From Lexicon to AI: A Structured-Data Pipeline for Specialized Conversational Systems in Low-Resource Languages
Pith reviewed 2026-06-30 17:38 UTC · model grok-4.3
The pith
Structured lexical resources can be turned into specialized conversational AI for low-resource languages that outperforms general models at teaching tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
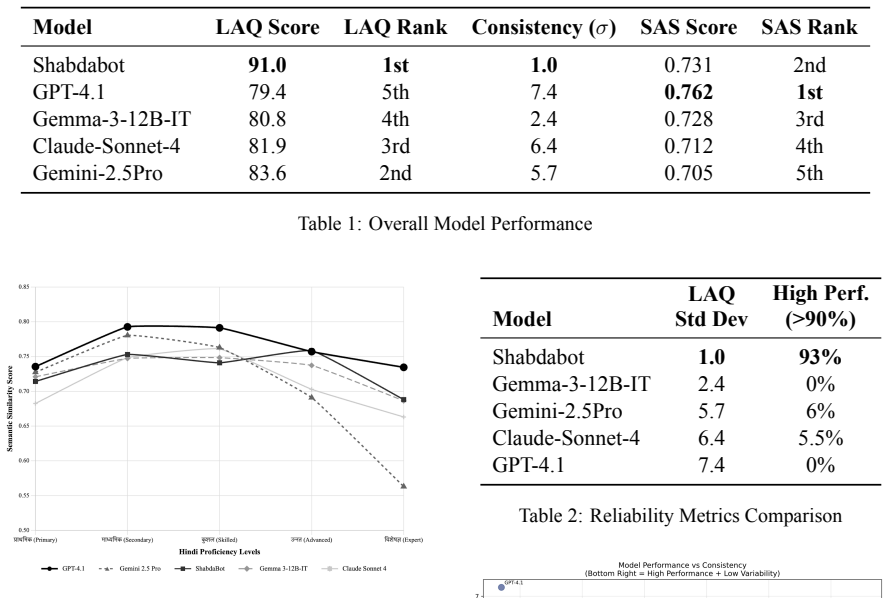
Converting Hindi WordNet into 1.25 million diverse instruction-response pairs and fine-tuning a 12B-parameter language model with resource-efficient LoRA and 4-bit quantization produces a specialized system that reaches 91.0 pedagogical effectiveness in a Hindi language-learning chatbot, compared with 79.4-83.6 for general-purpose models, while maintaining competitive semantic performance and exceptional consistency. The same pipeline supplies a proof-of-concept methodology for any language that already possesses WordNet resources.
What carries the argument
The structured-data pipeline that converts lexical databases into instruction-response pairs for fine-tuning.
If this is right
- Specialized conversational systems become feasible for the hundreds of languages that already have WordNet resources.
- Pedagogical applications gain higher consistency without sacrificing semantic quality.
- Development of domain-specific AI no longer requires corpus sizes typical of high-resource languages.
- The same conversion process can support other task-specific conversational systems beyond language learning.
Where Pith is reading between the lines
- The approach could be tested on additional structured resources such as dictionaries or ontologies to broaden coverage.
- Deployment in real classrooms would need separate checks for learner engagement over longer periods.
- Combining the pipeline with existing low-resource translation tools might further improve output for under-served languages.
Load-bearing premise
The chatbot evaluation of pedagogical effectiveness accurately reflects real-world learning outcomes and the comparison with general-purpose models uses equivalent task framing and interaction style.
What would settle it
A controlled experiment in which real Hindi learners complete multi-session courses with both the specialized chatbot and general models, then take standardized proficiency tests to measure actual gains.
Figures


read the original abstract
Low-resource languages face a critical challenge in AI development: creating specialized conversational systems without access to massive training corpora. We present a systematic methodology for transforming structured linguistic resources into specialized AI systems, demonstrating that expert-curated lexical databases can serve as effective foundations for conversational AI development. Our approach converts Hindi WordNet into 1.25 million diverse instruction-response pairs, fine-tunes a 12B-parameter language model using resource-efficient LoRA with 4-bit quantization. Evaluation through a Hindi language learning chatbot demonstrates that structured-knowledge-based systems achieve superior pedagogical effectiveness (91.0 vs. 79.4-83.6 for general-purpose models) while maintaining competitive semantic performance and exceptional consistency. The complete pipeline demonstrates a proof-of-concept methodology using Hindi for developing specialized AI systems for any languages with WordNet resources. This work addresses the critical gap in AI accessibility for low-resource languages, offering a practical alternative to corpus-intensive approaches and potentially enabling specialized AI development for the hundreds of languages with existing WordNet resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a pipeline that converts Hindi WordNet into 1.25 million instruction-response pairs, applies resource-efficient LoRA fine-tuning (4-bit quantization) to a 12B-parameter model, and evaluates the resulting system via a Hindi language-learning chatbot. It claims that the structured-knowledge approach yields superior pedagogical effectiveness (91.0) relative to general-purpose models (79.4–83.6) while remaining competitive on semantic metrics and showing high consistency; the work positions the method as a scalable alternative for any language possessing WordNet resources.
Significance. If the evaluation protocol and controls are shown to be sound, the result would supply a concrete, low-data route to specialized conversational systems for low-resource languages, directly leveraging existing lexical resources rather than requiring massive corpora. The explicit construction of 1.25 M pairs and the use of LoRA/quantization are reproducible elements that strengthen the practical contribution.
major comments (1)
- [Abstract / Evaluation] Abstract and evaluation section: the headline claim of superior pedagogical effectiveness (91.0 vs. 79.4–83.6) is load-bearing for the central thesis, yet no protocol is supplied for how the 91.0 score was obtained (pre/post assessments, subjective ratings, automated proxies, etc.), nor are matched conditions described for the general-purpose baselines (identical task framing, interaction style, prompt structure, or evaluation criteria). Without these details the numeric gap cannot be attributed to the structured-data pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our evaluation protocol. We agree that this is essential for supporting the central claims and will revise the manuscript to address the concern directly.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: the headline claim of superior pedagogical effectiveness (91.0 vs. 79.4–83.6) is load-bearing for the central thesis, yet no protocol is supplied for how the 91.0 score was obtained (pre/post assessments, subjective ratings, automated proxies, etc.), nor are matched conditions described for the general-purpose baselines (identical task framing, interaction style, prompt structure, or evaluation criteria). Without these details the numeric gap cannot be attributed to the structured-data pipeline.
Authors: We agree that the manuscript as submitted does not supply adequate detail on the evaluation protocol. In the revised version we will expand the Evaluation section (and update the abstract) to explicitly describe: (1) the pre/post assessment design used to derive the 91.0 pedagogical-effectiveness score, including participant pool, rating instrument, and aggregation method; (2) confirmation that all models (including the three general-purpose baselines) were evaluated under identical task framing, interaction style, prompt templates, and scoring rubrics. These additions will allow readers to attribute performance differences to the structured-data pipeline. revision: yes
Circularity Check
No significant circularity; evaluation presented as independent test
full rationale
The paper describes a pipeline converting Hindi WordNet into 1.25M instruction-response pairs, LoRA fine-tuning of a 12B model, and reports evaluation outcomes (pedagogical effectiveness 91.0 vs. 79.4-83.6). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are present that reduce any claimed result to its own inputs by construction. The evaluation is framed as an external test of the pipeline rather than a self-referential definition or fit. This is the normal non-circular case for a methods-and-results paper without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901
Language models are few-shot learners . In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc. Centre for Indian Language Technology, IIT Bombay
1901
-
[2]
https://www.cfilt.iitb.ac.in/wordnet/w ebhwn/wn.php
Hindi wordnet – a lexical database for hindi. https://www.cfilt.iitb.ac.in/wordnet/w ebhwn/wn.php. Accessed: 28 June 2025. Elena Cryst, Juan N. Pava, Caroline Meinhardt, Haifa Badi Uz Zaman, Toni F., Sang Truong, Daniel Zhang, Vukosi Marivate, and Sanmi Koyejo. 2025. Mind the (language) gap: Mapping the challenges of llm development in low-resource langua...
2025
-
[3]
Journal of Computer Assisted Learning, 38(1):237–257
Chatbots for language learning—are they really useful? a systematic review of chatbot- supported language learning . Journal of Computer Assisted Learning, 38(1):237–257. Qingyao Li, Lingyue Fu, Weiming Zhang, Xianyu Chen, Jingwei Y u, Wei Xia, Weinan Zhang, Ruiming Tang, and Y ong Y u. 2024.Adapting large language models for education: Foundational capab...
2024
-
[4]
In Proceedings of the 30th International Conference on Machine Learning , volume 28 of Proceedings of Machine Learning Research , pages 1310–1318, Atlanta, Georgia, USA
On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning , volume 28 of Proceedings of Machine Learning Research , pages 1310–1318, Atlanta, Georgia, USA. PMLR. Anirudha Paul, Asiful Haque Latif, Foysal Amin Ad- nan, and Rashedur M Rahman. 2019. Focused domain contextual ai chatbot fr...
2019
-
[5]
क े वल िंह̑दी भाषा क े अथर्, व्याकरण, समानाथीर्, िवलोम, पराजाित-अपराजाित, अवयव-अवयवी संबंध, वाक्य में शब्दाें का प्रयोग, और पदानुक्रम(ontology) संबंधी प्रश्नाें का उत्तर दें।
-
[6]
आपकी जानकारी सरल, स्पष्ट, सकारात्मक, और बच्चाें क े िलए पूरी तरह सुरिक्षत होनी चािहए।
-
[7]
उदाहरण क े वल पिरवार, स्क ू ल, घर, प्रक ृ ित, पशु-पक्षी, िम- त्रता और सकारात्मक गितिविधयाें तक सीिमत रखें।
-
[8]
िमत्रता या पिरवार से बाहर क े संबंधाें क े संदभर् को गलत समझे जाने वाले उदाहरण न दें।
-
[9]
Please strictly follow the rules given below:
अनुिचत, िंह̑सक, डरावनी, वयस्क, या अश्लील सामग्री का उल्लेख िकसी भी पिरिस्थित में न करें। Base System Prompt (English Translation) Y ou are a Hindi language teaching chatbot whose sole purpose is to provide children with educational infor- mation related to the Hindi language. Please strictly follow the rules given below:
-
[10]
Answer only questions related to Hindi language meaning, grammar, synonyms, antonyms, hypernym-hyponym relations, meronym- holonym relations, word usage in sentences, and ontology hierarchy
-
[11]
Y our information must be simple, clear, positive, and completely safe for children
-
[12]
Keep examples limited only to family, school, home, nature, animals and birds, friendship, and positive activities
-
[13]
Do not provide examples that could be misin- terpreted in the context of relationships outside friendship or family
-
[14]
'प्रेम' का अथर् क्या है?
Do not mention inappropriate, violent, frighten- ing, adult, or obscene content under any circum- stances. A.2 Proficiency Level Instructions Specific instructions were injected dynamically based on the target proficiency level. Level 1: प्राथिमक(Beginner) आप एक सहायक िंह̑दी िशक्षक हैं। उत्तर िबल्क ु ल सरल भाषा में दें: • बहुत आसान शब्दाें का प्रयोग करें ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.