PhysiFormer: Learning to Simulate Mechanics in World Space
Pith reviewed 2026-06-26 05:08 UTC · model grok-4.3
The pith
Casting vertex trajectory prediction as a single denoising diffusion process directly in world coordinates produces physically plausible 3D mesh motion without explicit inductive biases for rigidity or causality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that excellent results on physically-plausible 3D object motion can be obtained without ad-hoc latent spaces or explicit enforcement of rigidity and causality by representing objects as 3D meshes in world coordinates and casting vertex trajectory prediction as a single denoising diffusion process directly in those coordinates.
What carries the argument
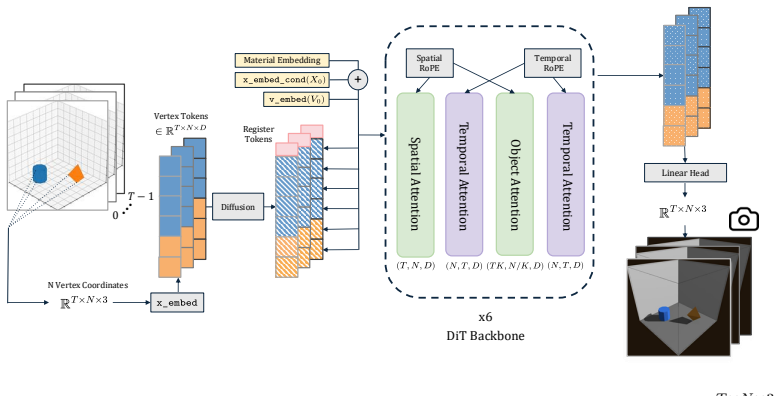
A diffusion transformer whose attention is factorised over time, space, and objects, performing denoising directly on vertex positions and velocities in world coordinates.
If this is right
- The probabilistic formulation enables sampling of multiple diverse yet plausible futures from identical initial conditions.
- Factorised attention supports permutation-invariant reasoning over multiple objects without explicit object encodings.
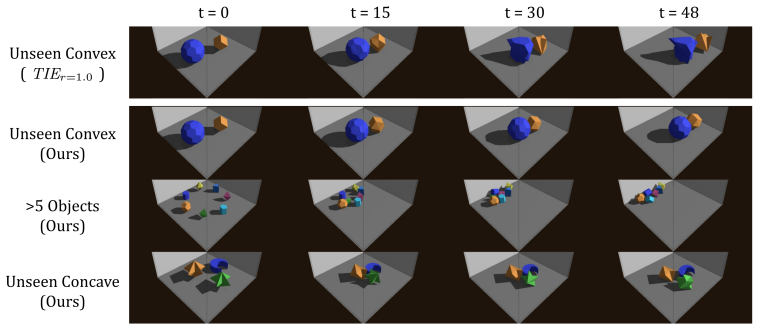
- The model generalises to mixed rigid-elastic interactions and to object counts and real-world geometries not seen during training.
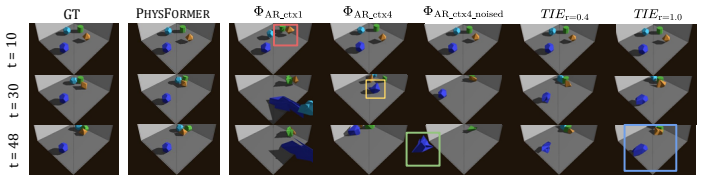
- Training on simulated data yields substantially higher trajectory accuracy, rigidity preservation, and physical consistency than autoregressive baselines.
Where Pith is reading between the lines
- The world-coordinate formulation could integrate directly with 3D reconstruction systems to enable physical prediction from partial observations.
- Fine-tuning the trained model on limited real motion-capture data might close the remaining sim-to-real gap for robotic manipulation tasks.
- Extending the vertex representation to include additional surface properties could allow the same diffusion process to handle contact with deformable environments.
Load-bearing premise
Trajectories generated by the underlying simulator constitute a sufficient and unbiased training distribution that supports generalization to real-world geometries and mixed-material interactions.
What would settle it
A controlled test in which the model produces trajectories that violate momentum conservation or lose rigidity when applied to a real scanned object with material properties and geometry outside the training distribution would falsify the central claim.
Figures



read the original abstract
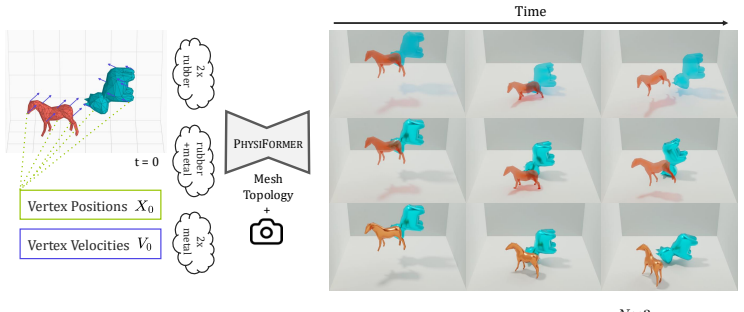
We present PhysiFormer, a diffusion transformer for physically-plausible 3D object motion. Unlike video world models that operate in view-dependent pixel space, PhysiFormer represents objects as 3D meshes expressed in world coordinates. Given the initial vertex positions and velocities, as well as object material type, rigid or elastic, the model samples future vertex trajectories. While related neural physics approaches build on ad-hoc latent spaces or explicitly enforce rigidity and causality, PhysiFormer shows that excellent results can be obtained without any such inductive biases, by casting vertex trajectory prediction as a single denoising diffusion process directly in world coordinates. The probabilistic formulation captures uncertainty in the learned dynamics, enabling diverse plausible futures from initial conditions, making this framework potentially useful for applications with unobserved uncertainty. The model features attention factorised over time, space, and objects for efficiency, enabling permutation-invariant multi-object reasoning without needing explicit object encoding. Trained on over 100k simulated trajectories, PhysiFormer generates rigid and elastic mechanics, and generalises to mixed-material settings, unseen real-world geometries, and larger object counts. It substantially outperforms autoregressive baselines in trajectory accuracy, rigidity preservation, and momentum-based physical consistency. Our results position coordinate-space diffusion as a promising step toward view-invariant, geometry-aware world modelling for robotics, graphics, and physical design. Visualisations, code, and models are available at https://yimingc9.github.io/physiformer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PhysiFormer, a diffusion transformer that predicts 3D mesh vertex trajectories directly in world coordinates via a single denoising diffusion process. Given initial positions, velocities, and material type (rigid or elastic), the model generates future trajectories without explicit rigidity, causality, or latent-space inductive biases. Trained on over 100k simulated trajectories, it claims to produce physically consistent rigid and elastic motion, generalize to mixed-material interactions, unseen real-world geometries, and larger object counts, and substantially outperform autoregressive baselines on trajectory accuracy, rigidity preservation, and momentum consistency. The probabilistic formulation allows sampling diverse plausible futures, and the architecture uses factorized attention over time, space, and objects for efficiency and permutation invariance.
Significance. If the central claims hold, the work provides evidence that coordinate-space diffusion can achieve strong physical plausibility and generalization without hand-engineered biases or latent encodings, potentially simplifying geometry-aware world models for robotics, graphics, and design. The public release of code, models, and visualizations is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the claim of 'substantially outperforms autoregressive baselines in trajectory accuracy, rigidity preservation, and momentum-based physical consistency' is presented without any quantitative metrics, baseline definitions, error bars, or table references, leaving the magnitude and statistical reliability of the reported gains unassessable from the provided summary.
- [Abstract] Abstract and training description: the generalization claims to 'mixed-material settings, unseen real-world geometries, and larger object counts' rest on training exclusively on 100k single-object rigid/elastic simulator trajectories; no details are given on how the simulator's geometry and material sampling distribution matches real-world variation, so out-of-distribution performance could reflect memorization rather than the diffusion formulation.
minor comments (1)
- [Abstract] The abstract states that 'visualisations, code, and models are available' at a URL; the manuscript should include a brief statement on the exact license and reproducibility package contents.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve the clarity and specificity of the abstract claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'substantially outperforms autoregressive baselines in trajectory accuracy, rigidity preservation, and momentum-based physical consistency' is presented without any quantitative metrics, baseline definitions, error bars, or table references, leaving the magnitude and statistical reliability of the reported gains unassessable from the provided summary.
Authors: We agree that the abstract would be strengthened by including quantitative references. In the revised version we will update the abstract to cite specific metrics (e.g., relative error reductions) and point to the tables and sections that define the autoregressive baselines, report error bars, and present statistical comparisons. revision: yes
-
Referee: [Abstract] Abstract and training description: the generalization claims to 'mixed-material settings, unseen real-world geometries, and larger object counts' rest on training exclusively on 100k single-object rigid/elastic simulator trajectories; no details are given on how the simulator's geometry and material sampling distribution matches real-world variation, so out-of-distribution performance could reflect memorization rather than the diffusion formulation.
Authors: The experiments in Sections 4.3–4.4 evaluate zero-shot generalization on mixed-material interactions, unseen real-world geometries, and larger object counts. We acknowledge that the current manuscript provides limited explicit discussion of the simulator sampling distribution. We will add a dedicated paragraph in the dataset section detailing the geometry and material parameter ranges and will include a brief analysis relating these ranges to real-world variation to better support the generalization claims. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper trains PhysiFormer as a standard denoising diffusion process on externally generated simulation data (over 100k trajectories from rigid/elastic simulators) and evaluates using independent physical-consistency metrics such as trajectory accuracy, rigidity preservation, and momentum conservation. No load-bearing step reduces by construction to a fitted parameter, self-defined quantity, or self-citation chain; the central modeling choice (world-coordinate diffusion without explicit rigidity/causality biases) is an architectural decision whose performance is measured against external baselines and held-out data rather than being tautological with its inputs. Generalization claims rest on empirical results rather than definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights
axioms (1)
- domain assumption Simulated trajectories accurately capture rigid and elastic mechanics for the objects used in training.
Reference graph
Works this paper leans on
-
[1]
Building normalizing flows with stochastic interpolants
Michael S Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InProc. ICLR, 2023
2023
-
[2]
Learning rigid dynamics with face interaction graph networks.arXiv preprint arXiv:2212.03574, 2022
Kelsey R Allen, Yulia Rubanova, Tatiana Lopez-Guevara, William Whitney, Alvaro Sanchez- Gonzalez, Peter Battaglia, and Tobias Pfaff. Learning rigid dynamics with face interaction graph networks.arXiv preprint arXiv:2212.03574, 2022
-
[3]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba, Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, Xia...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Genesis: A generative and universal physics engine for robotics and beyond,
Genesis Authors. Genesis: A generative and universal physics engine for robotics and beyond,
-
[5]
URLhttps://github.com/Genesis-Embodied-AI/Genesis
-
[6]
Large steps in cloth simulation
David Baraff and Andrew Witkin. Large steps in cloth simulation. InProc. SIGGRAPH, 1998
1998
-
[7]
Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, and Koray Kavukcuoglu
Peter W. Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, and Koray Kavukcuoglu. Interaction networks for learning about objects, relations and physics. In Proc. NeurIPS, 2016
2016
-
[8]
Prediction of aerodynamic flow fields using convolutional neural networks.Computational Mechanics, 64(2), 2019
Saakaar Bhatnagar, Yaser Afshar, Shaowu Pan, Karthik Duraisamy, and Shailendra Kaushik. Prediction of aerodynamic flow fields using convolutional neural networks.Computational Mechanics, 64(2), 2019
2019
-
[9]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv.cs, abs/2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InProc. CVPR, 2023
2023
-
[11]
Projective dynamics: Fusing constraint projections for fast simulation
Sofien Bouaziz, Sebastian Martin, Tiantian Liu, Ladislav Kavan, and Mark Pauly. Projective dynamics: Fusing constraint projections for fast simulation. InProc. SIGGRAPH, 2014
2014
-
[12]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. Technical report, OpenAI, 2024
2024
-
[13]
A discussion of semi-supervised learning and transduction
Olivier Chapelle, Bernhard Schölkopf, and Alexander Zien. A discussion of semi-supervised learning and transduction. InSemi-Supervised Learning. The MIT Press, 2006
2006
-
[14]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Yilun Du, Diego Martí, et al. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InNeurIPS, 2024
2024
-
[15]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.arXiv, 2407.01392, 2024
Boyuan Chen, Diego Marti Monso, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.arXiv, 2407.01392, 2024
-
[16]
PhysGen3D: Crafting a miniature interactive world from a single image.CVPR, 2025
Boyuan Chen, Hanxiao Jiang, Shaowei Liu, Saurabh Gupta, Yunzhu Li, Hao Zhao, and Shenlong Wang. PhysGen3D: Crafting a miniature interactive world from a single image.CVPR, 2025
2025
-
[17]
Motion 3-to-4: 3D motion reconstruction for 4D synthesis.arXiv, 2601.14253, 2026
Hongyuan Chen, Xingyu Chen, Youjia Zhang, Zexiang Xu, and Anpei Chen. Motion 3-to-4: 3D motion reconstruction for 4D synthesis.arXiv, 2601.14253, 2026
-
[18]
Pybullet, a python module for physics simulation for games, robotics and machine learning, 2016
Erwin Coumans and Yunfei Bai. Pybullet, a python module for physics simulation for games, robotics and machine learning, 2016. URLhttp://pybullet.org. 11
2016
-
[19]
Vision transformers need registers.Proc
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers.Proc. ICLR, 2024
2024
-
[20]
A generalization of transformer networks to graphs
Vijay Prakash Dwivedi and Xavier Bresson. A generalization of transformer networks to graphs. Proc. AAAI Workshop, 2021
2021
-
[21]
arXiv preprint arXiv:2505.19386 (2025) 4
Nate Gillman, Charles Herrmann, Michael Freeman, Daksh Aggarwal, Evan Luo, Deqing Sun, and Chen Sun. Force prompting: Video generation models can learn and generalize physics-based control signals. InProc. NeurIPS, volume 2505.19386, 2025
-
[22]
Hood: Hierarchical graphs for generalized modelling of clothing dynamics
Artur Grigorev, Michael J Black, and Otmar Hilliges. Hood: Hierarchical graphs for generalized modelling of clothing dynamics. InProc. CVPR, 2023
2023
-
[23]
Convolutional neural networks for steady flow approximation
Xiaoxiao Guo, Wei Li, and Francesco Iorio. Convolutional neural networks for steady flow approximation. InProc. SIGKDD, 2016
2016
-
[24]
Query-key normal- ization for transformers.arXiv, 2020
Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. Query-key normal- ization for transformers.arXiv, 2020
2020
-
[25]
simple diffusion: End-to-end diffusion for high resolution images
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. simple diffusion: End-to-end diffusion for high resolution images. InProc. ICML, 2023
2023
-
[26]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv, 2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
PhysTwin: Physics-informed reconstruction and simulation of deformable objects from videos
Hanxiao Jiang, Hao-Yu Hsu, Kaifeng Zhang, Hsin-Ni Yu, Shenlong Wang, and Yunzhu Li. PhysTwin: Physics-informed reconstruction and simulation of deformable objects from videos. InProc. ICCV, 2025
2025
-
[28]
A solution for the best rotation to relate two sets of vectors.F oundations of Crystallography, 32(5), 1976
Wolfgang Kabsch. A solution for the best rotation to relate two sets of vectors.F oundations of Crystallography, 32(5), 1976
1976
-
[29]
How far is video generation from world model: A physical law perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective. InProc. ICML, 2025
2025
-
[30]
DINO- foresight: Looking into the future with DINO
Efstathios Karypidis, Ioannis Kakogeorgiou, Spyros Gidaris, and Nikos Komodakis. DINO- foresight: Looking into the future with DINO. InProc. NeurIPS, 2025
2025
-
[31]
3D Gaussian Splatting for real-time radiance field rendering.Proc
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3D Gaussian Splatting for real-time radiance field rendering.Proc. SIGGRAPH, 42(4), 2023
2023
-
[32]
Minh-Quan Le, Yuanzhi Zhu, Vicky Kalogeiton, and Dimitris Samaras. What about gravity in video generation? post-training Newton’s laws with verifiable rewards.arXiv, 2512.00425, 2025
-
[33]
Codimensional incremental potential contact
Minchen Li, Danny M Kaufman, and Chenfanfu Jiang. Codimensional incremental potential contact. InProc. SIGGRAPH, 2021
2021
-
[34]
Back to basics: Let denoising generative models denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise. In CVPR, 2025
2025
-
[35]
Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids
Yunzhu Li, Jiajun Wu, Russ Tedrake, Joshua B Tenenbaum, and Antonio Torralba. Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids. InProc. ICLR, 2019
2019
-
[36]
Learning visible connectivity dynamics for cloth smoothing
Xingyu Lin, Yufei Wang, Zixuan Huang, and David Held. Learning visible connectivity dynamics for cloth smoothing. InProc. CoRL, 2021
2021
-
[37]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv.cs, abs/2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
PhysGen: Rigid-body physics-grounded image-to-video generation
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang. PhysGen: Rigid-body physics-grounded image-to-video generation. InProc. ECCV, 2024. 12
2024
-
[39]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InProc. ICLR, 2023
2023
-
[40]
Black, Derek Nowrouzezahrai, Liam Paull, and Weiyang Liu
Zhen Liu, Yao Feng, Michael J. Black, Derek Nowrouzezahrai, Liam Paull, and Weiyang Liu. Meshdiffusion: Score-based generative 3d mesh modeling. InICLR, 2023
2023
-
[41]
Otaduy, and Steve Marschner
Eder Miguel, Derek Bradley, Bernhard Thomaszewski, Bernd Bickel, Wojciech Matusik, Miguel A. Otaduy, and Steve Marschner. Data-driven estimation of cloth simulation models. In Proc. Eurographics, 2012
2012
-
[42]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. InProc. ECCV, 2020
2020
-
[43]
Flexible neural representation for physics prediction
Damian Mrowca, Chengxu Zhuang, Elias Wang, Nick Haber, Fei-Fei Li, Josh Tenenbaum, and Daniel L K Yamins. Flexible neural representation for physics prediction. InProc. NeurIPS, 2018
2018
-
[44]
Particle-based fluid simulation for interactive applications
Matthias Müller, David Charypar, and Markus Gross. Particle-based fluid simulation for interactive applications. InProc. Eurographics, 2003
2003
-
[45]
Genie 3: A new frontier for world models, 2025
Jack Parker-Holder and Shlomi Fruchter. Genie 3: A new frontier for world models, 2025. URL https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/
2025
-
[46]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProc. ICCV, 2023
2023
-
[47]
Battaglia
Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter W. Battaglia. Learning mesh-based simulation with graph networks. InProc. ICLR, 2021
2021
-
[48]
Allen, William F
Yulia Rubanova, Tatiana Lopez-Guevara, Kelsey R. Allen, William F. Whitney, Kimberly Stachenfeld, and Tobias Pfaff. Learning rigid-body simulators over implicit shapes for large- scale scenes and vision. InProc. NeurIPS, volume k, 2024
2024
-
[49]
Battaglia
Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, and Peter W. Battaglia. Learning to simulate complex physics with graph networks. InProc. ICML, 2020
2020
-
[50]
The graph neural network model.IEEE Trans
Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model.IEEE Trans. on Neural Networks, 2009
2009
-
[51]
Transformer with implicit edges for particle-based physics simulation
Yidi Shao, Chen Change Loy, and Bo Dai. Transformer with implicit edges for particle-based physics simulation. InProc. ECCV, 2022
2022
-
[52]
Self-attention with relative position repre- sentations
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position repre- sentations. InProc. NAACL, 2018
2018
-
[53]
Noam M. Shazeer. GLU variants improve transformer. InarXiv, 2020
2020
-
[54]
Jianlin Su, Murtadha H. M. Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 2024
2024
-
[55]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. InProc.IROS, 2012
2012
-
[56]
Lagrangian fluid simulation with continuous convolutions
Benjamin Ummenhofer, Lukas Prantl, Nils Thuerey, and Vladlen Koltun. Lagrangian fluid simulation with continuous convolutions. InProc. ICLR, 2020
2020
-
[57]
A simple approach to nonlinear tensile stiffness for accurate cloth simulation
Pascal V olino, Nadia Magnenat-Thalmann, and Francois Faure. A simple approach to nonlinear tensile stiffness for accurate cloth simulation. InProc. SIGGRAPH, 2009
2009
-
[58]
Integrating physics and topology in neural networks for learning rigid body dynamics.Nature Communications, 16(1), 2025
Amaury Wei and Olga Fink. Integrating physics and topology in neural networks for learning rigid body dynamics.Nature Communications, 16(1), 2025. 13
2025
-
[59]
PhysGaussian: Physics-integrated 3D Gaussians for generative dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. PhysGaussian: Physics-integrated 3D Gaussians for generative dynamics. InProc. CVPR, 2024
2024
-
[60]
Learning flexible body collision dynamics with hierarchical contact mesh transformer
Youn-Yeol Yu, Jeongwhan Choi, Woojin Cho, Kookjin Lee, Nayong Kim, Kiseok Chang, ChangSeung Woo, Ilho Kim, SeokWoo Lee, Joon Young Yang, et al. Learning flexible body collision dynamics with hierarchical contact mesh transformer. InProc. ICLR, 2024
2024
-
[61]
RenderFormer: transformer- based neural rendering of triangle meshes with global illumination
Chong Zeng, Yue Dong, Pieter Peers, Hongzhi Wu, and Xin Tong. RenderFormer: transformer- based neural rendering of triangle meshes with global illumination. InProc. SIGGRAPH, 2025
2025
-
[62]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InProc. NeurIPS, 2019
2019
-
[63]
3DShape2VecSet: A 3d shape representation for neural fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3DShape2VecSet: A 3d shape representation for neural fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023
2023
-
[64]
3DShape2VecSet: A 3D shape representation for neural fields and generative diffusion models
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3DShape2VecSet: A 3D shape representation for neural fields and generative diffusion models. InACM Transactions on Graphics, 2023
2023
-
[65]
Gaussian variation field diffusion for high-fidelity video-to-4D synthesis
Bowen Zhang, Sicheng Xu, Chuxin Wang, Jiaolong Yang, Feng Zhao, Dong Chen, and Baining Guo. Gaussian variation field diffusion for high-fidelity video-to-4D synthesis. InProc. ICCV, 2025
2025
-
[66]
Dynamic 3D Gaussian tracking for graph- based neural dynamics modeling
Mingtong Zhang, Kaifeng Zhang, and Yunzhu Li. Dynamic 3D Gaussian tracking for graph- based neural dynamics modeling. InProc. CoRL, 2024
2024
-
[67]
Reconstruction and simulation of elastic objects with spring-mass 3D Gaussians
Licheng Zhong, Hong-Xing Yu, Jiajun Wu, and Yunzhu Li. Reconstruction and simulation of elastic objects with spring-mass 3D Gaussians. InProc. ECCV, 2024. 14 PHYSIFORMER: Learning to Simulate Mechanics in World Space Supplementary Material A Method Continued A.1 PHYSIFORMER Register Tokens.In input data tokenization, we further prepend Nreg = 16 shared, l...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.