LCG: Long-Context Consistent Image Generation with Sparse Relational Attention
Pith reviewed 2026-06-26 01:10 UTC · model grok-4.3
The pith
Long-context image generation maintains character consistency using sparse relational attention and routing constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
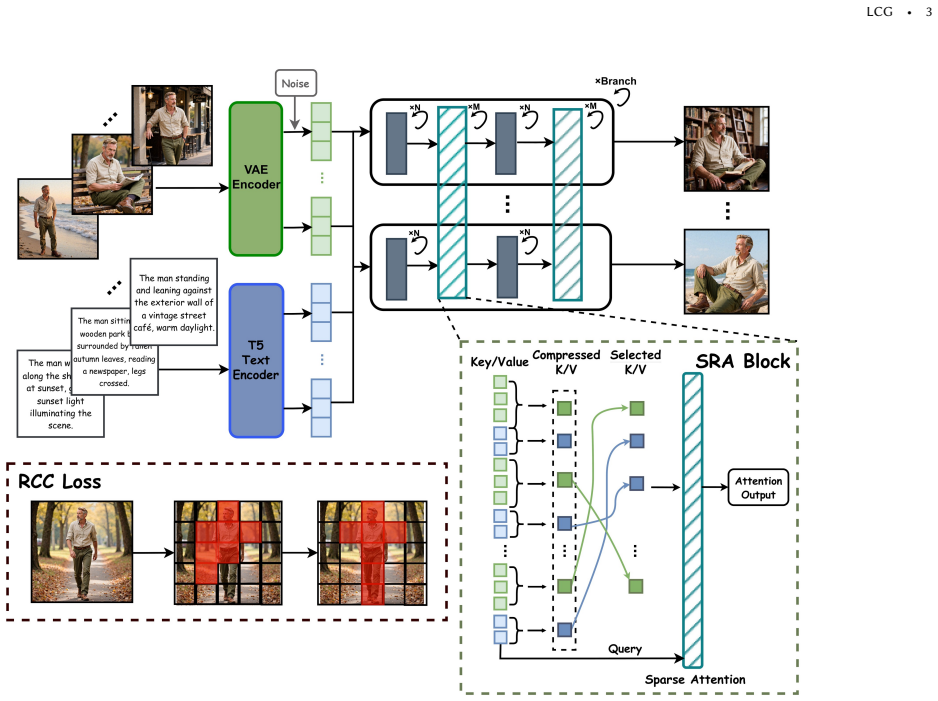
LCG achieves consistent long-context multi-image text-to-image generation by employing Sparse Relational Attention to selectively attend to core features across extended contexts and the Routing Consistency Constraint to align structural patterns using identity-aware masks, outperforming baselines in prompt alignment and character consistency on the LCCD dataset.
What carries the argument
Sparse Relational Attention (SRA), which selectively attends to core features across extended visual contexts to ensure tractable propagation of semantic and layout information.
If this is right
- Supports generation of comics, storyboards, and visual narratives with maintained consistency.
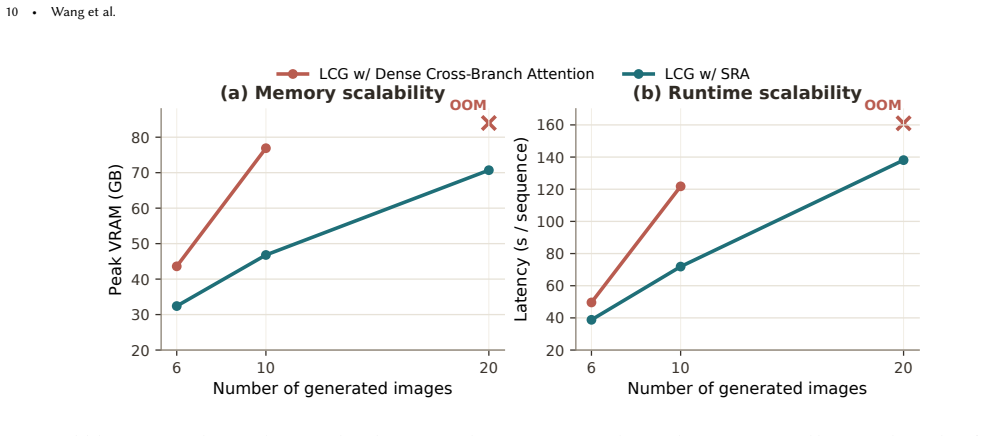
- Scales to sequences of 6 to 20 images without computational explosion.
- Improves handling of complex multi-character scenes.
- Provides a large synthetic dataset for further research in consistent image sequences.
Where Pith is reading between the lines
- The method could be adapted for generating consistent video frames from text descriptions.
- Real-world testing on human-drawn story sequences would be needed to confirm generalization beyond synthetic data.
- Combining this with other diffusion model improvements might enable interactive story creation tools.
Load-bearing premise
The synthetic Long-Context Consistency Dataset and identity-aware masks capture the distribution of real-world multi-image consistency challenges without introducing new artifacts.
What would settle it
Evaluating LCG on a collection of real human-created comic or storyboard sequences and measuring if consistency holds compared to baselines would test the claim.
Figures










read the original abstract
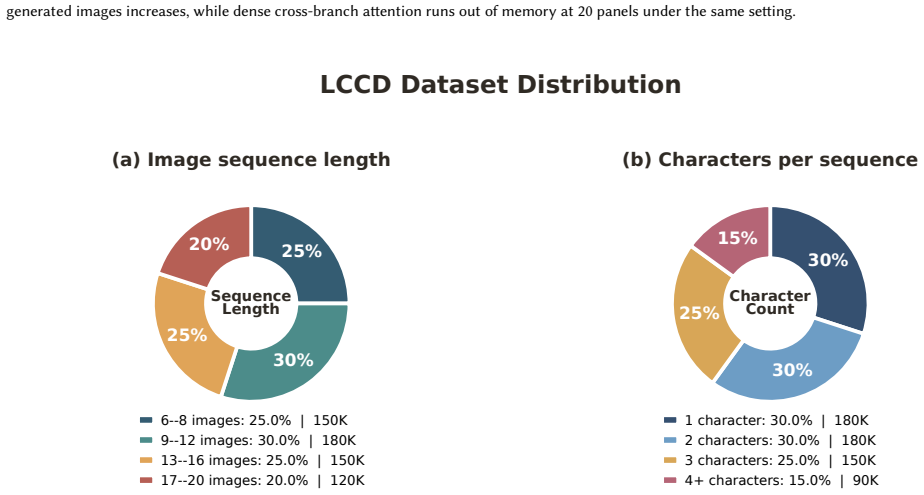
Recent image generation models achieve impressive quality in single-image synthesis, but often fail to maintain consistency across sequential outputs, as required in comics, storyboards, and visual narratives. We propose Long-Context Generation (LCG), a framework for long-context multi-image text-to-image generation, to improve consistency and scalability in long-context multi-image generation. LCG employs the Sparse Relational Attention (SRA) mechanism to selectively attend to core features across extended visual contexts, ensuring that the propagation of semantic and layout information remains computationally tractable. To enforce semantic alignment, we introduce the Routing Consistency Constraint (RCC), which leverages identity-aware masks to align structural patterns across generation branches, effectively mitigating drift in appearance even in complex multi-character scenes. To support training and evaluation in this setting, we construct the Long-Context Consistency Dataset (LCCD), a large-scale synthetic dataset comprising character-centric multi-image sequences spanning varied situational contexts. LCCD contains 600K training sequences and a separate 1K test set, with each sequence containing 6 to 20 images. The experiments demonstrate that LCG outperforms the compared baselines in prompt alignment and character consistency for long-context image generation, including multi-character scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Long-Context Generation (LCG), a framework for consistent multi-image text-to-image synthesis over long sequences. It introduces Sparse Relational Attention (SRA) to handle extended visual contexts tractably and the Routing Consistency Constraint (RCC) that uses identity-aware masks to reduce appearance drift. A synthetic Long-Context Consistency Dataset (LCCD) with 600K training sequences (6-20 images each) and a 1K test split is constructed to train and evaluate the method. The central claim is that LCG outperforms baselines on prompt alignment and character consistency, including in multi-character scenes.
Significance. If the quantitative gains hold under broader evaluation, the work would address a practically important limitation of current diffusion models for narrative applications such as comics and storyboards. The construction of a large-scale character-centric dataset is a concrete contribution that could support future research even if the proposed mechanisms require refinement.
major comments (2)
- [Experiments] Experiments section (and abstract): all reported quantitative results are confined to the held-out 1K test split of the synthetic LCCD; no cross-evaluation on external real-world comic, storyboard, or multi-image narrative datasets is described. Because the RCC relies on identity-aware masks derived from the same synthetic construction, this leaves the generalization claim load-bearing and untested.
- [§3.2] §3.2 (Routing Consistency Constraint): the description of how identity-aware masks are generated and how the alignment loss is formulated is not accompanied by an ablation that isolates the contribution of RCC versus SRA alone, making it impossible to determine whether the reported consistency improvements are attributable to the proposed constraint or to other training choices.
minor comments (2)
- [Abstract] The abstract states that experiments demonstrate outperformance but supplies no numerical metrics, baseline names, or statistical details; these should be added to the abstract or a results table for immediate readability.
- [§3.1] Notation for the sparse attention mask in SRA is introduced without an explicit equation reference; adding a numbered equation would improve clarity when the mechanism is first described.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify limitations in our current experimental scope and the need for component ablations. We respond to each major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): all reported quantitative results are confined to the held-out 1K test split of the synthetic LCCD; no cross-evaluation on external real-world comic, storyboard, or multi-image narrative datasets is described. Because the RCC relies on identity-aware masks derived from the same synthetic construction, this leaves the generalization claim load-bearing and untested.
Authors: We agree that the absence of evaluation on external real-world datasets leaves the generalization claim untested. The LCCD was constructed specifically to enable controlled, large-scale study of long-sequence consistency challenges that are difficult to annotate at scale in real data. We will revise the manuscript to (1) explicitly qualify the scope of our claims to the synthetic setting and (2) add a dedicated limitations paragraph discussing the challenges and potential avenues for real-world transfer. We do not plan to add new cross-dataset experiments in this revision, as they would require substantial new data collection and annotation effort beyond the current work. revision: partial
-
Referee: [§3.2] §3.2 (Routing Consistency Constraint): the description of how identity-aware masks are generated and how the alignment loss is formulated is not accompanied by an ablation that isolates the contribution of RCC versus SRA alone, making it impossible to determine whether the reported consistency improvements are attributable to the proposed constraint or to other training choices.
Authors: We accept this criticism. The revised manuscript will include a new ablation table that trains and evaluates (a) SRA alone and (b) SRA + RCC under identical training settings. This will isolate the incremental effect of the Routing Consistency Constraint on the reported metrics. revision: yes
Circularity Check
No significant circularity; empirical claims rest on held-out synthetic test split without self-referential reduction
full rationale
The provided abstract and description contain no equations, derivations, or first-principles claims that reduce to inputs by construction. LCG is presented as a framework with SRA and RCC mechanisms whose performance is evaluated empirically on a held-out 1K test split of the separately constructed LCCD (600K training sequences). This is standard train/test separation on synthetic data and does not equate the reported outperformance to a fitted parameter or self-definition. No self-citation chains, uniqueness theorems, or ansatzes are invoked in the visible text. The central claims remain independent of the evaluation protocol itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1931–1941. Yaowei Li, Xiaoyu Li, Zhaoyang Zhang, Yuxuan Bian, Gan Liu, Xinyuan Li, Jiale Xu, Wenbo Hu, Yating Liu, Lingen Li, Jing Cai, Yuexian Zou, Yancheng He, and Ying Shan. 2025. IC-Custom: Diverse Image Customiz...
arXiv 1931
-
[2]
Photomaker: Customizing realistic human photos via stacked id embedding. arXiv preprint(2023). Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. 2024. Evaluating text-to-visual generation with image- to-text generation. InEuropean Conference on Computer Vision. Springer, 366–384. Chang Liu, Haoning...
arXiv 2023
-
[3]
High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695. Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation. InProceedi...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.