SharQ: Bridging Activation Sparsity and FP4 Quantization for LLM Inference
Pith reviewed 2026-06-26 05:39 UTC · model grok-4.3
The pith
SharQ recovers 43-63 percent of the FP4 accuracy gap on LLMs by splitting activations into a quantized sparse backbone and a compensating dense residual
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
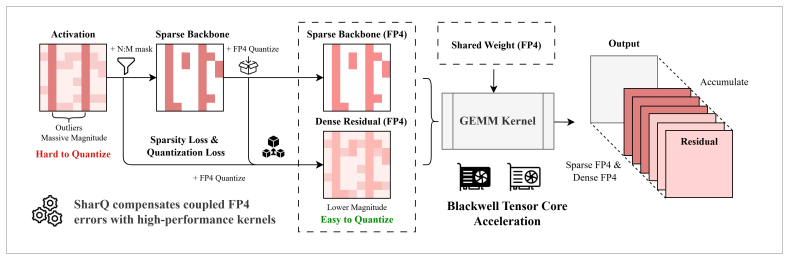
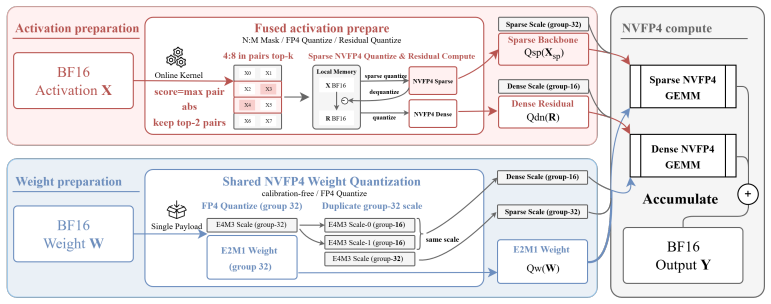
For each activation tensor, SharQ generates an input-adaptive N:M mask to extract an outlier-dominated sparse backbone, quantizes the backbone to FP4, and defines a dense residual relative to the quantized sparse backbone rather than the original values. A sparse FP4 GEMM handles the backbone while a dense FP4 GEMM compensates for both mask loss and quantization error; the paths share one FP4 weight payload with path-specific scales, and a fused preparation kernel absorbs mask generation, residual construction, and normalization.
What carries the argument
online sparse-dense decomposition that defines the dense residual relative to the quantized sparse backbone instead of the unquantized sparse values
If this is right
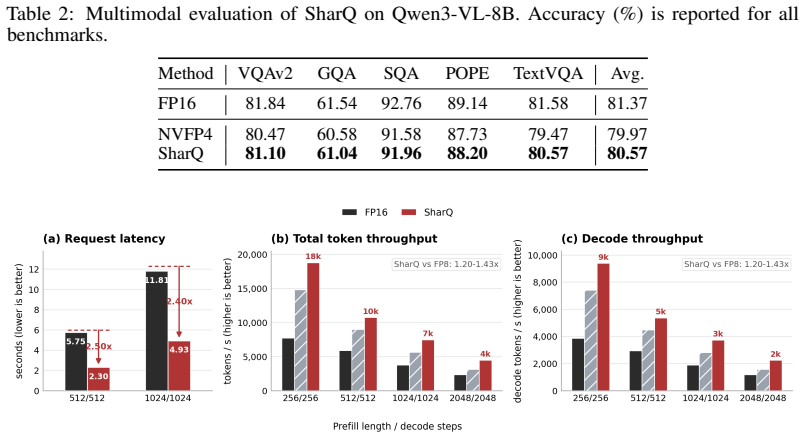
- The method recovers 43-63 percent of the accuracy gap between NVFP4 and FP16 across language and vision-language tasks on the tested models
- It delivers 2.2-2.4 times lower latency than FP16 and 1.2-1.4 times higher throughput than FP8 on RTX 5090 hardware
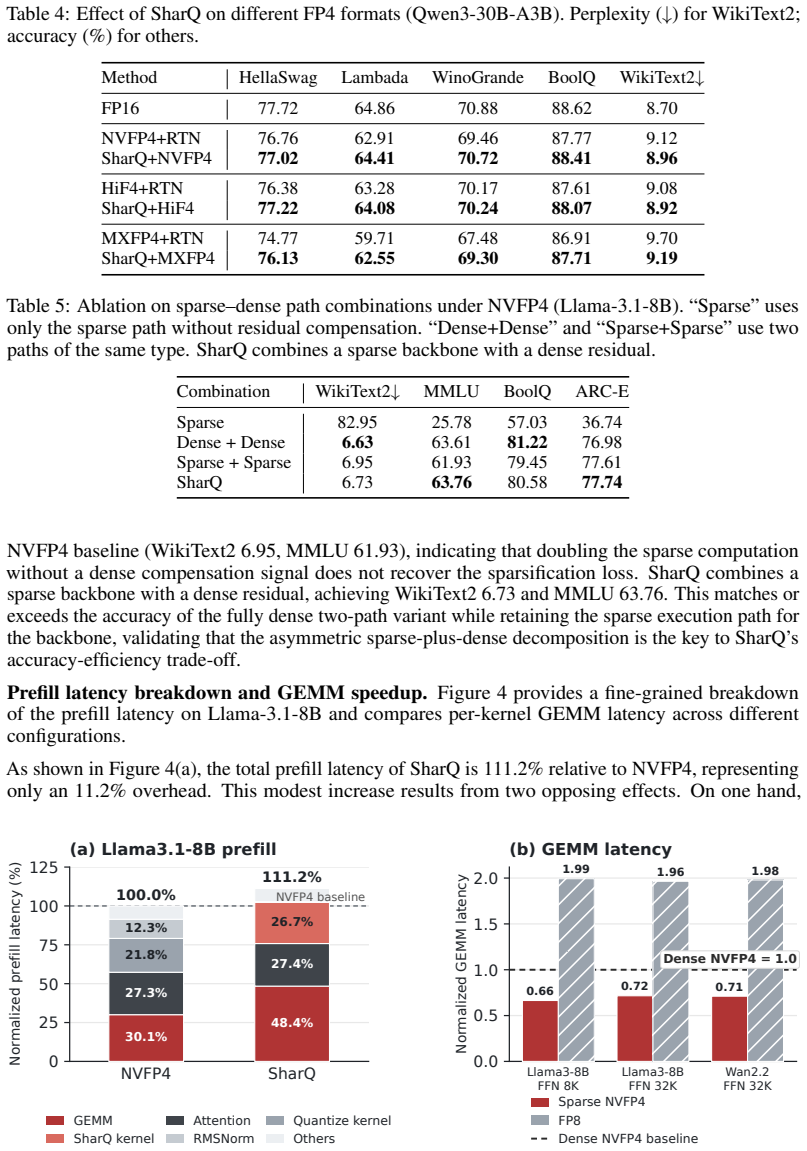
- The same decomposition works without changes across NVFP4, HiF4, and MXFP4 formats
- When combined with other attention optimizations it yields up to 1.58 times speedup on video generation workloads
Where Pith is reading between the lines
- The residual-against-quantized-values choice may generalize to other bit widths or sparsity ratios where direct masking hurts scale factors
- The fused kernel pattern could reduce overhead in pipelines that already combine sparsity with low-precision compute
- Testing the same split on training-time activations might reveal whether the decomposition reduces outlier sensitivity earlier in the pipeline
Load-bearing premise
The online generation of the input-adaptive N:M mask, construction of the dense residual relative to the quantized sparse backbone, and fused preparation kernel can be performed with negligible overhead and without model-specific tuning on the evaluated hardware and model families.
What would settle it
Measuring accuracy recovery and latency on the same models after disabling the fused kernel or after computing the residual against unquantized sparse values instead would show whether the claimed recovery range and speed gains depend on those exact steps.
Figures
read the original abstract
Low-bit floating-point formats and semi-structured sparsity are increasingly supported by modern accelerators, yet combining them for LLM activation compression remains challenging: activations contain input-dependent outliers that dominate block scales in FP4 quantization, and directly applying N:M sparsity masks discards moderate values, coupling sparsification loss with quantization error. We introduce SharQ, a training-free inference method that bridges activation sparsity and FP4 quantization through an online sparse--dense decomposition. For each activation tensor, SharQ generates an input-adaptive N:M mask to extract an outlier-dominated sparse backbone, quantizes it to FP4, and defines a dense residual relative to the quantized sparse backbone rather than the unquantized sparse values. A sparse FP4 GEMM processes the backbone while a dense FP4 GEMM compensates for both mask-induced activation loss and sparse-path quantization error. The two paths share a single FP4 weight payload with path-specific scale views, and a fused preparation kernel absorbs mask generation, residual construction, and layer normalization into one operator. SharQ requires no calibration data, retraining, or model-specific tuning. Evaluated on Llama-3.1-8B, Qwen2.5-7B, Qwen3-30B-A3B, and Qwen3-VL-8B, SharQ recovers 43--63% of the NVFP4-to-FP16 accuracy gap across language and vision-language tasks, and generalizes across NVFP4, HiF4, and MXFP4 formats. On an RTX 5090, SharQ delivers 2.2--2.4$\times$ latency reduction over FP16 and 1.2--1.4$\times$ throughput improvement over FP8 in language model serving, and up to 1.58$\times$ speedup on Wan2.2-T2V-A14B video generation when combined with SageAttention. Our code is available at https://github.com/actypedef/SharQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SharQ, a training-free method for LLM inference that combines N:M activation sparsity with FP4 quantization via an online input-adaptive sparse-dense decomposition: an N:M mask extracts an outlier-dominated sparse backbone quantized to FP4, while a dense residual (defined relative to the quantized sparse values) compensates mask and quantization errors using a second FP4 GEMM path. The two paths share a single FP4 weight payload with path-specific scales; a fused preparation kernel handles mask generation, residual construction, and layer norm. Evaluated on Llama-3.1-8B, Qwen2.5-7B, Qwen3-30B-A3B, and Qwen3-VL-8B, it recovers 43-63% of the NVFP4-to-FP16 accuracy gap across tasks and reports 2.2-2.4× latency reduction vs FP16 (plus 1.2-1.4× throughput vs FP8) on RTX 5090, with generalization to other FP4 formats and up to 1.58× speedup on video generation when combined with SageAttention.
Significance. If the overhead of the input-adaptive mask generation and fused kernel is truly negligible without model-specific tuning, and the accuracy recovery holds under the residual construction, SharQ would provide a practical way to exploit emerging hardware support for semi-structured sparsity and FP4 without retraining or calibration, improving the efficiency-accuracy frontier for both language and multimodal models.
major comments (3)
- [§4.3 and §5.3] §4.3 and §5.3 (latency evaluation): The 2.2-2.4× latency reduction claim over FP16 rests on the fused preparation kernel absorbing mask generation and residual construction with negligible cost, yet no per-component timing breakdown (e.g., mask selection time vs. the two GEMM paths) or scaling analysis with activation size is provided; without this, the net speedup cannot be verified against the stress-test concern that input-dependent N:M selection may not remain negligible.
- [§4.2] §4.2 (residual definition): The dense residual is constructed relative to the quantized sparse backbone rather than the unquantized sparse values, which is presented as compensating both mask loss and sparse-path quantization error, but no error analysis or bound is given showing why this choice yields the reported 43-63% gap recovery rather than simply adding a second quantization error term.
- [Table 2 and §5.1] Table 2 and §5.1 (ablation on mask adaptivity): The accuracy numbers are reported only for the full SharQ method; an ablation isolating the contribution of the input-adaptive N:M mask versus a static mask (or versus direct N:M on unquantized activations) is absent, making it impossible to confirm that adaptivity is load-bearing for the claimed recovery percentages.
minor comments (2)
- The abstract and §1 cite NVFP4, HiF4, and MXFP4 but the experimental tables do not explicitly label which format was used for each row; adding a column or footnote would improve clarity.
- Figure 3 (kernel diagram) uses abbreviations (e.g., 'SP-GEMM', 'DP-GEMM') without an accompanying legend in the caption; expanding the caption would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major point below, agreeing where additional evidence or clarification is needed and outlining the planned revisions.
read point-by-point responses
-
Referee: [§4.3 and §5.3] §4.3 and §5.3 (latency evaluation): The 2.2-2.4× latency reduction claim over FP16 rests on the fused preparation kernel absorbing mask generation and residual construction with negligible cost, yet no per-component timing breakdown (e.g., mask selection time vs. the two GEMM paths) or scaling analysis with activation size is provided; without this, the net speedup cannot be verified against the stress-test concern that input-dependent N:M selection may not remain negligible.
Authors: We agree that a per-component timing breakdown and scaling analysis would strengthen verification of the net speedup. In the revised version we will add detailed measurements separating mask generation, residual construction, and the two GEMM paths, together with scaling behavior across activation sizes on the evaluated hardware. revision: yes
-
Referee: [§4.2] §4.2 (residual definition): The dense residual is constructed relative to the quantized sparse backbone rather than the unquantized sparse values, which is presented as compensating both mask loss and sparse-path quantization error, but no error analysis or bound is given showing why this choice yields the reported 43-63% gap recovery rather than simply adding a second quantization error term.
Authors: The residual is defined after quantization so that the dense path directly offsets the combined mask and quantization error present in the sparse FP4 output. While the manuscript relies on empirical recovery rather than a formal bound, we will expand §4.2 with a short discussion of the motivation and why the chosen construction avoids simply accumulating an independent second quantization term. revision: partial
-
Referee: [Table 2 and §5.1] Table 2 and §5.1 (ablation on mask adaptivity): The accuracy numbers are reported only for the full SharQ method; an ablation isolating the contribution of the input-adaptive N:M mask versus a static mask (or versus direct N:M on unquantized activations) is absent, making it impossible to confirm that adaptivity is load-bearing for the claimed recovery percentages.
Authors: We acknowledge the value of isolating the adaptivity contribution. We will add the requested ablation (adaptive N:M versus static mask and versus direct N:M on unquantized activations) to Table 2 or a new table in §5.1 of the revised manuscript. revision: yes
Circularity Check
No circularity: empirical algorithmic method with no derivations or fitted predictions
full rationale
The paper describes a training-free inference algorithm (online N:M mask generation, sparse-dense decomposition, fused kernel) evaluated empirically on specific models and hardware. No mathematical derivation chain, first-principles predictions, parameter fitting, or self-citation load-bearing steps are present in the provided text. All performance claims (accuracy gap recovery, latency reductions) are direct experimental measurements rather than reductions to inputs by construction. This matches the default expectation of no significant circularity for non-derivational papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated LLM s. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=dfqsW38v1X
2024
-
[3]
Piqa: Reasoning about physical commonsense in natural language, 2019
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language, 2019. URL https://arxiv.org/abs/1911.11641
Pith/arXiv arXiv 2019
-
[4]
Oscillation-reduced mxfp4 training for vision transformers, 2025
Yuxiang Chen, Haocheng Xi, Jun Zhu, and Jianfei Chen. Oscillation-reduced mxfp4 training for vision transformers, 2025. URL https://arxiv.org/abs/2502.20853
arXiv 2025
-
[7]
OCP Microscaling (MX) Specification
Bita Darvish Rouhani, Nitin Garegrat, Tom Savell, Ankit More, Kyung-Nam Han, Mathew Zhao, Ritchie amd Hall, Jasmine Klar, Eric Chung, Yuan Yu, Michael Schulte, Ralph Wittig, Ian Bratt, Nigel Stephens, Jelena Milanovic, John Brothers, Pradeep Dubey, Marius Cornea, Alexander Heinecke, Andres Rodriguez, Martin Langhammer, Summer Deng, Maxim Naumov, Paulius M...
2023
-
[8]
Microscaling data formats for deep learning, 2023 b
Bita Darvish Rouhani, Ritchie Zhao, Ankit More, Mathew Hall, Alireza Khodamoradi, Summer Deng, Dhruv Choudhary, Marius Cornea, Eric Dellinger, Kristof Denolf, Stosic Dusan, Venmugil Elango, Maximilian Golub, Alexander Heinecke, Phil James-Roxby, Dharmesh Jani, Gaurav Kolhe, Martin Langhammer, Ada Li, Levi Melnick, Maral Mesmakhosroshahi, Andres Rodriguez,...
arXiv 2023
-
[9]
Llm.int8(): 8-bit matrix multiplication for transformers at scale, 2022
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Llm.int8(): 8-bit matrix multiplication for transformers at scale, 2022. URL https://arxiv.org/abs/2208.07339
Pith/arXiv arXiv 2022
-
[11]
S parse GPT : Massive language models can be accurately pruned in one-shot
Elias Frantar and Dan Alistarh. S parse GPT : Massive language models can be accurately pruned in one-shot. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 1...
2023
-
[12]
Gptq: Accurate post-training quantization for generative pre-trained transformers, 2023
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers, 2023. URL https://arxiv.org/abs/2210.17323
Pith/arXiv arXiv 2023
-
[13]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac'h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
arXiv 2024
-
[14]
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering, 2017. URL https://arxiv.org/abs/1612.00837
Pith/arXiv arXiv 2017
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, and et al. Akhil Mathur. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[16]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[17]
Coleman Hooper, Charbel Sakr, Ben Keller, Rangharajan Venkatesan, Kurt Keutzer, Sophia Shao, and Brucek Khailany. Fgmp: Fine-grained mixed-precision weight and activation quantization for hardware-accelerated llm inference, 2025. URL https://arxiv.org/abs/2504.14152
arXiv 2025
-
[18]
OSTQ uant: Refining large language model quantization with orthogonal and scaling transformations for better distribution fitting
Xing Hu, Yuan Cheng, Dawei Yang, Zhixuan Chen, Zukang Xu, JiangyongYu, XUCHEN, Zhihang Yuan, Zhe jiang, and Sifan Zhou. OSTQ uant: Refining large language model quantization with orthogonal and scaling transformations for better distribution fitting. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/f...
2025
-
[19]
Drew A. Hudson and Christopher D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering, 2019. URL https://arxiv.org/abs/1902.09506
Pith/arXiv arXiv 2019
-
[20]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[21]
Janghwan Lee, Jiwoong Park, Jinseok Kim, Yongjik Kim, Jungju Oh, Jinwook Oh, and Jungwook Choi. Amxfp4: Taming activation outliers with asymmetric microscaling floating-point for 4-bit llm inference, 2025. URL https://arxiv.org/abs/2411.09909
arXiv 2025
-
[23]
Evaluating object hallucination in large vision-language models, 2023
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models, 2023. URL https://arxiv.org/abs/2305.10355
Pith/arXiv arXiv 2023
-
[24]
Duquant++: Fine-grained rotation enhances microscaling fp4 quantization
Haokun Lin, Xinle Jia, Haobo Xu, Bingchen Yao, Xianglong Guo, Yichen Wu, Zhichao Lu, Ying Wei, Qingfu Zhang, and Zhenan Sun. Duquant++: Fine-grained rotation enhances microscaling fp4 quantization. 2026. URL https://api.semanticscholar.org/CorpusID:287634207
2026
-
[25]
Awq: Activation-aware weight quantization for llm compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration. In MLSys, 2024
2024
-
[27]
Spinquant: Llm quantization with learned rotations, 2024
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: Llm quantization with learned rotations, 2024. URL https://arxiv.org/abs/2405.16406
Pith/arXiv arXiv 2024
-
[28]
Deja vu: Contextual sparsity for efficient llms at inference time
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pages 22137--22176. PMLR, 2023
2023
-
[29]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In The 36th Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[33]
Nvidia blackwell architecture technical brief, 2024
Nvidia. Nvidia blackwell architecture technical brief, 2024. URL https://resources.nvidia.com/en-us-blackwell-architecture
2024
-
[34]
cuDNN Frontend API v1.14.0: Block-Scaling Operation
NVIDIA Corporation . cuDNN Frontend API v1.14.0: Block-Scaling Operation . https://docs.nvidia.com/deeplearning/cudnn/frontend/v1.14.0/operations/BlockScaling.html, 2024 a . Accessed: 2025-09-16
2024
-
[35]
PTX: Parallel Thread Execution, ISA Version 8.4
NVIDIA Corporation . PTX: Parallel Thread Execution, ISA Version 8.4 . https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#tcgen05-mma-instructions, 2024 b . Accessed: 2025-09-16
2024
-
[36]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germ\' a n Kruszewski, Angeliki Lazaridou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernandez. The LAMBADA dataset: Word prediction requiring a broad discourse context. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages ...
2016
-
[37]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
Pith/arXiv arXiv 2025
-
[38]
Winogrande: An adversarial winograd schema challenge at scale, 2019
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale, 2019. URL https://arxiv.org/abs/1907.10641
Pith/arXiv arXiv 2019
-
[39]
Resq: Mixed-precision quantization of large language models with low-rank residuals, 2025
Utkarsh Saxena, Sayeh Sharify, Kaushik Roy, and Xin Wang. Resq: Mixed-precision quantization of large language models with low-rank residuals, 2025. URL https://arxiv.org/abs/2412.14363
arXiv 2025
-
[40]
Omniquant: Omnidirectionally calibrated quantization for large language models, 2024
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models, 2024. URL https://arxiv.org/abs/2308.13137
arXiv 2024
-
[42]
Towards vqa models that can read, 2019
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read, 2019. URL https://arxiv.org/abs/1904.08920
Pith/arXiv arXiv 2019
-
[43]
Powerinfer: Fast large language model serving with a consumer-grade gpu
Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. Powerinfer: Fast large language model serving with a consumer-grade gpu. In Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles, pages 590--606, 2024
2024
-
[45]
Mingjie Sun, Xinlei Chen, J. Zico Kolter, and Zhuang Liu. Massive activations in large language models, 2024 b . URL https://arxiv.org/abs/2402.17762
Pith/arXiv arXiv 2024
-
[46]
A simple and effective pruning approach for large language models
Mingjie Sun, Zhuang Liu, Anna Bair, and Zico Kolter. A simple and effective pruning approach for large language models. In International Conference on Learning Representations, volume 2024, pages 4942--4964, 2024 c
2024
-
[47]
Flatquant: Flatness matters for LLM quantization
Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, Jiaxin Hu, Xianzhi Yu, Lu Hou, Chun Yuan, Xin Jiang, Wulong Liu, and Jun Yao. Flatquant: Flatness matters for LLM quantization. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste - Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors, Forty-second Internatio...
2025
-
[49]
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution, 2024
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution, 2024. URL https://arxiv.org/abs/2409.12191
Pith/arXiv arXiv 2024
-
[50]
Smoothquant: Accurate and efficient post-training quantization for large language models, 2024
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models, 2024. URL https://arxiv.org/abs/2211.10438
arXiv 2024
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Dayiheng Liu, Fan Zhou, Fei Huang, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Z...
Pith/arXiv arXiv 2025
-
[53]
Jintao Zhang, Haofeng Huang, Pengle Zhang, Jia Wei, Jun Zhu, and Jianfei Chen. Sageattention2: Efficient attention with thorough outlier smoothing and per-thread int4 quantization, 2025. URL https://arxiv.org/abs/2411.10958
arXiv 2025
-
[54]
Atom: Low-bit quantization for efficient and accurate llm serving
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. Atom: Low-bit quantization for efficient and accurate llm serving. In P. Gibbons, G. Pekhimenko, and C. De Sa, editors, Proceedings of Machine Learning and Systems, volume 6, pages 196--209, 2024. URL https://proceedings.m...
2024
-
[55]
2016 , eprint=
Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures , author=. 2016 , eprint=
2016
-
[56]
2024 , url=
Q-VLM: Post-training Quantization for Large Vision-Language Models , author=. 2024 , url=
2024
-
[57]
MLSys , year=
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration , author=. MLSys , year=
-
[58]
2024 , eprint=
CrossQuant: A Post-Training Quantization Method with Smaller Quantization Kernel for Precise Large Language Model Compression , author=. 2024 , eprint=
2024
-
[59]
2023 , eprint=
Matrix Compression via Randomized Low Rank and Low Precision Factorization , author=. 2023 , eprint=
2023
-
[60]
The Twelfth International Conference on Learning Representations , year=
The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction , author=. The Twelfth International Conference on Learning Representations , year=
-
[61]
2024 , eprint=
ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models , author=. 2024 , eprint=
2024
-
[62]
2023 , editor =
Frantar, Elias and Alistarh, Dan , booktitle =. 2023 , editor =
2023
-
[63]
2023 , eprint=
Optimal Brain Compression: A Framework for Accurate Post-Training Quantization and Pruning , author=. 2023 , eprint=
2023
-
[64]
2021 , eprint=
Post-Training Quantization for Vision Transformer , author=. 2021 , eprint=
2021
-
[65]
2023 , eprint=
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers , author=. 2023 , eprint=
2023
-
[66]
arXiv preprint arXiv:2305.14314 , year=
QLoRA: Efficient Finetuning of Quantized LLMs , author=. arXiv preprint arXiv:2305.14314 , year=
-
[67]
2024 , eprint=
SqueezeLLM: Dense-and-Sparse Quantization , author=. 2024 , eprint=
2024
-
[68]
2024 , eprint=
OneBit: Towards Extremely Low-bit Large Language Models , author=. 2024 , eprint=
2024
-
[69]
Rajarshi Saha, Varun Srivastava and Mert Pilanci , booktitle=
-
[70]
2023 , eprint=
The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction , author=. 2023 , eprint=
2023
-
[71]
arXiv preprint arXiv:2406.01721 , year=
DuQuant: Distributing Outliers via Dual Transformation Makes Stronger Quantized LLMs , author=. arXiv preprint arXiv:2406.01721 , year=
-
[72]
2024 , eprint=
Massive Activations in Large Language Models , author=. 2024 , eprint=
2024
-
[73]
2022 , eprint=
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale , author=. 2022 , eprint=
2022
-
[74]
2024 , eprint=
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models , author=. 2024 , eprint=
2024
-
[75]
Atom: Low-Bit Quantization for Efficient and Accurate LLM Serving , url =
Zhao, Yilong and Lin, Chien-Yu and Zhu, Kan and Ye, Zihao and Chen, Lequn and Zheng, Size and Ceze, Luis and Krishnamurthy, Arvind and Chen, Tianqi and Kasikci, Baris , booktitle =. Atom: Low-Bit Quantization for Efficient and Accurate LLM Serving , url =
-
[76]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[77]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[78]
2024 , eprint=
Phi-4 Technical Report , author=. 2024 , eprint=
2024
-
[79]
arXiv preprint arXiv:2309.15531 , year=
Rethinking channel dimensions to isolate outliers for low-bit weight quantization of large language models , author=. arXiv preprint arXiv:2309.15531 , year=
-
[80]
2024 , howpublished =
Ministral-8B-Instruct-2410 , author =. 2024 , howpublished =
2024
-
[81]
2024 , howpublished =
2024
-
[82]
arXiv preprint arXiv:1905.07830 , year=
Hellaswag: Can a machine really finish your sentence? , author=. arXiv preprint arXiv:1905.07830 , year=
Pith/arXiv arXiv 1905
-
[83]
arXiv preprint arXiv:2403.12544 , year=
Affinequant: Affine transformation quantization for large language models , author=. arXiv preprint arXiv:2403.12544 , year=
-
[84]
FlatQuant: Flatness Matters for
Yuxuan Sun and Ruikang Liu and Haoli Bai and Han Bao and Kang Zhao and Yuening Li and Jiaxin Hu and Xianzhi Yu and Lu Hou and Chun Yuan and Xin Jiang and Wulong Liu and Jun Yao , editor =. FlatQuant: Flatness Matters for. Forty-second International Conference on Machine Learning,. 2025 , url =
2025
-
[85]
Stephen Merity and Caiming Xiong and James Bradbury and Richard Socher , title =. CoRR , volume =. 2016 , url =. 1609.07843 , timestamp =
Pith/arXiv arXiv 2016
-
[86]
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. CoRR , volume =. 2019 , url =. 1910.10683 , timestamp =
Pith/arXiv arXiv 2019
-
[87]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[88]
Paperno, Denis and Kruszewski, Germ\'. The. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =. 2016 , address =
2016
-
[89]
2019 , eprint=
PIQA: Reasoning about Physical Commonsense in Natural Language , author=. 2019 , eprint=
2019
-
[90]
2019 , eprint=
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions , author=. 2019 , eprint=
2019
-
[91]
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. arXiv:1803.05457v1 , year =
-
[92]
2019 , eprint=
WinoGrande: An Adversarial Winograd Schema Challenge at Scale , author=. 2019 , eprint=
2019
-
[93]
arXiv preprint arXiv:2210.09261 , year=
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them , author=. arXiv preprint arXiv:2210.09261 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.