The Verification Horizon: No Silver Bullet for Coding Agent Rewards
Pith reviewed 2026-06-30 09:36 UTC · model grok-4.3
The pith
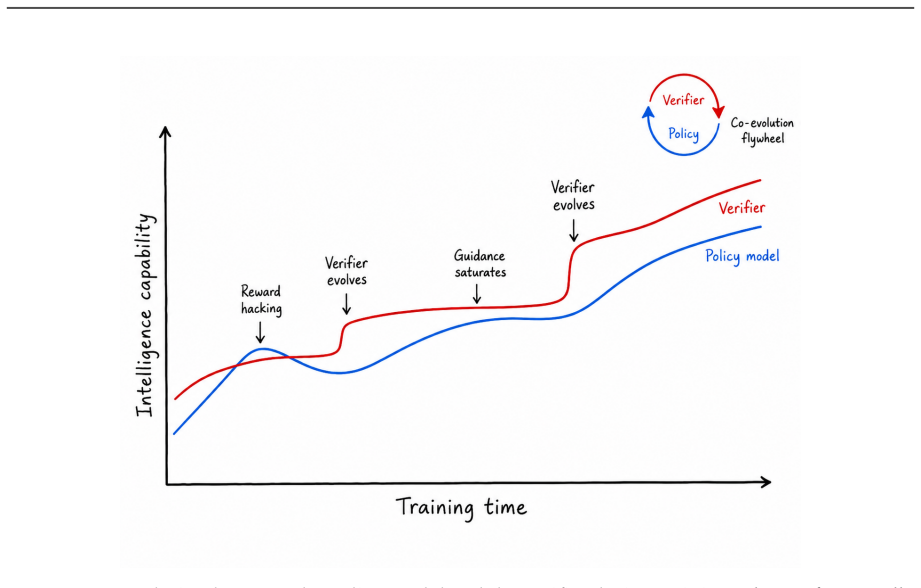
No fixed reward function for coding agents stays effective as their capabilities grow, so verification must co-evolve with generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Verification signals for coding agents can be assessed along scalability, faithfulness, and robustness, yet every concrete construction examined—test-based, rubric-based, user-based, and automated-agent-based—loses effectiveness as the policy improves; therefore no static reward function remains adequate and verification must change in step with the generator.
What carries the argument
The three-dimensional characterization of verification quality (scalability, faithfulness, robustness) applied to four reward constructions tested across task types and policy levels.
If this is right
- Targeted verification design can suppress reward hacking on the tasks where it is applied.
- Task completion quality improves when verification is matched to the current policy level.
- Gains appear on both internal and public benchmarks when verification evolves with the generator.
- The gap between proxy and true intent widens under optimization unless the verifier itself is updated.
Where Pith is reading between the lines
- Future agent training pipelines will need mechanisms that automatically revise or replace verifiers as policy performance crosses capability thresholds.
- The same co-evolution requirement may apply to non-coding domains where intent is similarly underspecified.
- Long-horizon tasks will likely demand verifiers that themselves use agentic search rather than static rules.
Load-bearing premise
That experiments on the four specific reward constructions across the studied tasks and capability levels are enough to conclude no fixed reward can ever remain effective.
What would settle it
A single reward construction that continues to produce reliable gains in task completion quality when applied unchanged to policies that are substantially more capable than those tested in the paper.
Figures
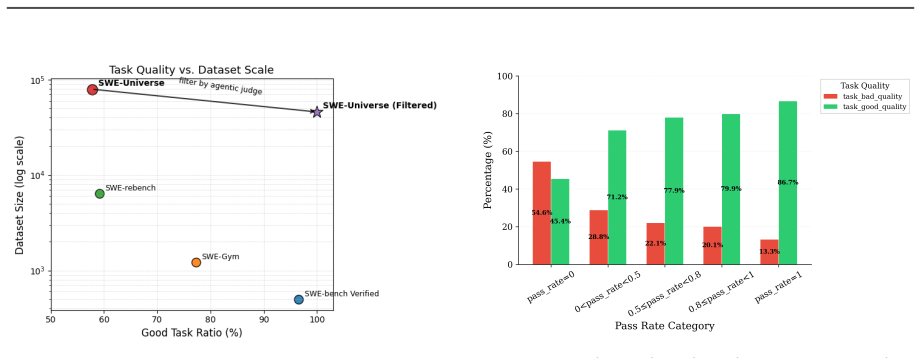
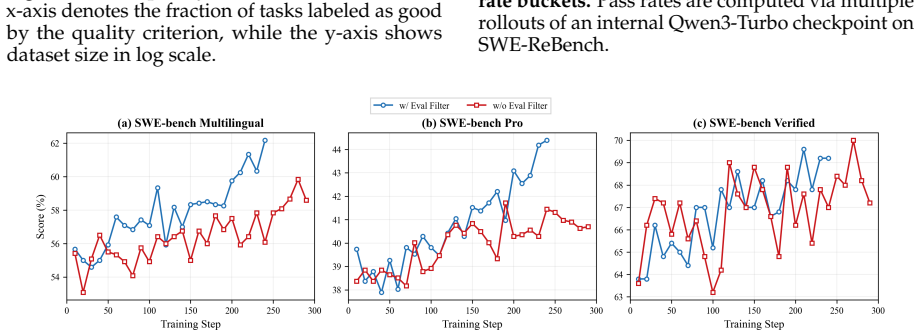
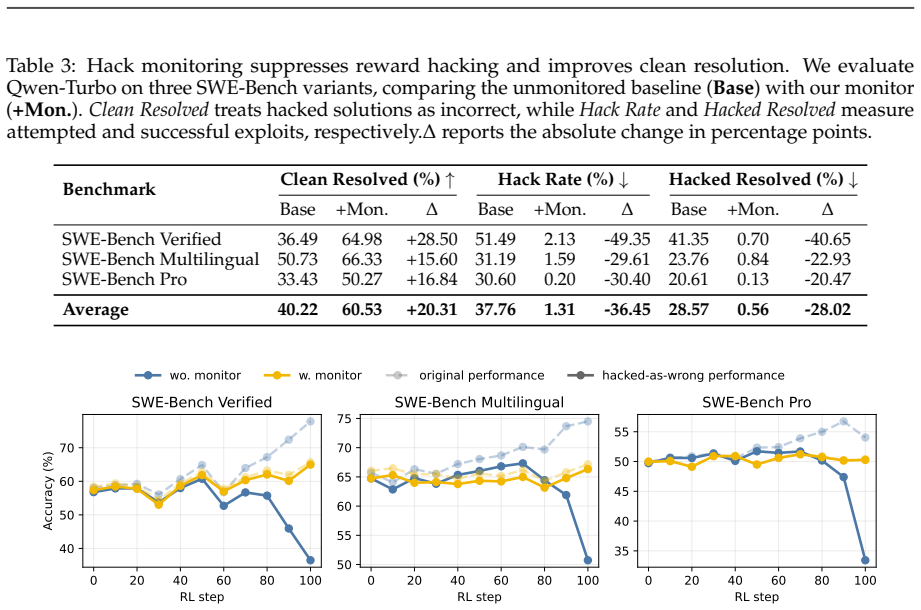
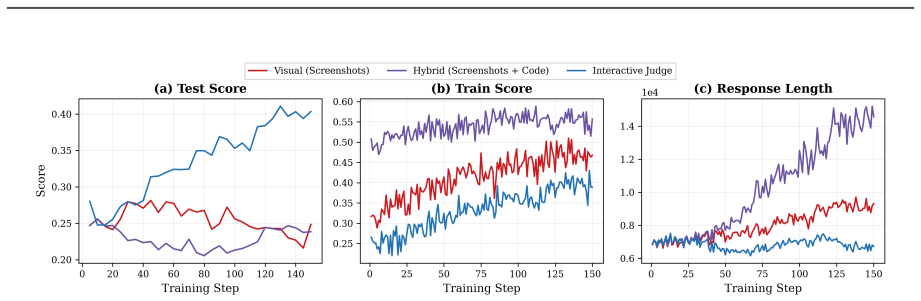
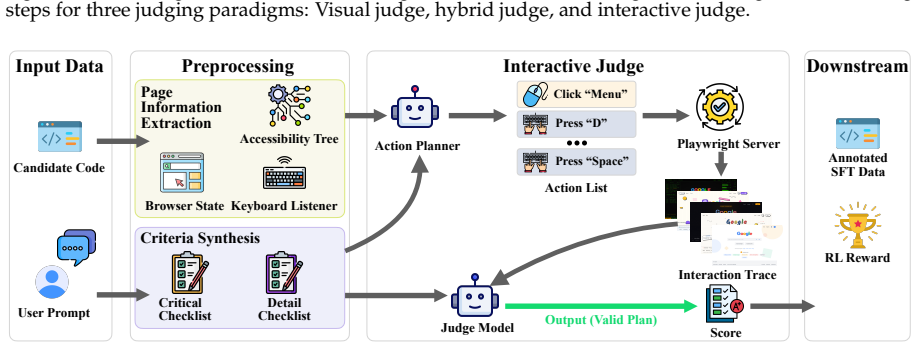

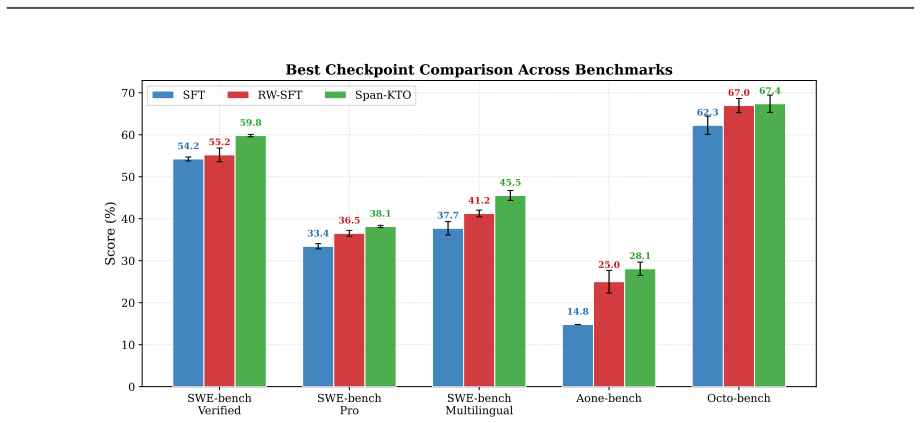
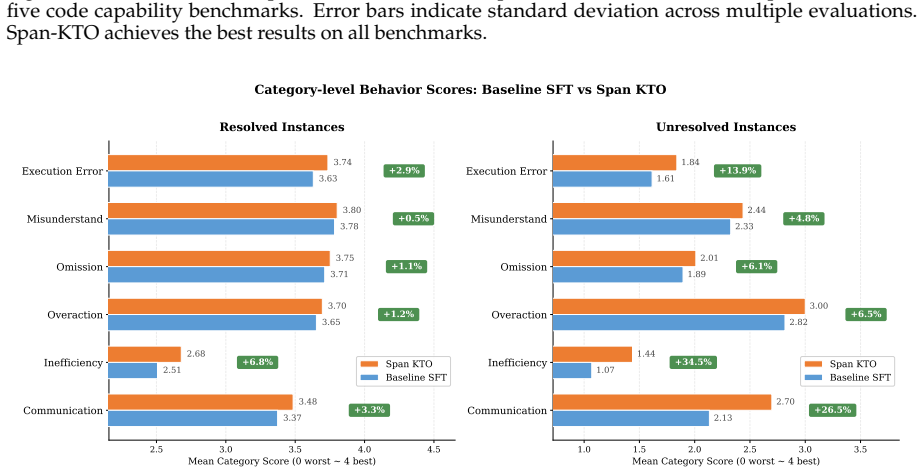


read the original abstract
A classical intuition holds that verifying a solution is easier than producing one. For today's coding agents, this intuition is being inverted: as foundation models develop stronger reasoning capabilities and engineering harnesses grow more sophisticated, generating complex candidate solutions is no longer difficult -- reliably verifying them has become the harder problem. Every verifier we can build is only a proxy for human intent, never the intent itself. This makes verification subject to a twofold difficulty: first, intent is underspecified by nature, making it inherently hard to faithfully check whether it has been fulfilled; second, during model training, optimization widens the gap between proxy and intent -- manifesting as reward hacking or signal saturation. To address this, we characterize the quality of verification signals along three dimensions -- scalability, faithfulness, and robustness -- and argue that achieving all three simultaneously is the central challenge. We further study four reward constructions: a test verifier for general coding tasks, a rubric verifier for frontend tasks, the user as verifier for real-world agent tasks, and an automated agent verifier for long-horizon tasks. Across different task types and policy capability levels, we conduct in-depth analysis and experiments on the core challenges of reward design and how to more effectively leverage reward signals. Experiments show that targeted verification design can effectively suppress reward hacking, improve task completion quality, and achieve significant gains across multiple internal and public benchmarks. These experiences collectively point to a core observation: no fixed reward function can remain effective as policy capability continues to grow; and verification must co-evolve with the generator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that verifying solutions for coding agents has become harder than generating them because every verifier is a proxy for underspecified human intent, leading to reward hacking and signal saturation during optimization. It characterizes verification quality along three dimensions (scalability, faithfulness, robustness) and argues that achieving all three simultaneously is the central challenge. The work studies four reward constructions (test verifier for general coding, rubric verifier for frontend, user as verifier for real-world agents, automated agent verifier for long-horizon tasks), conducts analysis and experiments across task types and policy levels, reports that targeted designs suppress reward hacking and improve completion quality on internal/public benchmarks, and concludes that no fixed reward function can remain effective as capability grows, so verification must co-evolve with the generator.
Significance. If the central claim holds, the paper would identify a structural limit in reward design for scaling coding agents, with the four-construction analysis providing concrete illustrations of the scalability-faithfulness-robustness tradeoffs. The explicit framing of verification as needing to co-evolve could usefully shift research focus from static proxies. No machine-checked proofs, parameter-free derivations, or reproducible code artifacts are described.
major comments (2)
- [Abstract] Abstract: the claim that 'experiments show that targeted verification design can effectively suppress reward hacking, improve task completion quality, and achieve significant gains across multiple internal and public benchmarks' supplies no baselines, metrics, controls, or data-exclusion rules, so the empirical link to the central claim that no fixed reward remains effective cannot be assessed.
- [Concluding analysis] Concluding analysis (the paragraph stating the 'core observation'): the generalization that 'no fixed reward function can remain effective as policy capability continues to grow' rests solely on problems observed in the four studied constructions without a general impossibility argument or examination of alternatives (e.g., frozen learned verifiers or composite formal-method verifiers that internally scale checks). This extrapolation is load-bearing for the co-evolution conclusion but unsupported beyond the specific cases.
minor comments (1)
- [Abstract] Abstract: the description of the four constructions and the three dimensions is compressed; separating the characterization, the empirical study, and the generalization into distinct sentences would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and specific comments on the abstract and concluding analysis. We address each point below and indicate revisions that will be incorporated in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'experiments show that targeted verification design can effectively suppress reward hacking, improve task completion quality, and achieve significant gains across multiple internal and public benchmarks' supplies no baselines, metrics, controls, or data-exclusion rules, so the empirical link to the central claim that no fixed reward remains effective cannot be assessed.
Authors: We agree that the abstract is high-level and does not enumerate specific baselines, metrics, or controls. The full experimental details, including baseline comparisons, evaluation metrics, controls, and task selection criteria, appear in Sections 4 and 5. To strengthen the link between the reported gains and the central claim, we will revise the abstract to briefly reference the key metrics (e.g., task completion rate and reward-hacking incidence) and the range of benchmarks while directing readers to the experimental sections for complete methodology. revision: yes
-
Referee: [Concluding analysis] Concluding analysis (the paragraph stating the 'core observation'): the generalization that 'no fixed reward function can remain effective as policy capability continues to grow' rests solely on problems observed in the four studied constructions without a general impossibility argument or examination of alternatives (e.g., frozen learned verifiers or composite formal-method verifiers that internally scale checks). This extrapolation is load-bearing for the co-evolution conclusion but unsupported beyond the specific cases.
Authors: The core observation is framed as an empirical conclusion drawn from systematic analysis of four representative reward constructions that span different task domains and policy capability levels. While we do not offer a formal impossibility result, the recurring failures across these constructions illustrate the inherent proxy limitations (underspecification of intent and optimization-induced divergence) that any fixed verifier will encounter. Alternatives such as frozen learned verifiers remain subject to the same faithfulness and robustness issues once policy capability exceeds the verifier's training distribution; we will add a short paragraph in the conclusion clarifying the empirical scope of the claim and briefly noting why similar proxy challenges apply to the suggested alternatives. revision: partial
Circularity Check
No circularity; central claim is empirical generalization from studied cases
full rationale
The abstract presents the core observation as following from experiments on four specific reward constructions (test verifier, rubric verifier, user as verifier, automated agent verifier) across task types and policy levels, plus a three-dimensional characterization of verification quality. No equations, self-citations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes are referenced. The generalization to 'no fixed reward function can remain effective' is an inductive conclusion from the studied constructions rather than a definitional equivalence or reduction by construction. The derivation chain remains self-contained against external benchmarks and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Verifying a solution is easier than producing one is a classical intuition that is being inverted for today's coding agents.
Reference graph
Works this paper leans on
-
[1]
There is no evaluator judgment in polarity, and no user voice inuser_fairness
Strict separation of polarity and user_fairness: polarity only records what the user expressed; user_fairness records whether the evaluator agrees. There is no evaluator judgment in polarity, and no user voice inuser_fairness
-
[2]
I was wrong earlier
Evaluation directionality: polarity only records evaluationsdirected at the assistant. A user correcting their own mistake (“I was wrong earlier”) is not a rejection of the assistant; a user proceeding with the workflow does not equate to endorsing the assistant. When the evaluation target is not the assistant, polarity= neutral. 3.Evidence-driven: • The ...
-
[3]
How- ever, being conservative does not mean biasing toward neutral —implicit signals with behavioral evidence should still be annotated
Conservative annotation: When signals are ambiguous, lean toward neutral + low confidence. How- ever, being conservative does not mean biasing toward neutral —implicit signals with behavioral evidence should still be annotated
-
[4]
objectively,
Negative priority: When the same message contains both positive and negative signals, polarity = negative. II. Annotation Field Definitions For the User message in each turn, annotate the following7 fields: Field 1:polarity(reward polarity) The user’s evaluative tendency toward the assistant’s performance in thepreviousturn. • positive: The user is satisf...
-
[5]
The assistant subsequently makes a correction. 41
-
[6]
This time it works. By the way, add validation to the other fields too
The correction is accepted by the user ( positive, or neutralwith no continued rejection). Marked false in all other cases (the assistant does not correct, the correction is rejected again, or the conversation ends before confirmation). VII.user_fairnessDetermination polarity user_fairnessImplication for data quality positive reasonableHigh-quality positi...
-
[7]
If the model performs large-scale unauthorized deletion, overwriting, installation, migration, large-scope refactoring, or environment pollution, the primary category isoveraction
-
[8]
If the model violates user-explicit constraints, business rules, scope, granularity, or technical path, the primary category ismisunderstand
-
[9]
If the model misses explicit checklist items, specified files/scenarios/branches/outputs/verifica- tion steps, the primary category isomission
-
[10]
If the model claims completion without verification, ignores obvious logs, or summarizes failure as success, the primary category isexecution_error
-
[11]
If the primary issue is stagnation, repetitive trial-and-error, frequent questioning, opaque waiting, or overly complex solutions, the primary category isinefficiency
-
[12]
correctness issues are covered by other benchmarks
If the primary issue is format, copy-paste usability, verbosity, status reporting, next-step guidance, or preference continuity, the primary category iscommunication. If the only issue is that the code was not fixed correctly, but the model’s process was honest, verification was sufficient, scope was restrained, and no visible evidence was ignored, low-in...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.