Generating Special Triangulations with Transformers
Pith reviewed 2026-06-26 03:24 UTC · model grok-4.3
The pith
Transformers with an appropriate encoding scheme can generate new representative FRSTs of 4D reflexive polytopes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
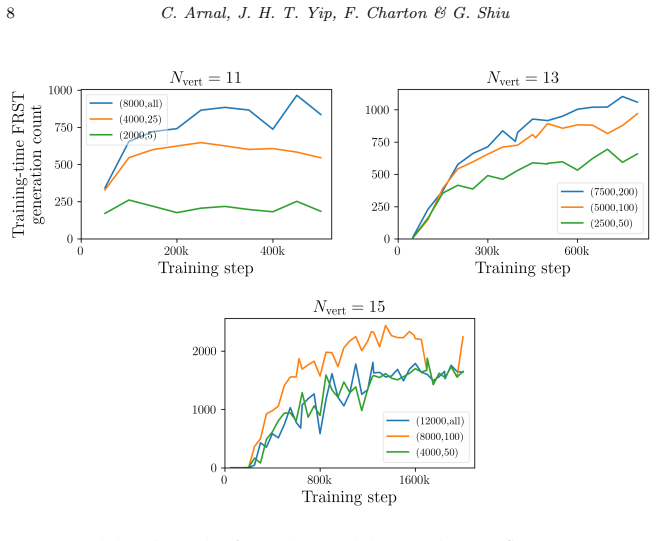
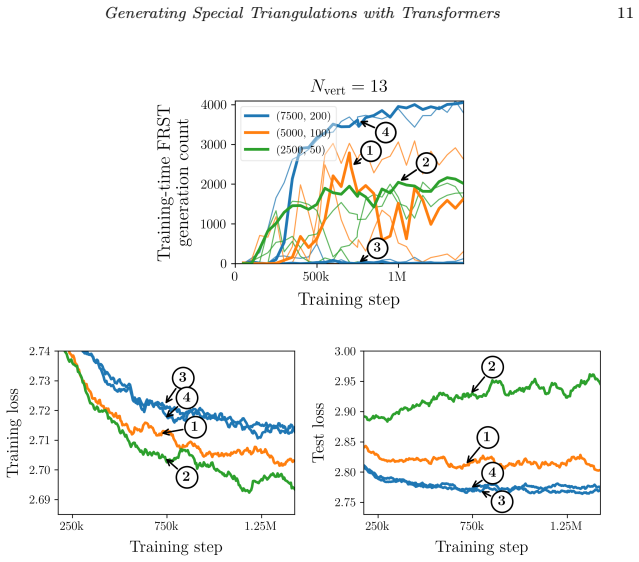
Transformers equipped with an appropriate encoding scheme can be effectively trained to representatively generate new FRSTs across a range of polytope sizes. Moreover, these models can also self-improve through retraining on their own output.
What carries the argument
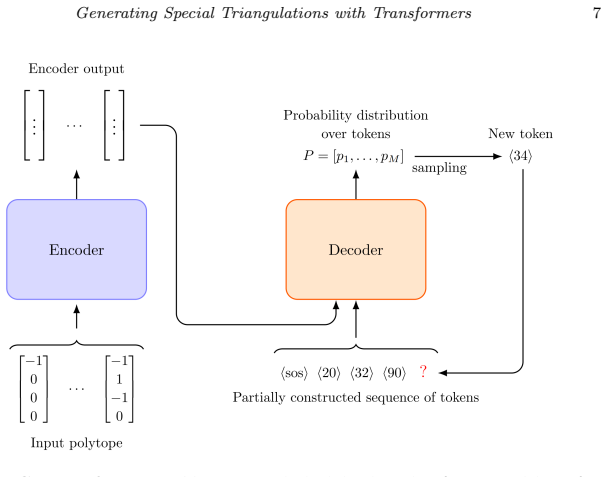
Transformer architecture combined with a custom encoding scheme that converts triangulations into sequences the model can learn and sample from.
If this is right
- New FRSTs become available for polytopes of sizes where exhaustive search is infeasible.
- Retraining on model outputs yields measurable improvement in generation quality.
- The method supplies concrete input for classifying Calabi-Yau threefolds arising from these triangulations.
- Similar techniques become feasible for related problems in combinatorics and algebraic geometry.
Where Pith is reading between the lines
- The same encoding idea could be tested on generating other discrete geometric objects such as lattice polytopes or graphs.
- Combining the generator with downstream validation networks might increase the fraction of immediately usable outputs.
- If the self-improvement loop continues without external data, the approach could reach regimes far beyond current enumerated databases.
Load-bearing premise
An encoding scheme exists that enables the transformer to learn and output valid, representative FRSTs rather than invalid or biased ones.
What would settle it
For a small reflexive polytope with a known complete list of FRSTs, sample many outputs from the trained model and check whether their distribution statistically matches the known enumeration rather than producing mostly duplicates or invalids.
Figures
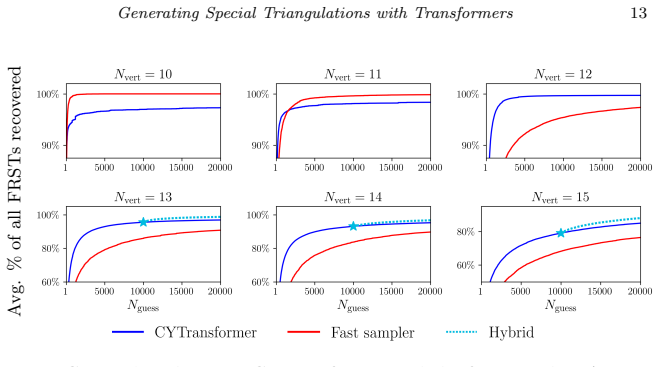
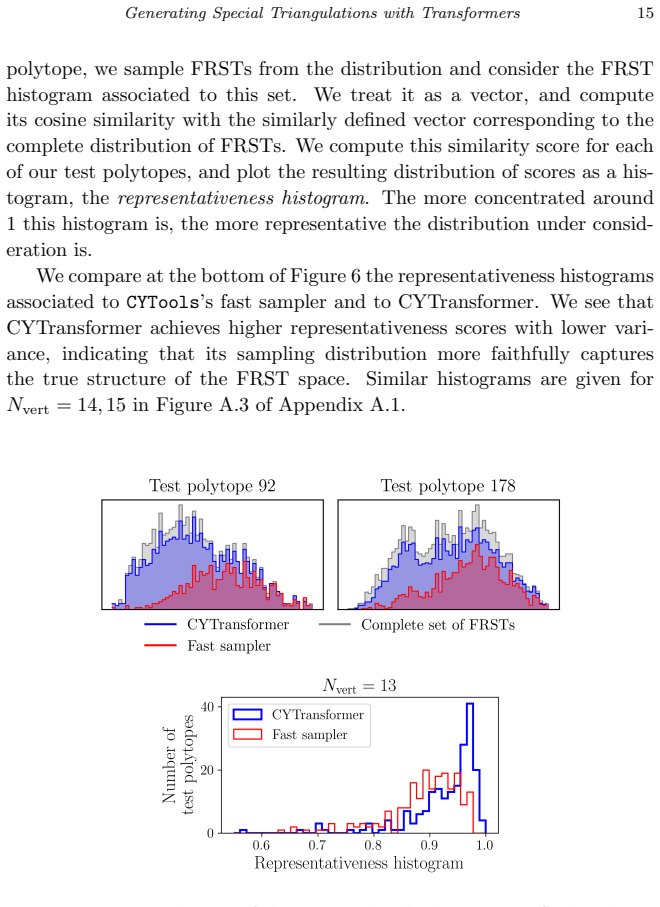

read the original abstract
Triangulations, i.e., well-structured decompositions of geometric objects into triangle-like pieces, are central objects in many domains of mathematics and physics. In particular, fine, regular, and star triangulations (FRSTs) of 4D reflexive polytopes give rise to smooth Calabi-Yau threefolds, which are of significant interest in string theory. However, the high dimensionality and combinatorial complexity of triangulations make them particularly challenging to model with classical numerical methods or machine learning. In this work, we show that transformers, equipped with an appropriate encoding scheme, can be effectively trained to representatively generate new FRSTs across a range of polytope sizes. Moreover, these models can also self-improve through retraining on their own output. This opens the door to both concrete applications to the classification of Calabi-Yau manifolds and further research in physics, combinatorics and algebraic geometry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that transformers equipped with an appropriate encoding scheme can be trained to generate representative new fine regular star triangulations (FRSTs) of 4D reflexive polytopes across a range of sizes, and that these models can self-improve by retraining on their own generated outputs. This is presented as enabling applications to the classification of Calabi-Yau threefolds.
Significance. If the empirical claims hold with rigorous validation, the work would offer a scalable ML-based alternative to combinatorial enumeration of FRSTs, which is computationally intensive; the self-improvement loop could be a notable contribution if shown to increase validity or diversity without external data.
major comments (2)
- Abstract: the central empirical claims of effectiveness and self-improvement are asserted without any reported metrics (e.g., validity rate, diversity measure, or comparison to baselines such as random or MCMC sampling of triangulations), validation procedures, or error analysis; this is load-bearing because the paper frames its contribution as a demonstrated capability rather than a theoretical derivation.
- No section or equation is provided that defines the encoding scheme, the training objective, or the self-training procedure; without these, it is impossible to assess whether the encoding avoids trivial invalid outputs or whether self-improvement is non-circular.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important gaps in the presentation of empirical results and methodological details. We agree that both issues require substantial revision and will address them by adding the requested metrics, validation procedures, and formal definitions in a revised manuscript.
read point-by-point responses
-
Referee: Abstract: the central empirical claims of effectiveness and self-improvement are asserted without any reported metrics (e.g., validity rate, diversity measure, or comparison to baselines such as random or MCMC sampling of triangulations), validation procedures, or error analysis; this is load-bearing because the paper frames its contribution as a demonstrated capability rather than a theoretical derivation.
Authors: We agree that the abstract and main text currently lack quantitative support for the claimed effectiveness and self-improvement. In the revision we will report validity rates, diversity measures (e.g., number of distinct FRSTs generated per polytope size), and direct comparisons against random sampling and MCMC baselines. We will also include a dedicated subsection on validation procedures, error analysis, and statistical significance of the self-improvement loop. revision: yes
-
Referee: No section or equation is provided that defines the encoding scheme, the training objective, or the self-training procedure; without these, it is impossible to assess whether the encoding avoids trivial invalid outputs or whether self-improvement is non-circular.
Authors: We acknowledge that the current manuscript does not contain an explicit section or equations defining the encoding scheme, loss function, or the self-training (retraining-on-generated-data) procedure. In the revised version we will add a new Methods section that formally specifies the tokenization/encoding of triangulations, the autoregressive training objective, the precise self-improvement protocol (including how generated samples are filtered and re-used), and any safeguards against trivial or circular outputs. revision: yes
Circularity Check
No significant circularity; empirical demonstration only
full rationale
The paper makes no deductive claims or derivations. Its central statements are that transformers with a suitable encoding can be trained to generate valid FRSTs and that retraining on model outputs improves performance. These are presented as empirical outcomes of standard ML training and evaluation pipelines, with no equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the result to its own inputs. The encoding scheme is treated as an experimental choice whose effectiveness is verified by results, not assumed by definition. No steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. H. T. Yip, C. Arnal, F. Charton, and G. Shiu, Transforming Calabi-Yau Constructions: Generating New Calabi-Yau Manifolds with Transformers, arXiv:2507.03732URLhttps://arxiv.org/abs/2507.03732
-
[2]
T. N. Kipf and M. Welling. Semi-supervised classification with graph convo- lutional networks (2016)
2016
-
[3]
W. L. Hamilton, R. Ying, and J. Leskovec. Inductive representation learning on large graphs (2017)
2017
-
[4]
Veliˇ ckovi´ c, G
P. Veliˇ ckovi´ c, G. Cucurull, A. Casanova, A. Romero, P. Li` o, and Y. Bengio. Graph attention networks (2017)
2017
-
[5]
B. Perozzi, R. Al-Rfou, and S. Skiena. Deepwalk: online learning of so- cial representations. InProceedings of the 20th ACM SIGKDD interna- tional conference on Knowledge discovery and data mining, KDD ’14, p. 701–710, ACM (Aug., 2014). doi: 10.1145/2623330.2623732. URLhttp: //dx.doi.org/10.1145/2623330.2623732
-
[6]
Grover and J
A. Grover and J. Leskovec. node2vec: Scalable feature learning for networks (2016)
2016
-
[7]
Gilmer, S
J. Gilmer, S. S. Schoenholz, P. F. Riley, O. Vinyals, and G. E. Dahl. Neural message passing for quantum chemistry (2017)
2017
-
[8]
J. Zhou, G. Cui, S. Hu, Z. Zhang, C. Yang, Z. Liu, L. Wang, C. Li, and M. Sun. Graph neural networks: A review of methods and applications (2018)
2018
-
[9]
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu, A compre- hensive survey on graph neural networks,IEEE Transactions on Neural Networks and Learning Systems.32(1), 4–24 (Jan., 2021). ISSN 2162-2388. doi: 10.1109/tnnls.2020.2978386. URLhttp://dx.doi.org/10.1109/TNNLS. 2020.2978386
-
[10]
Sharp and M
N. Sharp and M. Ovsjanikov. Pointtrinet: Learned triangulation of 3d point sets (2020)
2020
-
[11]
H. Lei, R. Leng, L. Zheng, and H. Li. Circnet: Meshing 3d point clouds with circumcenter detection (2023)
2023
- [12]
-
[13]
W. D. Neumann,Combinatorics of Triangulations and the Chern-Simons Invariant for Hyperbolic 3-Manifolds, In eds. B. Apanasov, W. D. Neu- mann, A. W. Reid, and L. Siebenmann,Topology ’90, pp. 243–272. De Gruyter, Berlin, Boston (1992). ISBN 9783110857726. doi: doi:10.1515/ 9783110857726.243. URLhttps://doi.org/10.1515/9783110857726.243
-
[14]
Lackenby, Taut ideal triangulations of 3-manifolds.,Geometry and Topol- ogy.4, 369–395 (2000)
M. Lackenby, Taut ideal triangulations of 3-manifolds.,Geometry and Topol- ogy.4, 369–395 (2000). URLhttp://eudml.org/doc/120886
2000
-
[15]
K. Husz´ ar, J. Spreer, and U. Wagner, On the treewidth of triangulated 3- manifolds,Journal of Computational Geometry. p. Vol. 10 No. 2 (2019): Spe- cial Issue of Selected Papers from SoCG 2018 (2019). doi: 10.20382/JOCG. V10I2A5. URLhttps://jocg.org/index.php/jocg/article/view/3088. Generating Special Triangulations with Transformers23
-
[16]
Itenberg and O
I. Itenberg and O. Viro, Patchworking algebraic curves disproves the ragsdale conjecture,The Mathematical Intelligencer.18, 19–28 (01, 1996). doi: 10. 1007/BF03026748
1996
-
[17]
O. Viro. Patchworking real algebraic varieties. URLhttps://arxiv.org/ abs/math/0611382(2006)
Pith/arXiv arXiv 2006
-
[18]
C. Arnal, Patchworking real algebraic hypersurfaces with asymptotically large betti numbers,Journal of Topology.15(3), 1154–1216 (June, 2022). ISSN 1753-8424. doi: 10.1112/topo.12251. URLhttp://dx.doi.org/10. 1112/topo.12251
-
[19]
Chazal and B
F. Chazal and B. Michel, An introduction to topological data analysis: Fun- damental and practical aspects for data scientists,Frontiers in Artificial In- telligence.4(2017)
2017
-
[20]
Carlsson and M
G. Carlsson and M. Vejdemo-Johansson,Topological Data Analysis with Ap- plications. Cambridge University Press (2021)
2021
-
[21]
V. V. Batyrev, Dual polyhedra and mirror symmetry for Calabi-Yau hyper- surfaces in toric varieties,J. Alg. Geom.3, 493–545 (1994)
1994
-
[22]
M. Kreuzer, Strings on calabi—yau spaces and toric geometry,Nuclear Physics B - Proceedings Supplements.102–103, 87–93 (Sept., 2001). ISSN 0920-5632. doi: 10.1016/s0920-5632(01)01541-9. URLhttp://dx.doi.org/ 10.1016/S0920-5632(01)01541-9
-
[23]
R. Altman, J. Gray, Y.-H. He, V. Jejjala, and B. D. Nelson, A Calabi-Yau Database: Threefolds Constructed from the Kreuzer-Skarke List,JHEP.02, 158 (2015). doi: 10.1007/JHEP02(2015)158
-
[24]
A. Z. Wagner. Constructions in combinatorics via neural networks. URL https://arxiv.org/abs/2104.14516(2021)
arXiv 2021
-
[25]
A. Novikov, N. V˜ u, M. Eisenberger, E. Dupont, P.-S. Huang, A. Z. Wagner, S. Shirobokov, B. Kozlovskii, F. J. R. Ruiz, A. Mehrabian, M. P. Kumar, A. See, S. Chaudhuri, G. Holland, A. Davies, S. Nowozin, P. Kohli, and M. Balog. Alphaevolve: A coding agent for scientific and algorithmic discov- ery. URLhttps://arxiv.org/abs/2506.13131(2025)
Pith/arXiv arXiv 2025
-
[26]
P. Candelas, G. T. Horowitz, A. Strominger, and E. Witten, Vacuum configurations for superstrings,Nucl. Phys. B.258, 46–74 (1985). doi: 10.1016/0550-3213(85)90602-9
-
[27]
F. Marchesano, G. Shiu, and T. Weigand, The Standard Model from String Theory: What Have We Learned?,Ann. Rev. Nucl. Part. Sci.74, 113–140 (2024). doi: 10.1146/annurev-nucl-102622-012235
-
[28]
Kreuzer and H
M. Kreuzer and H. Skarke, Complete classification of reflexive polyhedra in four-dimensions,Adv. Theor. Math. Phys.4, 1209–1230 (2000). doi: 10.4310/ ATMP.2000.v4.n6.a2
2000
-
[29]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention Is All You Need. In31st International Conference on Neural Information Processing Systems(6, 2017)
2017
-
[30]
J. A. De Loera, J. Rambau, and F. Santos,Triangulations: Structures for Algorithms and Applications, 1st edn. Springer Publishing Company, Incor- porated (2010). ISBN 3642129706
2010
-
[31]
M. Demirtas, L. McAllister, and A. Rios-Tascon, Bounding the Kreuzer- 24C. Arnal, J. H. T. Yip, F. Charton & G. Shiu Skarke Landscape,Fortsch. Phys.68, 2000086 (2020). doi: 10.1002/prop. 202000086
-
[32]
MacFadden, A
N. MacFadden, A. Schachner, and E. Sheridan, The DNA of Calabi-Yau Hypersurfaces (5, 2024)
2024
-
[33]
P. Berglund, G. Butbaia, Y.-H. He, E. Heyes, E. Hirst, and V. Jejjala, Gen- erating triangulations and fibrations with reinforcement learning,Phys. Lett. B.860, 139158 (2025). doi: 10.1016/j.physletb.2024.139158
-
[34]
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi` ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, Llama: Open and efficient foundation language models,ArXiv.abs/2302.13971(2023). URLhttps://api. semanticscholar.org/CorpusID:257219404
Pith/arXiv arXiv 2023
-
[35]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de Las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, Mistral 7b,ArXiv.abs/2310.06825(2023). URLhttps: //api.semanticscholar.org/CorpusID:263830494
Pith/arXiv arXiv 2023
-
[36]
O. J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Ale- man, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, R. Avila, I. Babuschkin, S. Balaji, V. Balcom, P. Baltescu, H. ing Bao, M. Bavarian, J. Belgum, I. Bello, J. Berdine, G. Bernadett-Shapiro, C. Berner, L. Bog- donoff, O. Boiko, M. laine Boyd, A.-L. Brakman, G. Brockman, T. Brooks, M...
2023
-
[37]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, and Z. Zhao, The llama 3 herd of models,ArXiv.arXiv.2407.21783(2024)
Pith/arXiv arXiv 2024
-
[38]
Nature625, 7995 (01 Jan 2024), 468–475
B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. Kumar, E. Dupont, F. Ruiz, J. Ellenberg, P. Wang, O. Fawzi, P. Kohli, and A. Fawzi, Mathematical discoveries from program search with large language models, Nature.625(12, 2023). doi: 10.1038/s41586-023-06924-6
-
[39]
F. Charton, J. S. Ellenberg, A. Z. Wagner, and G. Williamson, Pattern- boost: Constructions in mathematics with a little help from ai,arXiv preprint arXiv:2411.00566(2024)
arXiv 2024
-
[40]
A. Alfarano, F. Charton, and A. Hayat, Global lyapunov functions: a long-standing open problem in mathematics, with symbolic transformers, 10.48550/arXiv.2410.08304(2024)
-
[41]
B. Hashemi, R. G. Corominas, and A. Giacchetto. Can transformers do enu- merative geometry? URLhttps://arxiv.org/abs/2408.14915(2025)
arXiv 2025
-
[42]
N. D. Geneva and N. Zabaras, Transformers for modeling physical systems, Neural networks : the official journal of the International Neural Network Society.146, 272–289 (2020). URLhttps://api.semanticscholar.org/ CorpusID:222208767
2020
- [43]
-
[44]
T. Cai, G. W. Merz, F. Charton, N. Nolte, M. Wilhelm, K. Cranmer, and L. J. Dixon, Transforming the bootstrap: using transformers to compute scat- tering amplitudes in planarN= 4 super Yang–Mills theory,Mach. Learn. Sci. Tech.5(3), 035073 (2024). doi: 10.1088/2632-2153/ad743e
-
[45]
A. Dersy, M. Schwartz, and A. Zhiboedov, Reconstructing s-matrix phases 26C. Arnal, J. H. T. Yip, F. Charton & G. Shiu with machine learning,Journal of High Energy Physics.2024(05, 2024). doi: 10.1007/JHEP05(2024)200
-
[46]
Jumper, R
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Figurnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. ˇZ´ ıdek, A. Potapenko, et al., Highly accu- rate protein structure prediction with alphafold,nature.596(7873), 583–589 (2021)
2021
-
[47]
C. Olsson, N. Elhage, N. Nanda, N. Joseph, N. DasSarma, T. Henighan, B. Mann, A. Askell, Y. Bai, A. Chen, et al., In-context learning and induction heads,arXiv preprint arXiv:2209.11895(2022)
Pith/arXiv arXiv 2022
-
[48]
Cabannes, C
V. Cabannes, C. Arnal, W. Bouaziz, A. Yang, F. Charton, and J. Kempe. Iteration head: a mechanistic study of chain-of-thought. InProceedings of the 38th International Conference on Neural Information Processing Sys- tems, NIPS ’24, Curran Associates Inc., Red Hook, NY, USA (2025). ISBN 9798331314385
2025
-
[49]
E. Todd, M. Li, A. S. Sharma, A. Mueller, B. C. Wallace, and D. Bau, Function vectors in large language models,ArXiv.abs/2310.15213(2023). URLhttps://api.semanticscholar.org/CorpusID:264439657
arXiv 2023
-
[50]
S. Katz, A. Klemm, and C. Vafa, Geometric engineering of quantum field theories,Nuclear Physics B.497(1–2), 173–195 (July, 1997). ISSN 0550-
1997
-
[51]
doi: 10.1016/s0550-3213(97)00282-4. URLhttp://dx.doi.org/10. 1016/S0550-3213(97)00282-4
-
[52]
Kerber, R
M. Kerber, R. F. Tichy, and M. Weitzer. Constrained triangulations, vol- umes of polytopes, and unit equations. InInternational Symposium on Computational Geometry(2016). URLhttps://api.semanticscholar.org/ CorpusID:44417681
2016
-
[53]
DeepSeek-AI, Deepseek-r1: Incentivizing reasoning capability in llms via re- inforcement learning,arXiv.2501.12948(2025)
Pith/arXiv arXiv 2025
- [54]
-
[55]
Copet, Q
FAIR CodeGen team, J. Copet, Q. Carbonneaux, G. Cohen, J. Gehring, J. Kahn, J. Kossen, F. Kreuk, E. McMilin, M. Meyer, Y. Wei, D. Zhang, K. Zheng, J. Armengol-Estap´ e, P. Bashiri, M. Beck, P. Chambon, A. Char- nalia, C. Cummins, J. Decugis, Z. V. Fisches, F. Fleuret, F. Gloeckle, A. Gu, M. Hassid, D. Haziza, B. Y. Idrissi, C. Keller, R. Kindi, H. Leather...
2025
-
[56]
J. H. T. Yip, A. Mininno, and G. Shiu. Exploring Line Bundle Standard Models with Transformers. to appear (2026)
2026
-
[57]
Demirtas, A
M. Demirtas, A. Rios-Tascon, and L. McAllister, CYTools: A Software Pack- age for Analyzing Calabi-Yau Manifolds (11, 2022). Generating Special Triangulations with Transformers27
2022
-
[58]
F. Charton and J. Kempe. Emergent properties with repeated examples. URLhttps://arxiv.org/abs/2410.07041(2024)
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.