Identifying the Unknown: Prompt-Free Open Vocabulary Anomaly Recognition for Robot-Object Interaction
Pith reviewed 2026-06-26 05:43 UTC · model grok-4.3
The pith
AnomNOVIC lets robots recognize unseen objects without prompts by pairing anomaly detection for boxes with a dedicated classifier.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
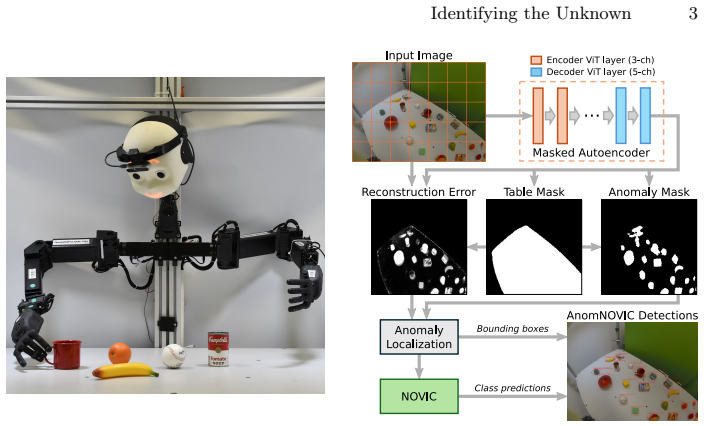
AnomNOVIC is a known-workspace two-stage system that combines a masked autoencoder trained for anomaly detection to generate object-agnostic bounding boxes with NOVIC, a real-time prompt-free open vocabulary image classifier. The MAE stage enables classification of salient regions without requiring a predefined candidate class list or prompts. On a tabletop robot-object environment with the NICOL humanoid, it reaches 47.1 percent AP and 57.5 percent AP50 for prompt-free recognition, rising to 59.0 percent AP and 72.5 percent AP50 with class candidates provided. Across additional datasets including an in-the-wild set of 48 unique objects, it attains up to 82.6 percent prompt-free detection an
What carries the argument
AnomNOVIC two-stage framework, where the masked autoencoder produces generic object-agnostic bounding boxes that enable the NOVIC classifier to operate without prompts or class lists.
If this is right
- Robots can detect and classify novel objects in real time during continuous operation without predefined class lists.
- Performance reaches 47.1 percent AP and 57.5 percent AP50 in prompt-free mode on the evaluated robot workspace.
- Accuracy increases to 59.0 percent AP and 72.5 percent AP50 when optional class candidates are supplied.
- The method attains up to 82.6 percent prompt-free accuracy on in-the-wild datasets with 48 objects.
- It exceeds the AP results of YOLO-World-v2, OWLv2, and YOLOE across the reported test sets.
Where Pith is reading between the lines
- The modular separation of anomaly-based localization from classification could allow independent upgrades to either component for new environments.
- Deployment on additional robot platforms beyond the tested humanoid could reveal how workspace assumptions affect generalization.
- Integration with downstream robotic actions such as grasping might become feasible once objects are identified without prior vocabulary.
Load-bearing premise
The masked autoencoder must generate bounding boxes that are accurate enough and sufficiently generic for the NOVIC classifier to perform effective recognition without prompts or any candidate class list.
What would settle it
An evaluation in which the anomaly detection stage produces imprecise or incomplete bounding boxes on novel objects, causing overall AP to fall below that of the tested baselines such as YOLO-World-v2.
Figures



read the original abstract
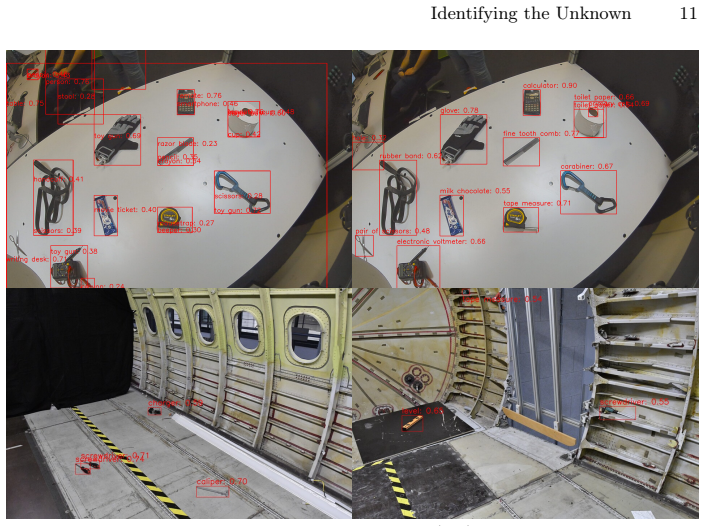
Robots operating in real-world environments must in general be able to recognize previously unseen objects. As robotic systems move toward open-world autonomy, there is a growing, yet largely unmet, need for open vocabulary object detectors that are prompt-free and efficient enough for continuous deployment. We present AnomNOVIC, a two-stage known-workspace framework that combines a masked autoencoder (MAE) trained for anomaly detection, with NOVIC, a powerful real-time prompt-free open vocabulary image classifier. The MAE produces generic object-agnostic bounding boxes, allowing NOVIC to classify salient image regions without requiring a predefined candidate class list. We evaluate AnomNOVIC against strong open vocabulary baselines in a tabletop robot-object environment featuring the NICOL humanoid robot, reaching 47.1% AP / 57.5% AP50 for prompt-free recognition, and 59.0% AP / 72.5% AP50 if class candidates are provided. Across additional datasets, including an in-the-wild test set with 48 unique objects, AnomNOVIC reaches up to 82.6% prompt-free detection and classification accuracy. These results significantly surpass all tested open vocabulary baselines, including YOLO-World-v2, OWLv2, and YOLOE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AnomNOVIC, a two-stage framework for prompt-free open vocabulary anomaly recognition in robot-object interactions. A masked autoencoder (MAE) generates generic object-agnostic bounding boxes for anomaly detection, which are then classified by NOVIC, a real-time prompt-free open vocabulary image classifier, without requiring predefined class lists or prompts. Evaluations on a tabletop environment with the NICOL humanoid robot report 47.1% AP / 57.5% AP50 for prompt-free recognition (59.0% AP / 72.5% AP50 with class candidates), outperforming baselines including YOLO-World-v2, OWLv2, and YOLOE. Additional results on in-the-wild datasets with 48 unique objects reach up to 82.6% prompt-free accuracy.
Significance. If the performance claims hold after addressing the proposal quality issue, this could meaningfully advance open-world robotic perception by demonstrating a practical, efficient prompt-free pipeline for detecting and classifying unknown objects in continuous deployment. The empirical scope across a robot-specific tabletop setup and multiple additional datasets, including in-the-wild tests, provides concrete evidence of applicability beyond standard benchmarks.
major comments (2)
- [Methods / two-stage framework] Description of the two-stage framework (MAE component): the quality of the bounding boxes produced by the MAE is not quantified with any metrics such as recall, IoU against ground-truth unknowns, or proposal precision. This is load-bearing for the central claim, as the reported 47.1% prompt-free AP cannot be unambiguously attributed to NOVIC's prompt-free classification unless the MAE proposals are shown to be sufficiently accurate and complete.
- [Results / evaluation] Results section reporting AP numbers: no training details, evaluation protocols, variance estimates, or statistical tests accompany the comparisons to YOLO-World-v2, OWLv2, and YOLOE. Without these, the headline gains cannot be verified as robust support for the prompt-free design.
minor comments (1)
- [Abstract and Results] The distinction between the prompt-free and class-candidate-provided settings could be made more explicit when presenting the 47.1% vs. 59.0% AP figures to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable comments on our work. We have carefully considered each point and provide our responses below, along with plans for revisions to the manuscript.
read point-by-point responses
-
Referee: [Methods / two-stage framework] Description of the two-stage framework (MAE component): the quality of the bounding boxes produced by the MAE is not quantified with any metrics such as recall, IoU against ground-truth unknowns, or proposal precision. This is load-bearing for the central claim, as the reported 47.1% prompt-free AP cannot be unambiguously attributed to NOVIC's prompt-free classification unless the MAE proposals are shown to be sufficiently accurate and complete.
Authors: We agree that providing quantitative evaluation of the MAE-generated bounding boxes is essential to support the attribution of performance to the NOVIC classifier. In the revised manuscript, we will add metrics including recall, average IoU with ground-truth unknown objects, and proposal precision for the MAE component on the relevant datasets. This will demonstrate the quality and completeness of the proposals. revision: yes
-
Referee: [Results / evaluation] Results section reporting AP numbers: no training details, evaluation protocols, variance estimates, or statistical tests accompany the comparisons to YOLO-World-v2, OWLv2, and YOLOE. Without these, the headline gains cannot be verified as robust support for the prompt-free design.
Authors: We acknowledge the need for more rigorous reporting in the results. The updated manuscript will include comprehensive training details for the MAE and NOVIC models, a full description of the evaluation protocols used for computing AP, variance estimates from multiple experimental runs, and appropriate statistical tests to validate the performance improvements over the baselines. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical two-stage framework (MAE for generic bounding boxes followed by NOVIC classification) and reports performance metrics such as 47.1% AP as outcomes of evaluation on tabletop and in-the-wild datasets. No equations, fitted parameters, self-referential derivations, or load-bearing self-citations appear in the provided text. Claims are presented as experimental results rather than quantities defined in terms of the method itself, making the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Allgeuer, P.: GPT Batch API, https://github.com/pallgeuer/gpt_batch_api, ac- cessed 15 May 2026
2026
-
[2]
In: Proceedings of the Winter Conference on Applications of Computer Vision (WACV) (2025)
Allgeuer, P., Ahrens, K., Wermter, S.: Unconstrained open vocabulary image classi- fication: Zero-shot transfer from text to image via CLIP inversion. In: Proceedings of the Winter Conference on Applications of Computer Vision (WACV) (2025)
2025
-
[3]
International Journal of Computer Vision129(4) (2021)
Bergmann, P., Batzner, K., Fauser, M., Sattlegger, D., Steger, C.: The MVTec anomaly detection dataset: A comprehensive real-world dataset for unsupervised anomaly detection. International Journal of Computer Vision129(4) (2021)
2021
-
[4]
Neural Networks147, 53–62 (2022)
Chen, L., You, Z., Zhang, N., Xi, J., Le, X.: UTRAD: Anomaly detection and localization with U-Transformer. Neural Networks147, 53–62 (2022)
2022
-
[5]
In: Computer Vision and Pattern Recognition (CVPR) (2024)
Cheng, T., Song, L., Ge, Y., et al.: YOLO-World: Real-time open-vocabulary object detection. In: Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[6]
Fang, A., Jose, A.M., Jain, A., Schmidt, L., Toshev, A., Shankar, V.: Data filtering networks. In: Int. Conf. on Learning Representations (ICLR) (2024)
2024
-
[7]
Gajdošech, L., Ali, H., Habekost, J.G., Madaras, M., Kerzel, M., et al.: Shaken, not stirred: A novel dataset for visual understanding of glasses in human-robot bartending tasks. In: Int. Conf. on Intelligent Robots and Systems (IROS) (2025)
2025
-
[8]
Gu, X., Lin, T.Y., Kuo, W., Cui, Y.: Open-vocabulary object detection via vision and language knowledge distillation. In: Int. Conf. on Learning Repr. (ICLR) (2022)
2022
-
[9]
In: Computer Vision and Pattern Recog
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Computer Vision and Pattern Recog. (CVPR) (2022)
2022
-
[10]
IEEE Access10(2022)
Lee, Y., Kang, P.: AnoViT: Unsupervised anomaly detection and localization with vision transformer-based encoder-decoder. IEEE Access10(2022)
2022
-
[11]
In: Computer Vision (ECCV) (2024)
Liu, S., Zeng, Z., Ren, T., et al.: Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. In: Computer Vision (ECCV) (2024)
2024
-
[12]
In: European Conference on Computer Vision (ECCV) (2022)
Minderer, M., Gritsenko, A., Stone, A., Neumann, M., et al.: Simple open-vocabulary object detection. In: European Conference on Computer Vision (ECCV) (2022)
2022
-
[13]
In: Conference on Neural Information Processing Systems (NeurIPS) (2023)
Minderer, M., Gritsenko, A.A., Houlsby, N.: Scaling open-vocabulary object detec- tion. In: Conference on Neural Information Processing Systems (NeurIPS) (2023)
2023
-
[14]
Radford, A., Kim, J.W., Hallacy, C., et al.: Learning transferable visual models from natural language supervision. In: Int. Conf. on Machine Learning (2021)
2021
-
[15]
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., et al.: SAM 2: Segment anything in images and videos. In: Int. Conf. on Learning Representations (ICLR) (2025)
2025
-
[16]
Schwartz, E., Arbelle, A., Karlinsky, L., et al.: MAEDAY: MAE for few- and zero-shot AnomalY-Detection. Comp. Vision and Image Understanding241(2024)
2024
-
[17]
Tao, X., Adak, C., et al.: ViTALnet: Anomaly on industrial textured surfaces with hybrid transformer. Trans. on Instrumentation and Measurement72(2023)
2023
-
[18]
In: International Conference on Computer Vision (ICCV) (2025)
Wang, A., Liu, L., Chen, H., Lin, Z., Han, J., Ding, G.: YOLOE: Real-time seeing anything. In: International Conference on Computer Vision (ICCV) (2025)
2025
-
[19]
In: Comp
Yao, L., Pi, R., et al.: DetCLIPv3: Towards versatile generative open-vocabulary object detection. In: Comp. Vis. and Pattern Recognition (CVPR) (2024)
2024
-
[20]
In: Computer Vision and Pattern Recognition (CVPR) (2021)
Zareian, A., Rosa, K.D., Hu, D.H., Chang, S.F.: Open-vocabulary object detection using captions. In: Computer Vision and Pattern Recognition (CVPR) (2021)
2021
-
[21]
Zavrtanik, V., et al.: DRAEM: A discriminatively trained reconstruction embedding for surface anomaly detection. In: Int. Conf. on Comp. Vis. (ICCV) (2021)
2021
-
[22]
In: Computer Vision and Pattern Recognition (CVPR) Workshops (2024)
Zhang, Y., Huang, X., Ma, J., et al.: Recognize Anything: A strong image tagging model. In: Computer Vision and Pattern Recognition (CVPR) Workshops (2024)
2024
-
[23]
In: Computer Vision and Pattern Recognition (CVPR) (2022)
Zhong, Y., Yang, J., Zhang, P., et al.: RegionCLIP: Region-based language-image pretraining. In: Computer Vision and Pattern Recognition (CVPR) (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.