Autoregressive Boltzmann Generators
Pith reviewed 2026-06-26 04:48 UTC · model grok-4.3
The pith
Autoregressive models generate Boltzmann-distributed molecular samples without the constraints of normalizing flows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
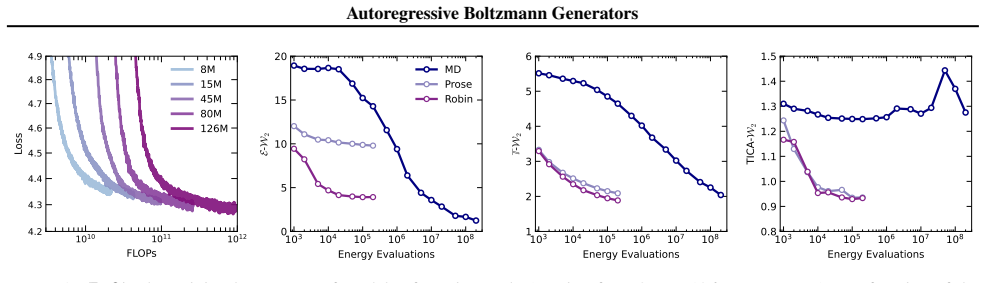
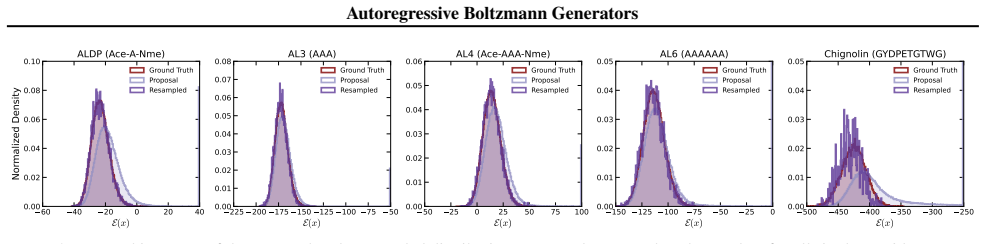
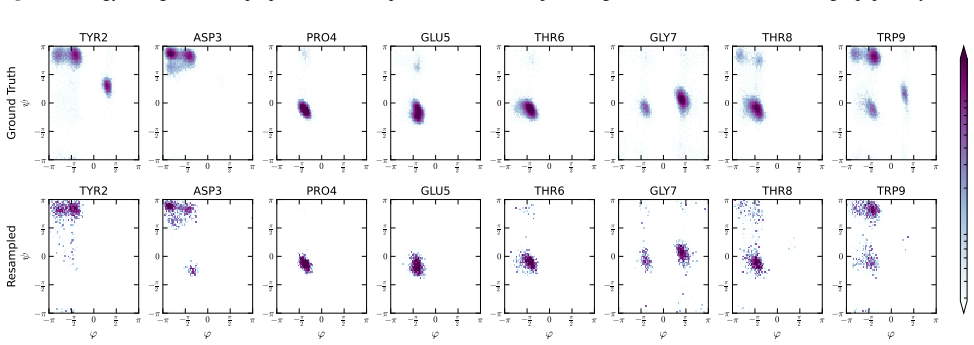
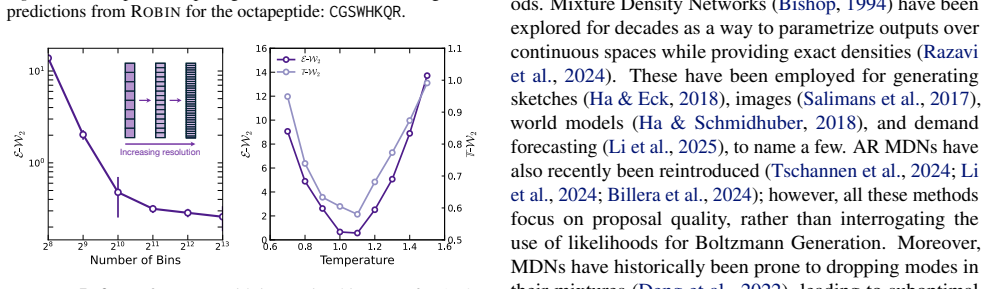
ArBG replaces normalizing-flow Boltzmann generators with an autoregressive framework that produces sequential proposals whose exact likelihoods, after importance-sampling correction, recover the target Boltzmann distribution; the resulting models outperform flow-based baselines on all tested peptide systems and enable a 132-million-parameter transferable model that reduces E-W₂ error by over 60 percent on 8-residue cases.
What carries the argument
Autoregressive proposal model that supplies exact likelihoods for importance-sampling correction in place of invertible flow transformations.
If this is right
- ArBG removes the topological and computational limits that restrict flow-based Boltzmann generators.
- Sequential architectures effective for language modeling become directly usable for molecular sampling.
- Inference-time interventions on individual residues become feasible because generation is sequential.
- Performance gains are largest on bigger peptide systems where flow expressivity previously limited accuracy.
- A single 132-million-parameter model can be trained to transfer across multiple residue lengths.
Where Pith is reading between the lines
- The framework may extend to other chain-like molecular systems such as proteins or RNA where sequential generation aligns with physical structure.
- Combining ArBG proposals with modern large-scale training regimes could further lower the cost of equilibrium sampling in drug-discovery pipelines.
- Because likelihoods remain exact, hybrid schemes that mix autoregressive steps with occasional flow or MCMC corrections could be explored without losing theoretical guarantees.
Load-bearing premise
An autoregressive model can be trained so that its proposals, once reweighted by importance sampling, recover the exact target Boltzmann distribution.
What would settle it
Training an autoregressive proposal model on a known small peptide and then measuring whether the importance-weighted energy histogram matches the reference Boltzmann distribution to within sampling noise.
Figures
read the original abstract
Efficient sampling of molecular systems at thermodynamic equilibrium is a hallmark challenge in statistical physics. This challenge has driven the development of Boltzmann Generators (BGs), which allow rapid generation of uncorrelated equilibrium samples by combining a generative model with exact likelihoods and an importance sampling correction. However, modern BGs predominantly rely on normalizing flows (NFs), which either suffer from limited expressivity due to strict invertibility constraints (discrete time) or computationally expensive likelihoods (continuous time). In this paper, we propose Autoregressive Boltzmann Generators (ArBG) -- a novel autoregressive modelling framework -- that overcomes these limitations by departing from the flow-based BG paradigm. ArBG circumvents the topological constraints of flows and enables sequential inference-time interventions, while offering enhanced scalability by leveraging architectures effective in Large Language Models. We empirically demonstrate that ArBG leads to significant improvements over flow-based models across all benchmarks, but particularly in larger peptide systems such as the 10-residue Chignolin. Furthermore, we introduce Robin, a 132 million parameter transferable model trained with the ArBG framework which improves over the previous state-of-the-art, reducing the zero-shot energy error, E-W$_2$, on 8-residue systems by over 60$\%$. The code can be found at the following link: https://github.com/danyalrehman/autobg.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Autoregressive Boltzmann Generators (ArBG), a framework replacing normalizing flows in Boltzmann Generators with autoregressive models for sampling equilibrium configurations of molecular systems. It claims that ArBG overcomes invertibility and computational limits of flows, enables sequential interventions, and yields significant empirical improvements over flow-based models on all benchmarks, especially larger peptides such as 10-residue Chignolin. It further introduces Robin, a 132-million-parameter transferable model trained under the ArBG framework that reduces zero-shot energy error E-W₂ by over 60% on 8-residue systems relative to prior state-of-the-art.
Significance. If the central claims hold, ArBG would represent a meaningful advance by demonstrating that autoregressive factorizations can supply tractable exact densities suitable for importance-sampling correction to the Boltzmann distribution, while scaling via LLM-style architectures to larger systems where flows are limited. The reported gains on Chignolin and the transferable Robin model would indicate practical utility for peptide sampling and transferable generative models in statistical physics.
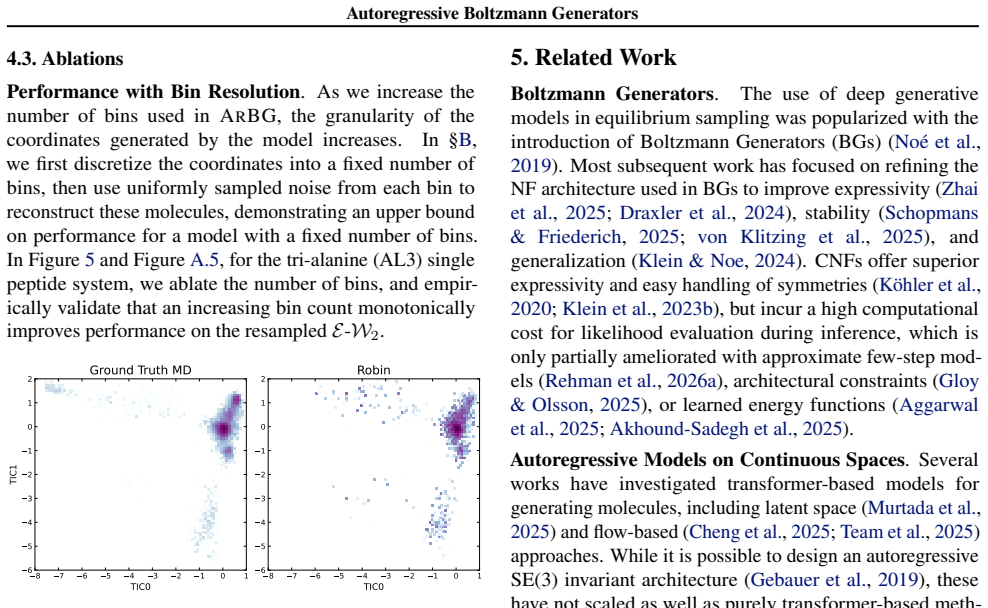
major comments (2)
- [Abstract] Abstract: The claim that autoregressive proposals q(x) supply exact, order-independent likelihoods whose importance weights p(x)/q(x) recover unbiased samples from the target Boltzmann distribution is load-bearing for all performance assertions. The provided text gives no derivation or empirical test showing that a fixed coordinate ordering avoids long-range correlation artifacts that cannot be corrected by reweighting alone.
- [Abstract] Abstract: The reported improvements (including the >60% reduction in E-W₂ for Robin on 8-residue systems and gains on 10-residue Chignolin) are presented without reference to any independent reference sampler, effective sample size diagnostics, or explicit verification that the reweighted distribution matches the target beyond energy-based metrics; this leaves the central unbiased-sampling claim unsupported.
Simulated Author's Rebuttal
We thank the referee for their comments, which highlight important aspects of the theoretical and empirical support for ArBG. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that autoregressive proposals q(x) supply exact, order-independent likelihoods whose importance weights p(x)/q(x) recover unbiased samples from the target Boltzmann distribution is load-bearing for all performance assertions. The provided text gives no derivation or empirical test showing that a fixed coordinate ordering avoids long-range correlation artifacts that cannot be corrected by reweighting alone.
Authors: Autoregressive models define an exact joint density by the chain rule: q(x) = q(x_1) ∏_i q(x_i | x_<i). This factorization yields an exact likelihood for any fixed ordering, independent of the target Boltzmann density p. Importance sampling with weights w(x) = p(x)/q(x) is unbiased for expectations under p by the standard importance-sampling identity, regardless of ordering. Ordering influences the variance of the weights (i.e., sampling efficiency) but does not introduce bias that reweighting cannot correct. We will insert a short derivation of this fact in Section 2 and a brief discussion of ordering effects on long-range correlations. revision: yes
-
Referee: [Abstract] Abstract: The reported improvements (including the >60% reduction in E-W_{2} for Robin on 8-residue systems and gains on 10-residue Chignolin) are presented without reference to any independent reference sampler, effective sample size diagnostics, or explicit verification that the reweighted distribution matches the target beyond energy-based metrics; this leaves the central unbiased-sampling claim unsupported.
Authors: We agree that explicit diagnostics strengthen the empirical case. In the revised manuscript we will report effective sample sizes for the reweighted ensembles, include comparisons against independent reference samplers (e.g., long MD trajectories) on the smaller systems, and add a direct check that the reweighted marginals on selected observables align with the reference. The energy-based E-W_{2} metric remains central because it directly quantifies deviation from the Boltzmann distribution, but the additional diagnostics will be included. revision: yes
Circularity Check
No circularity: ArBG claims rest on empirical benchmarks and architectural departure from flows, not self-referential fits or derivations.
full rationale
The abstract and provided text introduce ArBG as an autoregressive alternative to normalizing flows for Boltzmann generators, citing empirical gains on peptides and a large Robin model. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the given material. Performance claims (e.g., E-W2 reduction) are presented as measured outcomes on external benchmarks rather than quantities forced by construction from the model's own training data or prior self-references. The central premise—that autoregressive factorizations yield tractable exact densities correctable by importance sampling—is stated as a modeling choice with no reduction to tautology shown.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , journal=
MD-LLM-1: A Large Language Model for Molecular Dynamics , author=. 2025 , journal=
2025
-
[2]
2025 , eprint=
FARMER: Flow AutoRegressive Transformer over Pixels , author=. 2025 , eprint=
2025
-
[3]
The Continuous Language of Protein Structure , elocation-id =
Billera, Lukas and Oresten, Anton and St. The Continuous Language of Protein Structure , elocation-id =. 2024 , doi =
2024
-
[4]
2025 , eprint=
NextStep-1: Toward Autoregressive Image Generation with Continuous Tokens at Scale , author=. 2025 , eprint=
2025
-
[5]
2016 , booktitle=
Conditional Image Generation with PixelCNN Decoders , author=. 2016 , booktitle=
2016
-
[6]
2025 , booktitle=
HollowFlow: Efficient Sample Likelihood Evaluation using Hollow Message Passing , author=. 2025 , booktitle=
2025
-
[7]
2024 , booktitle=
Autoregressive Image Generation without Vector Quantization , author=. 2024 , booktitle=
2024
-
[8]
2026 , booktitle=
FALCON: Few-step Accurate Likelihoods for Continuous Flows , author=. 2026 , booktitle=
2026
-
[9]
2024 , booktitle=
GIVT: Generative Infinite-Vocabulary Transformers , author=. 2024 , booktitle=
2024
-
[10]
2026 , author =
Generative molecular dynamics , journal =. 2026 , author =
2026
-
[11]
Physical review , volume=
Correlations in the motion of atoms in liquid argon , author=. Physical review , volume=. 1964 , publisher=
1964
-
[12]
Studies in molecular dynamics. I. General method , author=. The Journal of Chemical Physics , volume=. 1959 , publisher=
1959
-
[13]
arXiv preprint arXiv:2202.04164 , year=
Enhanced sampling methods for molecular dynamics simulations , author=. arXiv preprint arXiv:2202.04164 , year=
-
[14]
2025 , eprint=
Scalable Autoregressive 3D Molecule Generation , author=. 2025 , eprint=
2025
-
[15]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Syed, Saifuddin and Bouchard-Côté, Alexandre and Deligiannidis, George and Doucet, Arnaud , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
-
[16]
2026 , booktitle=
MarS-FM: Generative Modeling of Molecular Dynamics via Markov State Models , author=. 2026 , booktitle=
2026
-
[17]
2024 , eprint=
Force-Guided Bridge Matching for Full-Atom Time-Coarsened Dynamics of Peptides , author=. 2024 , eprint=
2024
-
[18]
2024 , eprint=
EquiJump: Protein Dynamics Simulation via SO(3)-Equivariant Stochastic Interpolants , author=. 2024 , eprint=
2024
-
[19]
2024 , eprint=
Scaling Diffusion Language Models via Adaptation from Autoregressive Models , author=. 2024 , eprint=
2024
-
[20]
2024 , eprint=
DPLM-2: A Multimodal Diffusion Protein Language Model , author=. 2024 , eprint=
2024
-
[21]
2024 , eprint=
Scaling up Masked Diffusion Models on Text , author=. 2024 , eprint=
2024
-
[22]
Nature , pages=
Accurate structure prediction of biomolecular interactions with AlphaFold 3 , author=. Nature , pages=. 2024 , publisher=
2024
-
[23]
Algorithms for molecular biology , volume=
ViennaRNA Package 2.0 , author=. Algorithms for molecular biology , volume=. 2011 , publisher=
2011
-
[24]
Bioinformatics , volume=
Forna (force-directed RNA): Simple and effective online RNA secondary structure diagrams , author=. Bioinformatics , volume=. 2015 , publisher=
2015
-
[25]
Nucleic acids research , volume=
RNAcentral 2021: secondary structure integration, improved sequence search and new member databases , author=. Nucleic acids research , volume=. 2021 , publisher=
2021
-
[26]
Nature Methods , pages=
Accurate RNA 3D structure prediction using a language model-based deep learning approach , author=. Nature Methods , pages=. 2024 , publisher=
2024
-
[27]
, title =
Chang, Huiwen and Zhang, Han and Jiang, Lu and Liu, Ce and Freeman, William T. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
2022
-
[28]
arXiv preprint arXiv:2403.00043 , year=
Rinalmo: General-purpose rna language models can generalize well on structure prediction tasks , author=. arXiv preprint arXiv:2403.00043 , year=
-
[29]
ArXiv , year=
Generative Flows on Discrete State-Spaces: Enabling Multimodal Flows with Applications to Protein Co-Design , author=. ArXiv , year=
-
[30]
ArXiv , year=
DPLM-2: A Multimodal Diffusion Protein Language Model , author=. ArXiv , year=
-
[31]
ArXiv , year=
Diffusion Language Models Are Versatile Protein Learners , author=. ArXiv , year=
-
[32]
ArXiv , year=
A Reparameterized Discrete Diffusion Model for Text Generation , author=. ArXiv , year=
-
[33]
ArXiv , year=
Think While You Generate: Discrete Diffusion with Planned Denoising , author=. ArXiv , year=
-
[34]
arXiv preprint arXiv:2406.04329 , year=
Simplified and Generalized Masked Diffusion for Discrete Data , author=. arXiv preprint arXiv:2406.04329 , year=
-
[35]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Simple and Effective Masked Diffusion Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[36]
Sofroniew, Deniz Oktay, Zeming Lin, Robert Verkuil, Vincent Q
Thomas Hayes and Roshan Rao and Halil Akin and Nicholas J. Sofroniew and Deniz Oktay and Zeming Lin and Robert Verkuil and Vincent Q. Tran and Jonathan Deaton and Marius Wiggert and Rohil Badkundri and Irhum Shafkat and Jun Gong and Alexander Derry and Raul S. Molina and Neil Thomas and Yousuf A. Khan and Chetan Mishra and Carolyn Kim and Liam J. Bartie a...
-
[37]
Evolutionary-scale prediction of atomic-level protein structure with a language model , volume =
Zeming Lin and Halil Akin and Roshan Rao and Brian Hie and Zhongkai Zhu and Wenting Lu and Nikita Smetanin and Robert Verkuil and Ori Kabeli and Yaniv Shmueli and Allan dos Santos Costa and Maryam Fazel-Zarandi and Tom Sercu and Salvatore Candido and Alexander Rives , title =. Science , volume =. 2023 , doi =. https://www.science.org/doi/pdf/10.1126/scien...
-
[38]
ArXiv , year=
The LAMBADA dataset: Word prediction requiring a broad discourse context , author=. ArXiv , year=
-
[39]
ArXiv , year=
Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling , author=. ArXiv , year=
-
[40]
International Conference on Machine Learning , year=
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author=. International Conference on Machine Learning , year=
-
[41]
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[42]
ArXiv , year=
Training Verifiers to Solve Math Word Problems , author=. ArXiv , year=
-
[43]
ArXiv , year=
A Corpus and Cloze Evaluation for Deeper Understanding of Commonsense Stories , author=. ArXiv , year=
-
[44]
ArXiv , year=
Efficient Training of Language Models to Fill in the Middle , author=. ArXiv , year=
-
[45]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[46]
ArXiv , year=
Lessons from the Trenches on Reproducible Evaluation of Language Models , author=. ArXiv , year=
-
[47]
ArXiv , year=
Likelihood-Based Diffusion Language Models , author=. ArXiv , year=
-
[48]
ArXiv , year=
TinyLlama: An Open-Source Small Language Model , author=. ArXiv , year=
-
[49]
arXiv preprint arXiv:2311.07468 , year=
Are we falling in a middle-intelligence trap? an analysis and mitigation of the reversal curse , author=. arXiv preprint arXiv:2311.07468 , year=
-
[50]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[51]
The reversal curse: Llms trained on" a is b" fail to learn" b is a" , author=. arXiv preprint arXiv:2309.12288 , year=
-
[52]
ArXiv , year=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. ArXiv , year=
-
[53]
2019 , journal=
Language Models are Unsupervised Multitask Learners , author=. 2019 , journal=
2019
-
[54]
Cell systems , year=
ProGen2: Exploring the Boundaries of Protein Language Models , author=. Cell systems , year=
-
[55]
bioRxiv , year=
Protein generation with evolutionary diffusion: sequence is all you need , author=. bioRxiv , year=
-
[56]
2024 , eprint=
Informed Correctors for Discrete Diffusion Models , author=. 2024 , eprint=
2024
-
[57]
2024 , eprint=
Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling , author=. 2024 , eprint=
2024
-
[58]
bioRxiv , year=
Efficient evolution of human antibodies from general protein language models and sequence information alone , author=. bioRxiv , year=
-
[59]
ArXiv , year=
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations , author=. ArXiv , year=
-
[60]
ArXiv , year=
RoBERTa: A Robustly Optimized BERT Pretraining Approach , author=. ArXiv , year=
-
[61]
North American Chapter of the Association for Computational Linguistics , year=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. North American Chapter of the Association for Computational Linguistics , year=
-
[62]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[63]
2024 , eprint=
How Discrete and Continuous Diffusion Meet: Comprehensive Analysis of Discrete Diffusion Models via a Stochastic Integral Framework , author=. 2024 , eprint=
2024
-
[64]
2013 , publisher =
Limit theorems for stochastic processes , author =. 2013 , publisher =
2013
-
[65]
ArXiv , year=
Score-based Continuous-time Discrete Diffusion Models , author=. ArXiv , year=
-
[66]
2024 , eprint=
Discrete Flow Matching , author=. 2024 , eprint=
2024
-
[67]
Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg , title =
Jacob Austin and Daniel D. Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg , title =. CoRR , volume =. 2021 , url =. 2107.03006 , timestamp =
arXiv 2021
-
[68]
2022 , eprint=
A Continuous Time Framework for Discrete Denoising Models , author=. 2022 , eprint=
2022
-
[69]
George and Zhang, Qing , year =
Yin, G. George and Zhang, Qing , year =. Continuous-. doi:10.1007/978-1-4614-4346-9 , keywords =
-
[70]
2024 , eprint=
Simple Guidance Mechanisms for Discrete Diffusion Models , author=. 2024 , eprint=
2024
-
[71]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Benton, Joe and Shi, Yuyang and De Bortoli, Valentin and Deligiannidis, George and Doucet, Arnaud , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2024 , month =. doi:10.1093/jrsssb/qkae005 , url =
-
[72]
2024 , eprint=
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data , author=. 2024 , eprint=
2024
-
[73]
Proceedings of the 31th International Conference on Machine Learning , year =
Benigno Uria and Iain Murray and Hugo Larochelle , title =. Proceedings of the 31th International Conference on Machine Learning , year =
-
[74]
Gritsenko and Jasmijn Bastings and Ben Poole and Rianne van den Berg and Tim Salimans , title =
Emiel Hoogeboom and Alexey A. Gritsenko and Jasmijn Bastings and Ben Poole and Rianne van den Berg and Tim Salimans , title =. 10th International Conference on Learning Representations , year =
-
[75]
Budhiraja, Amarjit and Dupuis, Paul , year =. Analysis and. doi:10.1007/978-1-4939-9579-0 , keywords =
-
[76]
2022 , eprint=
Training and Inference on Any-Order Autoregressive Models the Right Way , author=. 2022 , eprint=
2022
-
[77]
2021 , eprint=
Discovering Non-monotonic Autoregressive Orderings with Variational Inference , author=. 2021 , eprint=
2021
-
[78]
A general method for numerically simulating the stochastic time evolution of coupled chemical reactions , journal =. 1976 , issn =. doi:https://doi.org/10.1016/0021-9991(76)90041-3 , url =
-
[79]
, author=
GFN2-xTB-An Accurate and Broadly Parametrized Self-Consistent Tight-Binding Quantum Chemical Method with Multipole Electrostatics and Density-Dependent Dispersion Contributions. , author=. Journal of chemical theory and computation , year=
-
[80]
The Journal of Physical Chemistry , author =
Exact stochastic simulation of coupled chemical reactions , volume =. The Journal of Physical Chemistry , author =. 1977 , note =. doi:10.1021/j100540a008 , number =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.