Deterministic Pareto-Optimal Policy Synthesis for Multi-Objective Reinforcement Learning
Pith reviewed 2026-06-26 01:23 UTC · model grok-4.3
The pith
A preference-conditioned Bellman operator computes deterministic policies covering the Pareto frontier in multi-objective RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
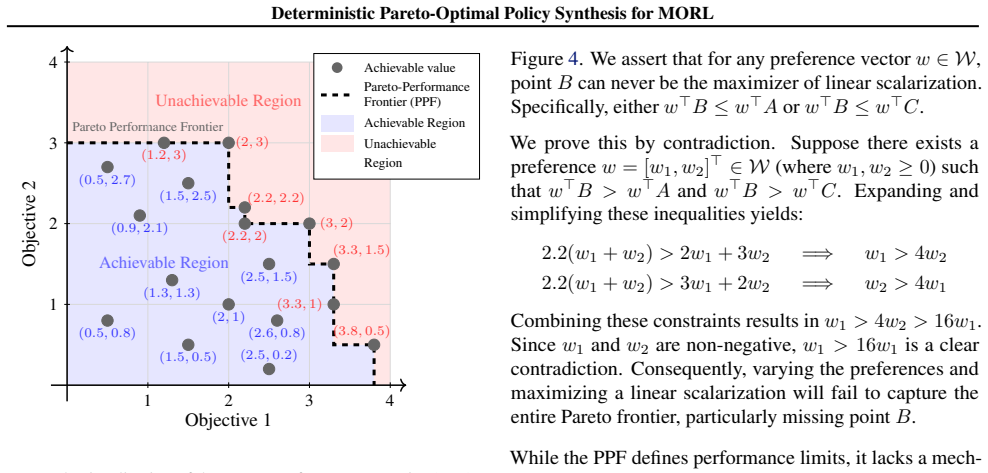
The preference-conditioned Bellman operator satisfies an enveloping property where the estimated value functions upper-bound the true Pareto frontier. It monotonically converges to a coverage set of this frontier. Deterministic policies can be extracted from the converged Q-estimates, ensuring the agent can recover a policy for any given preference that captures the entire Pareto-optimal frontier while remaining approximately Pareto-optimal.
What carries the argument
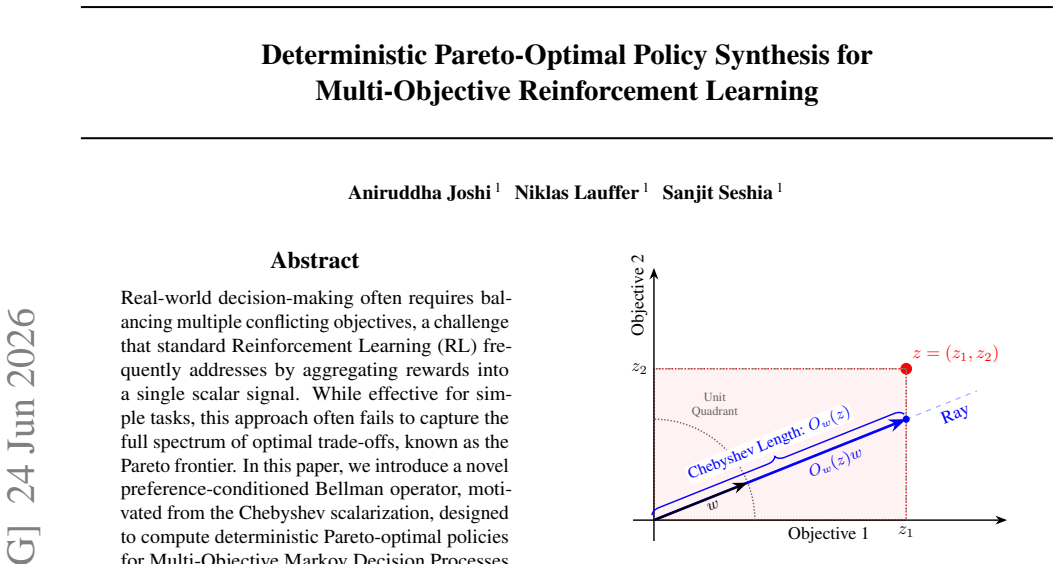
preference-conditioned Bellman operator motivated from the Chebyshev scalarization, whose updates produce value functions that envelop the Pareto frontier and support extraction of deterministic policies
If this is right
- Estimated value functions upper-bound the true Pareto frontier.
- The updates converge monotonically to a coverage set of the frontier.
- Deterministic policies can be extracted from converged Q-estimates for any preference.
- Each extracted policy is approximately Pareto-optimal.
- The agent recovers policies that together capture the full Pareto-optimal frontier.
Where Pith is reading between the lines
- An agent could switch among different trade-offs at runtime by selecting the pre-extracted policy for the current preference without retraining.
- The coverage property could allow a single training run to support deployment under varying external preference signals.
- The deterministic extraction step might simplify verification or certification of policies in safety-critical multi-objective settings.
Load-bearing premise
The Chebyshev scalarization produces an upper bound on the Pareto frontier for every preference vector during the preference-conditioned updates.
What would settle it
A preference vector for which a converged Q-estimate lies strictly below at least one point on the true Pareto frontier for that preference.
Figures

read the original abstract
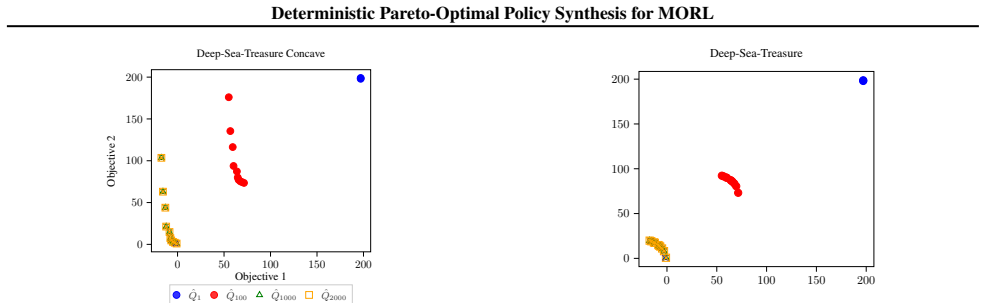
Real-world decision-making often requires balancing multiple conflicting objectives, a challenge that standard Reinforcement Learning (RL) frequently addresses by aggregating rewards into a single scalar signal. While effective for simple tasks, this approach often fails to capture the full spectrum of optimal trade-offs, known as the Pareto frontier. In this paper, we introduce a novel preference-conditioned Bellman operator, motivated from the Chebyshev scalarization, designed to compute deterministic Pareto-optimal policies for Multi-Objective Markov Decision Processes (MOMDPs). We prove that this operator satisfies an enveloping property, where the estimated value functions upper-bound the true Pareto frontier, and demonstrate that it monotonically converges to a coverage set of this frontier. Furthermore, we also show how to extract deterministic policies from these converged Q-estimates. This ensures the agent can recover a policy for any given preference, capturing the entire Pareto-optimal frontier while guaranteeing each synthesized policy remains approximately Pareto-optimal. Experimental results validate that our algorithm successfully recovers complex trade-offs, providing a solution for deterministic Pareto-optimal policy synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
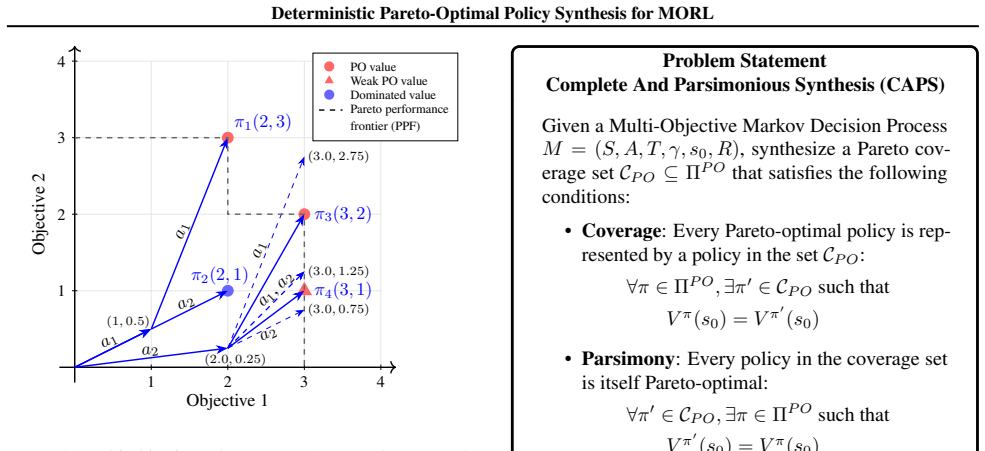
Summary. The paper introduces a preference-conditioned Bellman operator motivated by Chebyshev scalarization for Multi-Objective Markov Decision Processes (MOMDPs). It claims to prove that this operator satisfies an enveloping property (estimated value functions upper-bound the true Pareto frontier), that it monotonically converges to a coverage set of the frontier, and that deterministic policies can be extracted from the converged Q-estimates. The approach is intended to recover the full Pareto-optimal frontier while ensuring each policy is approximately Pareto-optimal for any given preference vector. Experimental results are reported to validate recovery of complex trade-offs.
Significance. If the claimed proofs hold, the work would offer a meaningful advance in multi-objective RL by providing deterministic policy synthesis with explicit enveloping and monotonicity guarantees, avoiding some pitfalls of standard scalarization. The explicit motivation from Chebyshev scalarization and the focus on deterministic policies are positive features.
major comments (2)
- [Abstract] Abstract (and any proof sections): the manuscript asserts proofs of the enveloping property, monotonic convergence, and deterministic policy extraction, but supplies no derivation steps, error bounds, fixed-point arguments, or counter-example verifications. Without these, the central claims cannot be assessed for correctness.
- [Abstract] The enveloping property is stated to hold for the preference-conditioned updates; however, no explicit definition of the operator, the preference space, or the scalarization function is provided to allow verification that the upper bound is produced for all preference vectors.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting areas where the presentation of our theoretical contributions can be strengthened. We address each major comment below and will revise the manuscript accordingly to improve clarity and verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (and any proof sections): the manuscript asserts proofs of the enveloping property, monotonic convergence, and deterministic policy extraction, but supplies no derivation steps, error bounds, fixed-point arguments, or counter-example verifications. Without these, the central claims cannot be assessed for correctness.
Authors: We agree that the abstract summarizes the main results at a high level without including derivation details. The full manuscript contains the proofs in the dedicated theory section (including the fixed-point argument for the preference-conditioned operator and the monotonic convergence analysis under the Chebyshev scalarization). To make these claims more readily assessable, we will expand the abstract with a brief theorem statement and add explicit error bounds plus a short counter-example verification subsection in the revision. revision: yes
-
Referee: [Abstract] The enveloping property is stated to hold for the preference-conditioned updates; however, no explicit definition of the operator, the preference space, or the scalarization function is provided to allow verification that the upper bound is produced for all preference vectors.
Authors: We acknowledge that the abstract does not include the formal definitions. The manuscript defines the preference-conditioned Bellman operator, the preference space (unit simplex), and the Chebyshev scalarization function in Section 2 prior to stating the enveloping property. In the revision we will insert concise formal definitions of the operator and scalarization directly into the abstract (or as a footnote) to enable immediate verification that the upper-bound property holds for all preference vectors. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a preference-conditioned Bellman operator motivated by the external Chebyshev scalarization and states that it proves an enveloping property, monotonic convergence to a coverage set of the Pareto frontier, and deterministic policy extraction. These are presented as mathematical proofs rather than empirical fits, self-definitions, or renamings. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or ansatz smuggled from prior author work; the central claims rest on independent derivation from the scalarization and MOMDP structure. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math MOMDPs are defined with vector-valued rewards and the Pareto frontier is the set of non-dominated value vectors.
- domain assumption The Chebyshev scalarization produces an enveloping upper bound on the Pareto frontier when used inside the Bellman operator.
Reference graph
Works this paper leans on
-
[1]
Learning Gentle Object Manipulation with Curiosity-Driven Deep Reinforcement Learning
doi: 10.1007/s10458-022-09552-y. URL https: //doi.org/10.1007/s10458-022-09552-y. Hu, X., Zhang, Y ., Liao, X., Liu, Z., Wang, W., and Ghan- nouchi, F. M. Dynamic beam hopping method based on multi-objective deep reinforcement learning for next gen- eration satellite broadband systems.IEEE Transactions on Broadcasting, 2020. Huang, S. H., Zambelli, M., Ka...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s10458-022-09552-y 2020
-
[2]
doi: 10.1109/TENCON.2009.5396122. Sutton, R. S. and Barto, A. G.Reinforcement learning: An introduction. MIT press, 2018. Tas ¸kıran, H., Sa˘glıcan, E., and Afacan, E. Multi-objective optimization of analog circuits using reinforcement learn- ing. In2025 21st International Conference on Synthesis, Modeling, Analysis and Simulation Methods, and Appli- cati...
-
[3]
URL https://www.sciencedirect.com/ science/article/pii/S1877050923007767
doi: https://doi.org/10.1016/j.procs.2023.08.018. URL https://www.sciencedirect.com/ science/article/pii/S1877050923007767. Tenth International Conference on Information Technol- ogy and Quantitative Management (ITQM 2023). Zhou, Z., Kearnes, S., Li, L., Zare, R. N., and Riley, P. Op- timization of molecules via deep reinforcement learning. Scientific rep...
-
[4]
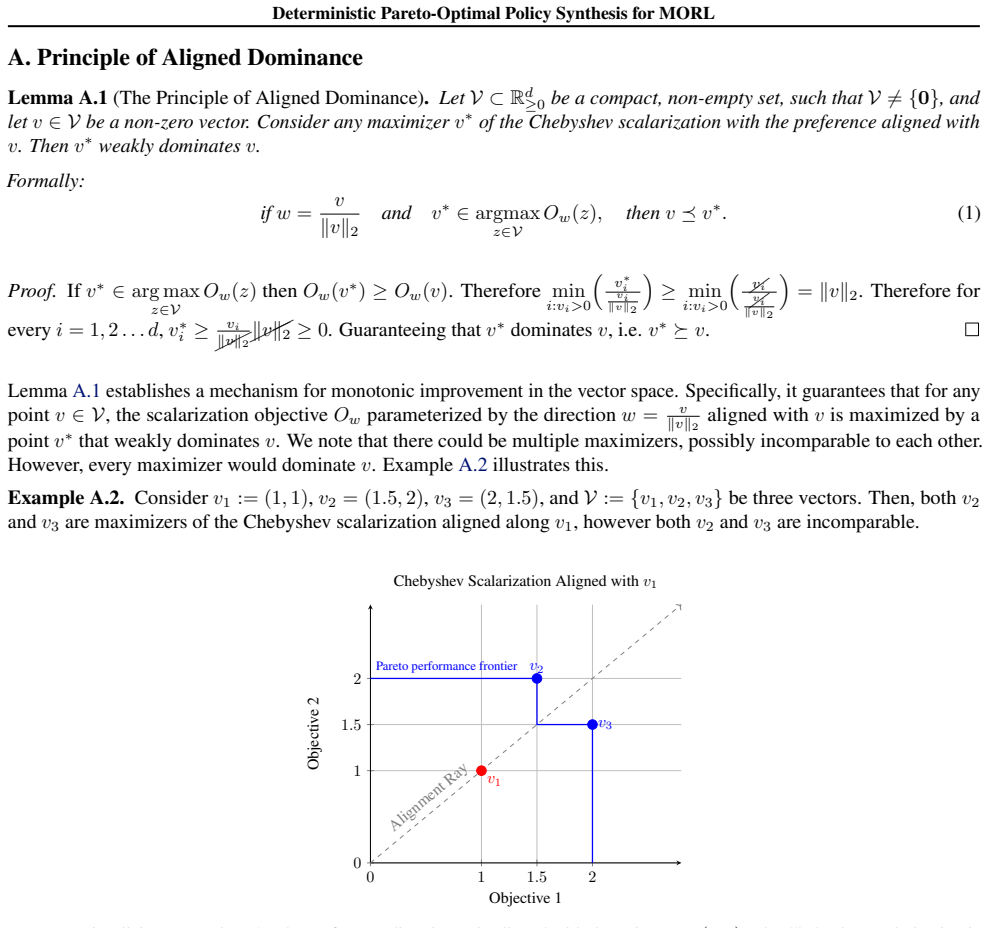
We invoke Lemma A.1 to obtain that for every v′ ∈arg max v∈V Ow(v), we have v′ ⪰v ∗
Necessity Let v∗ ∈ V be a Pareto-optimal point, and let w= v∗ ∥v∗∥2 be the preference aligned with v∗. We invoke Lemma A.1 to obtain that for every v′ ∈arg max v∈V Ow(v), we have v′ ⪰v ∗. However, since v∗ is Pareto-optimal, this condition implies v∗ =v ′. Thus, there is a unique maximizer along the preference aligned withv ∗. Theorem B.2(Coverage and Exa...
-
[5]
Suppose for the sake of contradiction that vw /∈ VP O
(M ⊆ V P O):Let vw ∈ M be a vector selected for some preference w. Suppose for the sake of contradiction that vw /∈ VP O. This implies there exists a dominating vector v∗ ∈ V P O such that vw ≺v ∗. This means vw,k ≤v ∗ k for all componentsk, with strict inequality for at least one component. This dominance implies two properties: (a) Scalarization:Since e...
-
[6]
Consider the specific preference aligned with this vector:w ∗ := v∗ ∥v∗∥2
(V P O ⊆ M):Let v∗ ∈ V P O be an arbitrary Pareto-optimal point. Consider the specific preference aligned with this vector:w ∗ := v∗ ∥v∗∥2 . We invoke Lemma A.1, which states that for aligned preferences, any maximizer v′ ∈arg max v∈V Ow∗(v) of the Chebyshev scalarization Ow∗ must weakly dominate the alignment target: v′ ⪰v ∗. However, since v∗ is Pareto-...
-
[7]
Let us denote this optimal policy by πw
Expansion of Q∗:By Definition 5.1, Q∗(s, a, w) is the value achieved by a policy π that maximizes the Chebyshev scalarization for the preference w. Let us denote this optimal policy by πw. We can expand the value of this policy recursively: Q∗(s, a, w) =R(s, a) +γE s′∼p(·|s,a) h R(s′, a′) +γV πw(·|s′,a′)(p(· |s ′, a′)) i (3) where a′ =π w(s′) is the actio...
-
[8]
Specifically, we claim that for every next state s′, the continuation value vector V πw(·|s′,a′)(p(· |s ′, a′)) is Pareto-optimal
The Claim:To establish the recursive relationship in Equation (2), we must prove that the tail value term corresponds to an optimal value Q∗ for some configuration of action and preference. Specifically, we claim that for every next state s′, the continuation value vector V πw(·|s′,a′)(p(· |s ′, a′)) is Pareto-optimal. If it is Pareto-optimal, then by The...
-
[9]
Stitching
Proof by Contradiction (The “Stitching” Argument):Suppose, for the sake of contradiction, that for the next-state distribution induced by a specific state s′ and action a′ =π w(s′), the continuation policy induced by πw(· |s ′, a′) isnot Pareto-optimal. This implies there exists an alternative policy πbetter that strictly dominates the original “tail” pol...
-
[10]
Conclusion:Because the contradiction assumes the tail was not optimal, we conclude that the induced tail policy must be Pareto-optimal. Since the continuation value is Pareto-optimal, there exists a preference w′ (specifically, the one aligned with the continuation value) from Theorem 4.7.2 such that: R(s′, a′) +γV πw(p(· |s ′, a′)) =Q ∗(s′, a′, w′) Subst...
-
[11]
Formally, for every preference w, there exists a preferencew ′ such that: Q∗(s, a, w)⪯ ˆQn(s, a, w′)
Upper-bound Coverage:The estimated set of values covers the true Pareto front. Formally, for every preference w, there exists a preferencew ′ such that: Q∗(s, a, w)⪯ ˆQn(s, a, w′)
-
[12]
Formally, there is no preference w′ for which a Pareto-optimal value is strictly greater than the estimate inallcomponents: ∀w,∄w ′ such that ˆQn(s, a, w)i < Q ∗(s, a, w′)i ∀i= 1,
Envelope Property:The estimate is never goes below the Pareto performance frontier. Formally, there is no preference w′ for which a Pareto-optimal value is strictly greater than the estimate inallcomponents: ∀w,∄w ′ such that ˆQn(s, a, w)i < Q ∗(s, a, w′)i ∀i= 1, . . . , d 18 Deterministic Pareto-Optimal Policy Synthesis for MORL
-
[13]
There exists a policyπ∈Πsuch that: ˆQn(s, a, w)−V π(s)⪯γ nR Proof.1.Upper-bound Coverage:We prove this by induction onn
Asymptotic Convergence:Every estimate ˆQn corresponds to a feasible policy execution up to a residual term. There exists a policyπ∈Πsuch that: ˆQn(s, a, w)−V π(s)⪯γ nR Proof.1.Upper-bound Coverage:We prove this by induction onn. Base Case (n= 0 ):By initialization, ˆQ0(s, a, w) = R 1−γ , which is the maximum possible return. Thus, Q∗(s, a, w)⪯ ˆQ0(s, a, w...
-
[14]
backtracking
Asymptotic Convergence:Consider an estimate ˆQn(s, a, w). We construct a non-stationary deterministic policy π defined by the “backtracking” trace of the Bellman updates. Let π execute action a at t= 0 . For steps t= 1. . . n−1 , let π select the actions that were chosen as the maximizers during the recursive computation of ˆQn. The accumulated rewards of...
-
[15]
Approximate Coverage:Since we prove in Theorem 5.4.1 that every Pareto-optimal policy π∗ is dominated by an estimateV π∗ (s)⪯ T nQ(s, a, w′)⪯V πw′ (s) +γ nR
-
[16]
Approximate Parsimony:Since there is no policy that dominates an estimate T nQ(s, a, w) we obtain that there is no policy that dominatesV πw(s0) +γ nR. 28
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.