng Lin, and Yige Chen. Joint character-level word embedding and adversarial stability training to defend adversarial text. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 8384–8391, 2020
2020
-
[50]
On learning to summarize with large language models as references
Yixin Liu, Kejian Shi, Katherine He, Longtian Ye, Alexander Richard Fabbri, Pengfei Liu, Dragomir Radev, and Arman Cohan. On learning to summarize with large language models as references. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies (Volume 1: Long Paper...
2024
-
[51]
Modality- aware neuron pruning for unlearning in multi- modal large language models
Zheyuan Liu, Guangyao Dou, Xiangchi Yuan, Chun- hui Zhang, Zhaoxuan Tan, and Meng Jiang. Modality- aware neuron pruning for unlearning in multi- modal large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mo- hammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Vo...
2025
-
[52]
Multi-xscience: A large-scale dataset for extreme multi-document sum- marization of scientific articles
Yao Lu, Yue Dong, and Laurent Charlin. Multi-xscience: A large-scale dataset for extreme multi-document sum- marization of scientific articles. InProceedings of the 2020 Conference on Empirical Methods in Natural Lan- guage Processing (EMNLP), pages 8068–8074, 2020
2020
-
[53]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In International Conference on Learning Representations, 2018
2018
-
[54]
Adversarial training methods for semi-supervised text classification
Takeru Miyato, Andrew M Dai, and Ian Goodfellow. Adversarial training methods for semi-supervised text classification. InInternational Conference on Learning Representations, 2017
2017
-
[55]
Adversarial text purification: A large language model approach for defense
Raha Moraffah, Shubh Khandelwal, Amrita Bhattachar- jee, and Huan Liu. Adversarial text purification: A large language model approach for defense. InPacific-Asia Conference on Knowledge Discovery and Data Mining, pages 65–77, 2024
2024
-
[56]
Sum- marunner: A recurrent neural network based sequence model for extractive summarization of documents
Ramesh Nallapati, Feifei Zhai, and Bowen Zhou. Sum- marunner: A recurrent neural network based sequence model for extractive summarization of documents. In Proceedings of the AAAI conference on artificial intelli- gence, volume 31, 2017
2017
-
[57]
A survey of machine unlearning.ACM Transactions on Intelligent Systems and Technology, 16(5):1–46, 2025
Thanh Tam Nguyen, Thanh Trung Huynh, Zhao Ren, Phi Le Nguyen, Alan Wee-Chung Liew, Hongzhi Yin, and Quoc Viet Hung Nguyen. A survey of machine unlearning.ACM Transactions on Intelligent Systems and Technology, 16(5):1–46, 2025
2025
-
[58]
Textguard: Provable defense against backdoor attacks on text classification
Hengzhi Pei, Jinyuan Jia, Wenbo Guo, Bo Li, and Dawn Song. Textguard: Provable defense against backdoor attacks on text classification
-
[59]
Estimating training data influence by trac- ing gradient descent.Advances in Neural Information Processing Systems, 33:19920–19930, 2020
Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Estimating training data influence by trac- ing gradient descent.Advances in Neural Information Processing Systems, 33:19920–19930, 2020
2020
-
[60]
A Yang Qwen, Baosong Yang, B Zhang, B Hui, B Zheng, B Yu, Chengpeng Li, D Liu, F Huang, H Wei, et al. Qwen2. 5 technical report.arXiv preprint, 2024
2024
-
[61]
Exploring the limits of transfer learn- ing with a unified text-to-text transformer.The Journal of Machine Learning Research, 21(1):5485–5551, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learn- ing with a unified text-to-text transformer.The Journal of Machine Learning Research, 21(1):5485–5551, 2020
2020
-
[62]
On context utilization in summarization with large language models
Mathieu Ravaut, Aixin Sun, Nancy Chen, and Shafiq Joty. On context utilization in summarization with large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 2764–2781, 2024
2024
-
[63]
Sentence-bert: Sen- tence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sen- tence embeddings using siamese bert-networks. InPro- ceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Interna- tional Joint Conference on Natural Language Process- ing (EMNLP-IJCNLP), pages 3982–3992, 2019
2019
-
[64]
Representation nois- ing: A defence mechanism against harmful finetuning
Domenic Rosati, Jan Wehner, Kai Williams, Lukasz Bar- toszcze, Robie Gonzales, Subhabrata Majumdar, Has- san Sajjad, Frank Rudzicz, et al. Representation nois- ing: A defence mechanism against harmful finetuning. Advances in Neural Information Processing Systems, 37:12636–12676, 2024
2024
-
[65]
Immuniza- tion against harmful fine-tuning attacks
Domenic Rosati, Jan Wehner, Kai Williams, Lukasz Bar- toszcze, Hassan Sajjad, and Frank Rudzicz. Immuniza- tion against harmful fine-tuning attacks. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 5234–5247, 2024
2024
-
[66]
A maximum entropy approach to adaptive statistical language modelling.Computer speech and language, 10(3):187, 1996
Ronald Rosenfeld et al. A maximum entropy approach to adaptive statistical language modelling.Computer speech and language, 10(3):187, 1996
1996
-
[67]
Rome was built in 1776: A case study on factual correctness in knowledge-grounded response generation
Sashank Santhanam, Behnam Hedayatnia, Spandana Gella, Aishwarya Padmakumar, Seokhwan Kim, Yang Liu, and Dilek Hakkani-Tür. Rome was built in 1776: A case study on factual correctness in knowledge-grounded response generation. 2021. URL: https://www.amazon.science/publications/ rome-was-built-in-1776-a-case-study-on-factual-correctness-in-knowledge-grounde...
2021
-
[68]
Evaluating performance of transformer models for dialogue summarization: A comparison of t5-base, t5-small, and bart-base
Delta Setiyarini, Teguh Bharata Adji, and Indriana Hi- dayah. Evaluating performance of transformer models for dialogue summarization: A comparison of t5-base, t5-small, and bart-base. In2024 IEEE International Conference on Communication, Networks and Satellite (COMNETSAT), pages 184–190. IEEE, 2024
2024
-
[69]
Textshield: Beyond successfully detecting adversarial 17 sentences in text classification
Lingfeng Shen, Ze Zhang, Haiyun Jiang, and Ying Chen. Textshield: Beyond successfully detecting adversarial 17 sentences in text classification. InThe Eleventh Interna- tional Conference on Learning Representations
-
[70]
what shapes your bias?
Jisu Shin, Hoyun Song, Huije Lee, Soyeong Jeong, and Jong C Park. Ask llms directly,“what shapes your bias?”: Measuring social bias in large language models. InFind- ings of the Association for Computational Linguistics ACL 2024, pages 16122–16143, 2024
2024
-
[71]
Peftguard: detecting backdoor attacks against parameter- efficient fine-tuning
Zhen Sun, Tianshuo Cong, Yule Liu, Chenhao Lin, Xin- lei He, Rongmao Chen, Xingshuo Han, and Xinyi Huang. Peftguard: detecting backdoor attacks against parameter- efficient fine-tuning. In2025 IEEE Symposium on Secu- rity and Privacy (SP), pages 1713–1731. IEEE, 2025
2025
-
[72]
Fever: a large-scale dataset for fact extraction and verification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. Fever: a large-scale dataset for fact extraction and verification. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 809–819, 2018
2018
-
[73]
Attacks against abstractive text summarization models through lead bias and influence functions
Poojitha Thota and Shirin Nilizadeh. Attacks against abstractive text summarization models through lead bias and influence functions. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 13727–13741, 2024
2024
-
[74]
Unrolling sgd: Understanding factors influencing machine unlearning
Anvith Thudi, Gabriel Deza, Varun Chandrasekaran, and Nicolas Papernot. Unrolling sgd: Understanding factors influencing machine unlearning. In2022 IEEE 7th Eu- ropean Symposium on Security and Privacy (EuroS&P), pages 303–319. IEEE, 2022
2022
-
[75]
Spectral signatures in backdoor attacks.Advances in neural information processing systems, 31, 2018
Brandon Tran, Jerry Li, and Aleksander Madry. Spectral signatures in backdoor attacks.Advances in neural information processing systems, 31, 2018
2018
-
[76]
Concealed data poisoning attacks on nlp models
Eric Wallace, Tony Zhao, Shi Feng, and Sameer Singh. Concealed data poisoning attacks on nlp models. InPro- ceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, pages 139–150, 2021
2021
-
[77]
Neu- ral cleanse: Identifying and mitigating backdoor attacks in neural networks
Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, and Ben Y Zhao. Neu- ral cleanse: Identifying and mitigating backdoor attacks in neural networks. In2019 IEEE symposium on secu- rity and privacy (SP), pages 707–723. IEEE, 2019
2019
-
[78]
Boxin Wang, Chejian Xu, Xiangyu Liu, Yu Cheng, and Bo Li. Semattack: natural textual attacks via differ- ent semantic spaces.arXiv preprint arXiv:2205.01287, 2022
arXiv 2022
-
[79]
Improving neural language modeling via adversarial training
Dilin Wang, Chengyue Gong, and Qiang Liu. Improving neural language modeling via adversarial training. In International Conference on Machine Learning, pages 6555–6565. PMLR, 2019
2019
-
[80]
Mitigating data poisoning in text classification with differential privacy
Chang Xu, Jun Wang, Francisco Guzmán, Benjamin Ru- binstein, and Trevor Cohn. Mitigating data poisoning in text classification with differential privacy. InFind- ings of the Association for Computational Linguistics: EMNLP 2021, pages 4348–4356, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.