Ask, Solve, Generate: Self-Evolving Unified Multimodal Understanding and Generation via Self-Consistency Rewards
Pith reviewed 2026-06-26 04:56 UTC · model grok-4.3
The pith
A unified multimodal model improves its visual understanding and image generation using only self-derived consistency signals from unlabeled images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
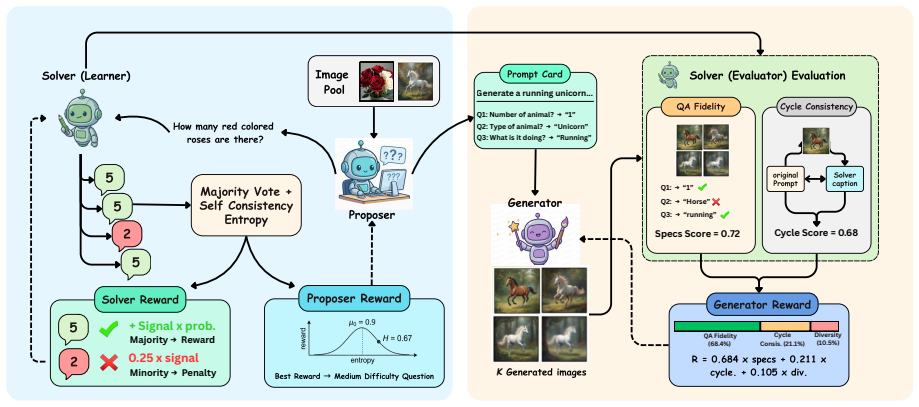
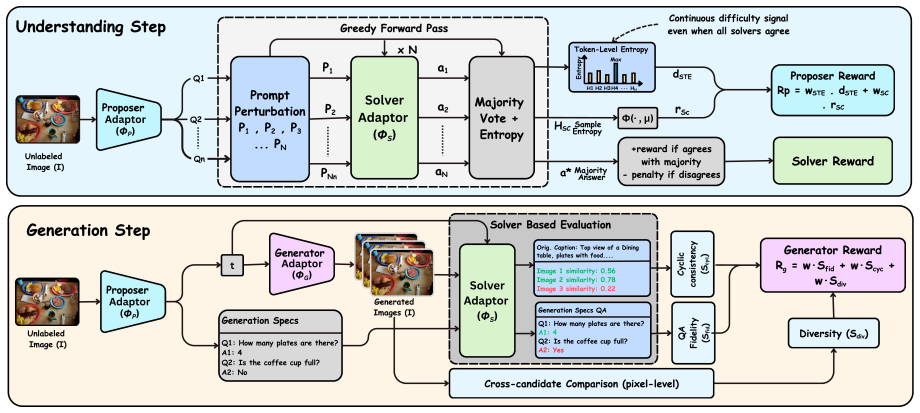
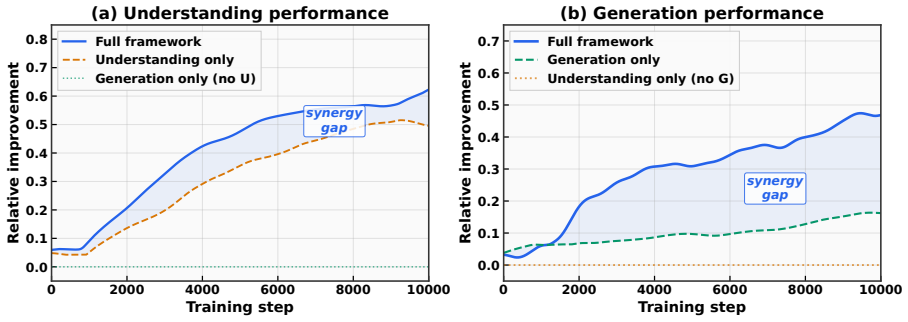
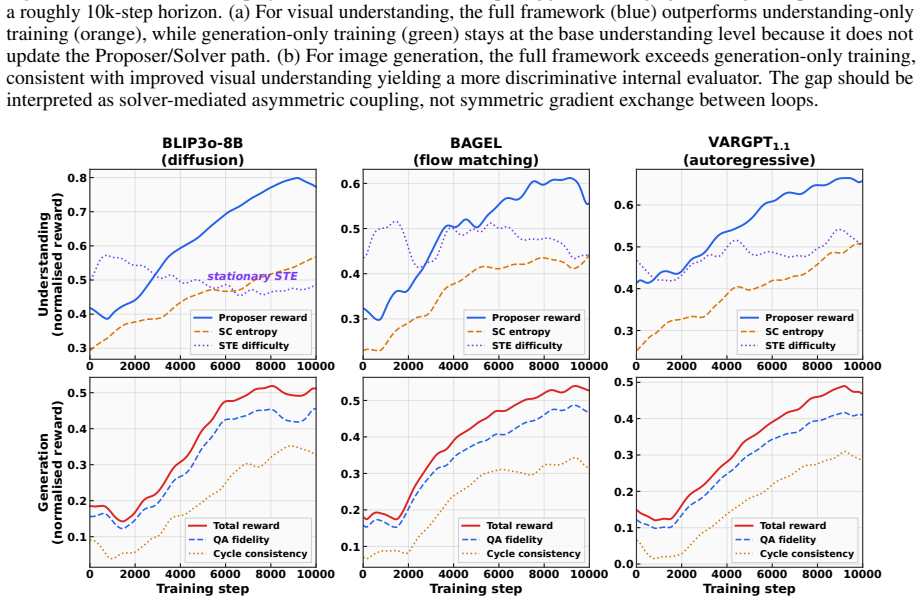
A Proposer-Solver-Generator loop that generates its own training signals from question-answer consistency and cycle-consistent image evaluation enables a unified LMM to raise performance on both understanding and generation tasks, delivering a 3.5-point absolute gain on MMMU and lifting GenEval from 82 percent to 85 percent for the BAGEL backbone while requiring only unlabeled images and each model’s native interface.
What carries the argument
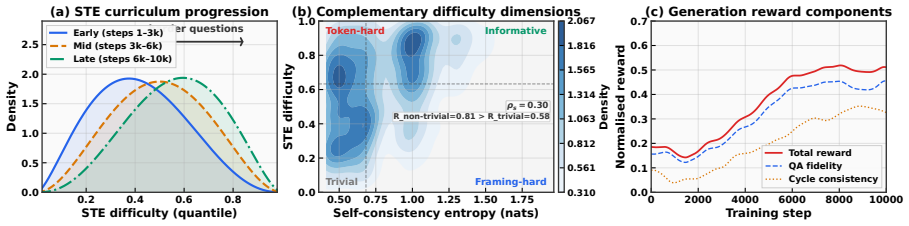
The Proposer-Solver-Generator loop mediated by Solver Token Entropy, which supplies a continuous internal difficulty signal that remains usable when sample-level consistency scores become unreliable.
If this is right
- Better visual understanding directly strengthens the reliability of the internal generation-assessment signal.
- The identical role decomposition and reward logic transfers across diffusion, rectified-flow, and autoregressive backbones without architecture-specific changes.
- No curated annotations, preference pairs, or separately trained judge models are required for the observed gains.
- Multi-scale fidelity scoring plus cycle-consistent captioning creates a closed coupling between understanding and generation training.
Where Pith is reading between the lines
- The approach could reduce dependence on large human-annotated multimodal datasets for continued scaling.
- Similar internal-consistency loops might be definable for other paired tasks such as text-to-video or audio-visual generation.
- If the entropy signal continues to function at larger scales, the method offers a route to iterative self-improvement without external supervision.
Load-bearing premise
The internal consistency signals produced by the three-role loop stay reliable enough to drive genuine improvement rather than reinforcing the model’s existing errors.
What would settle it
Training runs that apply the self-consistency rewards produce no gain or a measurable drop on held-out understanding and generation benchmarks relative to the untouched base models.
Figures
read the original abstract
Most unified large multimodal models (LMMs) that support both visual understanding and image generation still rely on curated post-training supervision, such as human annotations, preference labels, or external reward models. We ask whether a unified LMM can improve both abilities autonomously using only unlabeled images. We propose a self-evolving training framework with three internal roles: a Proposer that generates visual questions, a Solver that answers and evaluates them, and a Generator that synthesizes images. Training uses only self-derived consistency signals, without human annotations, preference labels, or task-trained external reward/judge models. To stabilize learning, we introduce Solver Token Entropy (STE), a continuous difficulty signal based on token-level prediction uncertainty that remains useful even when sample-level consistency becomes unreliable. For image generation, we design a multi-scale internal evaluation scheme that combines question-answer fidelity scoring with cycle-consistent captioning. This creates a solver-mediated coupling, where better visual understanding enables more reliable generation assessment and stronger internal training signals. The framework preserves the same role decomposition, reward logic, and training schedule across diffusion-based BLIP3o, rectified-flow BAGEL, and autoregressive VARGPT-v1.1 architectures, requiring only each backbone's native prompting and generation interface. Across eight understanding metrics, our method consistently improves over the corresponding base models. On BAGEL, it achieves a $+3.5\%$ absolute gain on MMMU and improves GenEval image generation performance from $82\%$ to $85\%$. Code and models are publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-evolving training framework for unified LMMs supporting both understanding and generation. It decomposes training into Proposer (generates questions from unlabeled images), Solver (answers and evaluates), and Generator (synthesizes images) roles, using only internal consistency signals between these components as the training objective. Solver Token Entropy (STE) is introduced as a continuous difficulty signal based on token uncertainty to stabilize learning when sample-level consistency fails. A multi-scale internal evaluation combines QA fidelity with cycle-consistent captioning for generation. The same framework is applied to BLIP3o, BAGEL, and VARGPT-v1.1, yielding consistent gains on eight understanding metrics and specific improvements on BAGEL (+3.5% MMMU, GenEval 82% to 85%). Code and models are released.
Significance. If the self-consistency signals can be shown to supply non-circular, task-aligned gradients rather than regularization effects, the result would be significant for demonstrating autonomous post-training of unified multimodal models without human annotations or external judges. The cross-architecture applicability and public release of code/models are explicit strengths that aid verification and extension.
major comments (2)
- [§3.3] §3.3 (Solver Token Entropy): The claim that STE supplies a reliable non-circular difficulty signal when sample-level consistency is unreliable is load-bearing for the central training loop, yet the manuscript provides no ablation that replaces STE with a constant or random signal while keeping other loop components fixed; without this isolation, attribution of the +3.5% MMMU gain to the semantic content of consistency versus implicit regularization remains unverified.
- [§4.2] §4.2 (BAGEL experiments): The reported gains on MMMU and GenEval are attributed to the Proposer-Solver-Generator consistency rewards, but the experimental design lacks a control that disables the consistency metric (e.g., uniform random rewards or extra forward passes without the reward logic); this leaves open whether observed improvements arise from the proposed self-derived signals or from auxiliary effects of the training schedule.
minor comments (2)
- [Abstract] Abstract: The phrase 'across eight understanding metrics' is used without enumeration; listing the specific metrics (e.g., VQAv2, GQA, etc.) would improve immediate clarity.
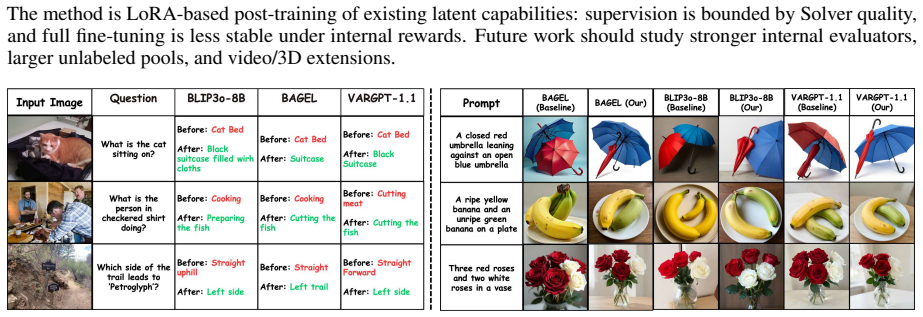
- [§3.1] §3.1: The multi-scale internal evaluation scheme for generation is described at a high level; providing the exact weighting or combination formula between QA fidelity and cycle-consistent captioning would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the need for stronger isolation of the self-consistency signals. We address each major point below. Where the manuscript lacks the requested controls, we agree that additional experiments are warranted and will incorporate them.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Solver Token Entropy): The claim that STE supplies a reliable non-circular difficulty signal when sample-level consistency is unreliable is load-bearing for the central training loop, yet the manuscript provides no ablation that replaces STE with a constant or random signal while keeping other loop components fixed; without this isolation, attribution of the +3.5% MMMU gain to the semantic content of consistency versus implicit regularization remains unverified.
Authors: We agree that an explicit ablation replacing Solver Token Entropy with a constant or random signal (while holding the remainder of the Proposer-Solver-Generator loop fixed) would strengthen attribution of gains to the semantic content of the consistency signals. The manuscript shows that STE prevents instability when sample-level consistency fails, but does not contain the requested control. We will add this ablation in the revised version. revision: yes
-
Referee: [§4.2] §4.2 (BAGEL experiments): The reported gains on MMMU and GenEval are attributed to the Proposer-Solver-Generator consistency rewards, but the experimental design lacks a control that disables the consistency metric (e.g., uniform random rewards or extra forward passes without the reward logic); this leaves open whether observed improvements arise from the proposed self-derived signals or from auxiliary effects of the training schedule.
Authors: We acknowledge that the current BAGEL results lack a control that replaces the consistency-derived rewards with random or null signals while preserving the training schedule. Such a control would more conclusively rule out auxiliary schedule effects. We will add the requested control experiments in the revision. revision: yes
Circularity Check
No significant circularity: external benchmarks validate internal self-consistency training
full rationale
The paper trains via internal Proposer-Solver-Generator consistency signals (plus STE) but evaluates gains on independent external benchmarks (MMMU +3.5%, GenEval 82%→85%). No equation or claim equates the reported performance improvement to the consistency metric by construction. The reward is a training objective; the output metrics are separate held-out tasks. No self-citations, fitted-input predictions, or self-definitional reductions appear in the abstract or described framework. The derivation chain remains non-circular because success is measured outside the self-derived signals.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-consistency between internally generated questions, answers, and images provides a reliable training signal without external grounding.
Reference graph
Works this paper leans on
-
[1]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, pages 41–48. ACM, June 2009. doi: 10.1145/1553374.1553380. URLhttp://dx.doi.org/10.1145/1553374.1553380
-
[2]
BLIP3-o: A family of fully open unified multimodal models-architecture, training and dataset, 2025
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, Le Xue, Caiming Xiong, and Ran Xu. BLIP3-o: A family of fully open unified multimodal models-architecture, training and dataset, 2025. URLhttps://arxiv.org/abs/2505.09568
Pith/arXiv arXiv 2025
-
[3]
Janus-Pro: Unified multimodal understanding and generation with data and model scaling, 2025
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-Pro: Unified multimodal understanding and generation with data and model scaling, 2025. URL https://arxiv.org/abs/2501.17811
Pith/arXiv arXiv 2025
-
[4]
Emerging properties in unified multimodal pretraining, 2025
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining, 2025. URLhttps://arxiv.org/abs/2505.14683
Pith/arXiv arXiv 2025
-
[5]
MME: A com- prehensive evaluation benchmark for multimodal large language models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, Rongrong Ji, Caifeng Shan, and Ran He. MME: A com- prehensive evaluation benchmark for multimodal large language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Trac...
2026
-
[6]
SEED-X: Multimodal models with unified multi-granularity comprehension and generation, 2025
Yuying Ge, Sijie Zhao, Jinguo Zhu, Yixiao Ge, Kun Yi, Lin Song, Chen Li, Xiaohan Ding, and Ying Shan. SEED-X: Multimodal models with unified multi-granularity comprehension and generation, 2025. URL https://arxiv.org/abs/2404.14396
Pith/arXiv arXiv 2025
-
[7]
Zigang Geng, Yibing Wang, Yeyao Ma, Chen Li, Yongming Rao, Shuyang Gu, Zhao Zhong, Qinglin Lu, Han Hu, Xiaosong Zhang, Linus, Di Wang, and Jie Jiang. X-Omni: Reinforcement learning makes discrete autoregressive image generative models great again, 2025. URLhttps://arxiv.org/abs/2507.22058. 11
arXiv 2025
-
[8]
GenEval: An object-focused framework for evaluating text-to-image alignment
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. GenEval: An object-focused framework for evaluating text-to-image alignment. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 52132–52152. Curran Associates, Inc., 2023. URL https://proceedings.neurips.c...
2023
-
[9]
Bellemare, Jacob Menick, Rémi Munos, and Koray Kavukcuoglu
Alex Graves, Marc G. Bellemare, Jacob Menick, Rémi Munos, and Koray Kavukcuoglu. Automated curriculum learning for neural networks. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1311–1320. PMLR, 06–11 Aug 2017. URLhttps://proceedin...
2017
-
[10]
UniCorn: Towards self-improving unified multimodal models through self-generated supervision, 2026
Ruiyan Han, Zhen Fang, XinYu Sun, Yuchen Ma, Ziheng Wang, Yu Zeng, Zehui Chen, Lin Chen, Wenxuan Huang, Wei-Jie Xu, Yi Cao, and Feng Zhao. UniCorn: Towards self-improving unified multimodal models through self-generated supervision, 2026. URLhttps://arxiv.org/abs/2601.03193
arXiv 2026
-
[11]
Turning internal gap into self-improvement: Promoting the generation-understanding unification in MLLMs
Yujin Han, Hao Chen, Andi Han, Zhiheng Wang, Xinyu Liu, Yingya Zhang, Shiwei Zhang, and Difan Zou. Turning internal gap into self-improvement: Promoting the generation-understanding unification in MLLMs. InThe Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=tVnml9Q4XW
2026
-
[12]
Jixiang Hong, Yiran Zhang, Guanzhong Wang, Yi Liu, Ji-Rong Wen, and Rui Yan. SUDER: Self-improving unified large multimodal models for understanding and generation with dual self-rewards, 2025. URL https://arxiv.org/abs/2506.07963
arXiv 2025
-
[13]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[14]
Hudson and Christopher D
Drew A. Hudson and Christopher D. Manning. GQA: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6700–6709, June 2019
2019
-
[15]
Co-reinforcement learning for unified multimodal understanding and generation
Jingjing Jiang, Chongjie Si, Jun Luo, Hanwang Zhang, and Chao Ma. Co-reinforcement learning for unified multimodal understanding and generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=aDa0xEFDu1
2026
-
[16]
SRUM: Fine- grained self-rewarding for unified multimodal models, 2025
Weiyang Jin, Yuwei Niu, Jiaqi Liao, Chengqi Duan, Aoxue Li, Shenghua Gao, and Xihui Liu. SRUM: Fine- grained self-rewarding for unified multimodal models, 2025. URL https://arxiv.org/abs/2510.12784
arXiv 2025
-
[17]
Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, October 2023
2023
-
[18]
SEED-Bench: Benchmarking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. SEED-Bench: Benchmarking multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13299–13308, June 2024
2024
-
[19]
Lawrence Zitnick, and Piotr Dollár
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context. InECCV, 2014
2014
-
[20]
MMBench: Is your multi-modal model an all- around player? InComputer Vision – ECCV 2024, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. MMBench: Is your multi-modal model an all- around player? InComputer Vision – ECCV 2024, pages 216–233. Springer Nature Switzerland, October
2024
-
[21]
doi: 10.1007/978-3-031-72658-3_13
ISBN 9783031726583. doi: 10.1007/978-3-031-72658-3_13. URL http://dx.doi.org/10.1007/ 978-3-031-72658-3_13
-
[22]
JanusFlow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Yu, Liang Zhao, Yisong Wang, Jiaying Liu, and Chong Ruan. JanusFlow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Patte...
2025
-
[23]
UniRL: Self-improving unified multimodal models via supervised and reinforcement learning, 2025
Weijia Mao, Zhenheng Yang, and Mike Zheng Shou. UniRL: Self-improving unified multimodal models via supervised and reinforcement learning, 2025. URLhttps://arxiv.org/abs/2505.23380
arXiv 2025
-
[24]
SILMM: Self-improving large multimodal models for compositional text-to-image generation
Leigang Qu, Haochuan Li, Wenjie Wang, Xiang Liu, Juncheng Li, Liqiang Nie, and Tat-Seng Chua. SILMM: Self-improving large multimodal models for compositional text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18497–18508, June 2025
2025
-
[25]
Du, Zehuan Yuan, and Xinglong Wu
Liao Qu, Huichao Zhang, Yiheng Liu, Xu Wang, Yi Jiang, Yiming Gao, Hu Ye, Daniel K. Du, Zehuan Yuan, and Xinglong Wu. TokenFlow: Unified image tokenizer for multimodal understanding and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2545–2555, June 2025
2025
-
[26]
LAION-COCO: 600M synthetic captions from LAION-2B-en
Christoph Schuhmann, Andreas Köpf, Theo Coombes, Richard Vencu, Benjamin Trom, and Romain Beaumont. LAION-COCO: 600M synthetic captions from LAION-2B-en. https://laion.ai/blog/laion-coco/,
-
[27]
Published September 15, 2022
2022
-
[28]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models, 2024. URLhttps://arxiv.org/abs/2402.03300
Pith/arXiv arXiv 2024
-
[29]
Towards VQA models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards VQA models that can read. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8317–8326, June 2019
2019
-
[30]
Unigame: Turning a unified multimodal model into its own adversary
Zhaolong Su, Wang Lu, Hao Chen, Sharon Li, and Jindong Wang. Unigame: Turning a unified multimodal model into its own adversary. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 37632–37641, 2026
2026
-
[31]
Endogenous reprompting: Self-evolving cognitive alignment for unified multimodal models, 2026
Zhenchen Tang, Songlin Yang, Zichuan Wang, Bo Peng, Yang Li, Beibei Dong, and Jing Dong. Endogenous reprompting: Self-evolving cognitive alignment for unified multimodal models, 2026. URL https://arxiv. org/abs/2601.20305
arXiv 2026
-
[32]
Chameleon: Mixed-modal early-fusion foundation models, 2025
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models, 2025. URL https://arxiv. org/abs/2405.09818
Pith/arXiv arXiv 2025
-
[33]
LongCat-Next: Lexicalizing modalities as discrete tokens, 2026
Meituan LongCat Team et al. LongCat-Next: Lexicalizing modalities as discrete tokens, 2026. URL https://arxiv.org/abs/2603.27538
arXiv 2026
-
[34]
EvoLMM: Self-evolving large multimodal models with continuous rewards, 2026
Omkar Thawakar, Shravan Venkatraman, Ritesh Thawkar, Abdelrahman Shaker, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, and Fahad Khan. EvoLMM: Self-evolving large multimodal models with continuous rewards, 2026. URLhttps://arxiv.org/abs/2511.16672
Pith/arXiv arXiv 2026
-
[35]
MetaMorph: Multimodal understanding and generation via instruction tuning
Shengbang Tong, David Fan, Jiachen Li, Yunyang Xiong, Xinlei Chen, Koustuv Sinha, Michael Rabbat, Yann LeCun, Saining Xie, and Zhuang Liu. MetaMorph: Multimodal understanding and generation via instruction tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17001–17012, October 2025
2025
-
[36]
ILLUME: Illuminating your LLMs to see, draw, and self-enhance
Chunwei Wang, Guansong Lu, Junwei Yang, Runhui Huang, Jianhua Han, Lu Hou, Wei Zhang, and Hang Xu. ILLUME: Illuminating your LLMs to see, draw, and self-enhance. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 21612–21622, October 2025
2025
-
[37]
Xinlong Wang, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Zhen Li, Yuqi Wang, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Chunlei Men, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Zhongyuan Wang, and Tiejun Huang. Multimodal learning with next-tok...
-
[38]
Janus: Decoupling visual encoding for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, and Ping Luo. Janus: Decoupling visual encoding for unified multimodal understanding and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12966–12977, June 2025. 13
2025
-
[39]
Junfeng Wu, Yi Jiang, Chuofan Ma, Yuliang Liu, Hengshuang Zhao, Zehuan Yuan, Song Bai, and Xiang Bai. Liquid: Language models are scalable and unified multi-modal generators.International Journal of Computer Vision, 134(1), January 2026. ISSN 1573-1405. doi: 10.1007/s11263-025-02639-5. URL http://dx.doi.org/10.1007/s11263-025-02639-5
-
[40]
VILA-U: a unified foundation model integrating visual understanding and generation, 2025
Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, Song Han, and Yao Lu. VILA-U: a unified foundation model integrating visual understanding and generation, 2025. URLhttps://arxiv.org/abs/2409.04429
Pith/arXiv arXiv 2025
-
[41]
Grok-1.5 Vision Preview
xAI. Grok-1.5 Vision Preview. https://x.ai/news/grok-1.5v, 2024. Introduces the RealWorldQA benchmark
2024
-
[42]
Reconstruction alignment improves unified multimodal models
Ji Xie, Trevor Darrell, Luke Zettlemoyer, and XuDong Wang. Reconstruction alignment improves unified multimodal models. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=ppQWp8yrm7
2026
-
[43]
Show-o: One single transformer to unify multimodal understanding and generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=o6Ynz6OIQ6
2025
-
[44]
Show-o2: Improved native unified multimodal models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show-o2: Improved native unified multimodal models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https: //openreview.net/forum?id=7VMg7Jb7AL
2026
-
[45]
Unified multimodal models as auto-encoders
Zhiyuan Yan, Kaiqing Lin, Zongjian Li, Junyan Ye, Hui Han, Haochen Wang, Zhendong Wang, Bin Lin, Hao Li, Xinyan Xiao, Jingdong Wang, Haifeng Wang, and Li Yuan. Unified multimodal models as auto-encoders. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 41903–41912, June 2026
2026
-
[46]
MM-Vet: Evaluating large multimodal models for integrated capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. MM-Vet: Evaluating large multimodal models for integrated capabilities. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=KOTutrSR2y
2024
-
[47]
MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for exp...
2024
-
[48]
Xianwei Zhuang, Yuxin Xie, Yufan Deng, Liming Liang, Jinghan Ru, Yuguo Yin, and Yuexian Zou. V ARGPT: Unified understanding and generation in a visual autoregressive multimodal large language model, 2025. URL https://arxiv.org/abs/2501.12327
arXiv 2025
-
[49]
Xianwei Zhuang, Yuxin Xie, Yufan Deng, Dongchao Yang, Liming Liang, Jinghan Ru, Yuguo Yin, and Yuexian Zou. Vargpt-v1.1: Improve visual autoregressive large unified model via iterative instruction tuning and reinforcement learning, 2025. URLhttps://arxiv.org/abs/2504.02949
arXiv 2025
-
[50]
Jialv Zou, Bencheng Liao, Qian Zhang, Wenyu Liu, and Xinggang Wang. OmniMamba: Efficient and unified multimodal understanding and generation via state space models, 2025. URL https://arxiv.org/abs/ 2503.08686. 14 Appendix We provide additional details needed to reproduce and interpret the experiments. The appendix includes the training algorithm, implemen...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.