SemCityLoc: Aerial 6DoF Localization Using Semantic 3D City Models
Pith reviewed 2026-06-29 02:14 UTC · model grok-4.3
The pith
Aligning semantic surfaces from images with standardized 3D city models enables precise 6DoF aerial localization without dense radiometric reconstructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SemCityLoc establishes that semantically structured geometry from lightweight LoD1-LoD3 city models supplies scalable constraints for 6DoF localization by aligning with image-derived semantic surfaces and depth estimates, yielding up to 36 percent higher recall and lowering mean positional error from 9.89 meters to 2.62 meters in urban canyons without requiring radiometric scene reconstructions.
What carries the argument
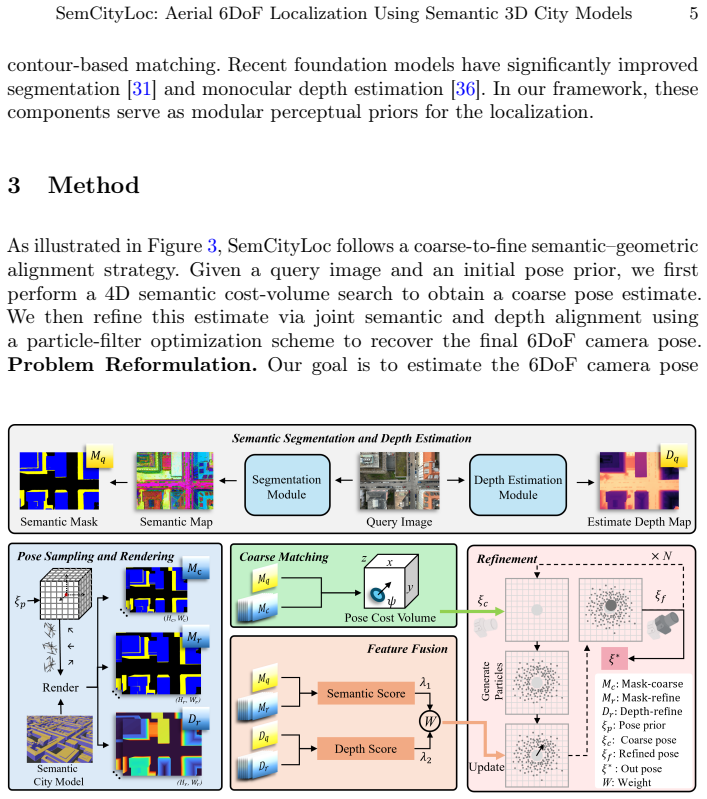
Structured surface registration that matches foundation-model semantic priors and monocular depth estimates to standardized LoD-compliant 3D building models.
If this is right
- Localization becomes feasible using only existing public city models rather than custom-built dense maps.
- Performance improves specifically in repetitive and occluded urban environments where contour or texture matching fails.
- On-board deployment is supported without GNSS or heavy radiometric processing.
- Standardized LoD1 to LoD3 models suffice for the alignment task instead of higher-detail reconstructions.
Where Pith is reading between the lines
- Navigation pipelines could shift toward maintaining semantic city models as primary reference data rather than image-based maps.
- The same surface registration principle might apply to ground-vehicle localization if monocular priors transfer across viewpoints.
- Benchmark construction with paired real poses and official city models sets a template for evaluating other map-based methods.
Load-bearing premise
Semantic labels and depth estimates from foundation models can be reliably matched to the geometry in standardized city models even under low-altitude occlusion and repetitive urban patterns.
What would settle it
A new set of low-altitude UAV flights through occluded urban canyons with independent centimeter-accurate ground truth where the reported pose errors remain above 5 meters on average would show the alignment does not deliver the claimed precision.
Figures



read the original abstract
Aerial 6DoF localization typically relies on precise GNSS signals or radiometrically rich 3D reconstructions, limiting scalability and on-board deployment. We propose SemCityLoc, a semantic-geometric alignment system that reframes aerial pose estimation as structured surface registration between foundation-model-derived visual priors and standardized LoD-compliant 3D city models. Instead of matching sparse contours or dense texture, our method aligns semantic surfaces and monocular depth with lightweight semantic 3D building models, increasing pose discriminability in repetitive and occluded urban environments. To enable accurate evaluation, we introduce SemCityLockeD, the first real-world benchmark combining centimeter-accurate UAV poses with standardized LoD1--LoD3 semantic city models and challenging low-altitude imagery. Experiments demonstrate substantial improvements over existing map-based approaches, improving recall by up to 36% and reducing mean positional error from 9.89m to 2.62m in challenging urban canyons. Our results indicate that semantically structured geometry provides sufficient and scalable constraints for high-precision aerial localization without radiometric scene reconstructions. The code and data are available at https://albertchen98.github.io/SemCityLoc.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SemCityLoc, a semantic-geometric alignment method for aerial 6DoF localization that registers foundation-model semantic surfaces and monocular depth estimates against standardized LoD1–LoD3 city models, reframing the problem as structured surface registration. It also presents the SemCityLockeD benchmark combining UAV imagery with centimeter-accurate poses and semantic city models. Experiments report up to 36% recall improvement and reduction of mean positional error from 9.89 m to 2.62 m over prior map-based methods, with the central claim that semantically structured geometry supplies sufficient constraints without radiometric reconstructions. Code and data are released.
Significance. If the correspondence and alignment claims hold, the work offers a scalable, map-based alternative to dense SfM or radiometric reconstruction for UAV localization in repetitive urban scenes. The release of code, data, and the new benchmark is a clear strength that supports reproducibility and further research.
major comments (3)
- [§4] §4 (Method): The structured surface registration step is described at a high level without explicit equations for the optimization objective, correspondence matching between semantic labels and LoD surfaces, or handling of monocular depth scale ambiguity. This makes it impossible to verify how the method avoids systematic mismatches (e.g., façade vs. roof labels) under the occlusion and repetition conditions highlighted in the abstract.
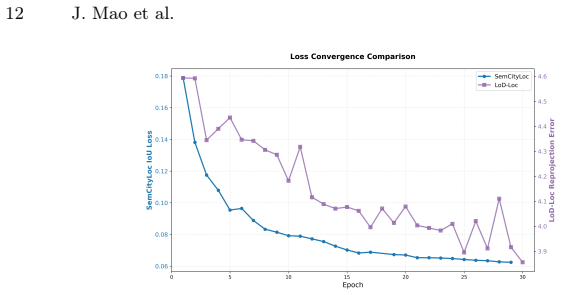
- [§5, Table 2] §5 (Experiments) and Table 2: The reported error reduction (9.89 m → 2.62 m) and recall gains are presented without ablations isolating the contribution of semantic priors versus geometric alignment alone, or failure-mode analysis for low-altitude occlusion. Without these, the attribution of gains specifically to “semantically structured geometry” cannot be confirmed as load-bearing.
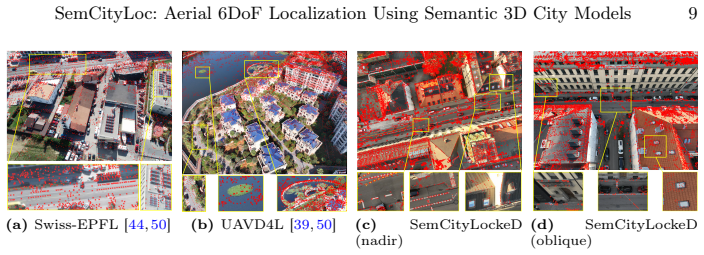
- [§3.2] §3.2 (Benchmark): The SemCityLockeD construction is described without quantitative metrics on the density or accuracy of semantic label transfer from foundation models to the LoD models, leaving the precondition of reliable correspondence untested in the reported results.
minor comments (2)
- [Abstract] Abstract: The phrase “increasing pose discriminability” is used without a supporting quantitative definition or reference to a discriminability metric in the main text.
- [Figure 3] Figure 3: Caption and axis labels are insufficient to interpret the alignment visualization without cross-reference to the method equations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate clarifications and additional analyses in the revised version where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (Method): The structured surface registration step is described at a high level without explicit equations for the optimization objective, correspondence matching between semantic labels and LoD surfaces, or handling of monocular depth scale ambiguity. This makes it impossible to verify how the method avoids systematic mismatches (e.g., façade vs. roof labels) under the occlusion and repetition conditions highlighted in the abstract.
Authors: We agree that the method description would benefit from greater mathematical detail. In the revised manuscript we will add explicit equations for the structured surface registration objective (a joint minimization of geometric surface distance and semantic label consistency), the correspondence procedure (projection-based matching restricted to identical semantic classes such as wall-to-wall or roof-to-roof), and the joint optimization of pose and monocular depth scale factor against the metric LoD geometry. These additions will directly demonstrate how label-specific constraints mitigate façade/roof mismatches. revision: yes
-
Referee: [§5, Table 2] §5 (Experiments) and Table 2: The reported error reduction (9.89 m → 2.62 m) and recall gains are presented without ablations isolating the contribution of semantic priors versus geometric alignment alone, or failure-mode analysis for low-altitude occlusion. Without these, the attribution of gains specifically to “semantically structured geometry” cannot be confirmed as load-bearing.
Authors: The existing comparisons are against prior map-based methods that lack semantic information, providing indirect evidence for the semantic contribution. Nevertheless, we acknowledge the referee’s point and will add an explicit ablation (semantic labels removed, replaced by generic geometric surfaces) together with a failure-mode analysis focused on low-altitude occlusion cases in the revised experiments section and supplementary material. revision: yes
-
Referee: [§3.2] §3.2 (Benchmark): The SemCityLockeD construction is described without quantitative metrics on the density or accuracy of semantic label transfer from foundation models to the LoD models, leaving the precondition of reliable correspondence untested in the reported results.
Authors: We agree that quantitative validation of the label transfer step would strengthen the benchmark description. In the revision we will include metrics (label accuracy, coverage density, and consistency with LoD surfaces) computed on the available ground-truth annotations and consistency checks. revision: yes
Circularity Check
No circularity: derivation relies on empirical alignment without self-referential reductions
full rationale
The paper reframes localization as semantic surface registration between foundation-model priors and LoD city models, then reports empirical gains (recall +36%, error 9.89 m to 2.62 m) on a newly introduced benchmark. No equations, fitted parameters, or predictions are shown that reduce by construction to the inputs. No load-bearing self-citations or uniqueness theorems appear in the provided text. The central claim is supported by external benchmark results rather than internal redefinition or renaming of known quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic labels from foundation models and monocular depth can be aligned to LoD city models via structured surface registration
Reference graph
Works this paper leans on
-
[1]
Anders, K., Wang, J., Chang, M., Letard, M., Schulte, F., Winiwarter, L.: Ter- restrial and UAV laser scanning point clouds of TUM Campus Ottobrunn (Dec 16 J. Mao et al. 2024). https://doi.org/10.5281/zenodo.14443336, https://doi.org/10.5281/ zenodo.14443336
-
[2]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Barath, D., Matas, J., Noskova, J.: Magsac: marginalizing sample consensus. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10197–10205 (2019)
2019
-
[3]
Barbosa, J., Schwab, B., Wysocki, O., Heeramaglore, M., Huang, X.: tum2twin: repository of CityGML LoD3 models of the technical university of munich.https: //github.com/tum-gis/tum2twin/tree/main(2023), Accessed: 2023-09-22
2023
-
[4]
ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences10, 55–62 (2024)
Bieringer, A., Wysocki, O., Tuttas, S., Hoegner, L., Holst, C.: Analyzing the impact of semantic lod3 building models on image-based vehicle localization. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences10, 55–62 (2024)
2024
-
[5]
Computers, Environment and Urban Systems48, 1–15 (2014)
Biljecki, F., Ledoux, H., Stoter, J., Zhao, J.: Formalisation of the level of detail in 3D city modelling. Computers, Environment and Urban Systems48, 1–15 (2014)
2014
-
[6]
IEEE Geoscience and Remote Sensing Magazine (2025)
Chen, D., Zhu, C., Zhang, Z., Na, J., Shen, Y., Chen, Y., Peethambaran, J., Zhang, L.: Public building geometric models from point clouds: A multidimensional quality evaluation framework. IEEE Geoscience and Remote Sensing Magazine (2025)
2025
-
[7]
In: The Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025)
Dhaouadi, O., Marin, R., Meier, J.M., Kaiser, J., Cremers, D.: Ortholoc: UAV 6-dof localization and calibration using orthographic geodata. In: The Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025)
2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Edstedt, J., Sun, Q., Bökman, G., Wadenbäck, M., Felsberg, M.: Roma: Robust dense feature matching. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19790–19800 (2024)
2024
-
[9]
Froech, T., Schwab, B., Wysocki, O.: CityGML2OBJ 2.0: Command line converter of citygml (.gml) to obj (.obj) files, while maintaining the semantics.https:// github.com/tum-gis/CityGML2OBJv2(2023), Accessed: 2023-08-23
2023
-
[10]
arXiv preprint arXiv:2505.17973 (2025)
Gaisbauer, S., Gyawali, P., Zhang, Q., Wysocki, O., Jutzi, B.: To glue or not to glue? classical vs learned image matching for mobile mapping cameras to textured semantic 3d building models. arXiv preprint arXiv:2505.17973 (2025)
-
[11]
arXiv preprint arXiv:2509.20787 (2025) 4, 10
Huang, S., Hou, Y., Liu, L., Yu, X., Shen, X.: Real-time object detection meets dinov3. arXiv preprint arXiv:2509.20787 (2025)
-
[12]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Ji, Y., He, B., Tan, Z., Wu, L.: Game4loc: A uav geo-localization benchmark from game data. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 3913–3921 (2025)
2025
-
[13]
Kolbe, T.H., Gröger, G., Plümer, L.: CityGML–3D city models and their potential foremergencyresponse.GeospatialInformationTechnologyforEmergencyResponse 257, 273–290 (2008)
2008
-
[14]
Kolbe, T.H., Kutzner, T., Smyth, C.S., Nagel, C., Roensdorf, C., Heazel, C.: OGC City Geography Markup Language (CityGML) Part 1: Conceptual Model Standard v3.0 (Jun 2021)
2021
-
[15]
ACM Transactions on Graphics (ToG) 39(6), 1–14 (2020)
Laine, S., Hellsten, J., Karras, T., Seol, Y., Lehtinen, J., Aila, T.: Modular primitives for high-performance differentiable rendering. ACM Transactions on Graphics (ToG) 39(6), 1–14 (2020)
2020
-
[16]
https : / / geodaten
LDBV: Das Landesamt für Digitalisierung, Breitband und Vermessung (LDBV). https : / / geodaten . bayern . de / opengeodata / OpenDataDetail . html ? pn = lod2 (2025), accessed: 2025-06-22
2025
-
[17]
In: European Conference on Computer Vision
Li, F., Zhang, H., Sun, P., Zou, X., Liu, S., Li, C., Yang, J., Zhang, L., Gao, J.: Segment and recognize anything at any granularity. In: European Conference on Computer Vision. pp. 467–484. Springer (2024) SemCityLoc: Aerial 6DoF Localization Using Semantic 3D City Models 17
2024
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, X., Wang, S., Zhao, Y., Verbeek, J., Kannala, J.: Hierarchical scene coordinate classification and regression for visual localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11983–11992 (2020)
2020
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Y., Jiang, L., Xu, L., Xiangli, Y., Wang, Z., Lin, D., Dai, B.: Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3205–3215 (2023)
2023
-
[20]
In: 2023 IEEE International Conference on Robotics and Automation (ICRA)
Maggio, D., Abate, M., Shi, J., Mario, C., Carlone, L.: Loc-nerf: Monte carlo localization using neural radiance fields. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 4018–4025. IEEE (2023)
2023
-
[21]
Applied geomatics6(1), 1–15 (2014)
Nex, F., Remondino, F.: Uav for 3d mapping applications: a review. Applied geomatics6(1), 1–15 (2014)
2014
-
[22]
ISPRS Open Journal of Photogrammetry and Remote Sensing p
Nex, F., Stathopoulou, E., Remondino, F., Yang, M., Madhuanand, L., Yogender, Y., Alsadik, B., Weinmann, M., Jutzi, B., Qin, R.: Usegeo-a uav-based multi-sensor dataset for geospatial research. ISPRS Open Journal of Photogrammetry and Remote Sensing p. 100070 (2024)
2024
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Panek, V., Kukelova, Z., Sattler, T.: Visual localization using imperfect 3d models from the internet. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13175–13186 (2023)
2023
-
[24]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[25]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12179–12188 (2021)
2021
-
[26]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
The International Archives of the Photogrammetry, Remote Sensing and Spatial Information SciencesXLI-B4, 747–754 (2016)
Roschlaub, R., Batscheider, J.: An INSPIRE-conform 3D building model of Bavaria using cadastre information, LiDAR and image matching. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information SciencesXLI-B4, 747–754 (2016)
2016
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: Superglue: Learning feature matching with graph neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4938–4947 (2020)
2020
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sarlin, P.E., DeTone, D., Yang, T.Y., Avetisyan, A., Straub, J., Malisiewicz, T., Bulo, S.R., Newcombe, R., Kontschieder, P., Balntas, V.: Orienternet: Visual local- ization in 2d public maps with neural matching. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21632–21642 (2023)
2023
-
[30]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4104–4113 (2016)
2016
-
[31]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Stilla, U., Xu, Y.: Change detection of urban objects using 3d point clouds: A review. ISPRS Journal of Photogrammetry and Remote Sensing197, 228–255 (2023).https://doi.org/https://doi.org/10.1016/j.isprsjprs.2023.01.010 18 J. Mao et al
-
[33]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Taira, H., Okutomi, M., Sattler, T., Cimpoi, M., Pollefeys, M., Sivic, J., Pajdla, T., Torii, A.: Inloc: Indoor visual localization with dense matching and view synthesis. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7199–7209 (2018)
2018
-
[34]
IEEE Transactions on Pattern Analysis and Machine Intelligence44(4), 2074–2088 (2020)
Toft, C., Maddern, W., Torii, A., Hammarstrand, L., Stenborg, E., Safari, D., Okutomi, M., Pollefeys, M., Sivic, J., Pajdla, T., et al.: Long-term visual localization revisited. IEEE Transactions on Pattern Analysis and Machine Intelligence44(4), 2074–2088 (2020)
2074
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Trivigno, G., Masone, C., Caputo, B., Sattler, T.: The unreasonable effectiveness of pre-trained features for camera pose refinement. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12786–12798 (2024)
2024
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, R., Xu, S., Dai, C., Xiang, J., Deng, Y., Tong, X., Yang, J.: Moge: Un- locking accurate monocular geometry estimation for open-domain images with optimal training supervision. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5261–5271 (2025)
2025
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang,Y.,He,X.,Peng,S.,Tan,D.,Zhou,X.:Efficientloftr:Semi-denselocalfeature matching with sparse-like speed. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21666–21675 (2024)
2024
-
[38]
In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Wu, H., Zhang, Z., Lin, S., Mu, X., Zhao, Q., Yang, M., Qin, T.: Maplocnet: Coarse-to-fine feature registration for visual re-localization in navigation maps. In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 13198–13205. IEEE (2024)
2024
-
[39]
In: 2024 International Conference on 3D Vision (3DV)
Wu, R., Cheng, X., Zhu, J., Liu, Y., Zhang, M., Yan, S.: Uavd4l: A large-scale dataset for uav 6-dof localization. In: 2024 International Conference on 3D Vision (3DV). pp. 1574–1583. IEEE (2024)
2024
-
[40]
The Interna- tional Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences48, 493–500 (2024)
Wysocki, O., Schwab, B., Beil, C., Holst, C., Kolbe, T.H.: Reviewing open data semantic 3D city models to develop novel 3D reconstruction methods. The Interna- tional Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences48, 493–500 (2024)
2024
-
[41]
Wysocki, O., Schwab, B., Willenborg, B., Knezevic, M.: Awesome CityGML.https: //github.com/OloOcki/awesome-citygml(2024), Accessed: 2024-01-30
2024
-
[42]
IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) pp
Wysocki, O., Xia, Y., Wysocki, M., Grilli, E., Hoegner, L., Cremers, D., Stilla, U.: Scan2LoD3: Reconstructing semantic 3D building models at LoD3 using ray casting and Bayesian networks. IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) pp. 6547–6557 (2023)
2023
-
[43]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xia, Y., Lu, Y., Song, R., Dhaouadi, O., Henriques, J.F., Cremers, D.: Trafficloc: localizing traffic surveillance cameras in 3d scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 28685–28695 (2025)
2025
-
[44]
Yan, Q., Zheng, J., Reding, S., Li, S., Doytchinov, I.: Crossloc: Scalable aerial localizationassistedbymultimodalsyntheticdata.In:ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17358–17368 (2022)
2022
-
[45]
In: 2023 IEEE International Conference on Multimedia and Expo (ICME)
Yan, S., Cheng, X., Liu, Y., Zhu, J., Wu, R., Liu, Y., Zhang, M.: Render-and- compare: Cross-view 6-dof localization from noisy prior. In: 2023 IEEE International Conference on Multimedia and Expo (ICME). pp. 2171–2176. IEEE (2023)
2023
-
[46]
arXiv preprint arXiv:2509.00833 (2025)
Yang, S., Wang, H., Xing, Z., Chen, S., Zhu, L.: Segdino: An efficient design for med- ical and natural image segmentation with dino-v3. arXiv preprint arXiv:2509.00833 (2025)
-
[47]
Ye, Y., Teng, X., Chen, S., Li, Z., Liu, L., Yu, Q., Tan, T.: Exploring the best way for uav visual localization under low-altitude multi-view observation condition: a benchmark. arXiv preprint arXiv:2503.10692 (2025) SemCityLoc: Aerial 6DoF Localization Using Semantic 3D City Models 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences10, 249–256 (2025)
Zhang, Q., Wysocki, O., Jutzi, B.: Gs4buildings: Prior-guided gaussian splatting for 3d building reconstruction. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences10, 249–256 (2025)
2025
-
[49]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhu, J., Peng, S., Wang, L., Tan, H., Liu, Y., Zhang, M., Yan, S.: Lod-loc v2: Aerial visual localization over low level-of-detail city models using explicit silhouette alignment. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 26610–26621 (2025)
2025
-
[50]
Advances in Neural Information Processing Systems37, 119063–119098 (2024)
Zhu, J., Yan, S., Wang, L., Zhang, S., Liu, Y., Zhang, M.: Lod-loc: Aerial visual localization using lod 3d map with neural wireframe alignment. Advances in Neural Information Processing Systems37, 119063–119098 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.