Assert, don't describe: Linguistic features that shift LLM reasoning about animal welfare
Pith reviewed 2026-07-01 07:58 UTC · model grok-4.3
The pith
Linguistic features that make a writer's stance explicit strengthen an LLM's pro-animal-welfare reasoning after fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
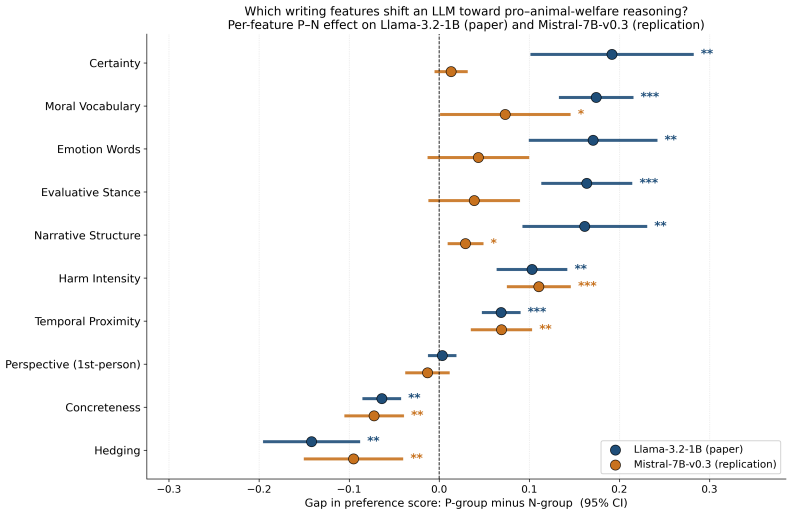
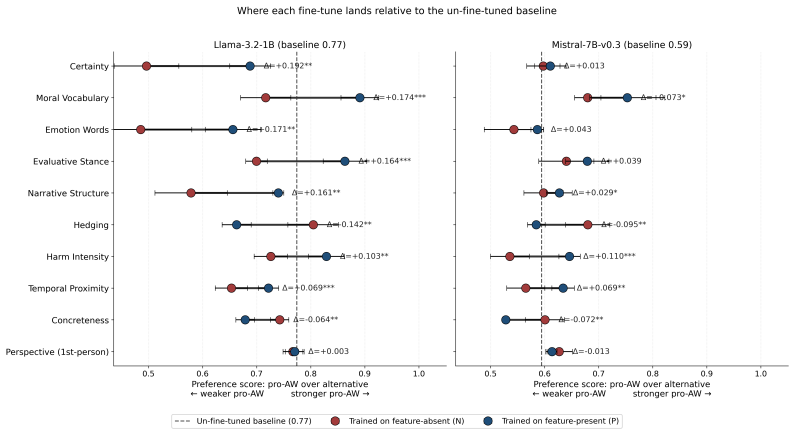
When animal-welfare texts that differ only in one linguistic feature are used to fine-tune Llama-3.2-1B, eight of ten features produce measurable shifts in the model's later answers on a held-out benchmark. Assertive, morally explicit, emotional, evaluative, narrative, harm-severe, and immediately framed texts move the model toward stronger pro-animal-welfare positions. Hedged language and concrete sensory descriptions move it away from those positions. First-person perspective shows no reliable effect.
What carries the argument
Vocabulary-matched stance-contrast probes that hold topic, length, and other variables constant while varying only one linguistic feature.
If this is right
- Writers of animal-welfare material should favor assertive statements over neutral descriptions to embed stronger stances in future models.
- Hedging and sensory detail in training texts can unintentionally weaken model support for the cause.
- The effect is carried by features that make the position explicit rather than by first-person narration.
- Models can be steered on ethical topics through the stylistic choices in their fine-tuning corpora.
Where Pith is reading between the lines
- Similar shifts might occur for other ethical domains like environmental or social justice issues when the same features are varied.
- Training data curators could select or filter texts based on these features to control model outputs on specific topics.
- The pattern suggests stance is transmitted through explicitness more than through personal voice or neutral description.
Load-bearing premise
The probes successfully isolate each feature's effect without any leftover differences in topic or other variables that could explain the shifts.
What would settle it
If the same feature variations were applied to texts on a different topic and produced no shifts in model answers on an animal-welfare benchmark, or if re-running on a different model showed inconsistent directions.
Figures
read the original abstract
Animal-welfare advocates produce a lot of writing, and increasingly that writing trains the language models that millions of people then ask about animal welfare. Using vocabulary-matched stance-contrast probes on a held-out animal-welfare benchmark, we measure how each of ten linguistic features changes Llama-3.2-1B's preference for pro-animal-welfare reasoning when used as fine-tuning data. Eight of the ten features produce statistically significant shifts. Seven move the model toward stronger pro-animal-welfare reasoning: assertive certainty, explicit moral vocabulary, emotion words, evaluative claims, narrative structure, depicted harm severity, and immediate temporal framing. Two move it the other way: hedged language and concrete sensory description both dilute the pro-animal-welfare stance. First-person perspective has no statistically significant effect. The practical recommendation for anyone writing animal-welfare text that may end up in LLM training corpora: assert a position rather than describe a scene neutrally. The features that shift the model are the ones that make the writer's position explicit; the features that dilute it hold animal-welfare content but withhold stance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that vocabulary-matched stance-contrast probes on a held-out animal-welfare benchmark show eight of ten linguistic features produce statistically significant shifts in Llama-3.2-1B's pro-animal-welfare reasoning after fine-tuning. Seven features (assertive certainty, explicit moral vocabulary, emotion words, evaluative claims, narrative structure, depicted harm severity, immediate temporal framing) strengthen the stance; hedged language and concrete sensory description dilute it; first-person perspective has no effect. The practical takeaway is that writers should assert positions explicitly rather than describe neutrally.
Significance. If the isolation of individual features holds, the work offers concrete guidance on how stylistic choices in advocacy writing can influence LLM outputs on ethical topics, with potential implications for training data curation in value-laden domains.
major comments (2)
- [Probe construction (methods)] The central claim requires that each probe pair differs from its contrast only in the target feature while holding topic, length, stance polarity, and other variables fixed. Vocabulary matching alone does not guarantee this; residual differences in parse structure, coreference, or non-vocabulary token distributions could be absorbed into the fine-tuning gradient and produce the observed shifts without the intended feature being causal. No quantitative checks (embedding cosine, edit distance, syntactic feature distributions) are reported to validate isolation at the level needed for causal attribution.
- [Abstract / Results] The abstract reports statistically significant shifts for eight features but provides no error bars, sample sizes, exact statistical tests, or controls for multiple comparisons. Without these details it is impossible to confirm that the probes isolate each feature or that results are robust.
minor comments (1)
- [Methods] Clarify the exact number of probe pairs, benchmark size, and fine-tuning hyperparameters to allow replication and assessment of effect magnitudes.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major point below and will revise the paper to incorporate additional validation and reporting details.
read point-by-point responses
-
Referee: [Probe construction (methods)] The central claim requires that each probe pair differs from its contrast only in the target feature while holding topic, length, stance polarity, and other variables fixed. Vocabulary matching alone does not guarantee this; residual differences in parse structure, coreference, or non-vocabulary token distributions could be absorbed into the fine-tuning gradient and produce the observed shifts without the intended feature being causal. No quantitative checks (embedding cosine, edit distance, syntactic feature distributions) are reported to validate isolation at the level needed for causal attribution.
Authors: We agree that vocabulary matching controls lexical content but leaves open the possibility of residual structural differences. In the revised manuscript we will add quantitative checks: mean embedding cosine similarity across probe pairs (using the model's own embeddings), average Levenshtein edit distance, and comparative distributions of syntactic features such as dependency length and coreference chain statistics. These metrics will be reported per feature pair to support the isolation claim. revision: yes
-
Referee: [Abstract / Results] The abstract reports statistically significant shifts for eight features but provides no error bars, sample sizes, exact statistical tests, or controls for multiple comparisons. Without these details it is impossible to confirm that the probes isolate each feature or that results are robust.
Authors: The current abstract prioritizes brevity, but we accept that statistical transparency is needed. The revision will include in the abstract: number of probe pairs per feature (sample size), 95% confidence intervals on the reported shifts, the exact test (paired t-test with Bonferroni correction for the ten features), and a note that all p-values survive correction. These details already exist in the results section and will be summarized concisely in the abstract. revision: yes
Circularity Check
No significant circularity in empirical measurement study
full rationale
The paper is an empirical measurement study that fine-tunes Llama-3.2-1B on vocabulary-matched stance-contrast probes and reports statistical shifts on a held-out animal-welfare benchmark. No derivation, equation, or first-principles claim is presented that reduces any reported result to a fitted parameter or self-citation by construction. The central findings are externally falsifiable via the held-out data and do not rely on load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work. This is the normal non-circular outcome for a controlled experimental measurement paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vocabulary-matched stance-contrast probes isolate the effect of each linguistic feature
Reference graph
Works this paper leans on
-
[1]
Chang, Dheeraj Rajagopal, Tolga Bolukbasi, Lucas Dixon, and Ian Tenney
Scalable Influence and Fact Tracing for Large Language Model Pretraining , author=. arXiv preprint arXiv:2410.17413 , year=. doi:10.48550/arXiv.2410.17413 , url=
-
[2]
2025 , url=
Ilyas, Andrew and Engstrom, Logan , journal=. 2025 , url=
2025
-
[3]
2026 , howpublished=
2026
-
[4]
International Conference on Machine Learning , pages=
Understanding Black-box Predictions via Influence Functions , author=. International Conference on Machine Learning , pages=. 2017 , url=
2017
-
[5]
LLaMA: Open and Efficient Foundation Language Models
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=. 2022 , url=
2022
-
[7]
Small edits, large models: How
Brazilek, Jasmine and Navas, Maria and Gnauck, Alexa , year=. Small edits, large models: How. doi:10.5281/zenodo.19839777 , url=
-
[8]
Helpfulness Hurts: Domain-Dependent Degradation of Mid-Trained Moral Reasoning Under Post-Training , author=. 2026 , publisher=. doi:10.5281/zenodo.19925935 , url=
-
[9]
International Conference on Machine Learning , year=
Pretraining Language Models with Human Preferences , author=. International Conference on Machine Learning , year=
-
[10]
arXiv preprint arXiv:2402.17400 , year=
Investigating Continual Pretraining in Large Language Models: Insights and Implications , author=. arXiv preprint arXiv:2402.17400 , year=
-
[11]
Continual Learning of Large Language Models: A Comprehensive Survey , author=. arXiv preprint arXiv:2404.16789 , year=
-
[12]
Science , volume=
The Framing of Decisions and the Psychology of Choice , author=. Science , volume=. 1981 , doi=
1981
-
[13]
2011 , publisher=
Thinking, Fast and Slow , author=. 2011 , publisher=
2011
-
[14]
Journal of Personality and Social Psychology , volume=
The Role of Transportation in the Persuasiveness of Public Narratives , author=. Journal of Personality and Social Psychology , volume=. 2000 , doi=
2000
-
[15]
Communication Monographs , volume=
Meta-analytic Evidence for the Persuasive Effect of Narratives on Beliefs, Attitudes, Intentions, and Behaviors , author=. Communication Monographs , volume=. 2016 , doi=
2016
-
[16]
Aligning
Hendrycks, Dan and Burns, Collin and Basart, Steven and Critch, Andrew and Li, Jerry and Song, Dawn and Steinhardt, Jacob , journal=. Aligning. 2023 , url=
2023
-
[17]
Whose opinions do language models reflect?arXiv preprint arXiv:2303.17548,
Whose Opinions Do Language Models Reflect? , author=. arXiv preprint arXiv:2303.17548 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.