A Multi-Level Validation and Traceability Framework for AI-Generated Telescope Scheduling Decisions
Pith reviewed 2026-06-26 05:12 UTC · model grok-4.3
The pith
A multi-level validation framework corrects and traces errors in AI telescope scheduling decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
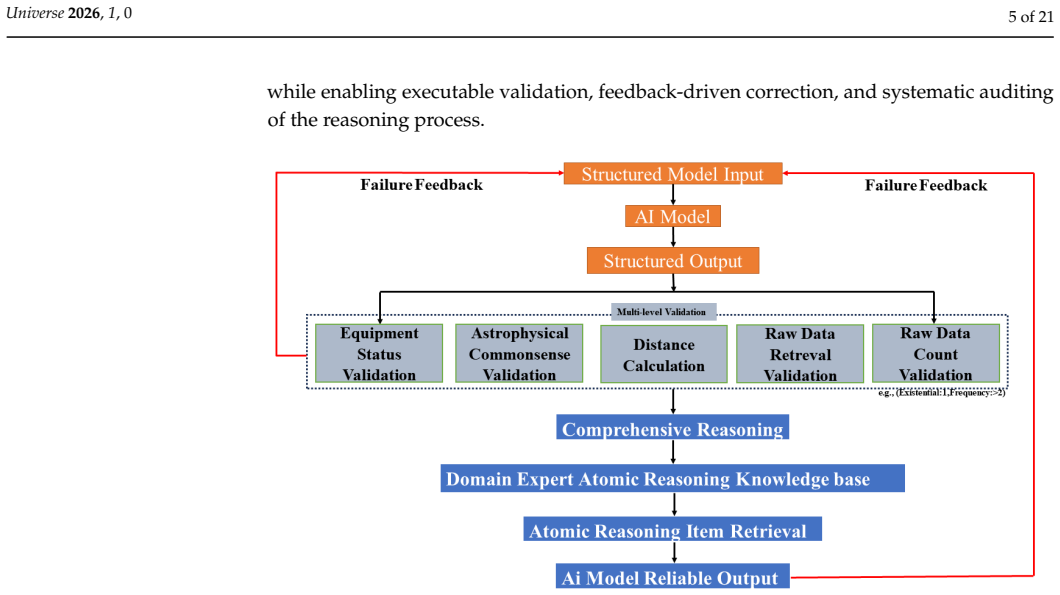
The multi-level validation and traceable reasoning framework performs systematic reliability verification of AI-generated decisions prior to execution through data reference validation, logical consistency checks, and observational and instrumental constraint verification. Scheduling decisions are represented as sequences of interconnected atomic reasoning units that support error localization and post hoc analysis. This approach improves the executability and reliability of AI scheduling, reduces loss of transient opportunities, and enhances the ability to repair and block erroneous decisions compared to pure AI methods while maintaining flexibility.
What carries the argument
The multi-level validation and traceability framework consisting of data reference validation, logical consistency checks, constraint verification, and atomic reasoning units with dependency relationships.
If this is right
- AI-generated scheduling decisions gain higher executability and reliability before execution.
- Feedback correction and structured validation of reasoning steps improve error repair and blocking in complex scenarios.
- The approach reduces loss of transient opportunities in astronomical observations.
- Traceable representation of decisions enables post hoc analysis and explicit reasoning support.
- Flexibility of AI methods is maintained while reliability and executability are substantially improved.
Where Pith is reading between the lines
- Similar validation structures could be tested in other AI decision domains requiring high reliability, such as resource allocation in scientific instruments.
- Integration with real-time telescope operations could be evaluated to measure impact on actual observation outcomes.
- The dependency relationships among atomic reasoning units might support automated debugging tools for scheduling AI.
- The framework's design allows for human-in-the-loop verification at specific reasoning steps.
Load-bearing premise
The validation layers can reliably detect and correct invalid AI decisions without introducing new errors or blocking valid schedules, and that the atomic reasoning units accurately capture the decision process.
What would settle it
Observing whether the framework incorrectly passes an invalid schedule with inconsistent data references or blocks a schedule that meets all constraints in a controlled test set of AI-generated decisions.
Figures


read the original abstract
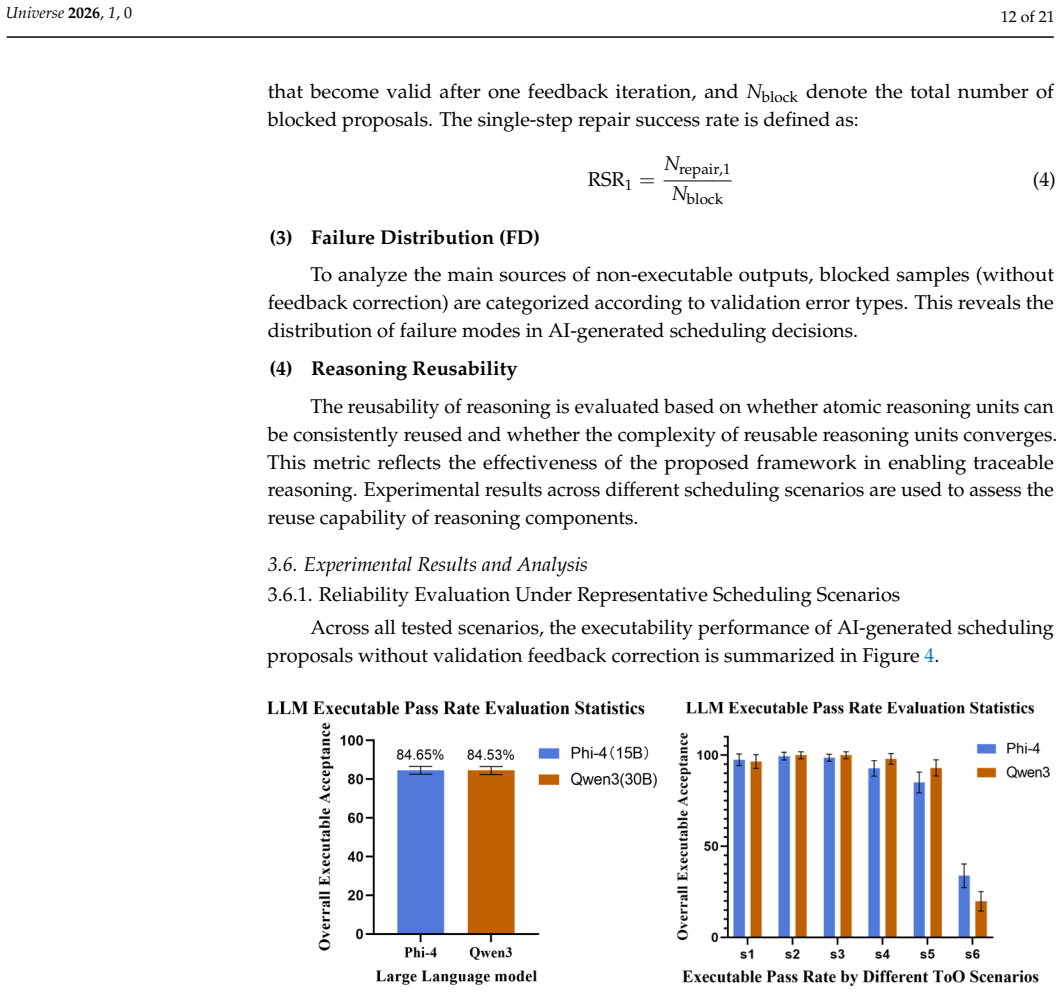
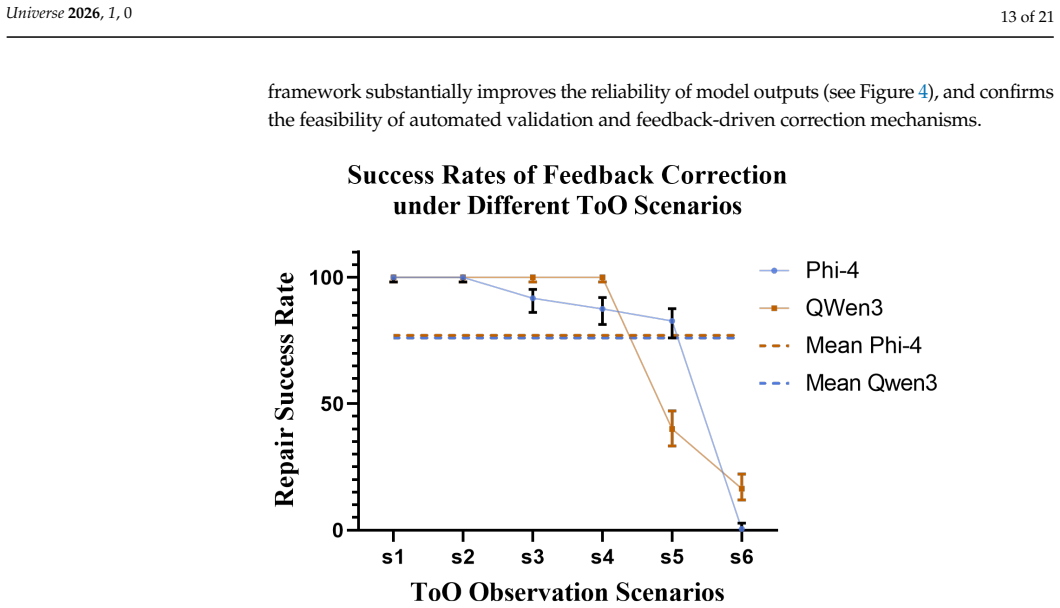
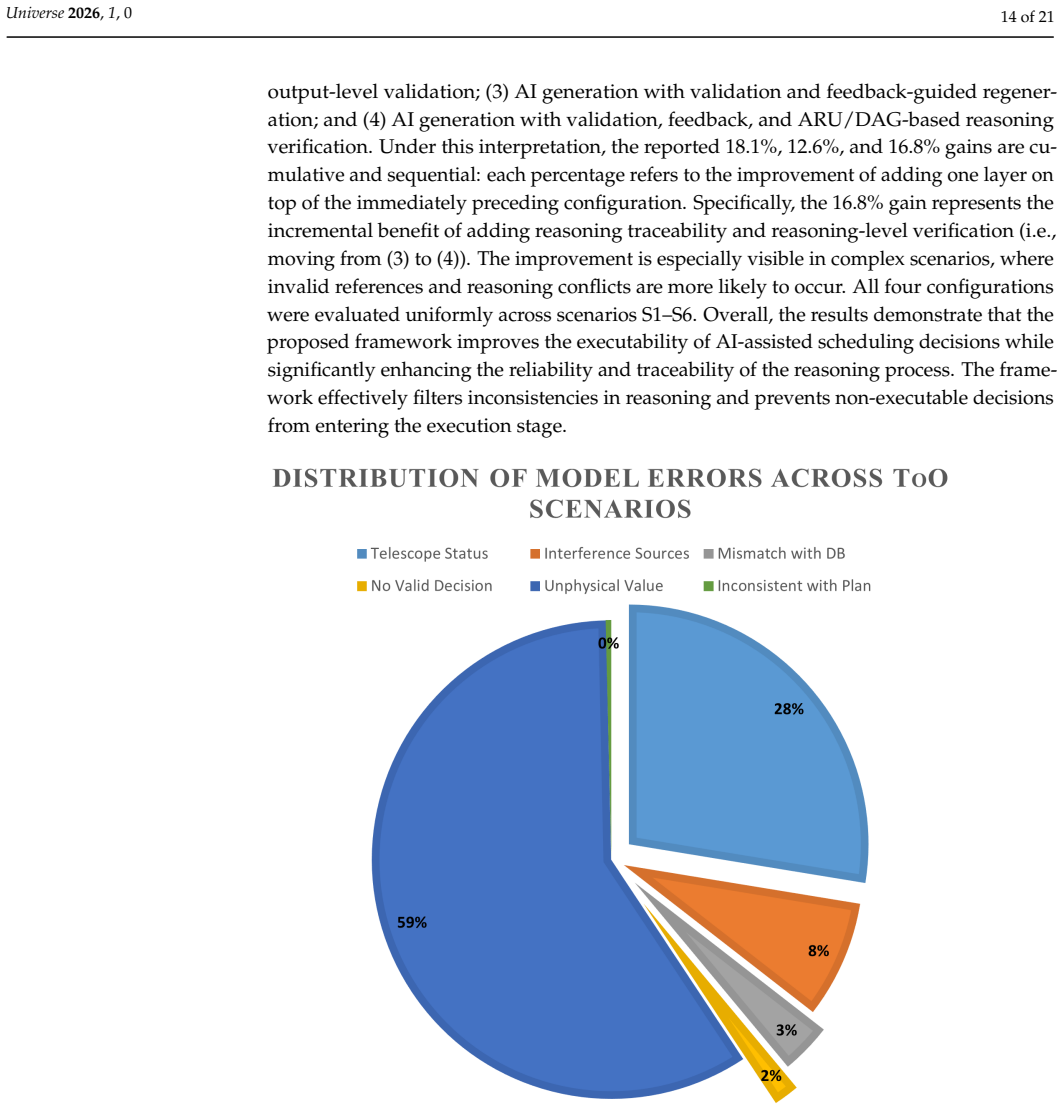
With the gradual introduction of AI into telescope scheduling, AI-based decision-making has shown advantages in handling complex multi-constraint problems. However, its outputs often suffer from inconsistent data references, reasoning errors, and non-executable decisions, limiting applicability in high-reliability observational tasks. In this work, we propose a multi-level validation and traceable reasoning framework that performs systematic reliability verification of AI-generated decisions prior to execution, and enables explicit representation of the reasoning process to support traceable decision-making. The framework integrates data reference validation, logical consistency checks, and observational and instrumental constraint verification to filter and correct invalid decisions. It also introduces atomic reasoning units and their dependency relationships, representing scheduling decisions as a sequence of interconnected reasoning steps that support error localization and post hoc analysis. Experiments show that the framework improves executability and reliability of AI scheduling and reduces loss of transient opportunities. In particular, feedback correction and structured validation of reasoning steps enhance the ability to repair and block erroneous decisions, especially in complex scenarios. Compared with pure AI methods, the framework-enhanced approach maintains flexibility while substantially improving reliability and executability. These results demonstrate a feasible and verifiable pathway for applying AI to high-reliability astronomical observation scheduling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-level validation and traceability framework for AI-generated telescope scheduling decisions. It integrates data reference validation, logical consistency checks, observational/instrumental constraint verification, and atomic reasoning units with dependency relationships to filter/correct invalid decisions and enable error localization. The central claim is that this framework improves executability, reliability, and reduces loss of transient opportunities compared to pure AI methods, with experiments demonstrating benefits especially in complex scenarios via feedback correction and structured validation.
Significance. If the experimental claims hold with supporting data, the work could offer a practical, verifiable approach to deploying AI in high-reliability astronomical scheduling by adding systematic checks and traceability without sacrificing flexibility. The use of atomic reasoning units for post-hoc analysis is a potentially useful contribution to explainable AI in constraint-heavy domains.
major comments (1)
- [Abstract] Abstract: The statement that 'Experiments show that the framework improves executability and reliability of AI scheduling and reduces loss of transient opportunities' and that it 'substantially improving reliability and executability' is presented without any quantitative results, baselines, datasets, test scenarios, error metrics, or statistical details. This directly undermines the central claim that the framework provides substantial improvements, as the evidence for the key benefit is absent from the manuscript text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the single major comment below and agree that revisions are needed to strengthen the presentation of experimental evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that 'Experiments show that the framework improves executability and reliability of AI scheduling and reduces loss of transient opportunities' and that it 'substantially improving reliability and executability' is presented without any quantitative results, baselines, datasets, test scenarios, error metrics, or statistical details. This directly undermines the central claim that the framework provides substantial improvements, as the evidence for the key benefit is absent from the manuscript text.
Authors: We agree that the abstract, as currently written, makes claims about experimental improvements without including quantitative details, baselines, or metrics. The full manuscript does contain an Experiments section with comparisons to pure AI methods, descriptions of test scenarios, error metrics, and results on executability/reliability in complex cases, but these specifics were not summarized numerically in the abstract. We will revise the abstract to include key quantitative highlights (e.g., percentage improvements, dataset sizes, and statistical comparisons) drawn directly from the experimental results to better support the central claims. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an independent multi-level validation and traceability framework for AI telescope scheduling, consisting of data reference validation, logical consistency checks, constraint verification, and atomic reasoning units with dependency relationships. No equations, fitted parameters, predictions of derived quantities, or self-citation chains appear in the provided text. Central claims rest on experimental outcomes rather than any reduction of outputs to inputs by definition or construction. The framework is presented as an additive verification layer, not a re-derivation of its own premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ivezi´ c, Ž.; Kahn, S.M.; Tyson, J.A.; Abel, B.; Acosta, E.; Allsman, R.; Alonso, D.; AlSayyad, Y.; Anderson, S.F.; Andrew, J.; et al. LSST: From Science Drivers to Reference Design and Anticipated Data Products.Astrophys. J.2019,873, 111. https://doi.org/10.3847/1538-4357/ab042c. https://doi.org/10.3390/universe1010000 Universe2026,1, 0 21 of 21
-
[2]
Magnier, E.A.; Chambers, K.C.; Flewelling, H.A.; Hoblitt, J.C.; Huber, M.E.; Price, P .A.; Sweeney, W.E.; Waters, C.Z.; Denneau, L.; Draper, P .W.; et al. The Pan-STARRS Data-processing System.Astrophys. J. Suppl. Ser.2020,251, 3. https://doi.org/10.3847/1538 -4365/abb829
-
[3]
The Mini-SiTian Array: Optical Design.Res
Han, Z.J.; Li, Z.Y.; Chen, C.; Cong, J.N.; Liu, T.T.; Zhang, Y.M.; Li, Q.S.; Chen, L.; Kong, W.B. The Mini-SiTian Array: Optical Design.Res. Astron. Astrophys.2025,25, 044002. https://doi.org/10.1088/1674-4527/adc78f
-
[4]
Naghib, E.; Yoachim, P .; Vanderbei, R.J.; Connolly, A.J.; Jones, R.L. A Framework for Telescope Schedulers: With Applications to the Large Synoptic Survey Telescope.Astron. J.2019,157, 151. https://doi.org/10.3847/1538-3881/aafece
-
[5]
Zhang, Y.; Yu, C.; Sun, C.; Shang, Z.; Hu, Y.; Zhi, H.; Yang, J.; Tang, S. A Multilevel Scheduling Framework for Distributed Time-domain Large-area Sky Survey Telescope Array.Astron. J.2023,165, 77. https://doi.org/10.3847/1538-3881/acac24
-
[6]
Jia, P .; Jia, Q.; Jiang, T.; Yang, Z. A simulation framework for telescope array and its application in distributed reinforcement learning-based scheduling of telescope arrays.Astron. Comput.2023,44, 100732. https://doi.org/10.1016/j.ascom.2023.100732
-
[7]
Basic Survey Scheduling for the Wide Field Survey Telescope (WFST).Res
Chen, Y.P .; Jiang, J.A.; Luo, W.T.; Zheng, X.Z.; Fang, M.; Yang, C.; Hong, Y.Y.; Lü, Z.F. Basic Survey Scheduling for the Wide Field Survey Telescope (WFST).Res. Astron. Astrophys.2024,24, 015003. https://doi.org/10.1088/1674-4527/ad07cd
-
[8]
Zhang, Y.; Yu, C.; Sun, C.; Hu, Y.; Shang, Z.; Wei, J.; Yang, X. GRRIS: A Real-time Intrasite Observation Scheduling Scheme for Distributed Survey Telescope Arrays.Astron. J.2024,168, 214. https://doi.org/10.3847/1538-3881/ad77ab
-
[9]
Relay Observation Scheduling of Global Distributed Telescope Array Based on Integer Programming.Res
Ju, J.; Yu, C.; Hu, Y.; Zhang, Y.; Sun, C.; Wei, J. Relay Observation Scheduling of Global Distributed Telescope Array Based on Integer Programming.Res. Astron. Astrophys.2025,25, 015008. https://doi.org/10.1088/1674-4527/ad9429
-
[10]
Cao, H.; Hu, S.; Du, J.; Chen, X.; Liu, S.; Feng, S.; Zhang, B.; Jiang, Y. Deep Reinforcement Learning for Efficient Scheduling of Ground-based Astronomical Observations.Astron. J.2025,170, 88. https://doi.org/10.3847/1538-3881/ade3dc
-
[11]
Rehemtulla, N.; Coughlin, M.W.; Miller, A.A.; du Laz, T.J. The automation of optical transient discovery and classification in Rubin-era time-domain astronomy.Nat. Astron.2025,9, 1764–1769. https://doi.org/10.1038/s41550-025-02720-6
-
[12]
Huang, K.; Hu, T.; Cai, J.; Pan, X.; Hou, Y.; Xu, L.; Wang, H.; Zhang, Y.; Cui, X. Artificial Intelligence in Astronomical Optical Telescopes: Present Status and Future Perspectives.Universe2024,10, 210. https://doi.org/10.3390/universe10050210
-
[13]
The indiscriminate adoption of ai threatens the foundations of academia
Trotta, R. The indiscriminate adoption of AI threatens the foundations of academia.Nat. Astron.2025,9, 1748–1749. https: //doi.org/10.1038/s41550-025-02738-w
-
[14]
de Haan, T.; Ting, Y.S.; Ghosal, T.; Nguyen, T.D.; Accomazzi, A.; Wells, A.; Ramachandra, N.; Pan, R.; Sun, Z. Achieving GPT-4o level performance in astronomy with a specialized 8B-parameter large language model.Sci. Rep.2025,15, 13751. https://doi.org/10.1038/s41598-025-97131-y
-
[15]
StarWhisper Telescope: An AI framework for automating end-to-end astronomical observations.Commun
Wang, C.; Zhang, Y.; Li, Y.; Hu, X.; Mao, Y.; Chen, X.; Du, P .; Wang, R.; Wu, Y.; Yang, H.; et al. StarWhisper Telescope: An AI framework for automating end-to-end astronomical observations.Commun. Eng.2025,4, 184. https://doi.org/10.1038/S44172-0 25-00520-4
-
[16]
Bellm, E.C.; Kulkarni, S.R.; Graham, M.J.; Dekany, R.; Smith, R.M.; Riddle, R.; Masci, F.J.; Helou, G.; Prince, T.A.; Adams, S.M.; et al. The Zwicky Transient Facility: System Overview, Performance, and First Results.Publ. Astron. Soc. Pac.2019,131, 018002. https://doi.org/10.1088/1538-3873/aaecbe
-
[17]
Patterson, M.T.; Bellm, E.C.; Rusholme, B.; Masci, F.J.; Juric, M.; Krughoff, K.S.; Golkhou, V .Z.; Graham, M.J.; Kulkarni, S.R.; Helou, G.; et al. The Zwicky Transient Facility Alert Distribution System.Publ. Astron. Soc. Pac.2019,131, 018001. https://doi.org/10.1088/1538-3873/aae904
-
[18]
Solving the Traveling Telescope Problem with Mixed-integer Linear Programming
Handley, L.B.; Petigura, E.A.; Miši´ c, V .V . Solving the Traveling Telescope Problem with Mixed-integer Linear Programming. Astron. J.2024,167, 33. https://doi.org/10.3847/1538-3881/ad0dfb
-
[19]
LUMOS: Linear programming Utility for Multi-messenger Optical Scheduling.arXiv2026, arXiv:2601.08912
Wagh, Y.P .; Coughlin, M.W.; Singer, L.P .; Bhalerao, V . LUMOS: Linear programming Utility for Multi-messenger Optical Scheduling.arXiv2026, arXiv:2601.08912. https://doi.org/10.48550/arXiv.2601.08912
-
[20]
An Integer Linear Programming Solution to the Telescope Network Scheduling Problem
Lampoudi, S.; Saunders, E.; Eastman, J. An Integer Linear Programming Solution to the Telescope Network Scheduling Problem. arXiv2015, arXiv:1503.07170. https://doi.org/10.48550/arXiv.1503.07170
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1503.07170
-
[21]
Visplot: A visibility plot and observation scheduling tool for astronomical observatories
Gafton, E.; Losada, I.R. Visplot: A visibility plot and observation scheduling tool for astronomical observatories.arXiv2026, arXiv:2604.14151. https://doi.org/10.48550/arXiv.2604.14151
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.14151
-
[22]
Team, Q. Qwen3 Technical Report.arXiv2025, arXiv:2505.09388. https://doi.org/10.48550/arXiv.2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388
-
[23]
Abdin, M.; Aneja, J.; Behl, H.; Bubeck, S.; Eldan, R.; Gunasekar, S.; Harrison, M.; Hewett, R.J.; Javaheripi, M.; Kauffmann, P .; et al. Phi-4 Technical Report.arXiv2024, arXiv:2412.08905. https://doi.org/10.48550/arXiv.2412.08905. Disclaimer/Publisher’s Note:The statements, opinions and data contained in all publications are solely those of the individua...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.08905
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.