ResilPhase: Plug-and-Play Phase Mapping and Noise-Resilient Macro-Trajectory Extrapolation for Diffusion Acceleration
Pith reviewed 2026-06-26 05:00 UTC · model grok-4.3
The pith
ResilPhase accelerates diffusion models by extrapolating their global drift trajectory in ODE space with derivative-free methods and bounded phase mapping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
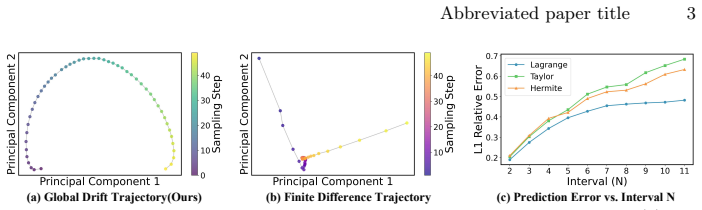
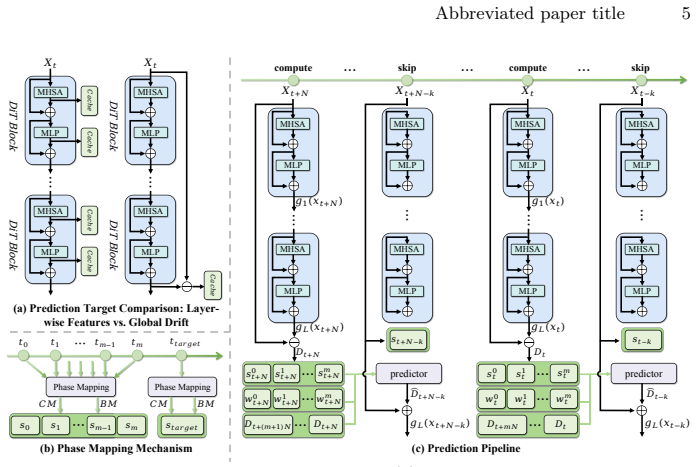
Accelerated DiTs suffer from accumulated spatial errors, noisy derivative amplification, and high-order instability because discrete extrapolation is performed on representations misaligned with the continuous diffusion trajectory. Reformulating the task as stable macro-trajectory extrapolation aligned with the model's Global Drift (end-to-end state evolution) removes feature inconsistency and memory overhead. A derivative-free barycentric Lagrange extrapolator bypasses derivative instability, while a bounded Phase Mapping regularizes the extrapolation domain and suppresses oscillatory error growth. Together these form ResilPhase, which experiments show delivers state-of-the-art fidelity on
What carries the argument
Bounded Phase Mapping, which regularizes the extrapolation domain, combined with a derivative-free barycentric Lagrange extrapolator applied to the model's Global Drift (end-to-end ODE state evolution).
If this is right
- Alignment with Global Drift eliminates feature inconsistency between cached and forecasted states.
- Derivative-free extrapolation removes both noisy amplification and approximation error from higher-order derivatives.
- Phase mapping confines the extrapolation domain and thereby limits oscillatory error accumulation.
- The resulting framework reaches state-of-the-art fidelity at aggressive acceleration ratios on both image and video diffusion models.
Where Pith is reading between the lines
- The same macro-trajectory view might be applied to other ODE-based generative processes such as flow-matching models.
- Lower memory overhead from avoiding per-feature caching could enable acceleration on resource-constrained hardware.
- If the Global Drift remains smooth across many steps, the method may also stabilize very long video or 3D generation sequences.
- Direct substitution of the Phase Mapping into existing derivative-based accelerators could serve as a lightweight plug-in test of the regularization effect.
Load-bearing premise
Higher-order temporal derivatives of the macro-trajectory are intrinsically noisy, and switching to derivative-free extrapolation plus bounded phase mapping suppresses error growth without introducing new inconsistencies.
What would settle it
An experiment on FLUX.1-dev or HunyuanVideo at 4x or higher acceleration ratios in which ResilPhase produces lower fidelity scores than derivative-based polynomial baselines would falsify the noise-resilience claim.
Figures




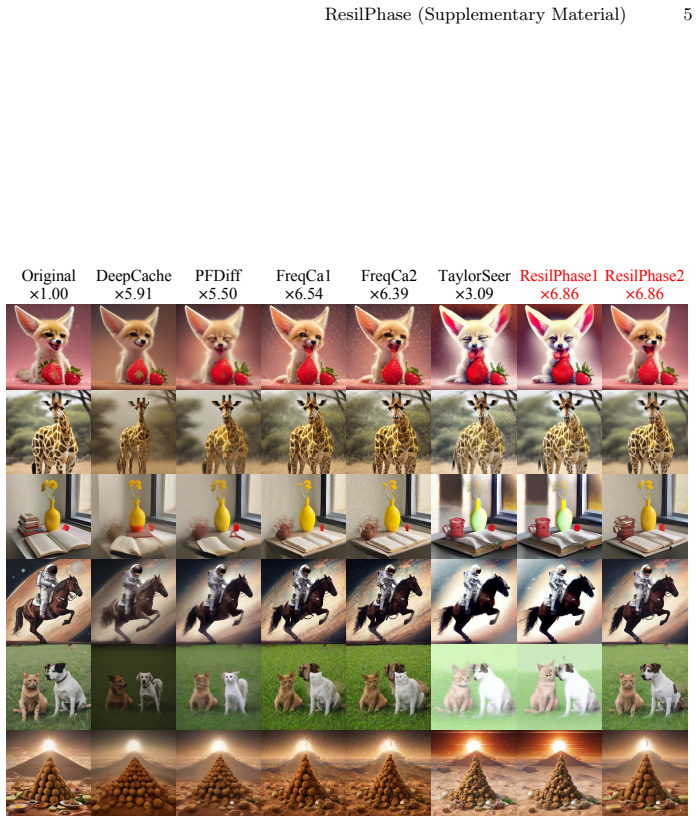



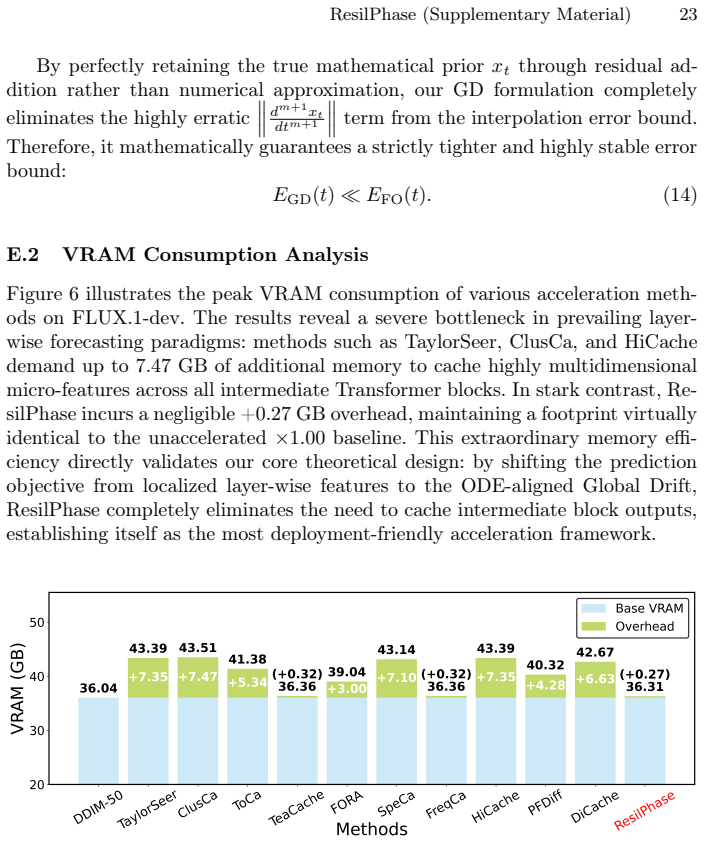
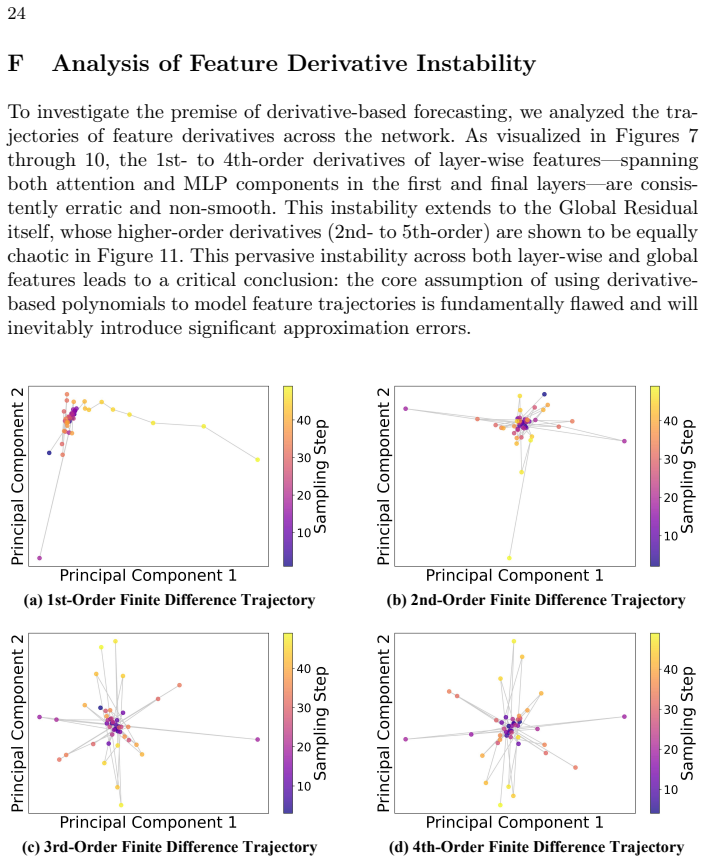
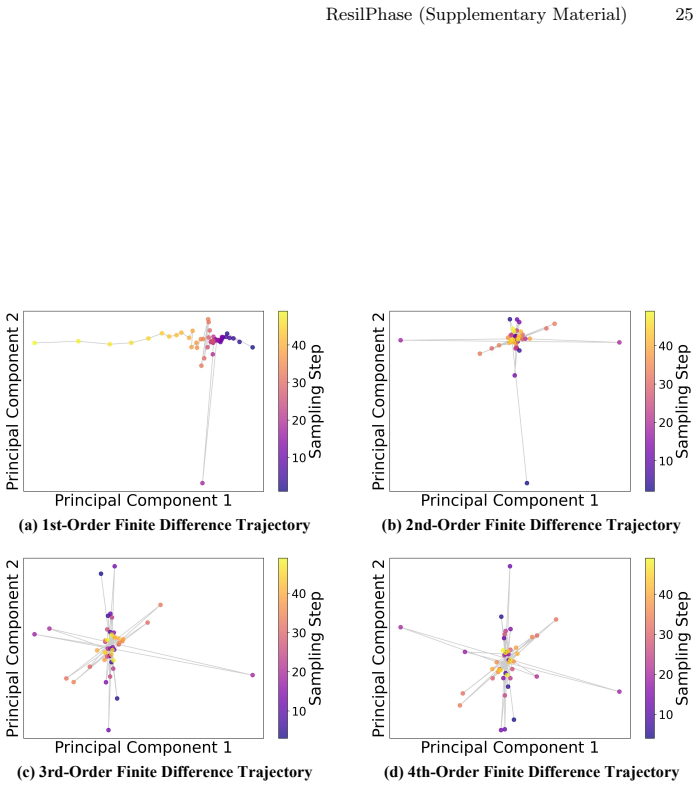
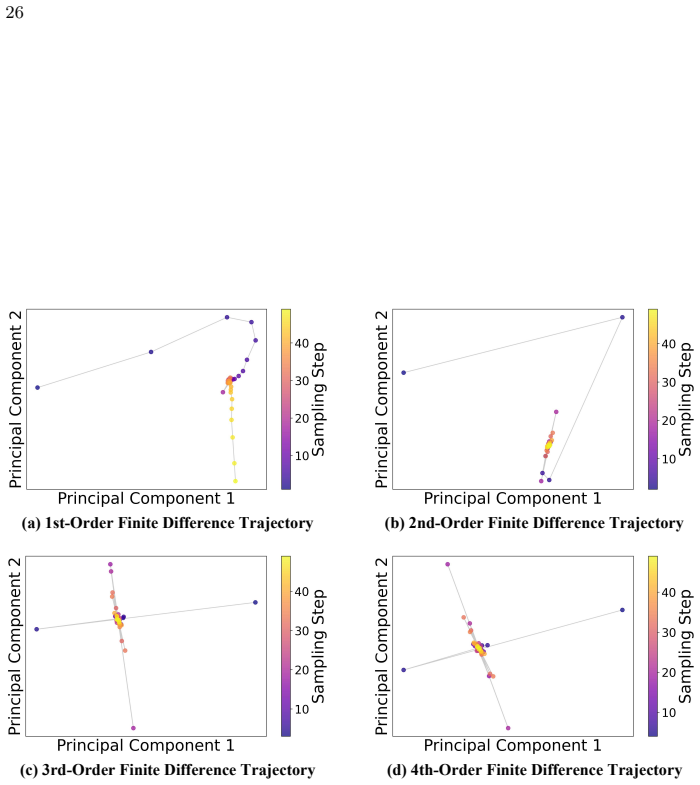
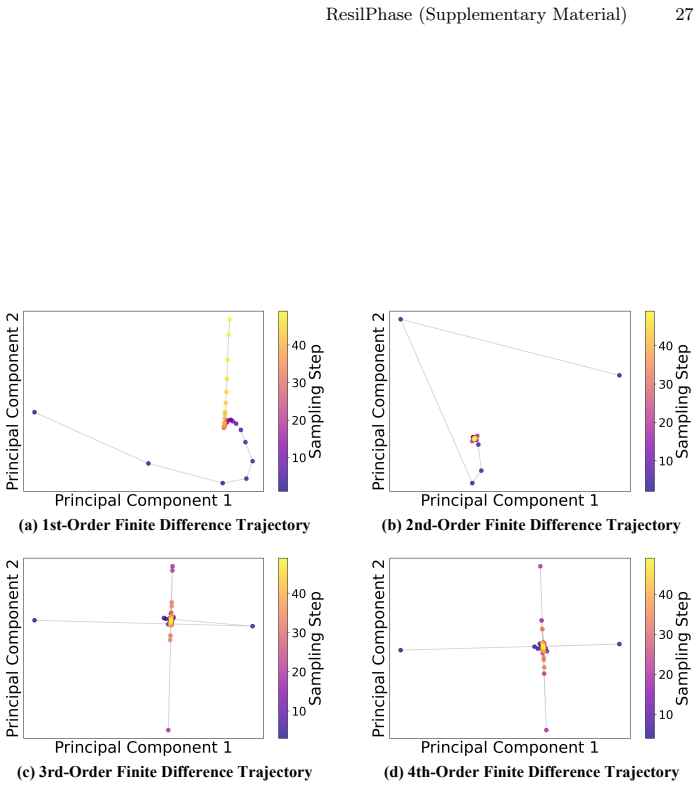
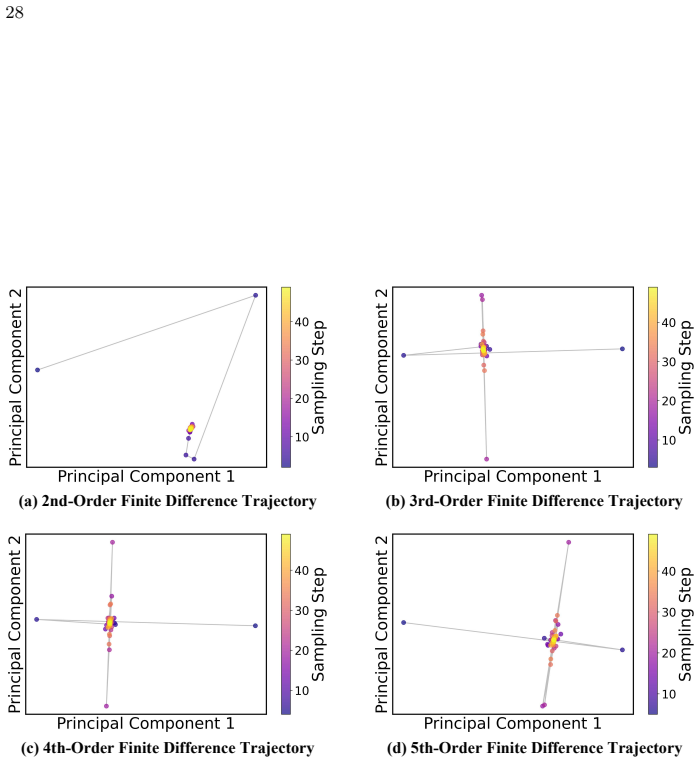
read the original abstract
The adoption of powerful diffusion models is hindered by their significant inference latency. Recent ``cache-then-forecast'' schemes alleviate this issue by accelerating DiTs using derivative-based polynomials, but they suffer from severe quality degradation at high acceleration ratios. Our analysis reveals its root cause: the discrete extrapolation performed on representations that are misaligned with the continuous diffusion trajectory and are numerically unstable. Thus, accelerated DiTs suffer from accumulated spatial errors, noisy derivative amplification, and high-order instability. We therefore reformulate accelerated inference as stable macro-trajectory extrapolation in ordinary differential equation (ODE) space. Instead of predicting intermediate features, we align forecasting with the model's Global Drift (GD), i.e., the end-to-end state evolution, thereby eliminating feature inconsistency and memory overhead. However, even this smooth macro-trajectory remains vulnerable to the derivative fallacy: its higher-order temporal derivatives are intrinsically noisy. Thus, we introduce a derivative-free barycentric Lagrange extrapolator to effectively bypass derivative instability and approximation error. We further propose a bounded Phase Mapping that regularizes the extrapolation domain, suppressing oscillatory error growth. These elements collectively constitute ResilPhase, a noise-resilient acceleration framework. Experiments on FLUX.1-dev and HunyuanVideo demonstrate state-of-the-art fidelity under aggressive acceleration ratios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ResilPhase, a plug-and-play acceleration framework for diffusion models that reformulates inference as stable macro-trajectory extrapolation in ODE space. It diagnoses quality degradation in prior cache-then-forecast methods (derivative-based polynomials) as arising from feature misalignment, noisy derivative amplification, and high-order instability. The solution aligns forecasting with the model's Global Drift, replaces derivatives with a barycentric Lagrange extrapolator, and adds bounded Phase Mapping to regularize the domain and suppress oscillations. Experiments on FLUX.1-dev and HunyuanVideo are stated to achieve state-of-the-art fidelity at aggressive acceleration ratios.
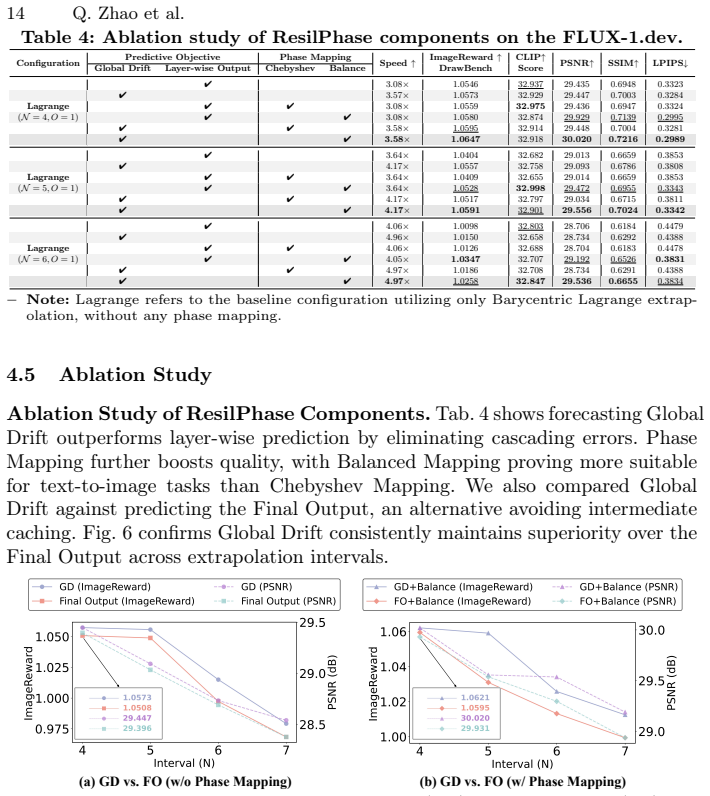
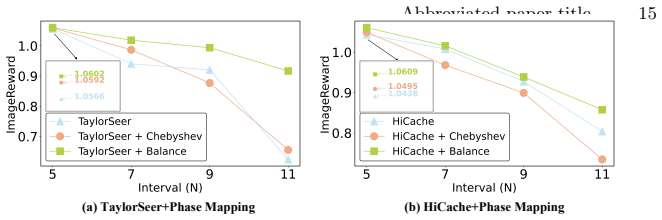
Significance. If the central claims hold with rigorous evidence, the work could meaningfully advance practical deployment of large DiTs by enabling higher acceleration ratios without fidelity loss. The shift to ODE-space macro-trajectory extrapolation and explicit avoidance of derivative instability offers a conceptually distinct angle from existing caching approaches. However, the absence of any derivations, quantitative results, or implementation details in the provided material prevents assessment of whether these advantages are realized.
major comments (3)
- [Abstract] Abstract: the root-cause analysis (feature inconsistency, noisy derivative amplification, high-order instability) is asserted without any supporting derivations, error analysis, or illustrative calculations, so the diagnosis cannot be evaluated.
- [Abstract] Abstract: the claim of state-of-the-art fidelity on FLUX.1-dev and HunyuanVideo under aggressive acceleration ratios is made without quantitative metrics, tables, ablation studies, or figures, leaving the experimental superiority unverifiable.
- [Abstract] Abstract: the assumption that higher-order temporal derivatives of the macro-trajectory are intrinsically noisy (the 'derivative fallacy') is stated without demonstration or analysis from the diffusion ODE, making the motivation for the derivative-free extrapolator ungrounded.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The major concerns focus on the abstract's assertions lacking visible support in the provided material. The full manuscript contains the requested derivations, error analyses, quantitative results, and ODE-based demonstrations in Sections 3 and 4. We address each point below by referencing the relevant sections. No changes to the manuscript are required, as the abstract is a summary of the complete work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the root-cause analysis (feature inconsistency, noisy derivative amplification, high-order instability) is asserted without any supporting derivations, error analysis, or illustrative calculations, so the diagnosis cannot be evaluated.
Authors: Section 3 of the manuscript provides the full root-cause analysis, including error propagation derivations, numerical illustrations of feature misalignment, and calculations showing noisy derivative amplification and high-order instability in the diffusion ODE. The abstract condenses these results; the complete supporting material is in the body of the paper. revision: no
-
Referee: [Abstract] Abstract: the claim of state-of-the-art fidelity on FLUX.1-dev and HunyuanVideo under aggressive acceleration ratios is made without quantitative metrics, tables, ablation studies, or figures, leaving the experimental superiority unverifiable.
Authors: Section 4 presents the experimental results, including quantitative metrics (e.g., FID, CLIP scores), comparison tables against prior cache-then-forecast methods, ablation studies on the barycentric extrapolator and Phase Mapping, and figures showing fidelity at high acceleration ratios on FLUX.1-dev and HunyuanVideo. The abstract summarizes these outcomes. revision: no
-
Referee: [Abstract] Abstract: the assumption that higher-order temporal derivatives of the macro-trajectory are intrinsically noisy (the 'derivative fallacy') is stated without demonstration or analysis from the diffusion ODE, making the motivation for the derivative-free extrapolator ungrounded.
Authors: Section 3.2 derives the derivative fallacy directly from the diffusion ODE, demonstrating through analysis and examples why higher-order temporal derivatives of the macro-trajectory are intrinsically noisy. This grounds the motivation for the derivative-free barycentric Lagrange extrapolator. revision: no
Circularity Check
No significant circularity detected
full rationale
The abstract presents a conceptual reformulation of diffusion inference as macro-trajectory extrapolation in ODE space, combined with a derivative-free barycentric Lagrange extrapolator and bounded phase mapping, without exhibiting any equations, fitted parameters, or self-citations that reduce the claimed improvements to inputs by construction. No load-bearing steps of the enumerated circularity patterns are identifiable from the given material, as the derivation chain is not formalized with mathematical reductions or empirical fits that could be inspected for tautology. The framework is described as addressing identified instabilities in prior cache-then-forecast methods through new components, leaving the central claims self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
T2v-compbench: A comprehensive benchmark for compositional text-to-video generation
Kaiyue Sun, Kaiyi Huang, Xian Liu, Yue Wu, Zihan Xu, Zhenguo Li, and Xihui Liu. T2v-compbench: A comprehensive benchmark for compositional text-to-video generation. arXiv preprint arXiv:2407.14505, 2024
arXiv 2024
-
[4]
arXiv preprint arXiv:2406.01125 (2024)
Chen, P., Shen, M., Ye, P., Cao, J., Tu, C., Bouganis, C.S., Zhao, Y., Chen, T.: -dit: A training-free acceleration method tailored for diffusion transformers. arXiv preprint arXiv:2406.01125 (2024)
arXiv 2024
-
[7]
Nature Electronics 7(8), 714--723 (2024)
Guo, Y., Yan, Z., Yu, X., Kong, Q., Xie, J., Luo, K., Zeng, D., Wu, Y., Jia, Z., Shi, Y.: Hardware design and the fairness of a neural network. Nature Electronics 7(8), 714--723 (2024)
2024
-
[8]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference-free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514--7528 (2021)
2021
-
[9]
Advances in neural information processing systems 30 (2017)
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems 30 (2017)
2017
-
[10]
Advances in neural information processing systems 33, 6840--6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems 33, 6840--6851 (2020)
2020
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807--21818 (2024)
2024
-
[12]
In: 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA)
Kim, S., Lee, H., Cho, W., Park, M., Ro, W.W.: Ditto: Accelerating diffusion model via temporal value similarity. In: 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). pp. 338--352. IEEE (2025)
2025
-
[14]
Advances in Neural Information Processing Systems 37, 85203--85240 (2024)
Li, S., Hu, T., van de Weijer, J., Khan, F.S., Liu, T., Li, L., Yang, S., Wang, Y., Cheng, M.M., Yang, J.: Faster diffusion: Rethinking the role of the encoder for diffusion model inference. Advances in Neural Information Processing Systems 37, 85203--85240 (2024)
2024
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, X., Liu, Y., Lian, L., Yang, H., Dong, Z., Kang, D., Zhang, S., Keutzer, K.: Q-diffusion: Quantizing diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17535--17545 (2023)
2023
-
[16]
Advances in Neural Information Processing Systems 36, 20662--20678 (2023)
Li, Y., Wang, H., Jin, Q., Hu, J., Chemerys, P., Fu, Y., Wang, Y., Tulyakov, S., Ren, J.: Snapfusion: Text-to-image diffusion model on mobile devices within two seconds. Advances in Neural Information Processing Systems 36, 20662--20678 (2023)
2023
-
[17]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, F., Zhang, S., Wang, X., Wei, Y., Qiu, H., Zhao, Y., Zhang, Y., Ye, Q., Wan, F.: Timestep embedding tells: It's time to cache for video diffusion model. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7353--7363 (2025)
2025
-
[20]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Liu, J., Zou, C., Lyu, Y., Ren, F., Wang, S., Li, K., Zhang, L.: Speca: Accelerating diffusion transformers with speculative feature caching. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10024--10033 (2025)
2025
-
[21]
In: The Eleventh International Conference on Learning Representations
Liu, X., Gong, C., et al.: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: The Eleventh International Conference on Learning Representations
-
[22]
Advances in neural information processing systems 35, 5775--5787 (2022)
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in neural information processing systems 35, 5775--5787 (2022)
2022
-
[23]
Machine Intelligence Research pp
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. Machine Intelligence Research pp. 1--22 (2025)
2025
-
[24]
arXiv e-prints pp
Ma, X., Wang, Y., Jia, G., Chen, X., Liu, Z., Li, Y.F., Chen, C., Qiao, Y.: Latte: Latent diffusion transformer for video generation. arXiv e-prints pp. arXiv--2401 (2024)
2024
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ma, X., Fang, G., Wang, X.: Deepcache: Accelerating diffusion models for free. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15762--15772 (2024)
2024
-
[26]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195--4205 (2023)
2023
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684--10695 (2022)
2022
-
[29]
International journal of computer vision 115(3), 211--252 (2015)
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al.: Imagenet large scale visual recognition challenge. International journal of computer vision 115(3), 211--252 (2015)
2015
-
[30]
Advances in neural information processing systems 35, 36479--36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems 35, 36479--36494 (2022)
2022
-
[31]
In: International Conference on Learning Representations
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. In: International Conference on Learning Representations
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shang, Y., Yuan, Z., Xie, B., Wu, B., Yan, Y.: Post-training quantization on diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1972--1981 (2023)
1972
-
[34]
In: International Conference on Learning Representations
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: International Conference on Learning Representations
-
[36]
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models (2023)
2023
-
[39]
IEEE transactions on image processing 13(4), 600--612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600--612 (2004)
2004
-
[40]
Integration 104, 102469 (2025)
Wu, Y., Yan, Z., Yin, X., He, L., Zhuo, C.: Anas: Software--hardware co-design of approximate neural network accelerators via neural architecture search. Integration 104, 102469 (2025)
2025
-
[41]
Advances in Neural Information Processing Systems 36, 15903--15935 (2023)
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems 36, 15903--15935 (2023)
2023
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yin, J., Chen, T., Chen, Y., Pei, G., Shu, X., Yao, Y., Shen, F.: Pca-seg: Revisiting cost aggregation for open-vocabulary semantic and part segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 27633--27643 (June 2026)
2026
-
[43]
IEEE Transactions on Image Processing 35, 3256--3270 (2026)
Yin, J., Jiang, X., Chen, T., Pei, G., Yao, Y., Shen, F., Shen, H.T.: Depmatch: Boosting semi-supervised semantic segmentation by exploring depth difference knowledge. IEEE Transactions on Image Processing 35, 3256--3270 (2026)
2026
-
[44]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586--595 (2018)
2018
-
[47]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Zheng, Z., Wang, X., Zou, C., Wang, S., Zhang, L.: Compute only 16 tokens in one timestep: Accelerating diffusion transformers with cluster-driven feature caching. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10181--10189 (2025)
2025
-
[48]
In: 2025 International Symposium of Electronics Design Automation (ISEDA)
Zhou, X., Zhang, Y., Sun, S., Wen, C., Yan, Z.: Deploying edge llms for wafer defect detection in chip manufacturing. In: 2025 International Symposium of Electronics Design Automation (ISEDA). pp. 7--11. IEEE (2025)
2025
-
[49]
Advances in Neural Information Processing Systems 37, 92581--92604 (2024)
Zhu, H., Tang, D., Liu, J., Lu, M., Zheng, J., Peng, J., Li, D., Wang, Y., Jiang, F., Tian, L., et al.: Dip-go: A diffusion pruner via few-step gradient optimization. Advances in Neural Information Processing Systems 37, 92581--92604 (2024)
2024
-
[51]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[52]
arXiv preprint arXiv:2311.15127 , year=
Stable video diffusion: Scaling latent video diffusion models to large datasets , author=. arXiv preprint arXiv:2311.15127 , year=
-
[53]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[54]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[55]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
2015
-
[56]
arXiv preprint arXiv:2305.10924 , volume=
Structural pruning for diffusion models , author=. arXiv preprint arXiv:2305.10924 , volume=
-
[57]
2023 , eprint=
Structural Pruning for Diffusion Models , author=. 2023 , eprint=
2023
-
[58]
Advances in Neural Information Processing Systems , volume=
Dip-go: A diffusion pruner via few-step gradient optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages=
Ditto: Accelerating Diffusion Model via Temporal Value Similarity , author=. 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages=. 2025 , organization=
2025
-
[60]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Q-diffusion: Quantizing diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[61]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Post-training quantization on diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[62]
Advances in neural information processing systems , volume=
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps , author=. Advances in neural information processing systems , volume=
-
[63]
Machine Intelligence Research , pages=
Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models , author=. Machine Intelligence Research , pages=. 2025 , publisher=
2025
-
[64]
arXiv preprint arXiv:2202.00512 , year=
Progressive distillation for fast sampling of diffusion models , author=. arXiv preprint arXiv:2202.00512 , year=
-
[65]
Progressive Distillation for Fast Sampling of Diffusion Models , author=
-
[66]
Consistency models , author=
-
[67]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deepcache: Accelerating diffusion models for free , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[68]
Advances in Neural Information Processing Systems , volume=
Faster diffusion: Rethinking the role of the encoder for diffusion model inference , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
arXiv preprint arXiv:2407.01425 , year=
Fora: Fast-forward caching in diffusion transformer acceleration , author=. arXiv preprint arXiv:2407.01425 , year=
-
[70]
-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers , author =
-
[71]
arXiv preprint arXiv:2410.05317 , year=
Accelerating diffusion transformers with token-wise feature caching , author=. arXiv preprint arXiv:2410.05317 , year=
-
[72]
arXiv preprint arXiv:2503.06923 , year=
From reusing to forecasting: Accelerating diffusion models with taylorseers , author=. arXiv preprint arXiv:2503.06923 , year=
-
[73]
arXiv preprint arXiv:2508.16211 , year=
Forecast then calibrate: Feature caching as ode for efficient diffusion transformers , author=. arXiv preprint arXiv:2508.16211 , year=
-
[74]
arXiv preprint arXiv:2508.16984 , year=
Hicache: Training-free acceleration of diffusion models via hermite polynomial-based feature caching , author=. arXiv preprint arXiv:2508.16984 , year=
-
[75]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Speca: Accelerating diffusion transformers with speculative feature caching , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[76]
arXiv preprint arXiv:2510.08669 , year=
Freqca: Accelerating diffusion models via frequency-aware caching , author=. arXiv preprint arXiv:2510.08669 , year=
-
[77]
arXiv preprint arXiv:2411.02265 , year=
Hunyuan-large: An open-source moe model with 52 billion activated parameters by tencent , author=. arXiv preprint arXiv:2411.02265 , year=
-
[78]
arXiv preprint arXiv:2209.03003 , year=
Flow straight and fast: Learning to generate and transfer data with rectified flow , author=. arXiv preprint arXiv:2209.03003 , year=
-
[79]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=
-
[80]
arXiv preprint arXiv:2010.02502 , year=
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
Pith/arXiv arXiv 2010
-
[81]
Denoising Diffusion Implicit Models , author=
-
[82]
Advances in neural information processing systems , volume=
Photorealistic text-to-image diffusion models with deep language understanding , author=. Advances in neural information processing systems , volume=
-
[83]
Advances in Neural Information Processing Systems , volume=
Imagereward: Learning and evaluating human preferences for text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[84]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Clipscore: A reference-free evaluation metric for image captioning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[85]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vbench: Comprehensive benchmark suite for video generative models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[86]
International journal of computer vision , volume=
Imagenet large scale visual recognition challenge , author=. International journal of computer vision , volume=. 2015 , publisher=
2015
-
[87]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[88]
IEEE transactions on image processing , volume=
Image quality assessment: from error visibility to structural similarity , author=. IEEE transactions on image processing , volume=. 2004 , publisher=
2004
-
[89]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
The unreasonable effectiveness of deep features as a perceptual metric , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[90]
Advances in Neural Information Processing Systems , volume=
Snapfusion: Text-to-image diffusion model on mobile devices within two seconds , author=. Advances in Neural Information Processing Systems , volume=
-
[91]
arXiv e-prints , pages=
Latte: Latent Diffusion Transformer for Video Generation , author=. arXiv e-prints , pages=
-
[92]
arXiv preprint arXiv:2412.20404 , year=
Open-sora: Democratizing efficient video production for all , author=. arXiv preprint arXiv:2412.20404 , year=
-
[93]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Timestep Embedding Tells: It's Time to Cache for Video Diffusion Model , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[94]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Compute only 16 tokens in one timestep: Accelerating diffusion transformers with cluster-driven feature caching , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[95]
Advances in Neural Information Processing Systems , volume=
Ditfastattn: Attention compression for diffusion transformer models , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.