Mean-Field PhiBE: Continuous-Time Mean-Field Reinforcement Learning from Discrete-Time Data
Pith reviewed 2026-06-26 04:24 UTC · model grok-4.3
The pith
MF-PhiBE replaces unknown continuous drifts in a Wasserstein PDE with one-step data estimators to yield first-order accurate mean-field control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
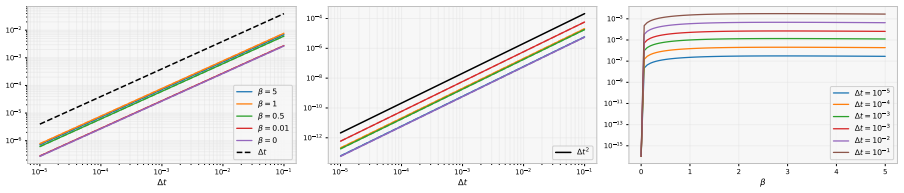
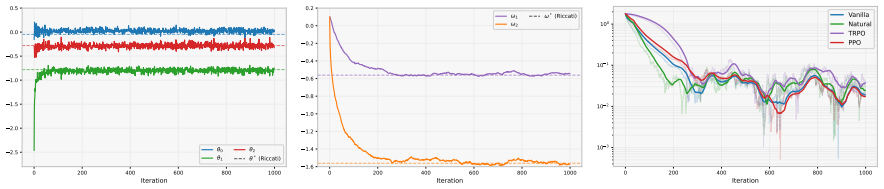
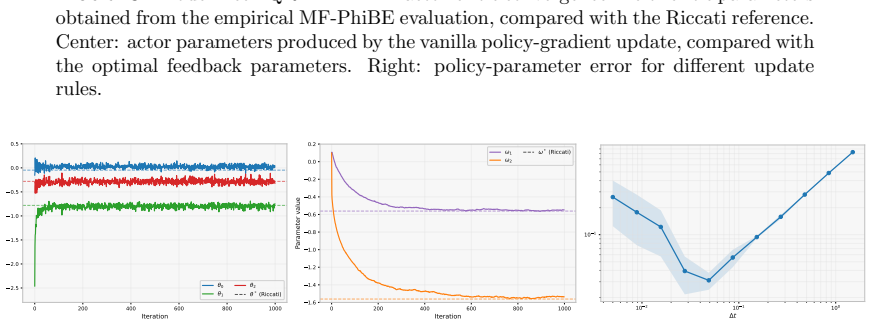
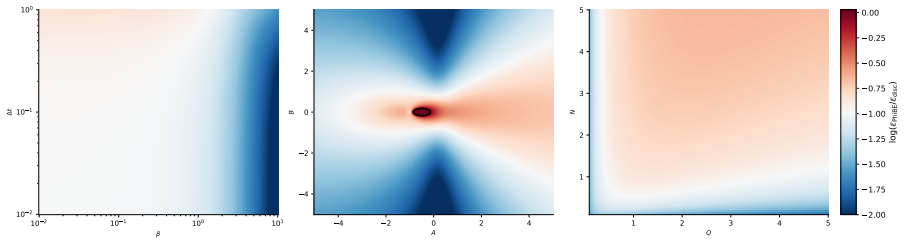
The MF-PhiBE replaces the unknown infinitesimal drift and covariance in the McKean-Vlasov HJB equation by one-step estimators computed from data, while preserving the generator structure of the McKean-Vlasov HJB equation. Combined with a policy-gradient theorem for entropy-regularized randomized feedback policies, this yields a model-free actor-critic method. We prove a first-order consistency estimate showing that the value induced by an optimal MF-PhiBE policy approximates the optimal continuous-time value with an error of order Δt. In the linear-quadratic case, we show our approximation achieves second-order accuracy with only one-step data.
What carries the argument
The MF-PhiBE equation, which substitutes discrete-time one-step estimators for the unknown infinitesimal generator inside the continuous McKean-Vlasov HJB PDE on the Wasserstein space.
If this is right
- The value induced by an optimal MF-PhiBE policy approximates the optimal continuous-time value with error of order Δt.
- In the linear-quadratic case the approximation achieves second-order accuracy using only one-step data.
- A policy-gradient theorem holds for entropy-regularized randomized feedback policies, expressing the actor direction via the action-wise infinitesimal advantage and the policy score.
- The two ingredients together produce a model-free actor-critic algorithm for continuous-time mean-field control from discrete observations.
Where Pith is reading between the lines
- If reliable one-step estimators remain computable in high dimensions, the same substitution idea could apply to mean-field games or other interaction structures beyond the tested crowd-aversion example.
- The first-order consistency result suggests that collecting multi-step trajectories might allow higher-order corrections in non-LQ settings, a direction left open by the current analysis.
- Discretization of the probability-measure space is still required for implementation and may limit accuracy independently of the Δt error term.
- Similar replacement of unknown generators by data estimators could be tested in other continuous-time control problems where only sampled trajectories are available.
Load-bearing premise
That one-step estimators computed from discrete transitions can stand in for the infinitesimal drift and covariance while keeping the generator structure intact enough for the consistency result to hold.
What would settle it
A concrete numerical counterexample in which the value error of the optimal MF-PhiBE policy fails to scale as O(Δt) when the time step is successively halved in a non-linear-quadratic McKean-Vlasov control problem.
Figures


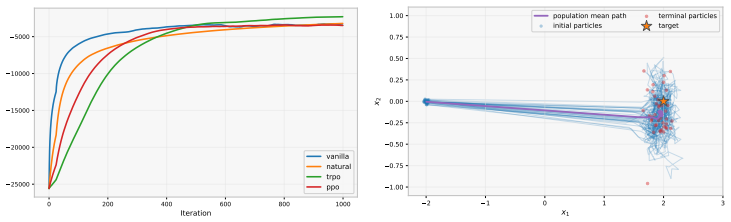
read the original abstract
This paper addresses model-free continuous-time mean-field control in a setting where the population dynamics evolve continuously according to an unknown McKean-Vlasov stochastic differential equation, while only discrete-time transition data are available. In the model-based formulation, policy evaluation is naturally described by a stationary Hamilton-Jacobi-Bellman equation on $\mathcal P_2(\mathbb R^d)$, but this equation involves the drift and diffusion coefficients of the controlled McKean-Vlasov dynamics, which are not identifiable when only discrete-time data are available. On the other hand, a direct reduction to a time-discrete Bellman equation avoids the non-identifiability issue but loses the differential equation structure. To bridge these two viewpoints, we introduce a Mean-Field-PhiBE (MF-PhiBE), which incorporates discrete-time transition information into a continuous-time PDE on the Wasserstein space. The MF-PhiBE replaces the unknown infinitesimal drift and covariance in the policy-evaluation equation by one-step estimators computed from data, while preserving the generator structure of the McKean-Vlasov HJB equation. We also derive a policy-gradient theorem for entropy-regularized randomized feedback policies, expressing the actor direction through an action-wise infinitesimal advantage and the score of the policy. Combining these two ingredients yields a model-free actor-critic method. We prove a first-order consistency estimate showing that the value induced by an optimal MF-PhiBE policy approximates the optimal continuous-time value with an error of order $\Delta t$. In the linear-quadratic case, we show our approximation achieves second-order accuracy with only one-step data. Numerical experiments on an LQR benchmark and a crowd-aversion problem illustrate the proposed framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Mean-Field PhiBE (MF-PhiBE) to enable model-free continuous-time mean-field control when only discrete-time transition data are available for an unknown McKean-Vlasov SDE. It substitutes one-step data estimators for the unknown drift and covariance inside a stationary HJB equation on P₂(ℝ^d), derives an entropy-regularized policy-gradient theorem, proves that the resulting optimal MF-PhiBE policy yields a value within O(Δt) of the true continuous-time optimum, obtains second-order accuracy in the linear-quadratic case, and illustrates the method on LQR and crowd-aversion benchmarks.
Significance. If the consistency result holds, the work provides a principled bridge between discrete data and continuous-time mean-field PDEs, which is valuable for applications such as crowd dynamics or systemic risk where only sampled transitions are observable. The explicit policy-gradient expression and the LQ second-order claim (when verified) would be concrete strengths.
major comments (2)
- [first-order consistency estimate] The first-order consistency estimate (abstract and the theorem establishing O(Δt) approximation): the argument that one-step estimators can be substituted into the McKean-Vlasov generator while keeping the induced perturbation O(Δt) must explicitly control the Wasserstein distance of the empirical drift/covariance estimators uniformly over admissible controls; without this, the measure-derivative terms in the HJB can amplify the approximation error beyond the claimed order.
- [linear-quadratic case] Linear-quadratic second-order accuracy claim (abstract): the proof must verify that the leading O(Δt) bias terms arising from the Euler-type one-step estimators cancel exactly under the linear mean-field interaction; otherwise the claimed improvement over the generic first-order result does not hold.
minor comments (1)
- Notation for the Wasserstein space and the precise definition of the one-step estimators should be introduced earlier to improve readability of the consistency argument.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. The two major comments identify points where the proofs would benefit from greater explicitness. We address each below and will incorporate the requested clarifications in a revised version.
read point-by-point responses
-
Referee: [first-order consistency estimate] The first-order consistency estimate (abstract and the theorem establishing O(Δt) approximation): the argument that one-step estimators can be substituted into the McKean-Vlasov generator while keeping the induced perturbation O(Δt) must explicitly control the Wasserstein distance of the empirical drift/covariance estimators uniformly over admissible controls; without this, the measure-derivative terms in the HJB can amplify the approximation error beyond the claimed order.
Authors: We agree that an explicit uniform-in-control bound on the Wasserstein distance of the one-step estimators is required to control the perturbation through the measure derivatives in the HJB equation. Our current argument uses the standing Lipschitz assumption on the controlled coefficients with respect to the measure variable together with compactness of the admissible control set to obtain a uniform O(Δt) bound; however, this step is only sketched. We will add a dedicated lemma (new Lemma 3.4) that states and proves sup over admissible controls of the Wasserstein distance between the empirical estimators and the true McKean-Vlasov coefficients is O(Δt) with high probability. This lemma will be placed immediately before the consistency theorem and will be invoked to justify that the induced HJB perturbation remains O(Δt). revision: yes
-
Referee: [linear-quadratic case] Linear-quadratic second-order accuracy claim (abstract): the proof must verify that the leading O(Δt) bias terms arising from the Euler-type one-step estimators cancel exactly under the linear mean-field interaction; otherwise the claimed improvement over the generic first-order result does not hold.
Authors: We thank the referee for this precise observation. In the LQ section we do expand the one-step estimators and substitute them into the quadratic value function, but the cancellation of the O(Δt) bias terms is not written out as a separate calculation. Because the dynamics are linear in both state and measure and the running cost is quadratic, the first-order bias contributed by the Euler drift estimator is exactly offset by the linear mean-field coupling term, while the covariance bias likewise cancels against the quadratic interaction. We will revise Section 5 to include an explicit intermediate expansion (new display equation (5.8)) that isolates and shows the vanishing of these O(Δt) terms, thereby confirming the second-order accuracy. revision: yes
Circularity Check
No circularity: consistency theorem is an independent mathematical estimate
full rationale
The central claims rest on introducing the MF-PhiBE via substitution of one-step data estimators into the McKean-Vlasov HJB and then proving a first-order consistency estimate (value error O(Δt)) plus an LQ second-order result. These are presented as derived theorems rather than tautological re-statements of the estimators or input data. No load-bearing self-citation, self-definitional loop, or fitted parameter renamed as prediction appears in the derivation chain; the policy-gradient theorem and consistency proof supply independent content that does not reduce to the discrete transitions by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The population dynamics evolve according to a controlled McKean-Vlasov SDE
- ad hoc to paper One-step estimators from discrete data can substitute for the infinitesimal generator coefficients
Forward citations
Cited by 1 Pith paper
-
Mean Field Reinforcement Learning
A monograph develops the probabilistic and control-theoretic framework connecting multi-agent reinforcement learning to mean field control, including analyses of Q-learning, policy gradients, and numerical methods for...
Reference graph
Works this paper leans on
-
[1]
Mean field type control with congestion.Applied Mathematics & Optimization, 73(3):393–418, 2016
Yves Achdou and Mathieu Lauri` ere. Mean field type control with congestion.Applied Mathematics & Optimization, 73(3):393–418, 2016
2016
-
[2]
Mean field type control with congestion II: An augmented lagrangian method
Yves Achdou and Mathieu Lauri` ere. Mean field type control with congestion II: An augmented lagrangian method. Applied Mathematics & Optimization, 74(3):535–578, 2016
2016
-
[3]
Finite approximations and q-learning for mean field type multi-agent control.Applied Mathematics and Optimization, 92(7), 2025
Erhan Bayraktar, Nicole B¨ auerle, and Ali Devran Kara. Finite approximations and q-learning for mean field type multi-agent control.Applied Mathematics and Optimization, 92(7), 2025
2025
-
[4]
A numerical scheme for a mean field game in some queueing systems based on markov chain approximation method.SIAM Journal on Control and Optimization, 56(6):4017–4044, 2018
Erhan Bayraktar, Amarjit Budhiraja, and Asaf Cohen. A numerical scheme for a mean field game in some queueing systems based on markov chain approximation method.SIAM Journal on Control and Optimization, 56(6):4017–4044, 2018
2018
-
[5]
Rate control under heavy traffic with strategic servers.Annals of Applied Probability, 29(1), 2019
Erhan Bayraktar, Amarjit Budhiraja, and Asaf Cohen. Rate control under heavy traffic with strategic servers.Annals of Applied Probability, 29(1), 2019
2019
-
[6]
Erhan Bayraktar, Andrea Cosso, and Huyˆ en Pham. Randomized dynamic programming principle and feynman–kac representation for optimal control of mckean–vlasov dynamics.Transactions of the American Mathematical Society, 370(3):2115–2165, 2018
2018
-
[7]
Comparison for semi-continuous viscosity solutions for second order pdes on the wasserstein space.Journal of Differential Equations, 455:1–31, 2026
Erhan Bayraktar, Ibrahim Ekren, Xihao He, and Xin Zhang. Comparison for semi-continuous viscosity solutions for second order pdes on the wasserstein space.Journal of Differential Equations, 455:1–31, 2026. 41
2026
-
[8]
Comparison of viscosity solutions for a class of second-order pdes on the wasserstein space.Communications in Partial Differential Equations, 50(4):570–613, 2025
Erhan Bayraktar, Ibrahim Ekren, and Xin Zhang. Comparison of viscosity solutions for a class of second-order pdes on the wasserstein space.Communications in Partial Differential Equations, 50(4):570–613, 2025
2025
-
[9]
Convergence rate of particle system for second-order pdes on wasserstein space.SIAM Journal on Control and Optimization, 63(3):1515–1782, 2025
Erhan Bayraktar, Ibrahim Ekren, and Xin Zhang. Convergence rate of particle system for second-order pdes on wasserstein space.SIAM Journal on Control and Optimization, 63(3):1515–1782, 2025
2025
-
[10]
Policy gradient for continuous-time mean-field control.Preprint, 2026
Erhan Bayraktar, Martin Hernandez, Qinxin Yan, and Yuhua Zhu. Policy gradient for continuous-time mean-field control.Preprint, 2026. arXiv preprint
2026
-
[11]
Learning with linear function approximations in mean-field control.Journal of Machine Learning Research, 26(192):1–53, 2025
Erhan Bayraktar and Ali Devran Kara. Learning with linear function approximations in mean-field control.Journal of Machine Learning Research, 26(192):1–53, 2025
2025
-
[12]
SpringerBriefs in Mathematics
Alain Bensoussan, Jens Frehse, and Phillip Yam.Mean field games and mean field type control theory. SpringerBriefs in Mathematics. Springer, New York, 2013
2013
-
[13]
Forward–backward stochastic differential equations and controlled McKean– Vlasov dynamics.Annals of Probability, 43(5):2647–2700, 2015
Ren´ e Carmona and Fran¸ cois Delarue. Forward–backward stochastic differential equations and controlled McKean– Vlasov dynamics.Annals of Probability, 43(5):2647–2700, 2015
2015
-
[14]
I, volume 83 of Probability Theory and Stochastic Modelling
Ren´ e Carmona and Fran¸ cois Delarue.Probabilistic theory of mean field games with applications. I, volume 83 of Probability Theory and Stochastic Modelling. Springer, Cham, 2018. Mean field FBSDEs, control, and games
2018
-
[15]
II, volume 84 of Probability Theory and Stochastic Modelling
Ren´ e Carmona and Fran¸ cois Delarue.Probabilistic theory of mean field games with applications. II, volume 84 of Probability Theory and Stochastic Modelling. Springer, Cham, 2018. Mean field games with common noise and master equations
2018
-
[16]
Ren´ e Carmona and Mathieu Lauri` ere. Convergence analysis of machine learning algorithms for the numerical solution of mean field control and games: II — the finite horizon case.Annals of Applied Probability, 32(6):4065–4105, 2022
2022
-
[17]
Ren´ e Carmona, Mathieu Lauri` ere, and Zongjun Tan. Linear-quadratic mean-field reinforcement learning: Convergence of policy gradient methods.Preprint arXiv:1910.04295, 2019
-
[18]
Numerical method for FBSDEs of McKean–Vlasov type.Annals of Applied Probability, 29(3):1640–1684, 2019
Jean-Fran¸ cois Chassagneux, Dan Crisan, and Fran¸ cois Delarue. Numerical method for FBSDEs of McKean–Vlasov type.Annals of Applied Probability, 29(3):1640–1684, 2019
2019
-
[19]
Martingale measures and stochastic calculus.Probability Theory and Related Fields, 84(1–2):83–101, 1990
Nicole El Karoui and Sylvie M´ el´ eard. Martingale measures and stochastic calculus.Probability Theory and Related Fields, 84(1–2):83–101, 1990
1990
-
[20]
Actor-critic learning for mean-field control in continuous time.J
Noufel Frikha, Maximilien Germain, Mathieu Lauriere, Huyˆ en Pham, and Xuanye Song. Actor-critic learning for mean-field control in continuous time.J. Mach. Learn. Res., 26:Paper No. [127], 42, 2025
2025
- [21]
-
[22]
Fast policy learning for linear-quadratic control with entropy regularization
Xin Guo, Xinyu Li, and Renyuan Xu. Fast policy learning for linear-quadratic control with entropy regularization. SIAM Journal on Control and Optimization, 64(1):124–151, 2026
2026
-
[23]
Accuracy of discretely sampled stochastic policies in continuous-time reinforcement learning
Yanwei Jia, Du Ouyang, and Yufei Zhang. Accuracy of discretely sampled stochastic policies in continuous-time reinforcement learning. Preprint arXiv:2503.09981, 2025
-
[24]
Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach.Journal of Machine Learning Research, 23(1):6918–6972, 2022
Yanwei Jia and Xun Yu Zhou. Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach.Journal of Machine Learning Research, 23(1):6918–6972, 2022
2022
-
[25]
Policy gradient and actor-critic learning in continuous time and space.Journal of Machine Learning Research, 23(1):12603–12652, 2022
Yanwei Jia and Xun Yu Zhou. Policy gradient and actor-critic learning in continuous time and space.Journal of Machine Learning Research, 23(1):12603–12652, 2022
2022
-
[26]
Yanwei Jia and Xun Yu Zhou.q-learning in continuous time.Journal of Machine Learning Research, 24(161):1–61, 2023
2023
-
[27]
Limit theory for controlled McKean–Vlasov dynamics.SIAM Journal on Control and Optimization, 55(3):1641–1672, 2017
Daniel Lacker. Limit theory for controlled McKean–Vlasov dynamics.SIAM Journal on Control and Optimization, 55(3):1641–1672, 2017
2017
-
[28]
Numerical methods for mean field games and mean field type control.Proceedings of Symposia in Applied Mathematics, 78:221–282, 2021
Mathieu Lauri` ere. Numerical methods for mean field games and mean field type control.Proceedings of Symposia in Applied Mathematics, 78:221–282, 2021
2021
-
[29]
On Bellman equations for continuous-time policy evaluation I: Discretization and approximation
Wenlong Mou and Yuhua Zhu. On Bellman equations for continuous-time policy evaluation I: Discretization and approximation. Preprint arXiv:2407.05966, 2024
-
[30]
Actor-critic learning algorithms for mean-field control with moment neural networks
Huyˆ en Pham and Xavier Warin. Actor-critic learning algorithms for mean-field control with moment neural networks. Methodology and Computing in Applied Probability, 27(13), 2025
2025
-
[31]
Dynamic programming for optimal control of stochastic McKean–Vlasov dynamics
Huyˆ en Pham and Xiaoli Wei. Dynamic programming for optimal control of stochastic McKean–Vlasov dynamics. SIAM Journal on Control and Optimization, 55(2):1069–1101, 2017
2017
-
[32]
Mean-field neural networks: Learning mappings on wasserstein space.Neural Net- works, 168:380–393, 2023
Huyˆ en Pham and Xavier Warin. Mean-field neural networks: Learning mappings on wasserstein space.Neural Net- works, 168:380–393, 2023
2023
-
[33]
Osher, Wuchen Li, Levon Nurbekyan, and Samy Wu Fung
Lars Ruthotto, Stanley J. Osher, Wuchen Li, Levon Nurbekyan, and Samy Wu Fung. A machine learning framework for solving high-dimensional mean field game and mean field control problems.Proceedings of the National Academy of Sciences, 117(17):9183–9193, 2020
2020
-
[34]
arXiv preprint arXiv:2503.17869 , year=
H. Mete Soner, Josef Teichmann, and Qinxin Yan. Learning algorithms for mean field optimal control.Preprint arXiv:2503.17869, 2025
-
[35]
Perturbation theory for algebraic riccati equations.SIAM Journal on Matrix Analysis and Applications, 19(1):39–65, 1998
Ji-guang Sun. Perturbation theory for algebraic riccati equations.SIAM Journal on Matrix Analysis and Applications, 19(1):39–65, 1998
1998
-
[36]
The exact law of large numbers via fubini extension and characterization of insurable risks.Journal of Economic Theory, 126(1):31–69, 2006
Yeneng Sun. The exact law of large numbers via fubini extension and characterization of insurable risks.Journal of Economic Theory, 126(1):31–69, 2006
2006
-
[37]
Optimal scheduling of entropy regularizer for continuous- time linear-quadratic reinforcement learning.SIAM Journal on Control and Optimization, 62(1):135–166, 2024
Lukasz Szpruch, Tanut Treetanthiploet, and Yufei Zhang. Optimal scheduling of entropy regularizer for continuous- time linear-quadratic reinforcement learning.SIAM Journal on Control and Optimization, 62(1):135–166, 2024
2024
-
[38]
Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research, 21(198):1–34, 2020
Haoran Wang, Thaleia Zariphopoulou, and Xun Yu Zhou. Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research, 21(198):1–34, 2020
2020
-
[39]
Continuous time q-learning for mean-field control problems.Applied Mathematics & Opti- mization, 91(1):10, 2025
Xiaoli Wei and Xiang Yu. Continuous time q-learning for mean-field control problems.Applied Mathematics & Opti- mization, 91(1):10, 2025. 42
2025
-
[40]
Policy optimization for continuous reinforcement learning
Hanyang Zhao, Wenpin Tang, and David Yao. Policy optimization for continuous reinforcement learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 13637–13663. Curran Associates, Inc., 2023
2023
-
[41]
PhiBE: A PDE-based Bellman equation for continuous time policy evaluation
Yuhua Zhu. PhiBE: A PDE-based Bellman equation for continuous time policy evaluation. Preprint arXiv:2405.12535, 2024
-
[42]
Optimal-phibe: A pde-based model-free framework for continuous-time reinforcement learning, 2025
Yuhua Zhu, Yuming Zhang, and Haoyu Zhang. Optimal-phibe: A pde-based model-free framework for continuous-time reinforcement learning, 2025. 43
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.