ProtoKV: Streaming Video Understanding under Delayed Query with Summary-State Memory
Pith reviewed 2026-06-26 05:15 UTC · model grok-4.3
The pith
ProtoKV keeps a fixed-size prototype bank that preserves early video cues for queries arriving after long delays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
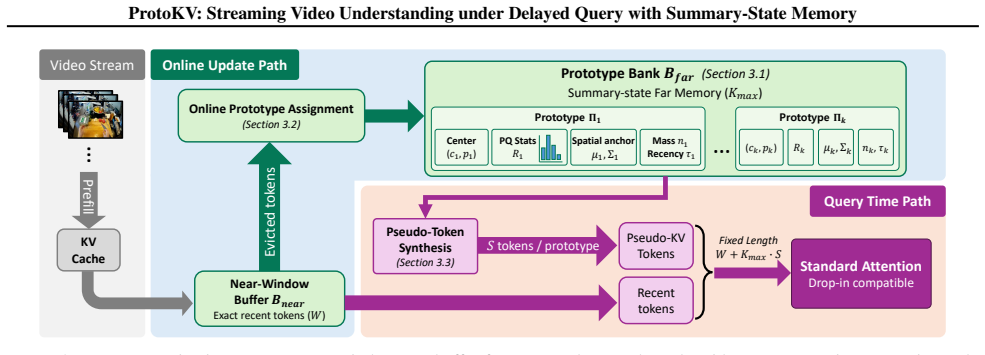
ProtoKV maintains an exact near-window KV cache while compressing far history into a fixed number of semantic-spatial prototypes augmented with residual statistics; each prototype is presented to the attention mechanism through a bounded set of pseudo-tokens, allowing the model to attend to summary information from arbitrarily distant past without growing the cache size.
What carries the argument
The semantic-spatial prototype bank with residual statistics, which aggregates far history into a constant-capacity summary state exposed via pseudo-tokens.
If this is right
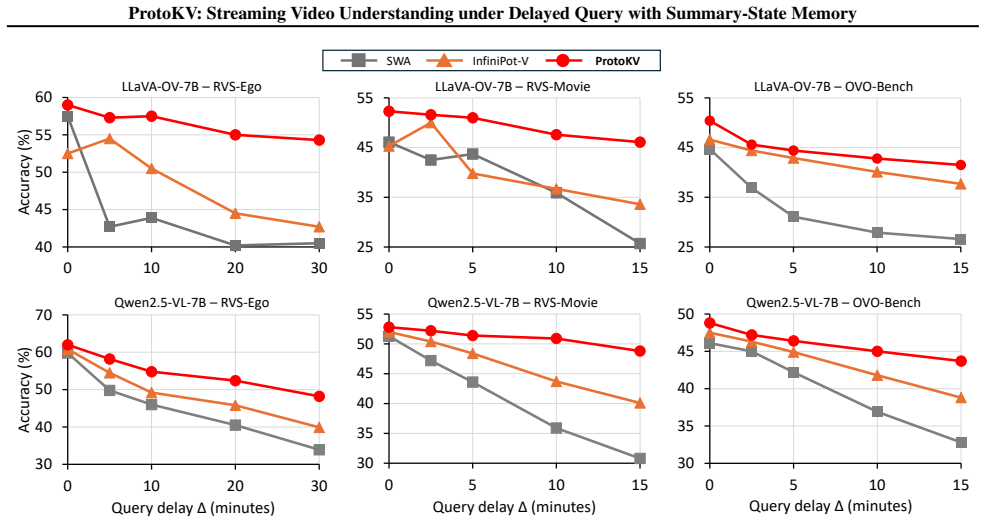
- Accuracy stays higher than token-retention baselines as query delay grows.
- Memory footprint remains constant no matter how far back the decisive content appeared.
- The pseudo-token interface works with unmodified attention layers.
- Gains appear under identical GPU-memory and latency budgets as the baselines.
- The relative improvement widens with longer delays on the same benchmarks.
Where Pith is reading between the lines
- The same summary-state design could apply to other asynchronous streaming tasks such as audio event detection.
- Adaptive allocation of prototype slots might reduce loss on videos whose content changes at very different rates.
- The residual statistics could support approximate reconstruction of token distributions for auxiliary tasks.
- Real-time deployment tests on variable frame-rate streams would expose practical latency limits not covered by benchmarks.
Load-bearing premise
The semantic-spatial prototype bank can preserve decisive cues from far history without significant information loss when queries are delayed.
What would settle it
An experiment in which accuracy on SVU benchmarks stops improving or declines as query delay increases while memory budget and query-time cost remain fixed.
Figures
read the original abstract
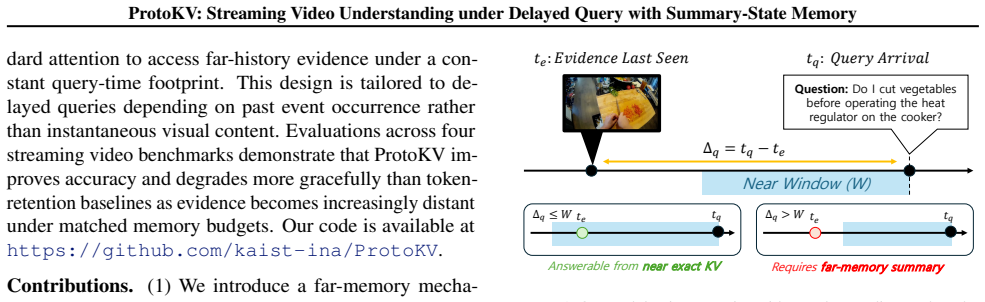
Streaming video understanding (SVU) must answer queries that arrive asynchronously while visual tokens stream continuously under strict GPU-memory and query-time latency budgets. A key challenge is delayed query: decisive cues may appear briefly, yet many subsequent updates occur before the query arrives, increasing the risk that those cues are evicted or diluted under bounded memory. We propose ProtoKV, a constant-footprint SVU memory that represents far history as a fixed-capacity summary state rather than retaining token instances. ProtoKV keeps an exact near-window KV cache and aggregates older content into a semantic-spatial prototype bank with residual statistics. At query time, each prototype is exposed through a bounded pseudo-token interface that is drop-in compatible with standard attention. Under matched budgets and comparable query-time cost, ProtoKV improves accuracy by up to 12.5 points over token-retention baselines on SVU benchmarks in the long-delay regime, with gains that grow as query delay increases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProtoKV, a constant-footprint memory design for streaming video understanding (SVU) under delayed queries. It maintains an exact near-window KV cache while aggregating older visual content into a semantic-spatial prototype bank with residual statistics; at query time, prototypes are exposed via a bounded pseudo-token interface compatible with standard attention. The central empirical claim is that, under matched memory budgets and comparable query-time cost, ProtoKV yields accuracy gains of up to 12.5 points over token-retention baselines on SVU benchmarks in the long-delay regime, with gains that increase as query delay grows.
Significance. If the empirical results hold under rigorous verification, the constant-footprint summary-state approach would represent a meaningful advance for practical SVU systems that must handle asynchronous queries without unbounded memory growth. The design's drop-in compatibility with existing attention mechanisms and the reported scaling of gains with delay are particularly relevant for real-world streaming applications.
major comments (2)
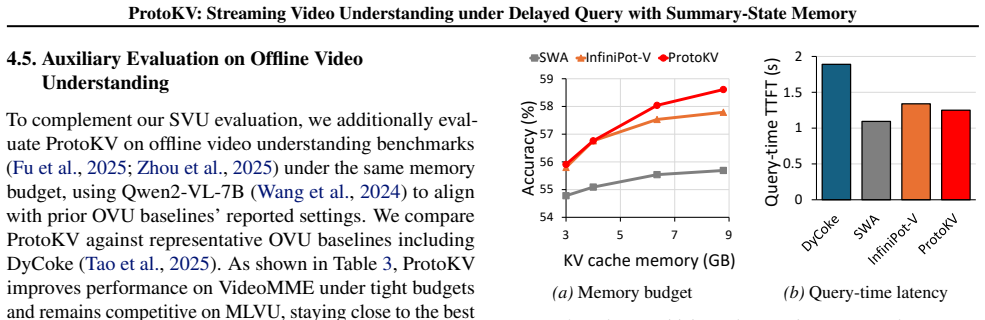
- [Abstract and §4 (Experiments)] The abstract states empirical gains of up to 12.5 points but the manuscript provides no details on the SVU benchmarks, token-retention baselines, number of runs, error bars, or statistical tests. This information is required to evaluate whether the reported improvement is load-bearing for the central claim.
- [§3 (Method) and §4.3 (Ablations)] The weakest assumption—that the semantic-spatial prototype bank with residual statistics preserves decisive cues from far history without significant loss—is not accompanied by an ablation that isolates information loss as delay increases (e.g., a controlled comparison of prototype capacity versus cue retention).
minor comments (2)
- [§3.2] Notation for the prototype bank and residual statistics should be introduced with explicit equations rather than prose descriptions to improve reproducibility.
- [Figures 3–5] Figure captions should explicitly state the memory budget and delay values used in each plotted curve.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] The abstract states empirical gains of up to 12.5 points but the manuscript provides no details on the SVU benchmarks, token-retention baselines, number of runs, error bars, or statistical tests. This information is required to evaluate whether the reported improvement is load-bearing for the central claim.
Authors: We agree that the current presentation is insufficient for rigorous evaluation. Although Section 4 describes the experimental protocol at a high level, it does not list the exact SVU benchmarks, the precise token-retention baselines, the number of runs, error bars, or statistical tests. In the revised manuscript we will expand both the abstract and Section 4 to include: (i) the specific benchmarks and their delay regimes, (ii) the matched token-retention baselines, (iii) results reported as mean ± std over at least three independent runs, and (iv) a brief statement on statistical significance testing. revision: yes
-
Referee: [§3 (Method) and §4.3 (Ablations)] The weakest assumption—that the semantic-spatial prototype bank with residual statistics preserves decisive cues from far history without significant loss—is not accompanied by an ablation that isolates information loss as delay increases (e.g., a controlled comparison of prototype capacity versus cue retention).
Authors: We concur that a direct ablation isolating information loss versus delay would more convincingly support the central modeling assumption. Existing ablations in §4.3 vary prototype capacity and report end-to-end accuracy under different delays, but do not explicitly measure cue retention or reconstruction fidelity as a function of delay. We will add a new controlled ablation that quantifies information loss (via both accuracy drop on cue-specific queries and a simple reconstruction metric) across increasing delays for several prototype capacities, and include the results in the revised §4.3. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical architecture (ProtoKV) for streaming video understanding and reports benchmark accuracy gains under matched budgets. No derivation chain, equations, or self-citations are presented that reduce a claimed prediction or uniqueness result to a fitted input or prior self-work by construction. The reported improvements are framed as experimental outcomes, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhang, Haoji and Wang, Yiqin and Tang, Yansong and Liu, Yong and Feng, Jiashi and Jin, Xiaojie , booktitle=. Flash-
-
[2]
arXiv preprint arXiv:2504.13915 , year=
Memory-efficient Streaming VideoLLMs for Real-time Procedural Video Understanding , author=. arXiv preprint arXiv:2504.13915 , year=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Videollm-online: Online video large language model for streaming video , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Relational space-time query in long-form videos , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
Advances in Neural Information Processing Systems , year=
Videollm-mod: Efficient video-language streaming with mixture-of-depths vision computation , author=. Advances in Neural Information Processing Systems , year=
-
[6]
Proceedings of the 52nd Annual International Symposium on Computer Architecture , pages=
Oaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV Cache Quantization , author=. Proceedings of the 52nd Annual International Symposium on Computer Architecture , pages=
-
[7]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[8]
FlexGen: high-throughput generative inference of large language models with a single GPU , year =
Sheng, Ying and Zheng, Lianmin and Yuan, Binhang and Li, Zhuohan and Ryabinin, Max and Chen, Beidi and Liang, Percy and R\'. FlexGen: high-throughput generative inference of large language models with a single GPU , year =. Proceedings of the 40th International Conference on Machine Learning , articleno =
-
[9]
IEEE transactions on pattern analysis and machine intelligence , volume=
Product quantization for nearest neighbor search , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2010 , publisher=
2010
-
[10]
Advances in neural information processing systems , volume=
Max-margin token selection in attention mechanism , author=. Advances in neural information processing systems , volume=
-
[11]
Sun, Hanshi and Chang, Li-Wen and Bao, Wenlei and Zheng, Size and Zheng, Ningxin and Liu, Xin and Dong, Harry and Chi, Yuejie and Chen, Beidi , booktitle =
-
[12]
Li, Bo and Zhang, Yuanhan and Guo, Dong and Zhang, Renrui and Li, Feng and Zhang, Hao and Zhang, Kaichen and Zhang, Peiyuan and Li, Yanwei and Liu, Ziwei and Li, Chunyuan , journal =
-
[13]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and others , journal=
-
[14]
Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang , journal=. Qwen2-
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding? , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[16]
arXiv preprint arXiv:2411.03628 , year=
Streamingbench: Assessing the gap for mllms to achieve streaming video understanding , author=. arXiv preprint arXiv:2411.03628 , year=
-
[17]
Kim, Minsoo and Shim, Kyuhong and Choi, Jungwook and Chang, Simyung , journal =
-
[18]
International Conference on Learning Representations , year =
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. International Conference on Learning Representations , year =
-
[19]
European Conference on Computer Vision , pages=
Llama-vid: An image is worth 2 tokens in large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[20]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Ego4d: Around the world in 3,000 hours of egocentric video , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[21]
International Conference on Learning Representations , year=
Streaming video question-answering with in-context video kv-cache retrieval , author=. International Conference on Learning Representations , year=
-
[22]
International Conference on Learning Representations , year =
Efficient Streaming Language Models with Attention Sinks , author =. International Conference on Learning Representations , year =
-
[23]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
International Conference on Learning Representations , year =
Compressive Transformers for Long-Range Sequence Modelling , author =. International Conference on Learning Representations , year =
-
[25]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2004.05150 , year=
Longformer: The long-document transformer , author=. arXiv preprint arXiv:2004.05150 , year=
Pith/arXiv arXiv 2004
-
[27]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[28]
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages =. doi:10.18653/v1/2021.acl-long.353 , year =
-
[29]
Perceiver io: A general architecture for structured inputs & outputs. arXiv 2021 , author=. arXiv preprint arXiv:2107.14795 , year=
Pith/arXiv arXiv 2021
-
[30]
International Conference on Learning Representations , year =
Long-tail Learning via Logit Adjustment , author =. International Conference on Learning Representations , year =
-
[31]
Advances in neural information processing systems , volume=
Balanced meta-softmax for long-tailed visual recognition , author=. Advances in neural information processing systems , volume=
-
[32]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[33]
2017 IEEE international conference on image processing (ICIP) , pages=
Simple online and realtime tracking with a deep association metric , author=. 2017 IEEE international conference on image processing (ICIP) , pages=. 2017 , organization=
2017
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[35]
and Soran, Bilge and Krishnamoorthi, Raghuraman and Elhoseiny, Mohamed and Chandra, Vikas , booktitle =
Shen, Xiaoqian and Xiong, Yunyang and Zhao, Changsheng and Wu, Lemeng and Chen, Jun and Zhu, Chenchen and Liu, Zechun and Xiao, Fanyi and Varadarajan, Balakrishnan and Bordes, Florian and Liu, Zhuang and Xu, Hu and Kim, Hyunwoo J. and Soran, Bilge and Krishnamoorthi, Raghuraman and Elhoseiny, Mohamed and Chandra, Vikas , booktitle =
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mlvu: Benchmarking multi-task long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.