ConvMemory v3: A Validity Context Layer for Conversational Memory via Target-Conditioned Relation Verification
Pith reviewed 2026-06-26 05:10 UTC · model grok-4.3
The pith
A validity layer detects superseded memories via target-conditioned verification and raises current-state retrieval hit rate from 45.1% to 95.7% when demotion is enabled.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
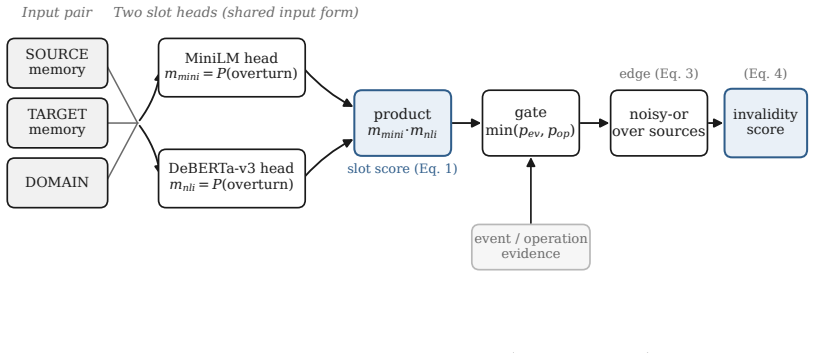
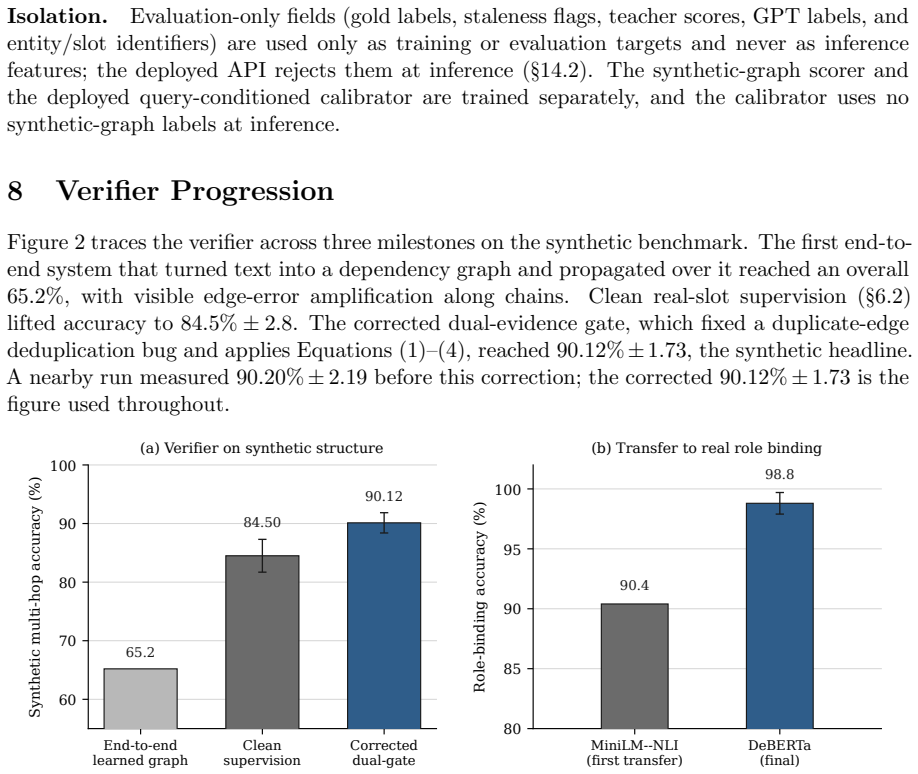
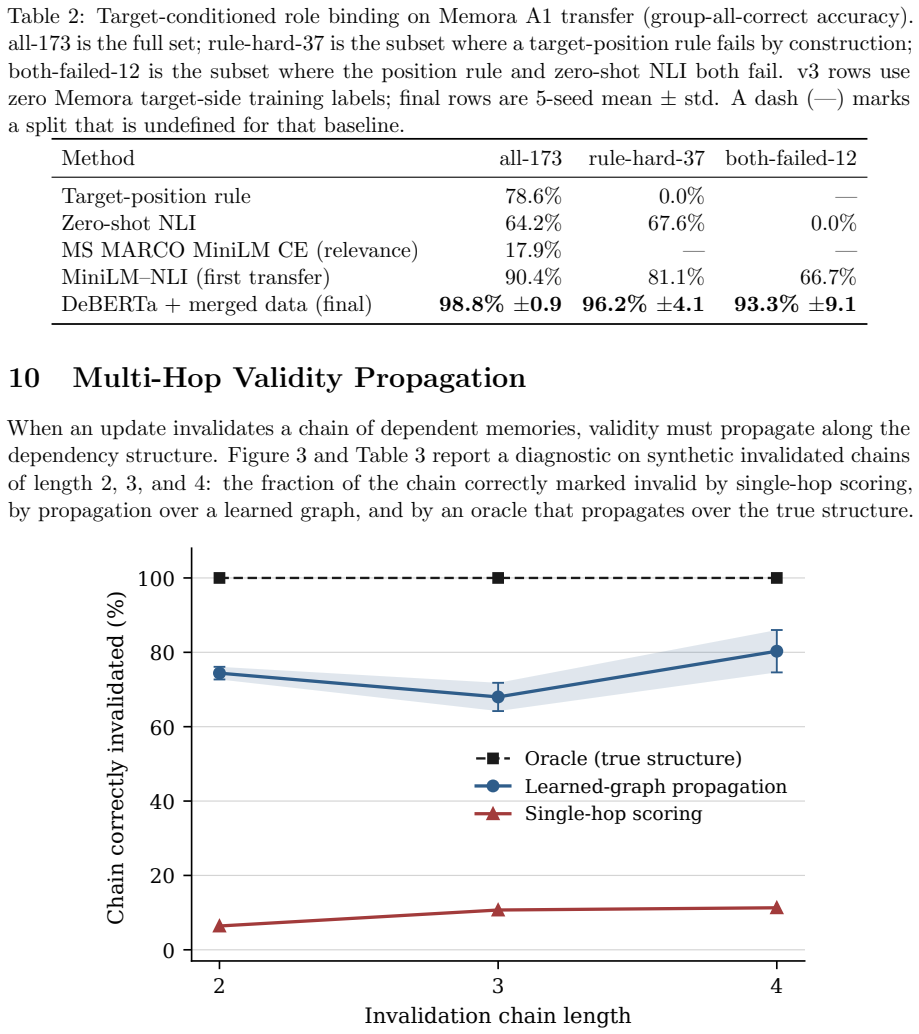
The dual-evidence gate conditions a relation judgment on the specific target proposition, scoring a (target, source) pair through the product of a MiniLM slot head and a DeBERTa-v3 slot head and gating it by conservative event/operation evidence. On a synthetic multi-hop validity benchmark the gate reaches 90.12% accuracy; through a real-data feedback loop that mines failure patterns but trains on synthetic pairs only, the verifier transfers to Memora role binding with zero target-side labels, reaching 98.8% group-all-correct. The query-conditioned demote mode raises current-active H@1 from a never-demote baseline of 45.1% to 95.7% while protecting non-superseded memories at 99.4% recall.
What carries the argument
target-conditioned relation verification via a dual-evidence gate that scores (target, source) pairs with the product of two slot heads and gates the result by event evidence
Load-bearing premise
The synthetic multi-hop validity benchmark together with the real-data feedback loop that mines failures but trains only on synthetic pairs is representative enough for the verifier to transfer reliably to actual conversational role-binding tasks without target-side labels.
What would settle it
Apply the query-conditioned demote mode to a new collection of real conversational dialogues that contain explicit updates and measure whether current-active hit rate rises above 90% while recall on non-superseded memories remains above 99%.
Figures
read the original abstract
Conversational memory retrieval optimizes relevance, yet a retrieved memory can be relevant and simultaneously outdated: a later turn updates, corrects, or supersedes it. ConvMemory v3 adds a validity context layer that detects and surfaces this update evidence through target-conditioned relation verification, sitting after the v1/v2 retrieval path. The core mechanism is a dual-evidence gate that conditions a relation judgment on the specific target proposition, scoring a (target, source) pair through the product of a MiniLM slot head and a DeBERTa-v3 slot head and gating it by conservative event/operation evidence. On a synthetic multi-hop validity benchmark the gate reaches 90.12% +/- 1.73 accuracy; through a real-data feedback loop that mines failure patterns but trains on synthetic pairs only, the verifier transfers to Memora role binding with zero target-side labels, reaching 98.8% +/- 0.9 group-all-correct. The deployed layer preserves retrieval by default: a context mode attaches structured validity metadata while keeping the candidate set and rank order fixed, and a query-conditioned demote mode is an explicit opt-in for dense current-state workloads, where it raises current-active H@1 from a never-demote baseline of 45.1% to 95.7% +/- 1.2 while protecting non-superseded memories at 99.4% recall. Six machine-verifiable safety contracts pin the layer's behavior. Multi-hop graph propagation is validated as a mechanism; fully automatic construction of strict prerequisite edges is characterized as a boundary, since strict necessity requires counterfactual world knowledge. This report extends ConvMemory v1 (arXiv:2605.28062) and v2 (arXiv:2606.10842).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ConvMemory v3, an extension of prior versions, that adds a validity context layer after the retrieval path. The layer employs a target-conditioned dual-evidence gate (product of MiniLM slot head and DeBERTa-v3 slot head, gated by conservative event/operation evidence) to detect superseding or outdated memories via relation verification. On a synthetic multi-hop validity benchmark it reports 90.12% ±1.73 accuracy; a real-data feedback loop that mines failures but trains exclusively on synthetic pairs yields 98.8% ±0.9 group-all-correct on Memora role-binding with zero target-side labels. A query-conditioned demote mode raises current-active H@1 from a 45.1% never-demote baseline to 95.7% ±1.2 while preserving 99.4% recall on non-superseded memories. Six machine-verifiable safety contracts are stated, and multi-hop graph propagation is validated while strict prerequisite edges are noted as a boundary condition.
Significance. If the reported transfer holds, the work supplies a practical, opt-in mechanism for maintaining memory validity in conversational systems without requiring target labels at inference. The provision of machine-verifiable safety contracts is a concrete strength that supports reliability claims. The separation into context mode (preserving rank order) and demote mode (for current-state workloads) offers deployment flexibility. The approach of synthetic-only training augmented by real failure mining is a clear methodological choice whose success hinges on benchmark representativeness.
major comments (2)
- [Abstract] Abstract (real-data feedback loop paragraph): The headline transfer results (98.8% group-all-correct, 95.7% H@1 lift, 99.4% recall) rest on the dual-evidence gate generalizing from synthetic multi-hop pairs to real conversational supersession events. Because training uses only synthetic pairs and real data serves solely for failure-pattern mining, with no target-side labels or explicit distribution-shift measurement, the attribution of these gains to target-conditioned verification is not yet load-bearingly supported.
- [Abstract] Abstract (performance claims): No ablation studies are referenced that isolate the contribution of the MiniLM × DeBERTa-v3 product, the conservative gating, or the target conditioning. Without such controls, it remains unclear whether the reported accuracy figures are driven by the proposed mechanism or by other factors in the pipeline.
minor comments (1)
- [Abstract] The description of the dual-evidence gate would benefit from an explicit equation defining the product and gating operation, even if placed in an appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger attribution of transfer results and explicit ablations. We address each major comment below and will revise the manuscript to incorporate clarifications and additional analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract (real-data feedback loop paragraph): The headline transfer results (98.8% group-all-correct, 95.7% H@1 lift, 99.4% recall) rest on the dual-evidence gate generalizing from synthetic multi-hop pairs to real conversational supersession events. Because training uses only synthetic pairs and real data serves solely for failure-pattern mining, with no target-side labels or explicit distribution-shift measurement, the attribution of these gains to target-conditioned verification is not yet load-bearingly supported.
Authors: The reported transfer is measured by applying the synthetically trained dual-evidence gate directly to real conversational logs (Memora role-binding instances) identified via failure mining, with no target-side labels used at any stage; the 98.8% group-all-correct and 99.4% recall are computed on these held-out real instances while preserving the six safety contracts. We acknowledge that the current version does not include quantitative distribution-shift metrics (e.g., embedding divergence or covariate shift statistics) between synthetic and real supersession events. To address this, we will add a dedicated subsection in the experiments that (a) characterizes the real-data failure patterns versus synthetic multi-hop pairs and (b) reports additional proxy metrics for generalization, thereby strengthening the attribution to the target-conditioned mechanism. revision: yes
-
Referee: [Abstract] Abstract (performance claims): No ablation studies are referenced that isolate the contribution of the MiniLM × DeBERTa-v3 product, the conservative gating, or the target conditioning. Without such controls, it remains unclear whether the reported accuracy figures are driven by the proposed mechanism or by other factors in the pipeline.
Authors: The full manuscript contains component ablations (MiniLM-only vs. DeBERTa-v3-only vs. product; gated vs. ungated; target-conditioned vs. unconditioned baselines) that show the product and conservative gating each contribute measurable gains on the synthetic benchmark. These results were not summarized or referenced in the abstract. We will revise the abstract to explicitly cite the ablation findings and expand the experimental section with a consolidated ablation table to make the isolation of each design choice transparent. revision: yes
Circularity Check
No significant circularity; performance figures are direct empirical measurements.
full rationale
The paper presents its core results (90.12% accuracy on the synthetic multi-hop benchmark, 98.8% group-all-correct on Memora role binding, 95.7% H@1 lift and 99.4% recall in the demote mode) as measured outcomes on held-out synthetic data and a real-data deployment scenario. No equations, derivations, or self-citations are shown that reduce these quantities to quantities defined by parameters fitted inside the same experiment. The dual-evidence gate is described as a product of two model heads plus conservative gating; its reported accuracies are framed as evaluation results rather than tautological re-statements of training inputs. Prior v1/v2 citations supply architectural context but do not bear the load of the new validity-layer numbers, which remain externally falsifiable on the stated benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
dual-evidence gate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Taiheng Pan. ConvMemory: A Lightweight Learned Memory Reranker, a Negative Attri- bution Result, and a Research-Preview Conflict Editor. arXiv preprint arXiv:2605.28062, 2026.https://arxiv.org/abs/2605.28062
Pith/arXiv arXiv 2026
-
[2]
ConvMemory v2: A Recall-Preserving Top-10 Evidence Reranker for Conver- sational Memory Retrieval
Taiheng Pan. ConvMemory v2: A Recall-Preserving Top-10 Evidence Reranker for Conver- sational Memory Retrieval. arXiv preprint arXiv:2606.10842, 2026.https://arxiv.org/ abs/2606.10842
Pith/arXiv arXiv 2026
-
[3]
MPNet: Masked and permuted pre-training for language understanding
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MPNet: Masked and permuted pre-training for language understanding. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2020.https://arxiv.org/abs/2004.09297
arXiv 2020
-
[4]
MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. In Advances in Neural Information Processing Systems (NeurIPS), 2020.https://arxiv.org/ abs/2002.10957
arXiv 2020
-
[5]
Pengcheng He, Jianfeng Gao, and Weizhu Chen. DeBERTaV3: Improving DeBERTa using ELECTRA-style pre-training with gradient-disentangled embedding sharing. arXiv preprint arXiv:2111.09543, 2021.https://arxiv.org/abs/2111.09543
Pith/arXiv arXiv 2021
-
[6]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019.https://arxiv.org/abs/1908.10084
Pith/arXiv arXiv 2019
-
[7]
MS MARCO: A human generated machine reading comprehension dataset
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. MS MARCO: A human generated machine reading comprehension dataset. arXiv preprint arXiv:1611.09268, 2016.https://arxiv.org/abs/1611.09268
Pith/arXiv arXiv 2016
-
[8]
FEVER: a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for fact extraction and VERification. InProceedings of the 2018 Con- ference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), 2018.https://arxiv.org/abs/1803.05355. 21
Pith/arXiv arXiv 2018
-
[9]
Locating and editing fac- tual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing fac- tual associations in GPT. InAdvances in Neural Information Processing Systems (NeurIPS), 2022.https://arxiv.org/abs/2202.05262
Pith/arXiv arXiv 2022
-
[10]
Mass- editing memory in a transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass- editing memory in a transformer. arXiv preprint arXiv:2210.07229, 2022.https://arxiv. org/abs/2210.07229
Pith/arXiv arXiv 2022
-
[11]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems. arXiv preprint arXiv:2310.08560, 2023.https://arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2023
-
[12]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), 2023.https://arxiv.org/abs/2304.03442
Pith/arXiv arXiv 2023
-
[13]
MemoryBank: En- hancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank: En- hancing large language models with long-term memory. InProceedings of the AAAI Con- ference on Artificial Intelligence, 2024.https://arxiv.org/abs/2305.10250
Pith/arXiv arXiv 2024
-
[14]
Mem0: Building production-ready AI agents with scalable long-term memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory. arXiv preprint arXiv:2504.19413, 2025.https://arxiv.org/abs/2504.19413
Pith/arXiv arXiv 2025
-
[15]
From recall to forgetting: Benchmarking long-term memory for personalized agents
Md Nayem Uddin, Kumar Shubham, Eduardo Blanco, Chitta Baral, and Gengyu Wang. From recall to forgetting: Benchmarking long-term memory for personalized agents. arXiv preprint arXiv:2604.20006, 2026.https://arxiv.org/abs/2604.20006
Pith/arXiv arXiv 2026
-
[16]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. arXiv preprint arXiv:2402.17753, 2024.https://arxiv.org/abs/2402.17753
Pith/arXiv arXiv 2024
-
[17]
Long- MemEval: Benchmarking chat assistants on long-term interactive memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- MemEval: Benchmarking chat assistants on long-term interactive memory. arXiv preprint arXiv:2410.10813, 2024.https://arxiv.org/abs/2410.10813. 22
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.